Routing-Aligned Fine-Tuning for Multilingual Downstream Tasks in Mixture-of-Experts Models
Pith reviewed 2026-06-29 13:07 UTC · model grok-4.3
The pith
RA-MoE aligns middle-layer routing in MoE models to English task-expert patterns on ci-type examples to close multilingual performance gaps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
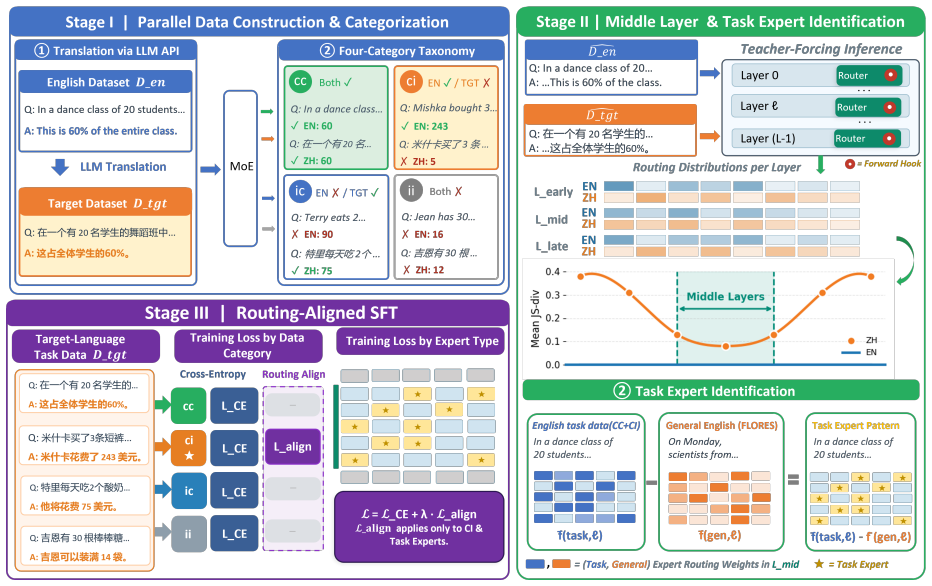
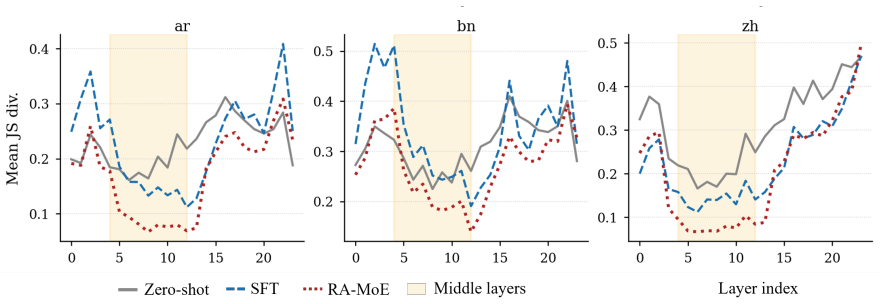
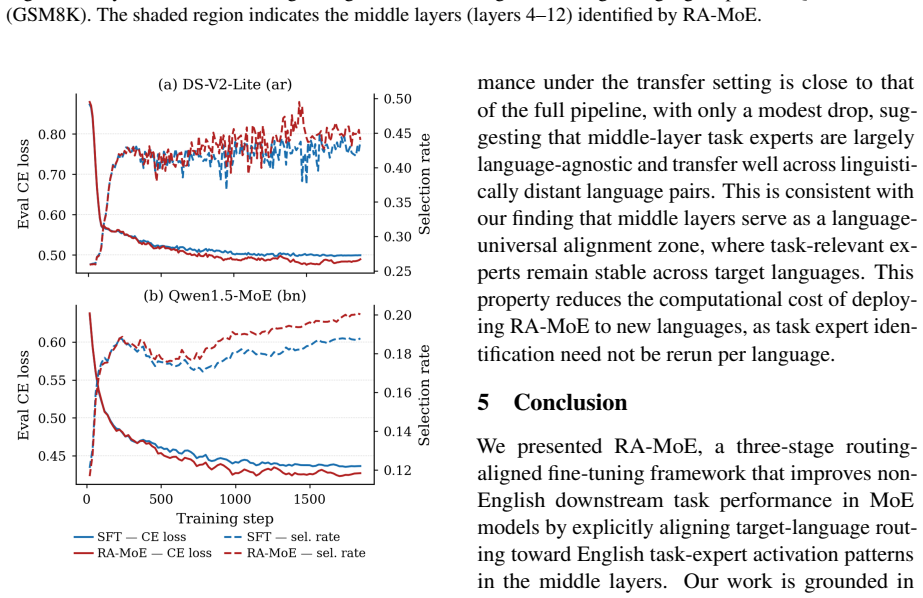
Middle layers form a language-universal alignment zone; routing divergence there predicts per-language task performance gaps. RA-MoE therefore categorizes parallel examples into