CyberJurors: A Multi-Agent Simulation Task for E-Commerce Disputes Verdict
Pith reviewed 2026-06-29 12:15 UTC · model grok-4.3
The pith
A multi-agent framework decomposes e-commerce dispute evidence into four reasoning stages then simulates jury discussion and voting to match real crowdsourced verdicts more closely than single LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
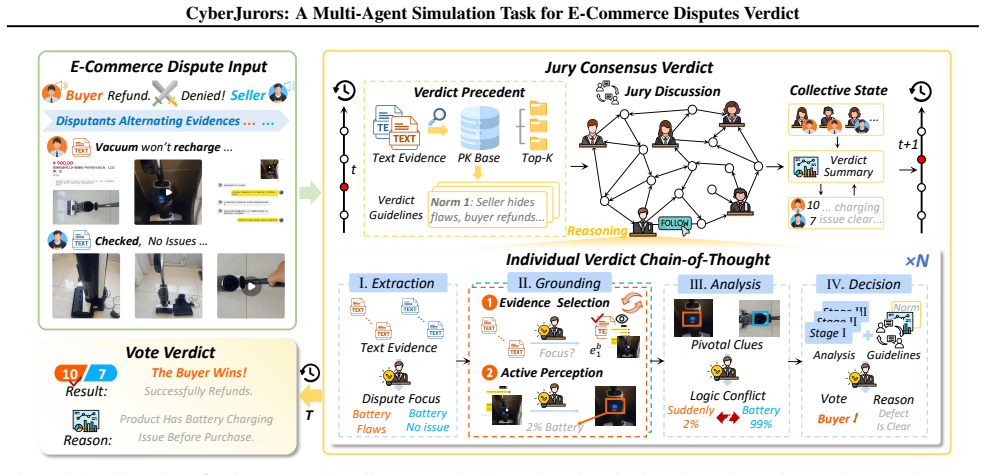
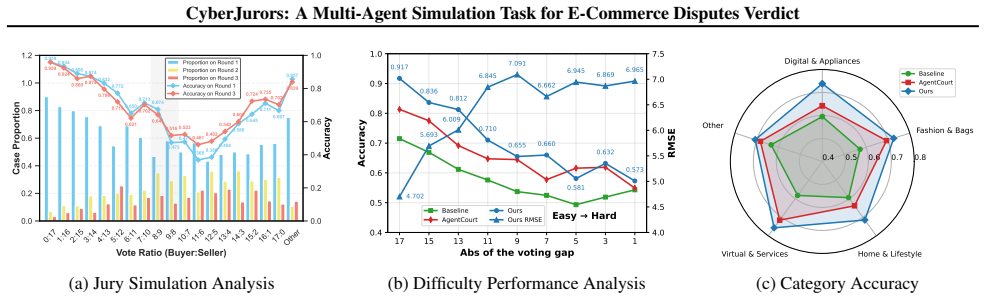
CyberJurors clarifies dispute logic through four-stage Individual Verdict Chain-of-Thought for fine-grained clue perception and causal links, then regulates outcomes via Jury Consensus Verdict that runs simulated multi-round discussion and incorporates precedents to reduce bias toward either party, producing verdicts on VerdictBench that exceed those of state-of-the-art models and match real-world jury patterns more closely.
What carries the argument
Individual Verdict Chain-of-Thought that decomposes the task into four reasoning stages plus Jury Consensus Verdict that simulates discussion and precedent use among multiple agents.
Load-bearing premise
The 6000 cases and the real jury voting patterns used for comparison represent the full range of e-commerce disputes without the four-stage process creating artificial alignment that fits only this benchmark.
What would settle it
Running CyberJurors on a fresh collection of e-commerce disputes drawn from a different platform or later time period and measuring whether its alignment with actual jury votes remains as strong as on VerdictBench.
