HRBench: Benchmarking and Understanding Thinking-Mode Switch Strategies in Hybrid-Reasoning LLMs
Pith reviewed 2026-06-29 12:01 UTC · model grok-4.3
The pith
Switching strategies in hybrid-reasoning LLMs occupy distinct regions of the effectiveness-efficiency trade-off space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
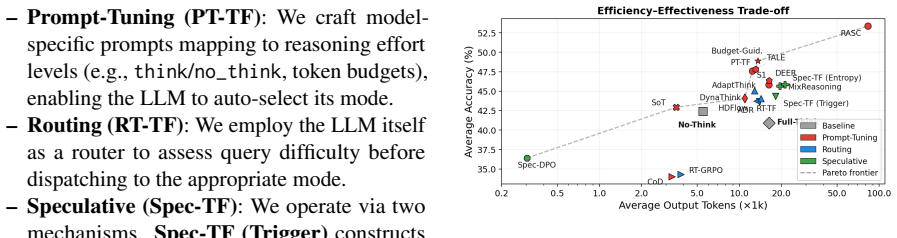
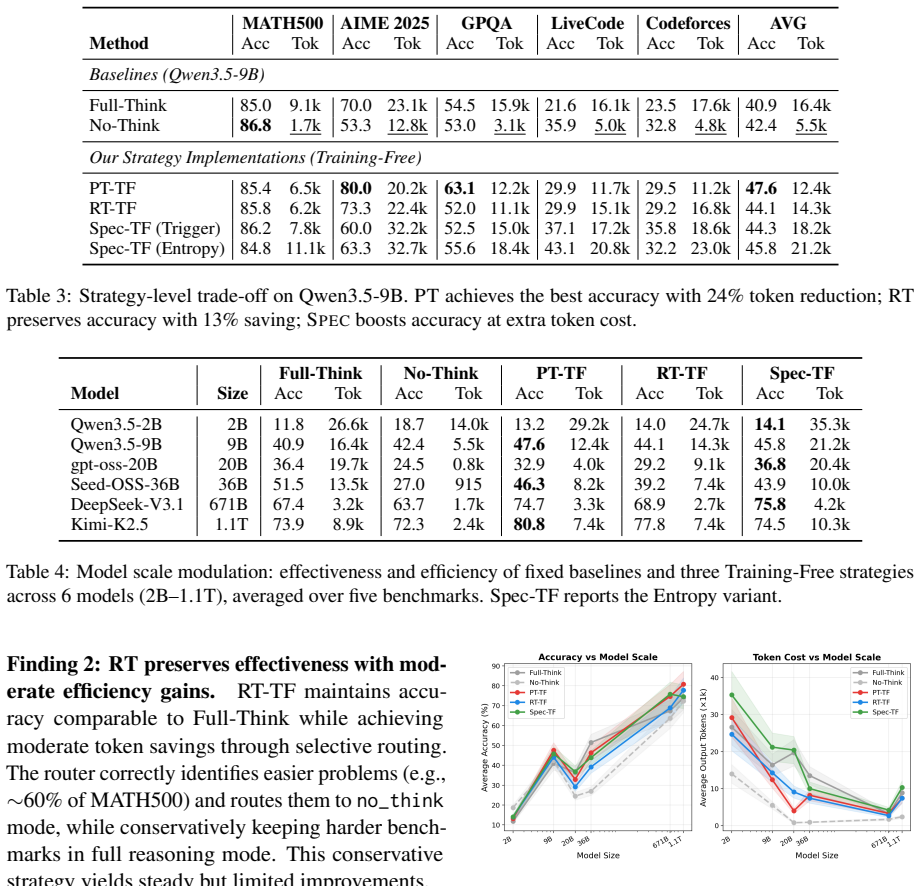
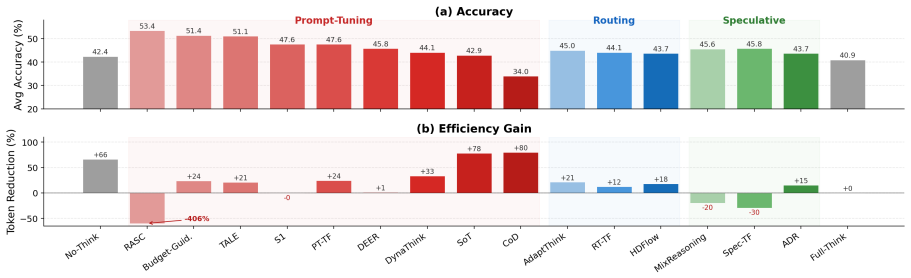
HRBench is a unified evaluation framework that organizes the design space along two axes: three switching strategy families (prompt-based selection, external routing, and speculative execution) and four training regimes (training-free, SFT, offline RL, and online RL), yielding 12 controlled settings. When 12+ prior methods are reimplemented inside the same pipeline and evaluated on six LLMs from 2B to 1.1T parameters and five benchmarks spanning mathematics, science, and code, the analysis shows that prompt-based methods often provide favorable token-accuracy trade-offs, routing methods offer more stable cost reduction, and speculative methods tend to improve accuracy at higher token cost. T
What carries the argument
HRBench, the benchmark framework that standardizes comparison of switching strategies by fixing model, data, and implementation variables across three strategy families and four training regimes.