a four-way taxonomy (cc/ci/ic/ii), locates task-relevant experts in those layers, and augments supervised fine-tuning with a routing alignment loss that makes target-language routing on ci examples follow the English task-expert pattern.
What carries the argument
The routing alignment loss applied only to ci-type examples, which encourages target-language activations in middle-layer experts to match the English task-expert pattern identified from parallel data.
If this is right
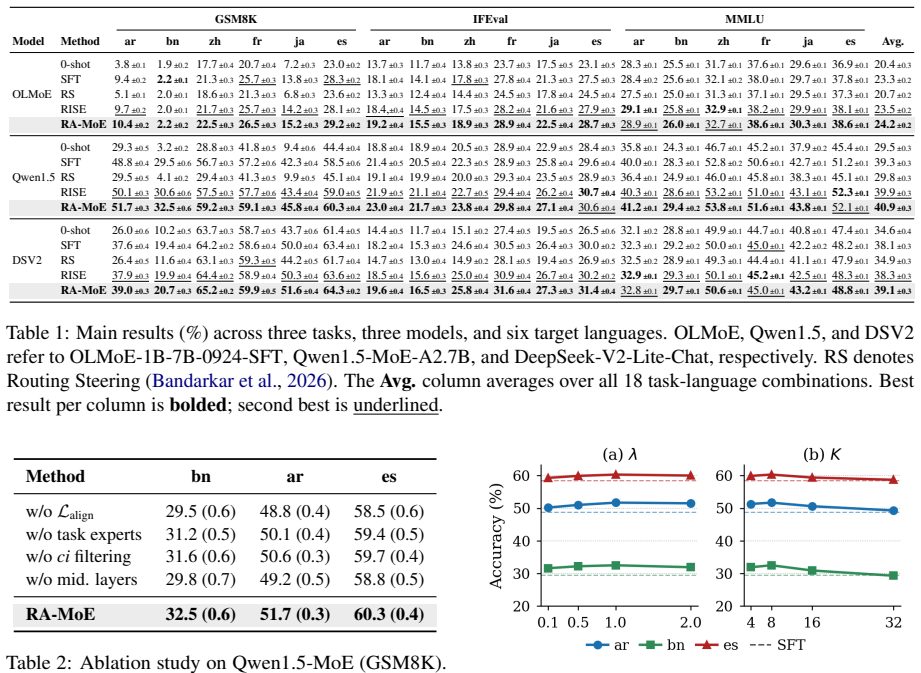
- RA-MoE improves accuracy over standard SFT and baselines on three MoE models, three tasks, and six target languages.