Figures


read the original abstract
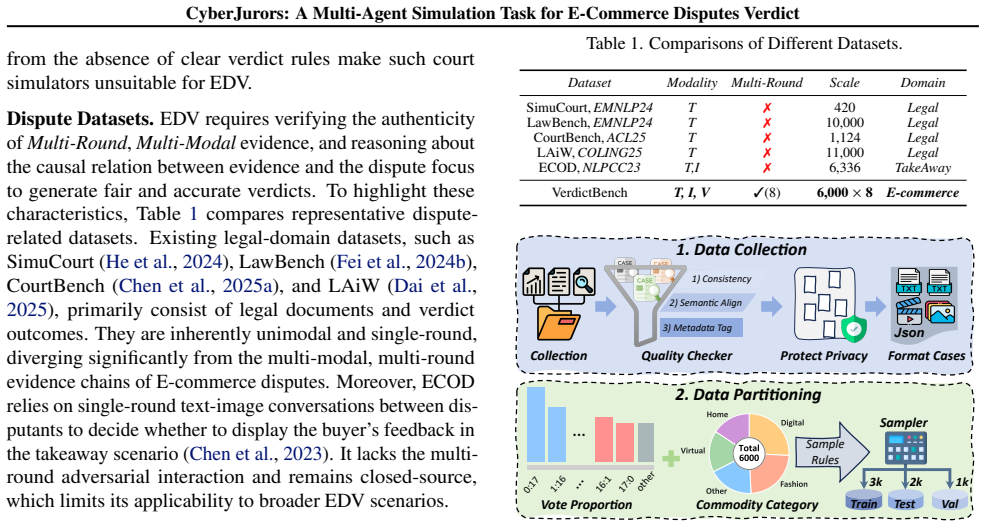
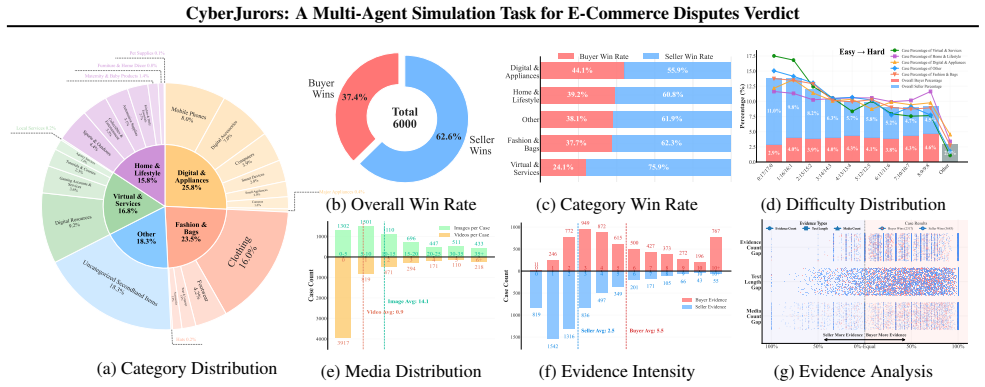
E-commerce platforms have begun recruiting crowdsourced jurors to adjudicate massive volumes of transaction disputes. Unlike formal legal judgment, E-commerce dispute verdicts require grounding pivotal clues from redundant, multi-round, multimodal evidence and making decisions under flexible platform-specific conventions. These characteristics render existing methods insufficient for this scenario. To bridge this gap, we introduce a pioneering task, E-commerce Dispute Verdicts (EDV), and present VerdictBench, a multimodal benchmark comprising 6,000 real-world cases designed to reflect crowdsourced jury decisions. Building upon this, we propose CyberJurors, a multi-agent framework to clarify the dispute logic and regulate the verdict process. At the individual level, Individual Verdict Chain-of-Thought decomposes the EDV task into four structured reasoning stages, enabling fine-grained clue perception and clarifying causal logic between pivotal clues and the dispute focus. At the collective level, Jury Consensus Verdict simulates multi-round discussion and voting among jurors, while incorporating verdict precedents to mitigate cognitive biases toward either disputant. Experiments on VerdictBench show that CyberJurors outperforms state-of-the-art LLMs, MLLMs, and court simulators, while achieving stronger alignment with real-world jury voting patterns. Code and dataset are available at https://github.com/YanhuiS/CyberJurors and https://huggingface.co/datasets/piggi/VerdictBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the E-commerce Dispute Verdicts (EDV) task and VerdictBench, a multimodal benchmark of 6,000 real-world cases reflecting crowdsourced jury decisions. It proposes CyberJurors, a multi-agent framework consisting of Individual Verdict Chain-of-Thought (four structured reasoning stages for clue perception and causal logic under platform conventions) at the individual level and Jury Consensus Verdict (multi-round discussion, voting, and precedent incorporation) at the collective level. Experiments claim that CyberJurors outperforms state-of-the-art LLMs, MLLMs, and court simulators on VerdictBench while achieving stronger alignment with real-world jury voting patterns. Code and dataset are released.
Significance. If the empirical claims hold after validation, this work would provide a practical benchmark and multi-agent approach for high-volume e-commerce dispute resolution, addressing a gap where existing methods fail on multimodal evidence and flexible platform conventions. The open release of code and dataset strengthens reproducibility and enables follow-on work in multi-agent legal simulation.
major comments (2)
- [§2] §2 (VerdictBench construction): The 6,000 cases are described as chosen to reflect crowdsourced jury decisions, yet no details are given on selection criteria, annotation protocol, or hold-out procedures that would ensure independence from the 'platform-specific conventions' explicitly encoded in the four-stage Individual Verdict CoT (described in §3.1). This directly bears on the alignment claim, as any shared inductive bias between benchmark construction and the method could produce the reported stronger alignment without genuine generalization.