If this is right
- Prompt-based methods are preferable when the goal is to maximize accuracy per additional token.
- Routing methods deliver more consistent cost savings across varying conditions.
- Speculative methods are appropriate when extra tokens can be spent to raise final accuracy.
- Training regime must be matched to the chosen switching family rather than applied uniformly.
- Strategy selection should be conditioned on both model scale and the target task domain.
Where Pith is reading between the lines
- Deployed systems could route queries to different switching families based on current token budget or latency target.
- The observed scale dependence suggests that very large models may require separate strategy tuning from smaller ones.
- Extending the benchmark to measure intra-generation switching decisions could reveal further efficiency gains.
- The domain variation implies that specialized benchmarks per task type would sharpen strategy recommendations.
Load-bearing premise
The reimplemented methods faithfully reproduce the behavior of the original papers and the six models plus five benchmarks cover the relevant space of hybrid-reasoning behavior without systematic bias from implementation choices or task selection.
What would settle it
An independent reimplementation of the same 12+ methods that produces substantially different trade-off regions, or evaluation on a new benchmark suite in which all three strategy families show nearly identical accuracy-cost curves.
Figures


read the original abstract
Hybrid-reasoning large language models (LLMs) expose explicit controls over reasoning effort, allowing users or systems to trade off answer quality against inference cost. However, existing methods for adaptive thinking-mode selection are typically evaluated under different models, datasets, and implementation assumptions, making it difficult to compare their practical behavior. We introduce HRBench, a unified evaluation framework for studying thinking-mode switching in hybrid-reasoning LLMs. HRBench organizes the design space along two axes: three switching strategy families, prompt-based selection, external routing, and speculative execution, and four training regimes, training-free, SFT, offline and online RL, yielding 12 controlled evaluation settings. We evaluate these settings across 6 LLMs, from Qwen3.5-2B to Kimi-K2.5-1.1T, and 5 reasoning benchmarks covering mathematics, science, and code, while reimplementing 12+ representative prior methods within the same pipeline. Our analysis characterizes how different switching strategies occupy distinct effectiveness-efficiency trade-off regions: prompt-based methods often provide favorable token-accuracy trade-offs, routing methods offer more stable cost reduction, and speculative methods tend to improve accuracy at higher token cost. We further find that training affects strategies differently, and that the preferred strategy varies with model scale and task domain. HRBench provides reference implementations and a unified evaluation platform to support more controlled research on efficient reasoning in hybrid-reasoning LLMs. Our data, code and repository are available at https://github.com/usail-hkust/HRBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HRBench, a unified evaluation framework for thinking-mode switching in hybrid-reasoning LLMs. It structures the space along three strategy families (prompt-based selection, external routing, speculative execution) and four training regimes (training-free, SFT, offline/online RL) for 12 controlled settings. The authors reimplement 12+ prior methods and evaluate them on 6 LLMs (Qwen3.5-2B to Kimi-K2.5-1.1T) across 5 reasoning benchmarks in mathematics, science, and code. The central empirical claim is that the families occupy distinct effectiveness-efficiency trade-off regions (prompt-based often favorable on token-accuracy, routing stable on cost reduction, speculative improving accuracy at higher token cost), with further interactions from training, model scale, and task domain. Reference implementations, data, and code are released.
Significance. If the reimplementations are faithful, the work supplies a controlled, multi-model, multi-domain comparison that clarifies practical trade-offs among switching strategies and their sensitivity to training and scale. The explicit release of code, data, and reference implementations is a concrete strength that supports reproducibility and follow-on research on efficient hybrid reasoning.
major comments (1)
- [Reimplementation and evaluation pipeline] Reimplementation section (and abstract claim on trade-off regions): The partitioning of the three strategy families into distinct effectiveness-efficiency regions rests on the fidelity of the 12+ reimplementations. The manuscript reports no side-by-side verification that the reimplemented baselines recover the performance numbers originally published for those methods on overlapping datasets or models; without such checks, the observed region assignments could be artifacts of prompt formatting, threshold choices, or decoding parameters rather than intrinsic properties of the strategy families.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on reimplementation fidelity. We respond point-by-point below.
read point-by-point responses
-
Referee: The partitioning of the three strategy families into distinct effectiveness-efficiency regions rests on the fidelity of the 12+ reimplementations. The manuscript reports no side-by-side verification that the reimplemented baselines recover the performance numbers originally published for those methods on overlapping datasets or models; without such checks, the observed region assignments could be artifacts of prompt formatting, threshold choices, or decoding parameters rather than intrinsic properties of the strategy families.
