Geometry of Relaxed Fair Regression: A Unified Framework for Aware and Unaware Settings
Pith reviewed 2026-06-29 10:07 UTC · model grok-4.3
The pith
Fair regression under demographic parity can be reformulated exactly as an optimal transport problem that works in both aware and unaware settings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
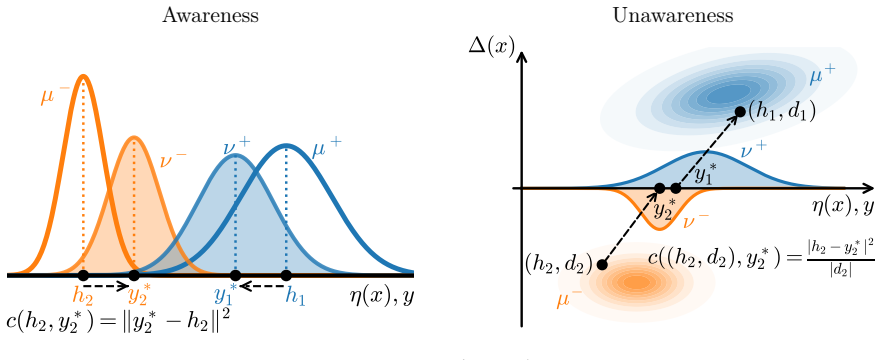
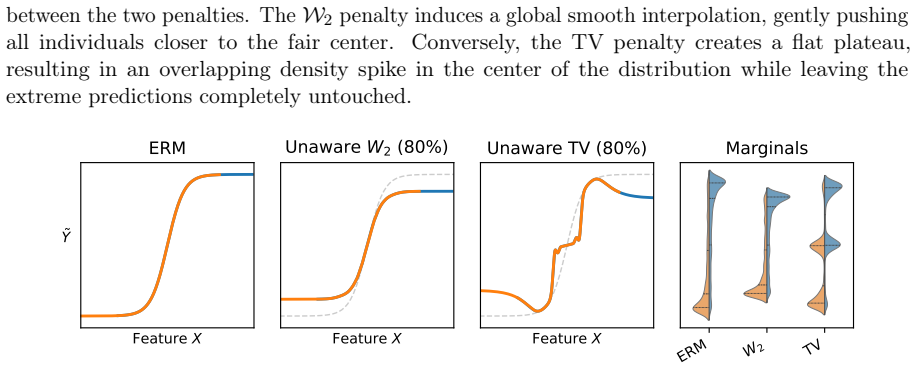
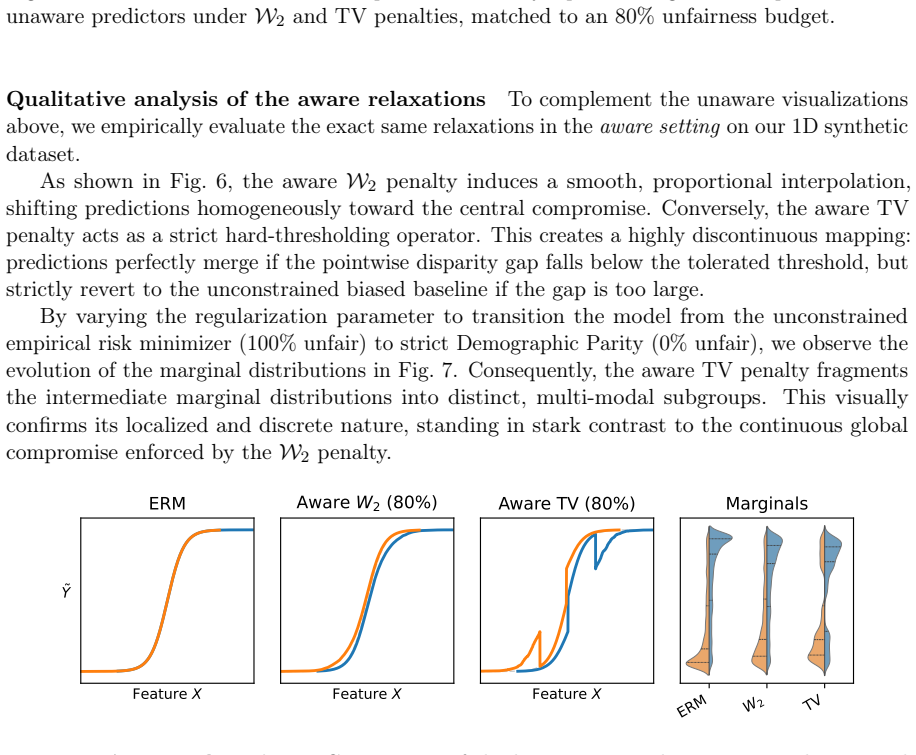
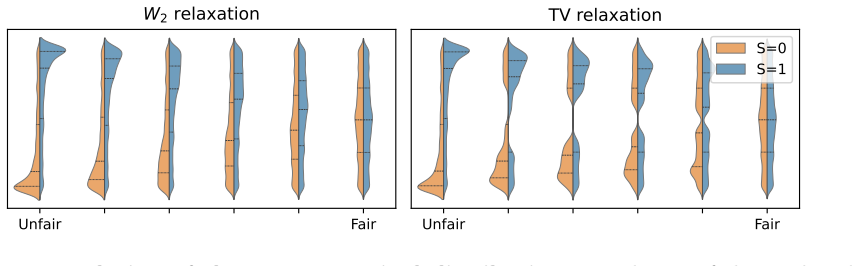
Formulating regression under a demographic parity penalty as an optimal transport problem unifies both the aware and unaware settings and characterizes optimal prediction functions via optimal transport maps, under both squared Wasserstein-2 and Total Variation penalties. These results reveal that the Wasserstein penalty induces a smooth, population-wide compromise, while Total Variation enforces exact parity for a subset of individuals.