- [§4] §4 (Experiments and results): The central claims of outperformance over LLMs/MLLMs/simulators and stronger alignment with real jury patterns are asserted, but the manuscript provides no quantitative metrics (e.g., accuracy, agreement rate, Cohen's kappa), statistical tests, error bars, ablation results isolating the four-stage CoT or consensus voting, or baseline details. Without these, it is impossible to assess whether gains are load-bearing or attributable to the proposed framework.
minor comments (2)
- [§3] The abstract and §3 use terms like 'pivotal clues' and 'dispute focus' without a precise definition or example in the main text; adding a short illustrative case would improve clarity.
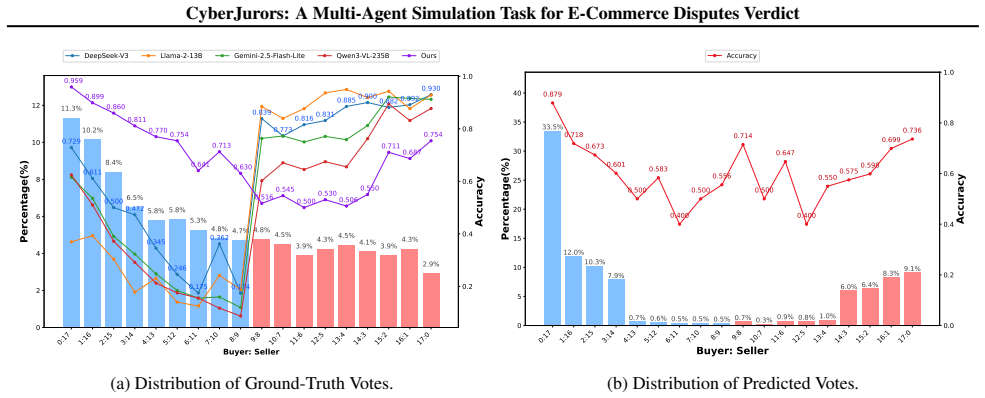
- [Figure 2] Figure 2 (framework overview) and Table 1 (results) would benefit from explicit axis labels and caption details on what 'alignment' metric is plotted.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on VerdictBench construction and experimental reporting. We will revise the manuscript to provide the requested details and metrics while preserving the core contributions of the EDV task, VerdictBench, and CyberJurors framework.
read point-by-point responses
-
Referee: [§2] §2 (VerdictBench construction): The 6,000 cases are described as chosen to reflect crowdsourced jury decisions, yet no details are given on selection criteria, annotation protocol, or hold-out procedures that would ensure independence from the 'platform-specific conventions' explicitly encoded in the four-stage Individual Verdict CoT (described in §3.1). This directly bears on the alignment claim, as any shared inductive bias between benchmark construction and the method could produce the reported stronger alignment without genuine generalization.
Authors: We agree that additional transparency is needed. In the revised manuscript, we will expand §2 with a new subsection detailing: (1) the platform data sourcing and filtering criteria to select cases reflecting actual jury verdicts; (2) the expert annotation protocol, including how multimodal evidence was labeled for pivotal clues and platform conventions; and (3) the train/test/hold-out splits with explicit measures to avoid leakage. On the inductive bias concern, the four-stage CoT encodes general EDV reasoning patterns derived from the task definition rather than case-specific memorization; the benchmark cases are real, unseen disputes independent of any model training data. We will also report inter-annotator agreement to support the alignment claims. revision: yes
-
Referee: [§4] §4 (Experiments and results): The central claims of outperformance over LLMs/MLLMs/simulators and stronger alignment with real jury patterns are asserted, but the manuscript provides no quantitative metrics (e.g., accuracy, agreement rate, Cohen's kappa), statistical tests, error bars, ablation results isolating the four-stage CoT or consensus voting, or baseline details. Without these, it is impossible to assess whether gains are load-bearing or attributable to the proposed framework.
Authors: We acknowledge the need for fuller quantitative reporting. The revised §4 will include: comprehensive tables with accuracy, agreement rate, Cohen's kappa, and other metrics comparing CyberJurors against all baselines; results of statistical significance tests (e.g., paired t-tests or McNemar's test); error bars from multiple random seeds; and ablation studies that isolate the contribution of each CoT stage and the jury consensus mechanism. Expanded baseline descriptions (including implementation details for LLMs, MLLMs, and simulators) will also be added. These additions will substantiate the outperformance and alignment claims. revision: yes
Circularity Check
No circularity: benchmark from external real cases, method independent of evaluation data
full rationale
The derivation introduces an external real-world benchmark (VerdictBench of 6000 cases reflecting crowdsourced jury decisions) and a new multi-agent framework whose four-stage CoT and consensus voting are defined by the authors without reference to fitted parameters or self-citations that would force the reported alignment or outperformance. Alignment is claimed against real-world jury patterns treated as external ground truth, and no equations or construction steps reduce the results to the inputs by definition. The central claims therefore remain independently testable on the released dataset.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Large language models can perform fine-grained clue perception and causal reasoning over redundant multimodal evidence when given structured stage prompts.
