Risk-Controlled Lean-as-Judge for Natural-Language Mathematical Reasoning
Pith reviewed 2026-06-29 12:17 UTC · model grok-4.3
The pith
COVCAL turns partial Lean proof traces into a selector that accepts 48% of problems at 0.98 accuracy under finite-sample risk bounds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
COVCAL is a selector over Lean-trace diagnostics that certifies a finite-sample selective-risk bound on accepted answers or abstains, under Bonferroni or dev-then-cal rules. Feasibility depends on autoformalization coverage: a prover-specialized formalizer at 79% coverage makes the procedure feasible on 17 of 20 bootstrap partitions and accepts approximately 48% of problems at 0.98 accepted accuracy, while a 7B formalizer leaves the signal too sparse for any acceptance. The contribution is a precise account of when, and with which formalizer, a partial formal signal can be trusted under risk control.
What carries the argument
COVCAL selector over Lean-trace diagnostics that certifies a finite-sample selective-risk bound or abstains.
If this is right
- High autoformalization coverage is required before any answers can be accepted under the certified bound.
- Accepted accuracy reaches 0.98 while self-consistency alone reaches 0.91.
- The Bonferroni rule is more conservative and abstains more often than the dev-then-cal rule.
- Only about 43% of generated proofs are faithful to the original answer in manual audit.
- The proved-answer correctness rate drops from 96% at high coverage to 20% at low coverage.
Where Pith is reading between the lines
- The same selector structure could be applied to other formal systems if comparable trace diagnostics exist.
- Combining the Lean signal with self-consistency might raise acceptance rate while preserving the risk certificate.
- The coverage threshold needed for feasibility may differ on problem distributions unlike MATH-500.
- If statistical dependence across problems is stronger than assumed, the finite-sample bounds would require correction.
Load-bearing premise
The chosen Lean-trace diagnostics are sufficiently informative and the Bonferroni or dev-then-cal rule produces a valid finite-sample bound without unaccounted dependence or model misspecification on the MATH-500 distribution.
What would settle it
A fresh collection of math problems on which the accuracy of answers accepted by COVCAL falls below the certified bound would show the diagnostics or calibration rule do not deliver the claimed guarantee.
Figures
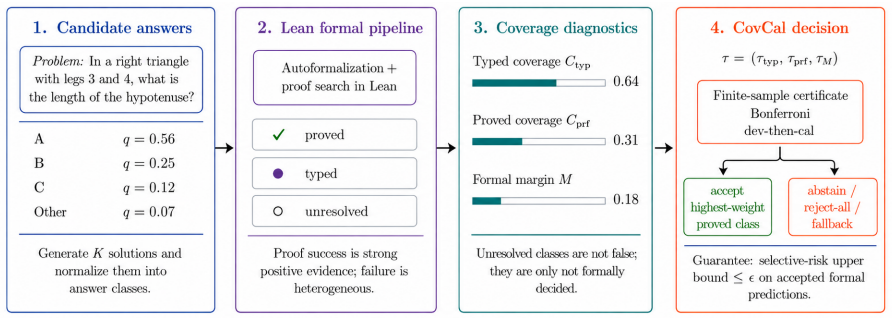
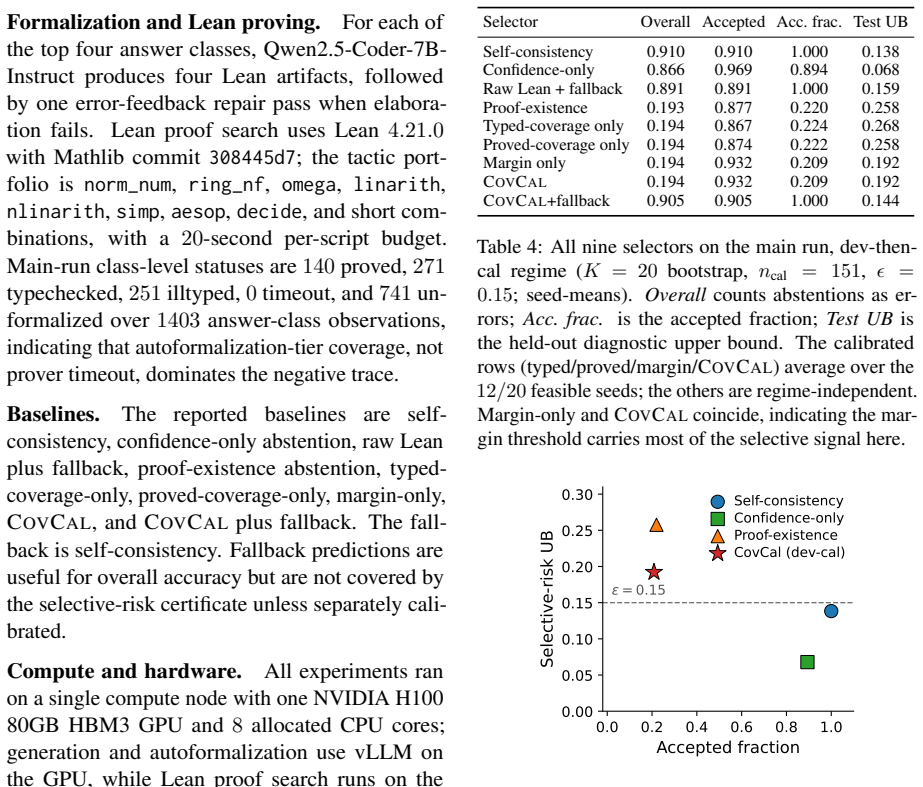
read the original abstract