What carries the argument
the optimal transport formulation of the demographic parity penalty, whose solutions are the optimal transport maps between the relevant conditional distributions
If this is right
- The optimal fair predictors are exactly the optimal transport maps for the chosen penalty.
- The Wasserstein-2 penalty produces a smooth adjustment across the entire population.
- The total variation penalty meets demographic parity exactly for a subset of individuals.
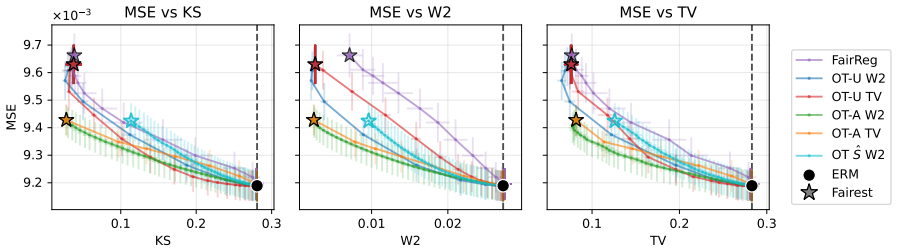
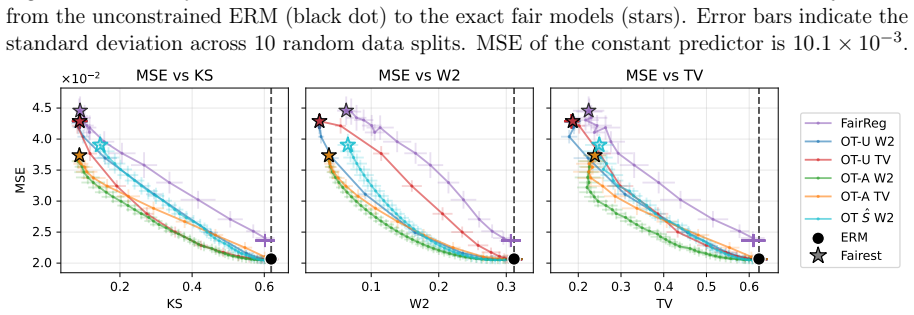
- A simple algorithm derived from the transport characterization is computationally efficient and matches or exceeds prior methods on real benchmarks.
Where Pith is reading between the lines
- The transport view could guide the design of new fairness penalties based on other cost functions between distributions.
- The same geometry might extend to fairness notions beyond demographic parity once they are expressed as transport costs.
- In practice, the choice between penalties could be driven by whether a smooth or a hard fairness guarantee is preferred on a given dataset.
Load-bearing premise
The demographic parity penalty admits an exact optimal transport formulation whose solutions are precisely the OT maps for the chosen penalties, without further restrictions on the regressor class or data distributions.
What would settle it
A concrete counter-example distribution and loss where the minimizer of the fairness-penalized regression objective is not an optimal transport map under either the Wasserstein-2 or total variation penalty.
