HardMTBench: Stress-Testing Chinese-English Translation on Knowledge-Intensive Domains
Pith reviewed 2026-06-29 12:55 UTC · model grok-4.3
The pith
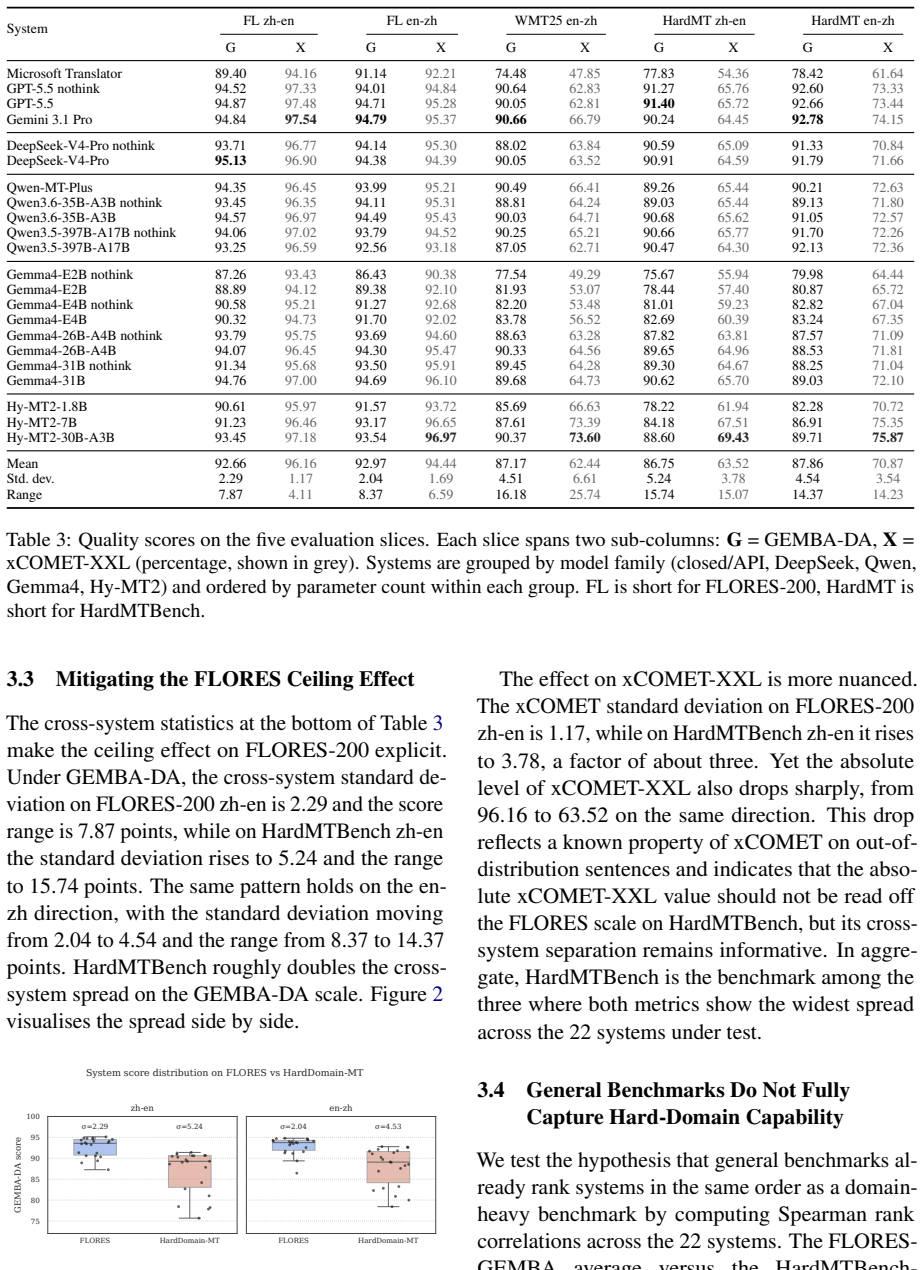
HardMTBench widens GEMBA score ranges by a factor of two and reorders system rankings on Chinese-English domain translation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across 22 systems spanning general LLMs, commercial engines and specialised MT models, HardMTBench widens the cross-system GEMBA range by roughly a factor of two over FLORES-200, induces visible rank reorderings, and exposes domain-specific terminology and knowledge weaknesses that quality-only metrics tend to flatten.
