How Far Can Disaggregation Go? A Design-Space Exploration of Attention-FFN Disaggregation for Efficient MoE LLM Serving
Pith reviewed 2026-06-29 14:08 UTC · model grok-4.3
The pith
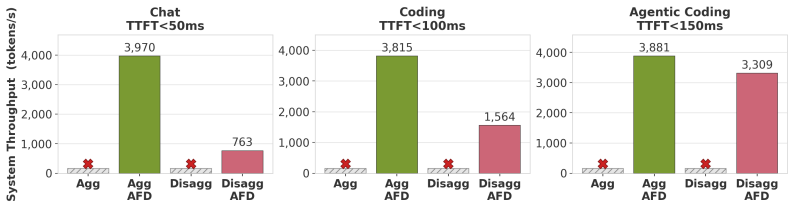
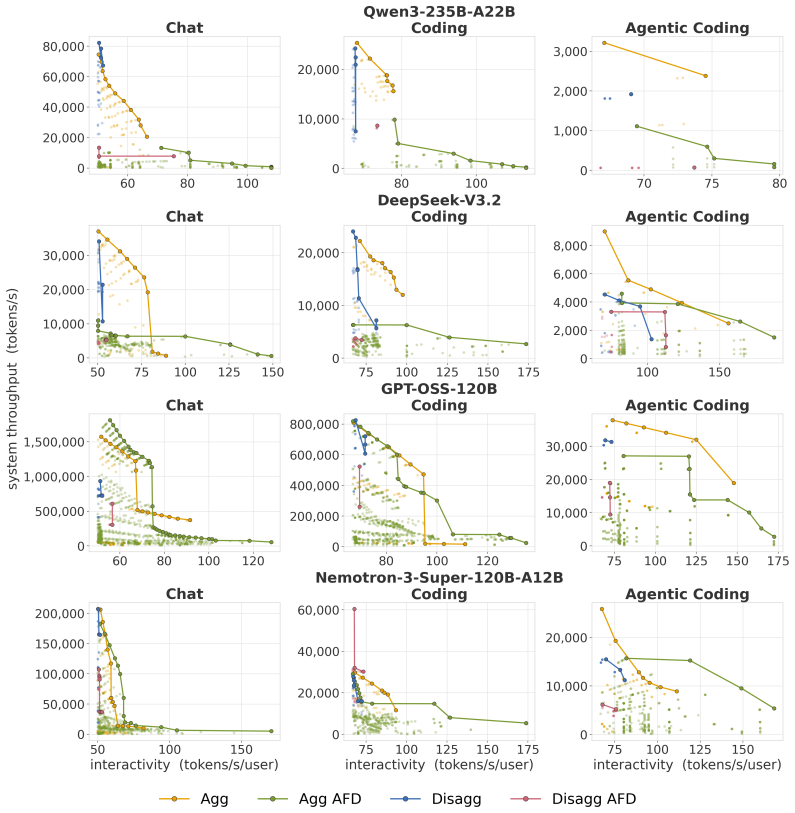
AFD sustains around 4k tokens/s throughput for DeepSeek-V3.2 under strict TTFT/TPOT SLOs where non-AFD is infeasible.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
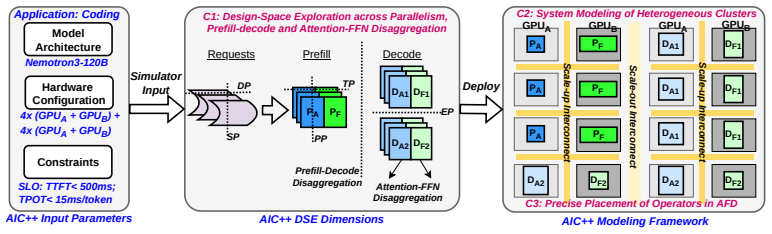
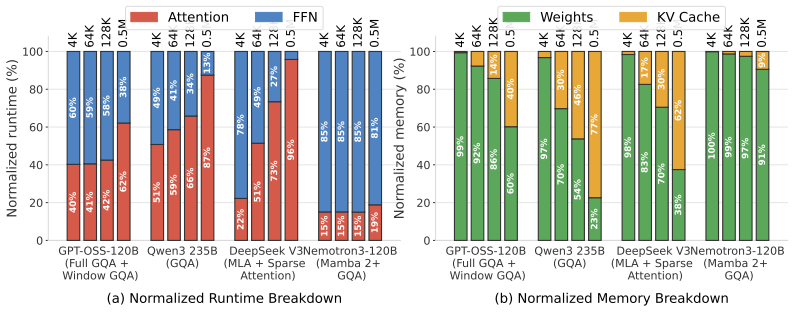
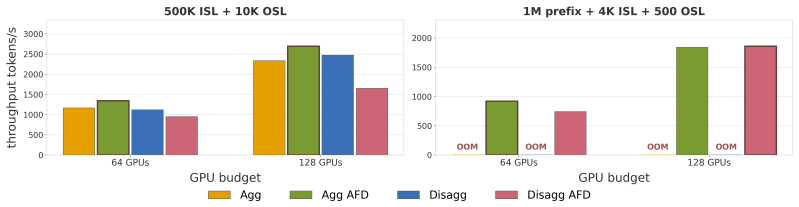
By placing attention and MoE-FFN execution on separate GPU groups, AFD manages the distinct demands of memory-bound attention, compute-intensive expert FFNs, and MoE dispatch/combine communication, sustaining around 4k tokens/s of system throughput on DeepSeek-V3.2 under strict TTFT/TPOT SLOs across chat, coding, and agentic-coding workloads, where non-AFD deployments are infeasible.
What carries the argument
Attention-FFN Disaggregation (AFD), which assigns attention computations and MoE expert FFN computations to distinct GPU groups.
If this is right
- Partitioning attention and FFN across GPUs must be chosen as a function of workload sequence lengths, prefix-KV reuse, and model architecture.
- AFD becomes necessary to sustain both throughput and interactivity when strict per-user latency constraints are enforced on large MoE models.
- Design principles for current rack- and cluster-scale deployments favor deeper disaggregation to handle MoE operator heterogeneity.
- Joint optimization of throughput and interactivity requires evaluating all three disaggregation levels against the specific input/output characteristics of the target workload.
Where Pith is reading between the lines
- Extending the simulation framework to other MoE architectures could test whether the 4k tokens/s threshold generalizes beyond DeepSeek-V3.2.
- Real interconnect topologies that deviate from the simulated network model might shift the workload regimes where AFD provides the largest gains.
- The same measurement-plus-simulation approach could be applied to explore whether finer operator-level splits become worthwhile on next-generation hardware.
Load-bearing premise
The fused on-device kernel measurements and high-fidelity network simulation accurately predict real rack- and cluster-scale behavior for AFD scheduling and communication patterns.
What would settle it