Figures
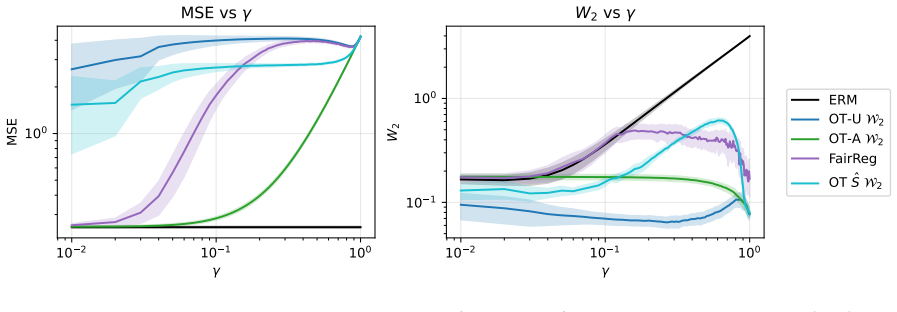
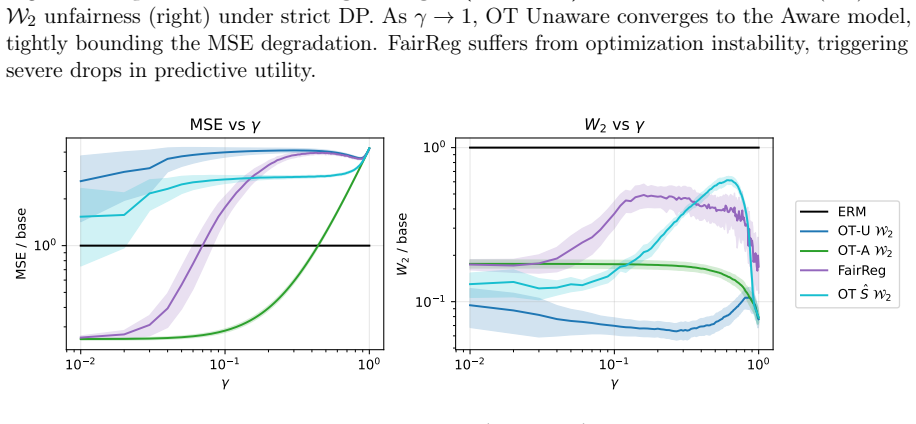
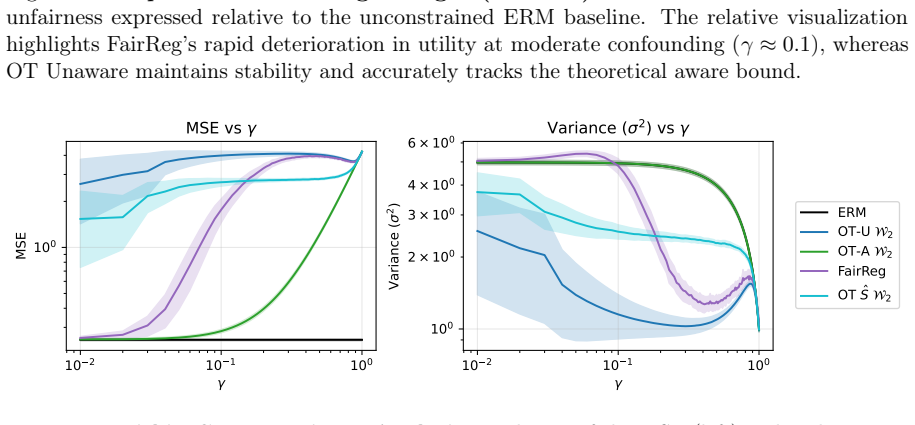
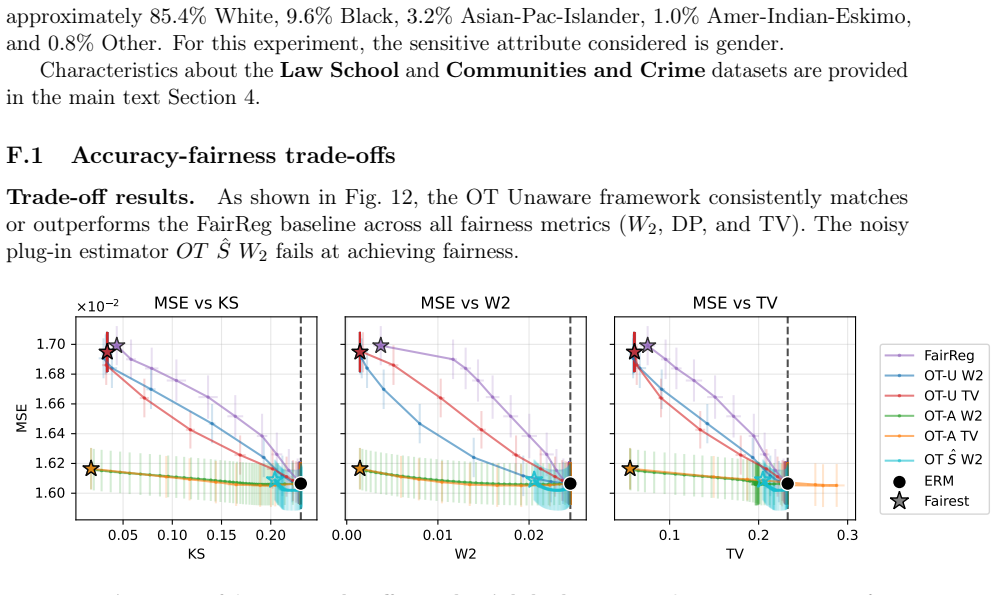
read the original abstract
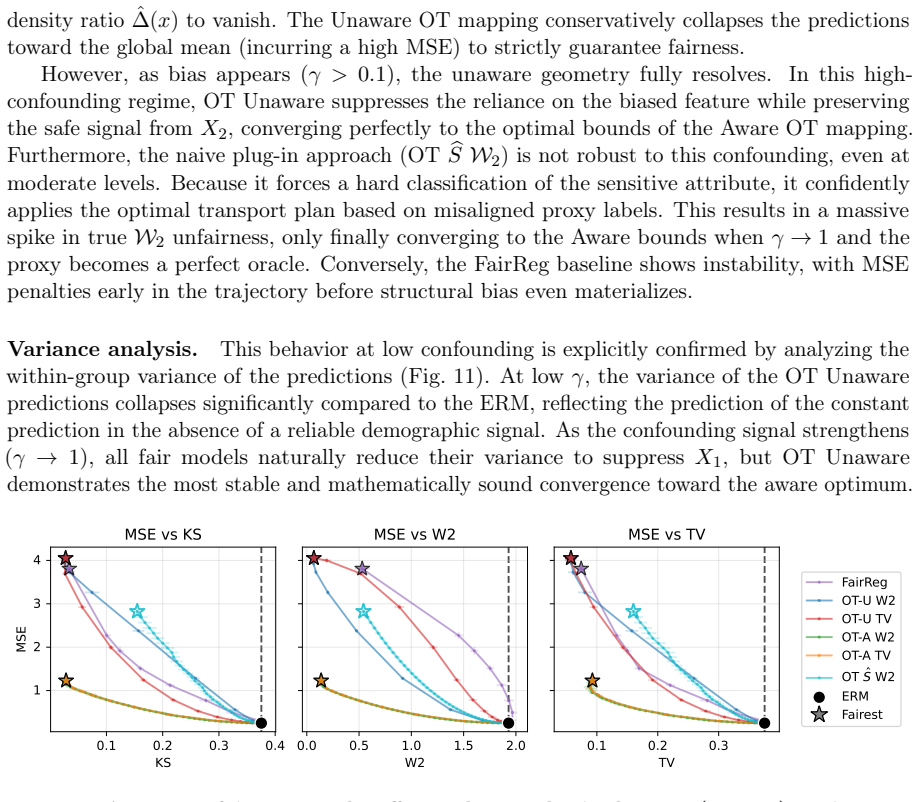
Fairness-accuracy trade-offs are a central concern in the deployment of fairness-aware machine learning methods. When sensitive attributes are unavailable at inference time-the so called unawareness setting, principled methods for obtaining accurate predictions under relaxed fairness constraints are largely missing. In this work, we address this gap by formulating regression under a demographic parity penalty as an optimal transport problem. Our framework unifies both the \emph{aware} and \emph{unaware} settings and characterizes optimal prediction functions via optimal transport maps, under both squared Wasserstein-2 and Total Variation penalties. These results reveal that the choice of penalty reflects fundamentally different fairness philosophies: the Wasserstein penalty induces a smooth, population-wide compromise, while Total Variation enforces exact parity for a subset of individuals. Building on these theoretical characterizations, we propose an algorithm that is simple to implement, computationally efficient, and consistently matches or outperforms state-of-the-art baselines on real-world benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formulates regression under a demographic parity penalty as an optimal transport problem. It unifies the aware and unaware settings by characterizing optimal prediction functions via OT maps, for both squared Wasserstein-2 and Total Variation penalties. The work distinguishes the fairness philosophies induced by each penalty and proposes a simple, efficient algorithm that matches or exceeds baselines on real-world data.