What carries the argument
A three-stage construction pipeline that builds a domain-balanced candidate pool of 84,566 pairs, applies an LLM-based multi-signal judge over knowledge density, translation difficulty, terminology load and reference correctness, and assembles the final test set under a hardness fusion rule with per-domain quotas.
If this is right
- Systems that appear similar on general benchmarks can be differentiated more clearly when tested on finance, healthcare, law, and science domains.
- Rank orderings among general LLMs, commercial engines, and specialised MT models shift when domain knowledge and terminology demands increase.
- Quality-only metrics flatten domain-specific failures that become measurable once hardness selection is applied.
- The 10,000-sentence, 12-domain resource supplies per-domain quotas for targeted diagnostic evaluation.
Where Pith is reading between the lines
- The same multi-signal selection process could be reused to generate hardness-aware test sets for additional language pairs beyond Chinese-English.
- Developers could feed the identified weak domains back into continued pre-training or retrieval-augmented translation pipelines.
- Open release of the 20,000 directional items enables direct comparison of new models against the reported 22-system baseline on identical hard material.
Load-bearing premise
The LLM-based multi-signal judge produces reliable hardness labels that align with actual human-perceived difficulty and domain knowledge requirements.
What would settle it
If a controlled human study finds that translators rate HardMTBench sentences as no harder on average than FLORES-200 sentences, or if the GEMBA range across the same 22 systems stays comparable to the 7.87-point FLORES spread, the benchmark's diagnostic advantage would not hold.
Figures




read the original abstract
General-purpose machine translation benchmarks such as FLORES-200 have reached a saturation regime on Chinese-English pairs, where modern large language models cluster within a narrow band of high scores. Across 22 systems, FLORES-200 zh-en GEMBA scores fall in a 7.87-point range with a standard deviation of 2.29, which compresses the separation between systems on knowledge-intensive domains such as finance, healthcare, law, and science and technology. We introduce HardMTBench, a difficulty-aware diagnostic benchmark for bidirectional Chinese-English domain translation. HardMTBench covers 12 domains and contains 10,000 hand-curated source sentences with reference translations, packaged as 20,000 directional test items. A three-stage construction pipeline builds a domain-balanced candidate pool of 84{,}566 pairs, applies an LLM-based multi-signal judge over knowledge density, translation difficulty, terminology load and reference correctness, and assembles the final test set under a hardness fusion rule with per-domain quotas. Across 22 systems spanning general LLMs, commercial engines and specialised MT models, HardMTBench widens the cross-system GEMBA range by roughly a factor of two over FLORES-200, induces visible rank reorderings, and exposes domain-specific terminology and knowledge weaknesses that quality-only metrics tend to flatten. All data and code are open-sourced at https://github.com/jasonNLP/HardMTBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HardMTBench, a difficulty-aware benchmark for bidirectional Chinese-English translation across 12 knowledge-intensive domains (finance, healthcare, law, science/technology). It constructs a 10k-sentence test set (20k directional items) from an 84k-pair candidate pool via a three-stage pipeline that applies an LLM-based multi-signal judge (knowledge density, translation difficulty, terminology load, reference correctness) followed by a hardness fusion rule with per-domain quotas. Across 22 systems, HardMTBench widens the GEMBA score range by roughly 2x relative to FLORES-200 (from 7.87 to ~15.7 points) and induces rank reorderings that expose domain-specific terminology and knowledge gaps.
Significance. If the hardness selection is reliable, HardMTBench would address saturation in general-purpose MT benchmarks by providing better discrimination on specialized domains. The open-sourcing of the full dataset, code, and construction pipeline at the cited GitHub repository is a clear strength that enables direct reproducibility and further analysis.
major comments (2)
- [Abstract and §3] Abstract and §3 (construction pipeline): The central claim that HardMTBench exposes genuine domain-knowledge weaknesses rests on the LLM multi-signal judge producing valid hardness labels, yet no human-LLM correlation, inter-annotator agreement, or ablation against expert difficulty ratings is reported. This is load-bearing because the 10k selected items are chosen precisely on the basis of those fused signals.
- [Abstract and results section] Abstract and results section: The reported widening of the GEMBA range (factor of two) and rank reorderings are presented as evidence of improved stress-testing, but without an explicit statement of the exact hardness fusion formula (how the four signals are combined) or the per-domain quota enforcement details, it is impossible to verify that the selection rule actually prioritizes knowledge density over surface-level LLM-detectable features.
minor comments (2)
- [Abstract] Abstract: The precise numerical values for the expanded GEMBA range and standard deviation on HardMTBench should be stated explicitly rather than described as 'roughly a factor of two'.