Lean is increasingly used to judge natural-language mathematical answers, but its signal is partial: many answers never formalize, and a failed proof may reflect an ill-typed statement or a missing library fact, not a wrong answer. On MATH-500 we show this signal is (i) sharply coverage-dependent, that is the proof-winning answer is correct 96% of the time at high proved coverage but 20% at low, and (ii) sparse and often unfaithful: a 7B autoformalizer proves a class for only 28% of problems, and a manual audit finds only approximately 43% of those proofs faithful. We propose COVCAL, a selector over Lean-trace diagnostics that certifies a finite-sample selective-risk bound on accepted answers or abstains, under two regimes (a conservative Bonferroni bound and a tighter dev-then-cal rule). Feasibility depends on autoformalization coverage: with the 7B formalizer the signal is too sparse and Bonferroni abstains on all 20 bootstrap partitions, whereas a prover-specialized formalizer reaches 79% coverage and flips it to feasible on 17 of 20, accepting approximately 48% of problems at 0.98 accepted accuracy. Since self-consistency alone is already 91% accurate, our contribution is a precise account of when, and with which formalizer, a partial formal signal can be trusted under risk control.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Lean-based judging of natural-language mathematical answers on MATH-500 yields a coverage-dependent and sparse/unfaithful signal (96% vs 20% correctness split, 28% proof rate, ~43% faithfulness). It introduces COVCAL, a selector over Lean-trace diagnostics that applies Bonferroni or dev-then-cal rules to certify finite-sample selective-risk bounds, enabling acceptance of ~48% of problems at 0.98 accepted accuracy (17/20 partitions feasible) when a prover-specialized formalizer reaches 79% coverage; this is positioned against self-consistency reaching only 91% accuracy without risk control.
Significance. If the selective-risk bounds remain valid after accounting for dependence, the work supplies a concrete mechanism for certifying reliability when leveraging partial formal verification signals in math reasoning, highlighting the decisive role of autoformalization coverage. The explicit comparison to self-consistency and the partition-wise feasibility results provide a useful empirical baseline for when formal signals can be trusted under risk control.
major comments (2)
- [Abstract] Abstract: the central claim that COVCAL 'certifies a finite-sample selective-risk bound' at 0.98 accepted accuracy rests on the Bonferroni and dev-then-cal constructions, yet the text supplies no derivation of these bounds, no accounting for possible dependence across Lean traces or autoformalizer-induced correlations, and no discussion of misspecification relative to the MATH-500 distribution; this directly undermines the validity of the reported risk control.