Deploying AFD at rack scale on real hardware for DeepSeek-V3.2 and checking whether measured system throughput under the same TTFT/TPOT SLOs reaches the simulated value of around 4k tokens/s.
Figures

read the original abstract
Modern large language model (LLM) inference has progressively disaggregated to keep pace with growing model sizes and tight TTFT and TPOT service-level objectives: from chunked-prefill aggregation, to prefill-decode (P/D) disaggregation, and most recently to operator-level Attention-FFN Disaggregation (AFD). This trend is especially important for mixture-of-experts (MoE) models, where memory-bound attention, compute-intensive expert FFNs, and MoE dispatch/combine communication create distinct resource demands. AFD further exposes this heterogeneity by placing attention and MoE-FFN execution on separate GPU groups. Each level of disaggregation deepens the scheduling design space across workload characteristics, resource allocation, and interconnect topology, raising the central question: when does each level actually pay off? We systematically characterize this trade-off for MoE inference across realistic workloads spanning input/output sequence lengths, prefix-KV reuse, and per-user latency constraints. Using chunked-prefill and P/D disaggregation as baselines, we study the benefits and limits of AFD at scale through a framework that fuses on-device kernel measurements with high-fidelity network simulation. Under strict TTFT/TPOT SLOs, AFD sustains around 4k tokens/s of system throughput on DeepSeek-V3.2 across chat, coding, and agentic-coding workloads, where non-AFD deployments are infeasible. We distill concrete takeaways for jointly optimizing throughput and interactivity, including how to partition attention and FFN across GPUs as a function of workload and model architecture, providing design principles for current rack- and cluster-scale deployments as well as future disaggregated AI infrastructure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript explores the design space of operator-level Attention-FFN Disaggregation (AFD) for MoE LLM serving, comparing it to chunked-prefill and prefill-decode (P/D) disaggregation. Using a framework that fuses on-device kernel measurements with high-fidelity network simulation, it claims that under strict TTFT/TPOT SLOs, AFD sustains ~4k tokens/s system throughput on DeepSeek-V3.2 across chat, coding, and agentic-coding workloads (where non-AFD baselines are infeasible), and distills workload-dependent partitioning guidelines for attention and FFN across GPU groups.