Significance. If the OT characterizations are rigorous, the paper supplies a geometric lens on relaxed fairness constraints that directly yields practical algorithms for both aware and unaware regimes. The explicit link between penalty choice and population-wide versus subset-exact parity is a useful conceptual contribution, and the algorithm's reported performance suggests immediate applicability.
major comments (2)
- [§4] §4 (unaware case): The derivation equates the demographic parity penalty to an OT problem whose solutions are OT maps, but does not explicitly enforce that the regressor must be measurable with respect to σ(X) alone. If the resulting map depends on S, the claimed unification requires an additional conditional-expectation or projection step whose effect on the attained penalty value is not shown to be zero; this step is load-bearing for the unaware claim.
- [Theorem 3.1] Theorem 3.1 / Eq. (12): The statement that the Wasserstein-2 penalty induces a 'smooth, population-wide compromise' is presented as following directly from the OT map, yet the proof sketch does not quantify how the map behaves under the demographic parity constraint when the regressor class is restricted; a counter-example or explicit bound would strengthen the claim.
minor comments (2)
- Notation for the sensitive attribute S and the predictor f is introduced inconsistently between the aware and unaware sections; a single table of symbols would improve readability.
- The experimental section reports aggregate metrics but omits per-dataset variance or statistical significance tests against the strongest baseline; adding these would make the performance claims easier to assess.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [§4] §4 (unaware case): The derivation equates the demographic parity penalty to an OT problem whose solutions are OT maps, but does not explicitly enforce that the regressor must be measurable with respect to σ(X) alone. If the resulting map depends on S, the claimed unification requires an additional conditional-expectation or projection step whose effect on the attained penalty value is not shown to be zero; this step is load-bearing for the unaware claim.