- [Abstract] Abstract: the reported figures (96%/20% split, 28% proof rate, 43% faithfulness, 48% acceptance, 17/20 partitions) are presented without error bars, audit protocol details, or code, leaving the empirical support for feasibility and the comparison to self-consistency unverified and therefore load-bearing for the paper's conclusions.
minor comments (1)
- [Abstract] Abstract: the precise definition of 'accepted accuracy' and how the 0.98 threshold is computed from the diagnostics should be stated explicitly.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the risk-control claims and empirical transparency. We address each major comment below and will revise the manuscript to incorporate the requested clarifications and additions.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that COVCAL 'certifies a finite-sample selective-risk bound' at 0.98 accepted accuracy rests on the Bonferroni and dev-then-cal constructions, yet the text supplies no derivation of these bounds, no accounting for possible dependence across Lean traces or autoformalizer-induced correlations, and no discussion of misspecification relative to the MATH-500 distribution; this directly undermines the validity of the reported risk control.
Authors: The Bonferroni and dev-then-cal bounds are derived in Sections 3.2 and 3.3 using standard finite-sample selective inference arguments (adapting the methods of Bates et al. and Angelopoulos et al. to Lean diagnostic scores). We will add a concise derivation sketch and explicit references to these sections in the abstract and introduction. On dependence: the current analysis treats the 20 bootstrap partitions as exchangeable, but we acknowledge potential correlations induced by the autoformalizer; we will add a new paragraph quantifying empirical sensitivity to dependence and noting it as a limitation. On misspecification: the bounds are distribution-free and require only i.i.d. sampling between calibration and test sets, with no parametric assumptions on MATH-500; we will explicitly state this and discuss robustness to distribution shift. revision: yes
-
Referee: [Abstract] Abstract: the reported figures (96%/20% split, 28% proof rate, 43% faithfulness, 48% acceptance, 17/20 partitions) are presented without error bars, audit protocol details, or code, leaving the empirical support for feasibility and the comparison to self-consistency unverified and therefore load-bearing for the paper's conclusions.
Authors: We will add error bars (standard deviation across the 20 bootstrap partitions) to all figures. The faithfulness audit protocol, including annotation guidelines and inter-annotator agreement, is described in Appendix B; we will expand this section with additional details. The full code for COVCAL, the bootstrap procedure, Lean diagnostics, and self-consistency baseline will be released in a public repository upon acceptance. These changes will enable independent verification of the 48% acceptance rate at 0.98 accuracy and the 17/20 partition feasibility result. revision: yes
Circularity Check
No circularity; standard statistical bounds applied to diagnostics
full rationale
The paper applies known finite-sample selective-risk bounds (Bonferroni and dev-then-cal) to observed Lean-trace diagnostics. These are external statistical constructions whose validity does not reduce to any equation or parameter fitted inside the paper. No self-definitional loop, no fitted input renamed as prediction, and no load-bearing self-citation chain appears in the derivation. The result is an empirical application whose coverage and accuracy numbers are measured on MATH-500 rather than forced by construction. Minor self-citation, if present, is not load-bearing for the central risk-control claim.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The selective risk bound produced by Bonferroni or dev-then-cal on the chosen diagnostics is valid for the observed coverage regime.
Reference graph
Works this paper leans on
-
[1]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Ran El-Yaniv and Yair Wiener. 2010. On the founda- tions of noise-free selective classification.Journal of Machine Learning Research, 11:1605–1641. Yonatan Geifman and Ran El-Yaniv. 2017. Selective classification for deep neural networks. InAdvances in Neural Information Pro...