Significance. If the simulation framework is shown to be accurate at rack/cluster scale, the work would supply concrete, workload-specific design principles for when AFD pays off versus prior disaggregation levels in MoE inference. The systematic coverage of input/output lengths, prefix-KV reuse, and latency constraints is a strength of the empirical characterization.
major comments (2)
- [Abstract and framework description] Abstract and framework description: The central quantitative claim (~4k tokens/s throughput and infeasibility of non-AFD baselines) is produced by fusing on-device kernel measurements with high-fidelity network simulation. The manuscript supplies no validation of this simulation against real hardware at rack or cluster scale for MoE dispatch/combine volumes, AFD scheduling overheads, prefix-KV reuse, or cross-GPU contention; any systematic bias in modeled interconnect or runtime costs would alter both the reported throughput and the feasibility conclusions.
- [Throughput results (workload tables/figures)] Throughput results (workload tables/figures): No error bars, sensitivity analysis to simulation parameters, or explicit workload exclusion criteria are reported for the 4k tokens/s figure or the baseline infeasibility statements. This makes it impossible to assess robustness of the cross-workload claim that only AFD meets the SLOs.
minor comments (1)
- [Notation and definitions] Notation for TTFT/TPOT SLO thresholds and the exact definition of 'system throughput' (tokens/s) should be stated once in a dedicated subsection rather than scattered across the abstract and results.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the reliance on simulation and the need for robustness analysis. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and framework description] Abstract and framework description: The central quantitative claim (~4k tokens/s throughput and infeasibility of non-AFD baselines) is produced by fusing on-device kernel measurements with high-fidelity network simulation. The manuscript supplies no validation of this simulation against real hardware at rack or cluster scale for MoE dispatch/combine volumes, AFD scheduling overheads, prefix-KV reuse, or cross-GPU contention; any systematic bias in modeled interconnect or runtime costs would alter both the reported throughput and the feasibility conclusions.
Authors: We agree that the framework has not been validated end-to-end against real hardware at rack or cluster scale for the listed MoE operations and overheads. The approach fuses real on-device kernel measurements with a high-fidelity network simulator, but this remains a limitation. In revision we will add an explicit Limitations section describing the kernel-level validation performed, the assumptions in the network model, and the potential effects of unmodeled contention or scheduling overheads, while qualifying the reported throughput numbers. revision: yes
-
Referee: [Throughput results (workload tables/figures)] Throughput results (workload tables/figures): No error bars, sensitivity analysis to simulation parameters, or explicit workload exclusion criteria are reported for the 4k tokens/s figure or the baseline infeasibility statements. This makes it impossible to assess robustness of the cross-workload claim that only AFD meets the SLOs.