- domain assumption Simulated multi-round discussion and voting among agents, augmented by verdict precedents, produces outputs that align with real crowdsourced jury behavior.
Forward citations
Cited by 1 Pith paper
-
Modeling U.S. Attitudes Toward China via an Event-Steered Multi-Agent Simulator
ES-MAS combines a new CURE dataset of 258 events and 14,000 news items with dual-stream integration and localized interaction modules to simulate opinion dynamics and claims better reproduction of historical U.S.-Chin...
Reference graph
Works this paper leans on
-
[1]
What are the buyer’s core demands?
-
[2]
What are the seller’s core demands?
-
[3]
buyer core claim
What is the focus of the dispute between the disputants? Return format: ‘‘‘json { "buyer core claim":". . .", "seller core claim":". . .", "dispute focus":". . .", } ‘‘‘ E.4. The prompt for selecting evidence in stage II is as follows: Prompt E.4: Prompt for IV-CoT in stage II to select evidence You are analyzing the case from the perspective of [{perspec...
-
[4]
Carefully observe the key details in the picture/video
-
[5]
Return the path to the picture or video frame that contains the key information
-
[6]
Describe why the media is beneficial to [{perspective}]
-
[7]
visual findings
Assess the strength of the evidence Return format: ‘‘‘json { "visual findings":[ { "media type":"image/video", "media index": 0, "timestamp":"00:05", "description":". . .", "benefit analysis":"why it is beneficial to [{perspective}]", "importance":". . .", } ], "evidence summary":". . .", "support strength":". . .", "is sufficient":"true/false", "sufficie...
-
[8]
**Root cause analysis of disputes**: 21 CyberJurors: A Multi-Agent Simulation Task for E-Commerce Disputes Verdict - What is the root cause of this dispute? - Is it a product quality issue, a description mismatch, a service issue, or something else?
-
[9]
**Buyer’s Dispute Position**: - Why is the buyer dissatisfied? What are the specific demands? - Does the buyer provide evidence (text + visual) to support their claims? - What are the strengths and weaknesses of the buyer’s claim?
-
[10]
**Seller’s Dispute Position**: - What is the seller’s justification? - Does the seller provide evidence (text + visual) to support its defense? - What are the strengths and weaknesses of the seller’s claim?
-
[11]
dispute root cause
**Conflict Focus**: - Where is the core point of disagreement between the two sides? - Are there any contradictions in the evidence from both sides? - What key information can be seen from visual evidence? Return format: ‘‘‘json { "dispute root cause":"root cause for dispute", "buyer position":{ "main complaint":". . .", "demands": . . . , "key evidence":...
-
[12]
Key arguments and perspectives mentioned by the commenters
-
[13]
An assessment of whether there is a heated or intense debate
-
[14]
Case Details:{content} New Juror Arguments:{comment} Previous Report :{mf text} E.9
The current prevailing orientation of public opinion (who is being supported). Case Details:{content} New Juror Arguments:{comment} Previous Report :{mf text} E.9. The prompt for generating verdict guidelines in the Precedent Base Construction is as follows: Prompt E.9: Prompt for generating verdict guidelines You are a senior E-commerce dispute analyst. ...
-
[15]
Rules should be universal judgment standards for a category of issues, rather than case-specific details, and must be concise and refined
-
[16]
For example: ”When a product has significant undisclosed defects, ’non-returnable’ clauses are generally invalid.”
Rules should be stated from a third-party perspective. For example: ”When a product has significant undisclosed defects, ’non-returnable’ clauses are generally invalid.”
-
[17]
The output must be in JSON format and contain only one reflection result field, with its value being an array of 2 to 4 strings. E.10. The prompt for assigning metadata tags is as follows: Prompt E.10: Prompt for Metadata-Tag Based on the product information below, classify it into the most suitable subcategory. Product Information: ${product text} Option...
-
[18]
Return only the name of the most suitable subcategory (e.g., Mobile Phones, Computers, etc.)
-
[19]
You must select from the subcategories listed above; do not return a main category name
-
[20]
Do not include any explanations or additional text
-
[21]
If it cannot be classified into a specific subcategory, return ’Uncategorized Secondhand Items’. 25
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.