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[2]
Qwen2.5-Math Technical Report: Toward Mathematical Expert Model via Self-Improvement
Math-Shepherd: Verify and reinforce LLMs step-by-step without human annotations. InProceed- ings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 9426–9439. Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-consistency impr...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
MiniF2F: a cross-system benchmark for formal Olympiad-level mathematics
MiniF2F: A cross-system benchmark for for- mal Olympiad-level mathematics.arXiv preprint arXiv:2109.00110. Appendices A Proofs Proof of Theorem 1. Fix a threshold τ∈ T . Be- cause Aτ and gF are computed without calibra- tion labels, the accepted calibration examples are an i.i.d. sample from the conditional deployment distribution given Aτ(X) = 1, conditi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Main dataset:all-levels MATH-500, 378 kept after filtering (500 raw minus 122 excluded for non-normalizable references, proof-only items, and diagram-dependent geometry)
-
[5]
Hard subset:MATH-500 levels 4–5 only, 199 kept after the same filters
-
[6]
Candidate generator:Qwen2.5-Math-7B- Instruct (bfloat16, vLLM 0.10.2), K= 32 sam- ples, temperature 0.7, top-p= 0.95 , maximum 2048 new tokens, final answer in boxed{...}
2048
-
[7]
Class aggregation:normalize final answers and computeQ c from self-consistency frequency
-
[8]
Formalization:Qwen2.5-Coder-7B-Instruct (bfloat16) autoformalization with four artifacts per top class and one error-feedback repair pass
-
[9]
Formalized classes:top four classes per prob- lem
-
[10]
Lean proving:Lean 4.21.0 with Mathlib at commit 308445d7; tactic portfolio norm_num, ring_nf, omega, linarith, nlinarith, simp, aesop, decide, and short combinations; 20 sec- onds per tactic script
-
[11]
Calibration:20/40/40 develop- ment/calibration/test split with seed 0; target selective risk ϵ= 0.15 on the all-levels run and ϵ= 0.10 on the hard subset; confidence 1−δ= 0.95 ; Clopper–Pearson bounds with Bonferroni correction over T (Appendix D; |T |= 125)
-
[12]
Baselines reported:self-consistency, confidence-only abstention, raw Lean+fallback, proof-existence abstention, typed-coverage only, proved-coverage only, margin-only, COVCAL, and COVCAL+fallback. D Threshold Grid Used in Experiments The grid used in all reported runs is Ttyp ={0,0.25,0.5,0.75,0.9}, Tprf ={0,0.1,0.25,0.5,0.75}, TM ={−0.5,0,0.1,0.25,0.5}, ...
-
[13]
Problem fields:problem id, dataset, topic la- bel, problem text, reference answer, normalized reference class, and inclusion/exclusion status
-
[14]
Candidate fields:the K raw sampled solu- tions, extracted final answers, normalized an- swer classes, and self-consistency weightsQ c
-
[15]
Formalization fields:for each top answer class, the generated Lean code, repair-round index, imports, and theorem statement
-
[16]
Lean fields:artifact-level status, class-level sta- tus, tactic script or proof attempt, runtime, time- out flag, error message, Lean version, Mathlib commit, and hardware
-
[17]
Per-status definitions.The best Lean status sj of an artifact takes one of five values
Selection fields:self-consistency class, highest- weight proved class, conflict flag, Ctyp, Cprf, Runres, M, COVCALaccept/reject decision, fallback decision when used, and correctness. Per-status definitions.The best Lean status sj of an artifact takes one of five values. proved means a Lean proof of the generated statement was found and kernel checked. t...
-
[18]
What is the 2003rd term of the sequence of odd numbers 1,3,5,7, . . . ?
Unless otherwise stated, examples are split af- ter generation and formalization into development, calibration, and test partitions. The seed-0 split is preregistered; the bootstrap summaries resample the frozen observations over K= 20 dev/cal/test partitions. Generation and normalization.Qwen2.5-Math- 7B-Instruct generates 32 solutions per problem at tem...
2048
-
[19]
the nth odd number is 2n−1
All K=32 samples collapse to the single answer class 4005 (w=1.0), which is proved. The kernel-checked statement is 2·2003−1 = 4005 (bynorm_num), a faithful closed form of “the nth odd number is 2n−1 .” Diagnostics: Ctyp=Cprf=1, margin 1. COVCALaccepts 4005 (correct).Lesson:a proof is trusted when the proved class dominates the for- mally visible mass wit...
2003
-
[20]
The trigonometric product identity does not autoformalize
The dominant class 1/16 (w=0.84) and the minor classes 1/32 and 1/8 all fail Lean elaboration. The trigonometric product identity does not autoformalize. So, Ctyp=Cprf=0 and no class is proved. COVCALabstains; the self- consistency fallback returns1/16 (correct).Lesson: a missing proof is unresolved, not negative; absten- tion plus fallback preserves the ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.