Authors: We accept this observation. The revision will add error bars from repeated simulation runs, a sensitivity analysis on key parameters (interconnect bandwidth, latency, and dispatch volume), and explicit workload selection criteria. These additions will allow readers to evaluate the robustness of the 4k tokens/s claim and the baseline infeasibility statements. revision: yes
Circularity Check
No circularity: empirical simulation-based characterization
full rationale
The paper is an empirical design-space exploration that fuses on-device kernel measurements with high-fidelity network simulation to evaluate attention-FFN disaggregation for MoE models. No derivation chain, equations, or predictions are presented that reduce by construction to fitted inputs or self-citations. The central throughput claims (e.g., ~4k tokens/s under SLOs) are direct outputs of the simulation framework rather than any self-referential definition or renaming of known results. The work is self-contained against external benchmarks via measurements and simulation, with no load-bearing self-citation or ansatz smuggling.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills
Amey Agrawal, Ashish Panwar, Jayashree Mohan, Nipun Kwatra, Bhargav S Gulavani, and Ra- machandran Ramjee. Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills.arXiv preprint arXiv:2308.16369,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URLhttps://arxiv.org/abs/2405.05465. Vaswani Ashish. Attention is all you need.Advances in neural information processing systems, 30:I,
-
[3]
URLhttps://arxiv.org/abs/2504.09775. DeepSeek-AI, Aixin Liu, Bei Feng, Bin Wang, Bingxuan Wang, Bo Liu, Chenggang Zhao, Chengqi Dengr, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu, Hao Yang, Haowei Zhang, Honghui Ding, Huajian Xin, Huazuo G...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
URLhttps://arxiv.org/abs/2405.04434. Drew A Hudson and Christopher D Manning. Gqa: A new dataset for real-world visual reasoning and compositional question answering. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6700–6709,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Association for Computing Machinery. ISBN 9798400702297. doi: 10.1145/3600006.3613165. URLhttps://doi.org/ 10.1145/3600006.3613165. Xupeng Miao, Yujie Wang, Youhe Jiang, Chunan Shi, Xiaonan Nie, Hailin Zhang, and Bin Cui. Galvatron: Efficient transformer training over multiple gpus using automatic parallelism.arXiv preprint arXiv:2211.13878,
-
[6]
Accessed: 2025-04-10. Nvidia. Rubin (microarchitecture) - wikipedia, 6
2025
-
[7]
[Online; accessed 2025-04-11]
URLhttps://en.wikipedia.org/wiki/ Rubin_(microarchitecture). [Online; accessed 2025-04-11]. NVIDIA. Accelerating mixture of experts training with rail-optimized infiniband networking in crusoe cloud (presented by crusoe) s63014 | gtc san jose 2024 | nvidia on-demand.https: //www.nvidia.com/en-us/on-demand/session/gtc24-s63014/,
2025
-
[8]
NVIDIA. InsideNVIDIAGroq3LPX:TheLow-LatencyInferenceAcceleratorfortheNVIDIAVera Rubin Platform.https://developer.nvidia.com/blog/inside-nvidia-groq-3-lpx-t he-low-latency-inference-accelerator-for-the-nvidia-vera-rubin-platform/ , 2026a. Accessed: 2026-05-07. NVIDIA. TensorRT-LLM. https://github.com/NVIDIA/TensorRT-LLM , 2026b. GitHub repository. Accessed...
2026
-
[9]
StepMesh: A high-performance, low-latency communication library for attention-ffn disaggregation, 2025.https://github.com/stepfun-ai/StepMesh
StepFun. StepMesh: A high-performance, low-latency communication library for attention-ffn disaggregation, 2025.https://github.com/stepfun-ai/StepMesh. vLLM Project. [Model] Attention FFN Disaggregation (AFD) for MoE Models.https://github .com/vllm-project/vllm/pull/29772,
2025
-
[10]
Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun
URLhttps://arxiv.org/abs/2601.06288. Gyeong-In Yu, Joo Seong Jeong, Geon-Woo Kim, Soojeong Kim, and Byung-Gon Chun. Orca: A distributedservingsystemfor {Transformer-Based}generativemodels. In16thUSENIXSymposium on Operating Systems Design and Implementation (OSDI 22), pages 521–538,
-
[11]
12 6 Appendix 6.1 vLLM Implementation for AFD We prototype AFD on top of vLLM v0.16.0rc2 Kwon et al
URL https://arxiv.org/abs/2504.02263. 12 6 Appendix 6.1 vLLM Implementation for AFD We prototype AFD on top of vLLM v0.16.0rc2 Kwon et al
-
[12]
The prototype is used for correctness and implementation guidance, while the cluster-scale results use measured backend costs and AstraSim communication modeling
to verify functional correctness of the full bipartite attention–FFN execution path and to align the implementation structure with the communication pattern modeled inAIC++. The prototype is used for correctness and implementation guidance, while the cluster-scale results use measured backend costs and AstraSim communication modeling. Our starting point i...