Authors: We agree that the unaware case requires an explicit treatment of the σ(X)-measurability constraint. The OT map is initially derived on the joint law of (X,S,Y), but the unaware regressor must be a function of X alone. In the revision we will insert a dedicated paragraph in §4 that applies the conditional-expectation projection onto σ(X)-measurable functions and proves that this projection leaves the demographic-parity penalty unchanged: the penalty is a functional of the marginal push-forward measure of the predictions, which is invariant under conditioning on X. This step therefore does not alter the attained penalty value and preserves the claimed unification. revision: yes
-
Referee: [Theorem 3.1] Theorem 3.1 / Eq. (12): The statement that the Wasserstein-2 penalty induces a 'smooth, population-wide compromise' is presented as following directly from the OT map, yet the proof sketch does not quantify how the map behaves under the demographic parity constraint when the regressor class is restricted; a counter-example or explicit bound would strengthen the claim.
Authors: Theorem 3.1 characterizes the unrestricted optimal map, which illustrates the population-level geometry induced by the Wasserstein penalty. When the function class is restricted, the result serves as an ideal benchmark. We will revise the discussion following Eq. (12) to state this distinction explicitly and add a quantitative bound on the sub-optimality gap that arises from the restriction, obtained from the Lipschitz continuity of the Wasserstein-2 map with respect to the marginal constraint. This addition will make the scope of the claim precise. revision: yes
Circularity Check
No significant circularity; derivation relies on standard OT theory
full rationale
The paper derives its unification of aware and unaware fair regression by mapping the demographic parity penalty to an optimal transport problem and characterizing solutions via OT maps under W2 and TV penalties. This equivalence is presented as following from the mathematical definition of the penalties and standard OT results, without any reduction of predictions to fitted parameters by construction, self-definitional loops, or load-bearing self-citations. The unaware setting constraint (regressors measurable w.r.t. X only) is addressed as part of the framework setup rather than smuggled in via prior author work. No steps match the enumerated circularity patterns, and the central claims remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Demographic parity penalty can be exactly encoded as a cost in an optimal transport problem whose solutions are OT maps.
Reference graph
Works this paper leans on
-
[1]
Fair regression: Quantitative defi- nitions and reduction-based algorithms
Alekh Agarwal, Miroslav Dudik, and Zhiwei Steven Wu. Fair regression: Quantitative defi- nitions and reduction-based algorithms. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors,Proceedings of the 36th International Conference on Machine Learning, volume 97 ofProceedings of Machine Learning Research, pages 120–129. PMLR, 09–15 Jun 2019. URL https:/...
2019
-
[2]
Aliprantis and Kim C
Charalambos D. Aliprantis and Kim C. Border.Infinite Dimensional Analysis: A Hitchhiker’s Guide. Springer Berlin Heidelberg, 3 edition, 2006. ISBN 978-3-540-32696-0. doi: 10.1007/ 3-540-29587-9
2006
-
[3]
Equalized odds post- processing under imperfect group information
Pranjal Awasthi, Matthäus Kleindessner, and Jamie Morgenstern. Equalized odds post- processing under imperfect group information. In Silvia Chiappa and Roberto Calandra, editors,Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 1770–1780. PMLR, 2...
2020
-
[4]
MIT Press, 2023
Solon Barocas, Moritz Hardt, and Arvind Narayanan.Fairness and Machine Learning: Limitations and Opportunities. MIT Press, 2023
2023
-
[5]
A Convex Framework for Fair Regression
Richard A. Berk, Hoda Heidari, Shahin Jabbari, Matthew Joseph, Michael Kearns, Jamie Morgenstern, Seth Neel, and Aaron Roth. A convex framework for fair regression. In Proceedings of the 4th Workshop on Fairness, Accountability, and Transparency in Machine Learning (FAT/ML), ICML Workshop, August 2017. URLhttps://arxiv.org/abs/1706. 02409. Co-located with...