Authors: We agree that explicit verification against original reported numbers would increase confidence in the reimplementations. However, many source papers evaluate on non-overlapping models (e.g., proprietary or earlier versions), datasets, or decoding settings, making exact numerical recovery infeasible or non-informative. Our reimplementations follow the original method descriptions as closely as possible while enforcing a single pipeline, prompt template, and decoding configuration across all 12+ methods; the reported trade-off regions are therefore relative comparisons under these controlled conditions rather than absolute claims. We will revise the reimplementation section to include (1) a detailed table of key hyperparameter and formatting choices for each baseline and (2) any available side-by-side numbers on the subset of cases where original evaluation settings overlap with HRBench. This addition will make the fidelity argument more transparent without altering the core empirical claims. revision: partial
Circularity Check
Empirical benchmark paper with no derivation chain or self-referential reductions
full rationale
The paper introduces HRBench as a unified empirical evaluation framework for hybrid-reasoning switching strategies. It organizes existing methods into families, reimplements 12+ prior approaches, and reports comparative results across models and benchmarks. No equations, fitted parameters, predictions derived from inputs, or load-bearing self-citations appear in the provided text. All claims rest on external benchmarks and reimplemented baselines rather than any internal reduction to self-defined quantities. This is the standard case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sketch-of-thought: Efficient llm reasoning with adaptive cognitive-inspired sketching.arXiv preprint arXiv:2503.05179. ByteDance. 2025. Seed-oss open-source mod- els. https://github.com/ByteDance-Seed/ seed-oss. Xiaoxue Cheng, Junyi Li, Zhenduo Zhang, Xinyu Tang, Xin Zhao, Xinyu Kong, and Zhiqiang Zhang. 2026. Incentivizing dual process thinking for effic...
-
[2]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Haiquan Lu, Gongfan Fang, Xinyin Ma, Qi Li, and Xin- chao Wang. 2025. Mixreasoning: Switching modes to think.arXiv preprint arXiv:2510.06052. 9 Haotian Luo, Haiying He, Yibo Wang, Jinluan Yang, Rui Liu, Naiqiang Tan, Xiaochun Cao, Dacheng Tao, and Li Shen. 2025. Adar1: From long-cot to hybrid-cot ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
mode": "1
Stage 1 (Judge):A lightweight call with model- specific judge prompt (Appendix A §B.2). The judge runs in no-think/low-effort mode (max_tokens=256) to minimize overhead. It outputs a JSON object specifying the routing decision: • Qwen3.5: {"mode": "1"|"2"|"3", "budget": N} (think / nothink / budget- think) • gpt-oss: {"level": "high"|"medium"|"low"} • See...
-
[4]
JSON parsing includes fallback: if the response is malformed, the conservative default (full think) is used
Stage 2 (Solve):The problem is dispatched according to the judge’s decision. JSON parsing includes fallback: if the response is malformed, the conservative default (full think) is used. No additional parameters are trained— the LLM’s existing capabilities drive the routing decision. RT-SFT & RT-DPO.For both RT-SFT and RT- DPO, we collect routing labels as...
-
[5]
For each problem q, run RFT under all available modesm∈ M
-
[6]
Identify the mode m∗ that produces correct an- swers with minimum average token cost
-
[7]
This produces router training samples (q, m∗) for SFT, and preference pairs (q, m+, m−) for DPO wherem + =m ∗ andm − is any alternative mode
The routing label forqism ∗. This produces router training samples (q, m∗) for SFT, and preference pairs (q, m+, m−) for DPO wherem + =m ∗ andm − is any alternative mode. RT-GRPO.During GRPO training,only the router is updated—the backbone LLM is frozen. The router makes mode decisions, the LLM gener- ates responses under the routed mode, and rewards are ...
-
[8]
Pass 1:Generate complete response in no-think mode
-
[9]
Decision:Scan the response text for any match in the uncertainty keyword library (55 keywords across 6 categories; full list in §B.3)
-
[10]
Total token count = Pass 1 tokens + Pass 2 tokens
Pass 2 (if triggered):Discard Pass 1 output; re-generate with full think mode. Total token count = Pass 1 tokens + Pass 2 tokens. The keyword library is model-specific to account for different hedging patterns: • Qwen3.5: 55 keywords includingwait,actually, let me reconsider,I’m not sure,hmm,alterna- tively,let me verify, etc. • gpt-oss: Same core library...
-
[11]
Pass 1:Generate complete response in no-think modewith logprobs(top-20 logprobs). 16
-
[12]
Escalation fires if ≥3 tokens or >5% of total output tokens exceed the model-specific thresholdτ
Decision:Compute normalized Shannon en- tropy for each output token: Ht = −P v∈top-k ˆpt(v) log ˆpt(v) logk (8) where ˆpt is the renormalized distribution over the top-k= 20 tokens. Escalation fires if ≥3 tokens or >5% of total output tokens exceed the model-specific thresholdτ
-
[13]
Total token count includes both passes
Pass 2 (if triggered):Re-generate with full think mode. Total token count includes both passes. Spec-SFT/DPO.Training data follows the same RFT pipeline: we generate responses under both the initial no-think pass and the full speculative (trigger/entropy → re-think) pipeline, then select correct responses with minimum total tokens as SFT targets. For DPO,...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.