2025
-
[13]
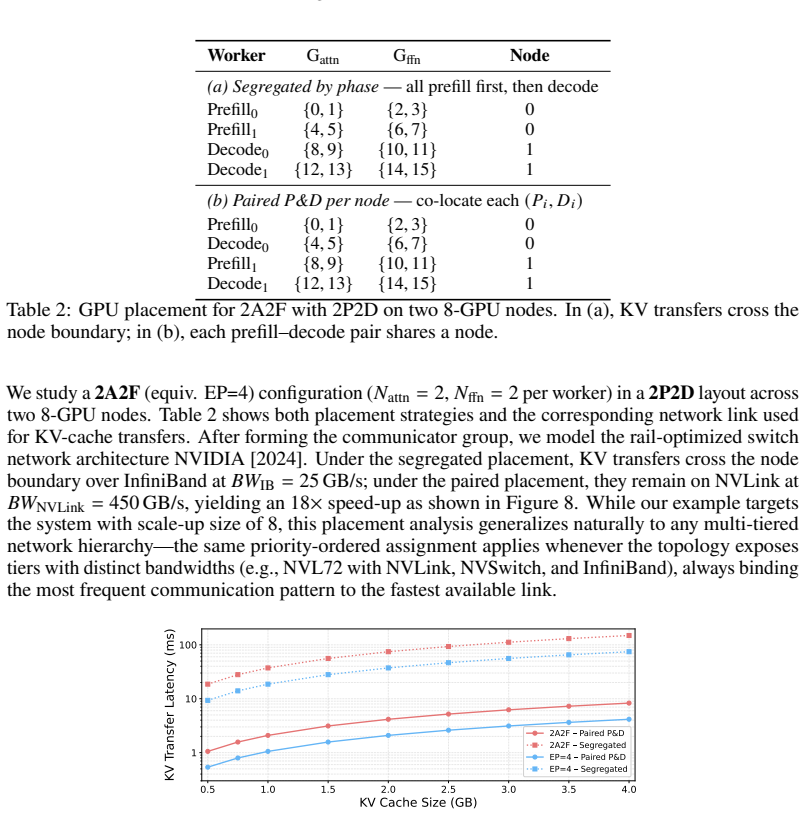
In (a), KV transfers cross the node boundary; in (b), each prefill–decode pair shares a node
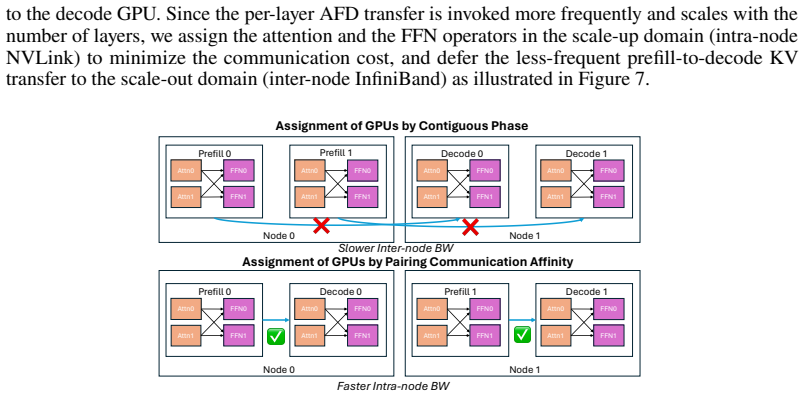
Attn0 Attn1 Node 0 FFN0 FFN1 Prefill 0Attn0 Attn1 FFN0 FFN1 Prefill 1 Attn0 Attn1 Node 0 FFN0 FFN1 Prefill 0Attn0 Attn1 FFN0 FFN1 Decode0 Attn0 Attn1 Node 1 FFN0 FFN1 Decode 0Attn0 Attn1 FFN0 FFN1 Attn0 Attn1 Node 1 FFN0 FFN1 Prefill 1Attn0 Attn1 FFN0 FFN1 Decode1 Decode 1 ✅ ✅ ❌ ❌Slower Inter-node BW Faster Intra-node BW Assignment of GPUs by Contiguous P...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.