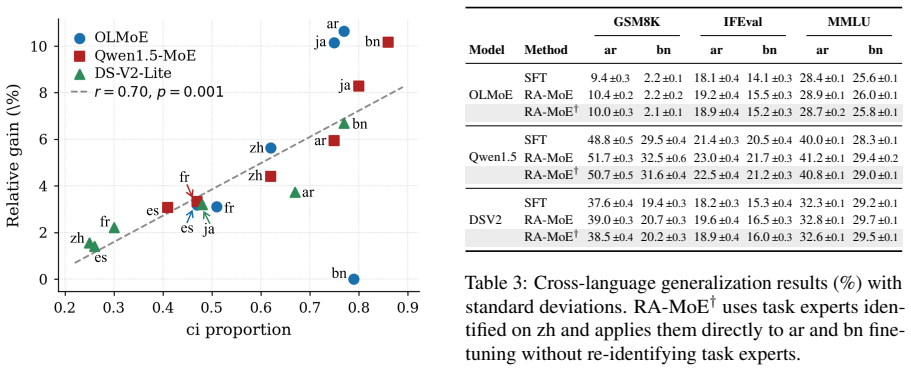
- The proportion of ci examples for a given task-language pair reliably predicts the size of the benefit from the alignment step.
- Task-relevant experts can be identified from English performance in the middle layers and then reused for target-language alignment.
- The four-way taxonomy (cc/ci/ic/ii) isolates the subset of examples where routing alignment is most useful.
Where Pith is reading between the lines
- The same taxonomy and alignment loss could be applied to other routing-based architectures beyond the three MoE models tested.
- If the middle-layer zone is stable across pretraining runs, the method might transfer to new MoE models without retraining the identifier step.
- Extending the taxonomy to more than two languages could reveal whether the alignment benefit scales with the number of mismatched languages.
Load-bearing premise
Middle layers form a language-universal alignment zone where routing divergence strongly predicts per-language task performance gaps.
What would settle it
An experiment that measures routing divergence in middle layers on held-out parallel data and finds no correlation with per-language accuracy gaps on the downstream tasks.
Figures

read the original abstract
Mixture-of-Experts (MoE) models have emerged as a dominant paradigm for efficient LLM scaling, yet adapting them to non-English downstream tasks remains challenging. Existing fine-tuning approaches treat MoE models as monolithic learners, ignoring the heterogeneous routing structure that develops during pretraining. We validate across multiple MoE models and downstream tasks that middle layers form a language-universal alignment zone where routing divergence strongly predicts per-language task performance gaps. Building on this observation, we propose RA-MoE (Routing-Aligned MoE Fine-Tuning), a three-stage framework that categorizes parallel task examples into a four-way taxonomy (cc/ci/ic/ii) based on correctness in English and the target language, identifies task-relevant experts in the middle layers, and augments standard SFT with a routing alignment loss that encourages target-language routing on ci-type examples to follow the English task-expert activation pattern. Experiments across three MoE models, three tasks, and six target languages demonstrate that RA-MoE consistently outperforms standard SFT and strong baselines including Routing Steering and RISE, with the ci proportion of a task-language pair serving as a reliable predictor of alignment benefit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that middle layers in MoE models constitute a language-universal alignment zone where routing divergence predicts per-language task performance gaps. It introduces RA-MoE, a three-stage framework that builds a four-way taxonomy (cc/ci/ic/ii) of parallel examples based on English vs. target-language correctness, identifies task-relevant experts in middle layers, and augments SFT with a routing alignment loss that steers ci-type target-language routing toward the English expert pattern. Experiments across three MoE models, three tasks, and six languages are said to show consistent gains over SFT and baselines (Routing Steering, RISE), with the ci proportion of a task-language pair serving as a reliable predictor of alignment benefit.
Significance. If the empirical claims hold, the work would supply a routing-aware fine-tuning method that exploits rather than ignores MoE heterogeneity, together with an observable predictor (ci proportion) of when alignment is useful. This could matter for efficient multilingual adaptation of large MoE models.
major comments (2)
- [Abstract] Abstract: the central claims of consistent outperformance and a predictive relationship are asserted without any experimental details, error bars, statistical tests, tables, or verification of the middle-layer observation; the soundness of the contribution therefore cannot be assessed from the provided text.