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[6]
InProceedings of the Conference on Fairness, Accountability, and Transparency (FAT* ’19)
Jiahao Chen, Nathan Kallus, Xiaojie Mao, Geoffry Svacha, and Madeleine Udell. Fairness under unawareness: Assessing disparity when protected class is unobserved. InProceedings of the Conference on Fairness, Accountability, and Transparency, FAT* ’19, page 339–348. ACM, January 2019. doi: 10.1145/3287560.3287594. URLhttp://dx.doi.org/10.1145/ 3287560.3287594
-
[7]
Silvia Chiappa, Ray Jiang, Tom Stepleton, Aldo Pacchiano, Heinrich Jiang, and John Aslanides. A general approach to fairness with optimal transport.Proceedings of the AAAI Conference on Artificial Intelligence, 34(04):3633–3640, Apr. 2020. doi: 10.1609/aaai.v34i04
-
[8]
URLhttps://ojs.aaai.org/index.php/AAAI/article/view/5771
-
[9]
Evgenii Chzhen and Nicolas Schreuder. A minimax framework for quantifying risk-fairness trade-off in regression.The Annals of Statistics, 50(4):2416–2442, August 2022. doi: 10.1214/22-AOS2198. URLhttps://arxiv.org/abs/2007.14265
-
[10]
Fair regression with wasserstein barycenters
Evgenii Chzhen, Christophe Denis, Mohamed Hebiri, Luca Oneto, and Massimiliano Pontil. Fair regression with wasserstein barycenters. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors,Advances in Neural Information Processing Systems, volume 33, pages 7321–7331. Curran Associates, Inc., 2020. URLhttps://proceedings.neurips.cc/ pape...
2020
-
[11]
Optimization with non-differentiable constraints with applications to fairness, recall, churn, and other goals.Journal of Machine Learning Research, 20(172): 1–59, 2019
Andrew Cotter, Heinrich Jiang, Maya Gupta, Serena Wang, Taman Narayan, Seungil You, and Karthik Sridharan. Optimization with non-differentiable constraints with applications to fairness, recall, churn, and other goals.Journal of Machine Learning Research, 20(172): 1–59, 2019. URLhttp://jmlr.org/papers/v20/18-616.html
2019
-
[12]
Fairness guarantees in multi-class classification with demographic parity.Journal of Machine Learning Research, 25(130):1–46, 2024
Christophe Denis, Romuald Elie, Mohamed Hebiri, and François Hu. Fairness guarantees in multi-class classification with demographic parity.Journal of Machine Learning Research, 25(130):1–46, 2024. URLhttps://jmlr.org/papers/v25/23-0322.html. 12
2024
-
[13]
Demographic parity in regression and classification within the unawareness framework, 2024
Vincent Divol and Solenne Gaucher. Demographic parity in regression and classification within the unawareness framework, 2024. URLhttps://arxiv.org/abs/2409.02471
-
[14]
Cynthia Dwork, Moritz Hardt, Toniann Pitassi, Omer Reingold, and Richard Zemel. Fairness through awareness. InProceedings of the 3rd Innovations in Theoretical Computer Science Conference, ITCS ’12, pages 214–226. ACM, January 2012. doi: 10.1145/2090236.2090255. URLhttps://arxiv.org/abs/1104.3913
-
[15]
Learning with minibatch Wasserstein : asymptotic and gradient properties
Kilian Fatras, Younes Zine, Rémi Flamary, Rémi Gribonval, and Nicolas Courty. Learning with minibatch Wasserstein : asymptotic and gradient properties. InAISTATS 2020 - 23nd International Conference on Artificial Intelligence and Statistics, volume volume 108 of PMLR, pages 1–20, Palermo, Italy, June 2020. URLhttps://hal.science/hal-02502329
2020
-
[16]
Fatou’s lemma for weakly converging probabilities.Theory of Probability & Its Applications, 58(4):683–689, 2014
Eugene A Feinberg, Pavlo O Kasyanov, and Nina V Zadoianchuk. Fatou’s lemma for weakly converging probabilities.Theory of Probability & Its Applications, 58(4):683–689, 2014
2014
-
[17]
Pot: Python optimal transport.Journal of Machine Learning Research, 22(78):1–8, 2021
Rémi Flamary, Nicolas Courty, Alexandre Gramfort, Mokhtar Z Alaya, Aurélie Boisbunon, Stanislas Chambon, Laetitia Chapel, Adrien Corenflos, Kilian Fatras, Nemo Fournier, et al. Pot: Python optimal transport.Journal of Machine Learning Research, 22(78):1–8, 2021
2021
-
[18]
Equality as a moral ideal.Ethics, 98(1):21–43, October 1987
Harry Gordon Frankfurt. Equality as a moral ideal.Ethics, 98(1):21–43, October 1987. doi: 10.1086/292913. URLhttps://www.jstor.org/stable/2381290
-
[19]
Fair learning with wasserstein barycenters for non-decomposable performance measures
Solenne Gaucher, Nicolas Schreuder, and Evgenii Chzhen. Fair learning with wasserstein barycenters for non-decomposable performance measures. In Francisco Ruiz, Jennifer Dy, and Jan-Willem van de Meent, editors,Proceedings of The 26th International Conference on Artificial Intelligence and Statistics, volume 206 ofProceedings of Machine Learning Research,...
2023
-
[20]
Projection to fairness in statistical learning, 2020
Thibaut Le Gouic, Jean-Michel Loubes, and Philippe Rigollet. Projection to fairness in statistical learning, 2020. URLhttps://arxiv.org/abs/2005.11720
-
[21]
Fairness without demographics in repeated loss minimization
Tatsunori Hashimoto, Megha Srivastava, Hongseok Namkoong, and Percy Liang. Fairness without demographics in repeated loss minimization. In Jennifer Dy and Andreas Krause, editors,Proceedings of the 35th International Conference on Machine Learning, volume 80 of Proceedings of Machine Learning Research, pages 1929–1938. PMLR, 10–15 Jul 2018. URL https://pr...