- [Results] The paper would benefit from a small table in the results section listing the 22 systems by category (general LLMs, commercial, specialized MT) to clarify the scope of the rank-reordering claim.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback on the construction pipeline and evaluation claims. We address each major comment below and will incorporate clarifications and additional analyses in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (construction pipeline): The central claim that HardMTBench exposes genuine domain-knowledge weaknesses rests on the LLM multi-signal judge producing valid hardness labels, yet no human-LLM correlation, inter-annotator agreement, or ablation against expert difficulty ratings is reported. This is load-bearing because the 10k selected items are chosen precisely on the basis of those fused signals.
Authors: We agree that the absence of human validation for the LLM multi-signal judge is a limitation of the current manuscript. The paper describes the four signals (knowledge density, translation difficulty, terminology load, reference correctness) and the fusion process in §3 but does not report correlation with expert human judgments. In the revision we will add a new subsection with (i) inter-annotator agreement on a 500-sentence sample rated by two domain experts and (ii) Pearson/Spearman correlation between the LLM judge scores and the expert ratings. This will directly address the load-bearing concern. revision: yes
-
Referee: [Abstract and results section] Abstract and results section: The reported widening of the GEMBA range (factor of two) and rank reorderings are presented as evidence of improved stress-testing, but without an explicit statement of the exact hardness fusion formula (how the four signals are combined) or the per-domain quota enforcement details, it is impossible to verify that the selection rule actually prioritizes knowledge density over surface-level LLM-detectable features.
Authors: We acknowledge that the exact fusion formula and quota mechanics were described at a high level in §3 rather than with full mathematical precision. The manuscript states that a hardness fusion rule with per-domain quotas is applied, but does not give the closed-form expression or the exact quota allocation algorithm. In the revision we will expand §3 to include (a) the precise weighted-sum or ranking-based fusion equation combining the four normalized signals and (b) the explicit per-domain quota enforcement procedure (including how ties and overflow are handled). This will allow readers to reproduce the selection logic exactly. revision: yes
Circularity Check
No circularity: benchmark selection and empirical evaluation are independent of any self-referential derivation
full rationale
The paper constructs HardMTBench via a three-stage pipeline that applies an LLM multi-signal judge to select sentences, then reports empirical results (widened GEMBA range, rank reorderings) by evaluating 22 external systems on the resulting test set. No equations, fitted parameters, or uniqueness theorems are present. The construction pipeline does not reduce to its own outputs by definition, nor does any central claim rely on self-citation chains or renaming of prior results. The LLM judge is an external methodological tool whose reliability is an open question of validation (human correlation), not a circularity in the derivation sense. The reported performance deltas are measured against independent systems and metrics, making the chain self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM-based multi-signal judge accurately measures knowledge density, translation difficulty, terminology load and reference correctness
Reference graph
Works this paper leans on
-
[1]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-V3.2: Pushing the frontier of open large language models.Preprint, arXiv:2512.02556. DeepSeek-V4-Pro variants ac- cessed via the official DeepSeek API. Daniel Deutsch, Eleftheria Briakou, Isaac Caswell, Mara Finkelstein, Rebecca Galor, Juraj Juraska, Geza Kovacs, Alison Lui, Ricardo Rei, Jason Riesa, Shruti Rijhwani, Parker Riley, Elizabeth Sales...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
WMT24++: Expanding the language coverage of WMT24 to 55 languages & dialects. Preprint, arXiv:2502.12404. Georgiana Dinu, Prashant Mathur, Marcello Federico, and Yaser Al-Onaizan
-
[3]
Are LLMs breaking MT met- rics? results of the WMT24 metrics shared task. In Proceedings of the Ninth Conference on Machine Translation (WMT). Google DeepMind. 2025a. Gemini 3 Pro model card. Google DeepMind model card. Accessed via the official Gemini API. No standalone arXiv technical report is available; this entry references the public model card and ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Translation as a scalable proxy for multilingual evaluation.CoRR, abs/2601.11778. Tom Kocmi, Eleftherios Avramidis, Rachel Bawden, Ondˇrej Bojar, Anton Dvorkovich, Christian Fed- ermann, Mark Fishel, Markus Freitag, Thamme Gowda, Roman Grundkiewicz, Barry Haddow, Philipp Koehn, Benjamin Marie, Christof Monz, Makoto Morishita, Kenton Murray, Makoto Nagata,...