- [Method description (taxonomy and loss)] Taxonomy and loss construction: the ci proportion used as a predictor is computed from the same four-way taxonomy that selects examples for the alignment loss, introducing partial dependence between the predictor and the training signal; downstream metrics are measured independently, but the circularity risk for the predictive claim is not addressed.
Simulated Author's Rebuttal
Thank you for the opportunity to respond to the referee's report. We address each major comment point by point below. We believe the concerns can be addressed through clarifications and minor revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims of consistent outperformance and a predictive relationship are asserted without any experimental details, error bars, statistical tests, tables, or verification of the middle-layer observation; the soundness of the contribution therefore cannot be assessed from the provided text.
Authors: The abstract serves as a high-level summary of the paper's contributions and findings. Detailed experimental setups, results with error bars (standard deviations from multiple seeds), statistical tests, tables comparing RA-MoE to baselines, and verification of the middle-layer alignment zone (including routing divergence metrics and layer-wise analysis) are provided in the main body of the manuscript, specifically in Sections 3, 4, and 5. We can revise the abstract to include brief mentions of the experimental scale (three MoE models, three tasks, six languages) if recommended. revision: partial
-
Referee: [Method description (taxonomy and loss)] Taxonomy and loss construction: the ci proportion used as a predictor is computed from the same four-way taxonomy that selects examples for the alignment loss, introducing partial dependence between the predictor and the training signal; downstream metrics are measured independently, but the circularity risk for the predictive claim is not addressed.
Authors: The taxonomy is built from correctness labels obtained by evaluating the pre-trained model on parallel English and target-language examples, which is done independently of the fine-tuning process. The ci proportion is a static characteristic of each task-language pair derived from this pre-evaluation. The routing alignment loss then leverages this taxonomy during training to align ci examples. The predictive relationship is assessed by measuring how well this pre-computed proportion correlates with the gains in downstream performance on held-out test data after applying RA-MoE. We will add explicit discussion in the revised manuscript to clarify this separation and mitigate any appearance of circularity. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and description outline a taxonomy (cc/ci/ic/ii) used both to select ci-type examples for the routing alignment loss and to compute the ci proportion as a predictor of alignment benefit. However, no equations, derivations, or explicit reductions are present that demonstrate any claimed prediction or result being equivalent to its inputs by construction. Downstream task metrics are described as measured independently, and the framework is presented as an empirical augmentation to SFT rather than a self-referential definition. Without load-bearing self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work, the derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Middle layers of MoE models form a language-universal alignment zone where routing divergence strongly predicts per-language task performance gaps.
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model
Deepseek-v2: A strong, economical, and effi- cient mixture-of-experts language model.Preprint, arXiv:2405.04434. Guanzhi Deng, Bo Li, Ronghao Chen, Xiujin Liu, Zhuo Han, Huacan Wang, Lijie Wen, and Linqi Song. 2026. Dr-lora: Dynamic rank lora for fine-tuning mixture- of-experts models.Preprint, arXiv:2601.04823. Naman Goyal, Cynthia Gao, Vishrav Chaudhary...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language under- standing.Preprint, arXiv:2009.03300. Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations. Albert Q Jiang, Alexandre Sablayrolles, Antoine Rou...
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[3]
Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437. Danni Liu and Jan Niehues. 2025. Middle-layer repre- sentation alignment for cross-lingual transfer in fine- tuned llms. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15979–15996. 9 Niklas Muennighoff, Luca Soldaini, D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
All training-based methods (SFT, RISE, RA-MoE) share identical training schedules, optimization set- tings, and data orders for a fair comparison
applied to the up and down projections of every FFN layer, with all other parameters frozen. All training-based methods (SFT, RISE, RA-MoE) share identical training schedules, optimization set- tings, and data orders for a fair comparison. Table 8 reports the hyperparameter settings shared across all models and tasks; Table 9 reports the per-model, per-ta...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.