1929
-
[22]
Assessing algorithmic fairness with un- observed protected class using data combination.Manage
Nathan Kallus, Xiaojie Mao, and Angela Zhou. Assessing algorithmic fairness with un- observed protected class using data combination.Manage. Sci., 68(3):1959–1981, March
1959
-
[23]
ISSN 0025-1909. doi: 10.1287/mnsc.2020.3850. URL https://doi.org/10.1287/ mnsc.2020.3850
-
[24]
Fairness without demographics through adversarially reweighted learning
Preethi Lahoti, Alex Beutel, Jilin Chen, Kang Lee, Flavien Prost, Nithum Thain, Xuezhi Wang, and Ed Chi. Fairness without demographics through adversarially reweighted learning. In H. Larochelle, M. Ranzato, R. Hadsell, M.F. Balcan, and H. Lin, editors, Advances in Neural Information Processing Systems, volume 33, pages 728–740. Curran As- sociates, Inc.,...
2020
-
[25]
Fair text classification via transferable representations.Journal of Machine Learning Research, 26(239):1–47, 2025
Thibaud Leteno, Michael Perrot, Charlotte Laclau, Antoine Gourru, and Christophe Gravier. Fair text classification via transferable representations.Journal of Machine Learning Research, 26(239):1–47, 2025. URLhttp://jmlr.org/papers/v26/25-0485.html. 13
2025
-
[26]
Levin, Y
D.A. Levin, Y. Peres, and E.L. Wilmer.Markov Chains and Mixing Times. American Mathematical Soc., 2009. ISBN 9780821886274. URLhttps://books.google.fr/books? id=6Cg5Nq5sSv4C
2009
-
[27]
Zhu Li, Adrian Perez-Suay, Gustau Camps-Valls, and Dino Sejdinovic. Kernel dependence regularizers and gaussian processes with applications to algorithmic fairness, 2019. URL https://arxiv.org/abs/1911.04322
-
[28]
Does mitigating ml's impact disparity require treatment disparity? In S
Zachary Lipton, Julian McAuley, and Alexandra Chouldechova. Does mitigating ml's impact disparity require treatment disparity? In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc., 2018. URLhttps://proceedings.neurips. cc/paper_fi...
2018
-
[29]
Too relaxed to be fair
Michael Lohaus, Michaël Perrot, and Ulrike Von Luxburg. Too relaxed to be fair. In Proceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020
2020
-
[30]
Harvard University Press, 1971
John Rawls.A Theory of Justice. Harvard University Press, 1971
1971
-
[31]
Birkhäuser Cham, 1 edition, 2015
Filippo Santambrogio.Optimal Transport for Applied Mathematicians: Calculus of Vari- ations, PDEs, and Modeling, volume 87 ofProgress in Nonlinear Differential Equations and Their Applications. Birkhäuser Cham, 1 edition, 2015. ISBN 978-3-319-20827-5. doi: 10.1007/978-3-319-20828-2. Published 27 October 2015
-
[32]
Computing barycentres of measures for generic transport costs.arXiv preprint arXiv:2501.04016, 2024
Eloi Tanguy, Julie Delon, and Nathaël Gozlan. Computing barycentres of measures for generic transport costs.arXiv preprint arXiv:2501.04016, 2024
-
[33]
Regression under demo- graphic parity constraints via unlabeled post-processing
Gayane Taturyan, Evgenii Chzhen, and Mohamed Hebiri. Regression under demo- graphic parity constraints via unlabeled post-processing. In A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, editors,Advances in Neural Information Processing Systems, volume 37, pages 117917–117953. Curran As- sociates, Inc., 2024. URLhttps://pr...
2024
-
[34]
Springer Science & Business Media, 2008
Cédric Villani.Optimal Transport: Old and New, volume 338 ofGrundlehren der mathema- tischen Wissenschaften. Springer Science & Business Media, 2008. ISBN 9783540710509
2008
-
[35]
Muhammad Bilal Zafar, Isabel Valera, Manuel Gomez-Rodriguez, and Krishna P. Gummadi. Fairness constraints: A flexible approach for fair classification.Journal of Machine Learning Research, 20(75):1–42, 2019. URLhttp://jmlr.org/papers/v20/18-262.html. 14 Appendix Table of Contents A Proofs of propositions and lemmas 2 A.1 Equivalence between (3) and (Pλ,D)...