-
[5]
InProceedings of the Eighth Conference on Ma- chine Translation (WMT), pages 1–42
Findings of the 2023 conference on machine trans- lation (WMT23): LLMs are here but not quite there yet. InProceedings of the Eighth Conference on Ma- chine Translation (WMT), pages 1–42. Association for Computational Linguistics. Tom Kocmi, Eleftherios Avramidis, Rachel Bawden, Ondˇrej Bojar, Anton Dvorkovich, Christian Feder- mann, Mark Fishel, Markus F...
2023
-
[6]
InPro- ceedings of the 2018 Conference on Empirical Meth- ods in Natural Language Processing, pages 543–553
MTNT: A testbed for machine translation of noisy text. InPro- ceedings of the 2018 Conference on Empirical Meth- ods in Natural Language Processing, pages 543–553. Mariana Neves, Antonio Jimeno Yepes, Amy Siu, Roland Roller, and Philippe Thomas
2018
-
[7]
InProceedings of the Seventh Conference on Machine Translation
Findings of the WMT 2022 biomedical translation shared task: Monolingual clinical case reports. InProceedings of the Seventh Conference on Machine Translation. OpenAI
2022
-
[8]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card. Preprint, arXiv:2508.10925. OpenAI
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
OpenAI GPT-5 system card.Preprint, arXiv:2601.03267. GPT-5.5 variants accessed via the official OpenAI API. Finn Schmidt, Jan Philip Wahle, Terry Ruas, and Bela Gipp
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Who Watches the Watchmen? Humans Disagree With Translation Metrics on Unseen Domains
Who watches the watchmen? humans disagree with translation metrics on unseen domains. CoRR, abs/2604.17393. Chihiro Taguchi, Seng Mai, Keita Kurabe, Yusuke Sakai, Georgina Agyei, Soudabeh Eslami, and David Chi- ang
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Languages still left behind: Toward a better multilingual machine translation benchmark. CoRR, abs/2508.20511. NLLB Team, Marta R. Costa-jussà, James Cross, Onur Çelebi, Maha Elbayad, Kenneth Heafield, Kevin Hef- fernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, Anna Sun, Skyler Wang, Guillaume Wenzek, Al Youngblood, Bapi Akula, Loic Barrau...
-
[12]
No Language Left Behind: Scaling Human-Centered Machine Translation
No language left behind: Scaling human-centered machine translation.arXiv preprint arXiv:2207.04672. Madison Van Doren, Casey Ford, Jennifer Barajas, and Cory Holland
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
"Be My Cheese?": Cultural Nuance Benchmarking for Machine Translation in Multilingual LLMs
“be my cheese?”: Cultural nuance benchmarking for machine translation in mul- tilingual LLMs.CoRR, abs/2602.04729. Longyue Wang, Siyou Liu, Chenyang Lyu, Wenxiang Jiao, Xing Wang, Jiahao Xu, Zhaopeng Tu, Yan Gu, Weiyu Chen, Minghao Wu, Liting Zhou, Philipp Koehn, Andy Way, and Yulin Yuan
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
InProceedings of the Ninth Con- ference on Machine Translation (WMT)
Find- ings of the WMT 2024 shared task on discourse-level literary translation. InProceedings of the Ninth Con- ference on Machine Translation (WMT). An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others
2024
-
[15]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Hongjian Yu, Yiming Shi, Zherui Zhou, and Christopher Haberland
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Machine translation evaluation benchmark for Wu Chinese: Workflow and analysis. CoRR, abs/2410.10278. Kaiyan Zhao, Zheyong Xie, Zhongtao Miao, Xinze Lyu, Yao Hu, and Shaosheng Cao
-
[17]
Benchmarking machine translation on Chinese social media texts. CoRR, abs/2601.22931. Mao Zheng, Zheng Li, Tao Chen, Bo Lv, Mingrui Sun, Mingyang Song, Jinlong Song, Hong Huang, Decheng Wu, Hai Wang, Yifan Song, Yanfeng Chen, and Guanwei Zhang
-
[18]
Hy-mt2: A family of fast, efficient and powerful multilingual translation models in the wild.Preprint, arXiv:2605.22064
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.