2019
-
[36]
Then,(ν +∗, ν−∗) = (y∗ 1, y∗ 2)♯π∗ is a minimizer of(P λ,D)
: R×R→R 2 be a measurable map such that(y∗ 1(z1, z2), y∗ 2(z1, z2))realizes the infimum in (10) for all( z1, z2) ∈ R2 ×R 2. Then,(ν +∗, ν−∗) = (y∗ 1, y∗ 2)♯π∗ is a minimizer of(P λ,D). Proof of Lemma 2.To prove this equivalence, we first establish that the pointwise optimization constitutes a lower bound for the global problem, and then demonstrate that t...
-
[37]
We can therefore push forwardπ∗ via the map(z1, z2) 7→ (z1, z2, y∗ 1, y∗ 2)and construct a joint measure ρ∗
: R2 ×R 2 →R 2 such that( y∗ 1(z1, z2), y∗ 2(z1, z2))is a minimizer ofΦ z1,z2 for all(z 1, z2)∈R×R. We can therefore push forwardπ∗ via the map(z1, z2) 7→ (z1, z2, y∗ 1, y∗ 2)and construct a joint measure ρ∗. The marginals ofρ∗ over its third and fouth coordinates (y1 and y2) define target distributions ν+∗ and ν−∗. Because ρ∗ constitutes a valid joint tr...
-
[38]
On the one hand, plugging this value into the first-order conditions yield ( y∗ 1 = h1(1+λa2)+λh2a1 1+λ(a1+a2) , y∗ 2 = h2(1+λa1)+λh1a2 1+λ(a1+a2)
From the optimality conditions we have ( y∗ 1 −h 1 =−λa 1u, y∗ 2 −h 2 =λa 2u, Subtracting these identities givesu = (h1 −h 2) −λ (a1 + a2)u, which resolves tou = h1−h2 1+λ(a1+a2). On the one hand, plugging this value into the first-order conditions yield ( y∗ 1 = h1(1+λa2)+λh2a1 1+λ(a1+a2) , y∗ 2 = h2(1+λa1)+λh1a2 1+λ(a1+a2) . (12) On the other hand, plug...
-
[39]
According to Lemma 2, a solution(ν+∗, ν−∗)of (Pλ,D) is given by the marginal distributions of (y∗ 1(Z1, Z2), y∗ 2(Z1, Z2))where( Z1, Z2) ∼π ∗ and π∗ is as in(5)
= (λa1u)2 a1 + (λa2u)2 a2 +λu 2 =λu2 (1 +λ(a 1 +a 2)) =λ (h1 −h 2)2 (1 +λ(a 1 +a 2))2 (1 +λ(a 1 +a 2)) = λ 1 +λ(a 1 +a 2)(h1 −h 2)2. According to Lemma 2, a solution(ν+∗, ν−∗)of (Pλ,D) is given by the marginal distributions of (y∗ 1(Z1, Z2), y∗ 2(Z1, Z2))where( Z1, Z2) ∼π ∗ and π∗ is as in(5). Our next goal is to show that under Assumption 1, the random v...
-
[40]
for allz 1,ψ(z 1) = inf z2(ϕ(z2) +C λ,c2(z1, z2)); 2.π ∗ is supported on theCu λ,c2-subdifferential of a Kantorovich potentialψ, that is the set Γ ={(z 1, z2)∈ Z × Z:ψ(z 1)−ϕ(z 2) =C λ,c2(z1, z2)}. The arguments used to prove Lemma 3 in Divol and Gaucher[12] can be reproduced to show that under Assumption 1, the Kantorovich potentialψ is differentiable in...
-
[41]
In particular, the two output laws become arbitrarily close inW2
Since R h2 |d| dµ± η,∆(z) = R X± η(x)2 dχ(x) ≤ E[η(X)2] <∞ , we haveW2 2(ν∗ 1,λ, ν∗ 2,λ) → 0as λ→ ∞ . In particular, the two output laws become arbitrarily close inW2. Therefore the relaxed solutions asymptotically enforce a single common output distribution; if the unrelaxed barycenter is unique, this common limit must coincide with the unrelaxed barycen...
-
[42]
Thus Cλ,c0(z1, z2) = λ and thus y∗ 1(z1, z2) = h1 clearly only depends onz1
+λ−ϕ(z 2)≥λ. Thus Cλ,c0(z1, z2) = λ and thus y∗ 1(z1, z2) = h1 clearly only depends onz1. This shows that the mapT + λ,TV is well-definedµ + η,∆-almost everywhere. Similarly, we show that the mapT− λ,TV is well-definedµ − η,∆-almost everywhere. We then conclude using Lemma 1 to show that solutions of Equation (3) take the form described in the lemma. Let ...
2000
-
[43]
For the Law School dataset, the initialW2 gap is approximately0.03
between the initial biased distributions. For the Law School dataset, the initialW2 gap is approximately0.03. The exact geometric cost to perfectly repair this disparity is therefore bounded by0.032 = 0.0009. Because the targets are scaled to [−1, 1], the base ERM risk is naturally around0.010. Adding the absolute maximum fairness penalty yields an expect...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.