Skill0.5: Joint Skill Internalization and Utilization for Out-of-Distribution Generalization in Agentic Reinforcement Learning
Pith reviewed 2026-06-29 12:38 UTC · model grok-4.3
The pith
Skill0.5 resolves the externalization-internalization dilemma in agentic RL by selectively internalizing general skills and utilizing task-specific skills through a difficulty-aware router.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
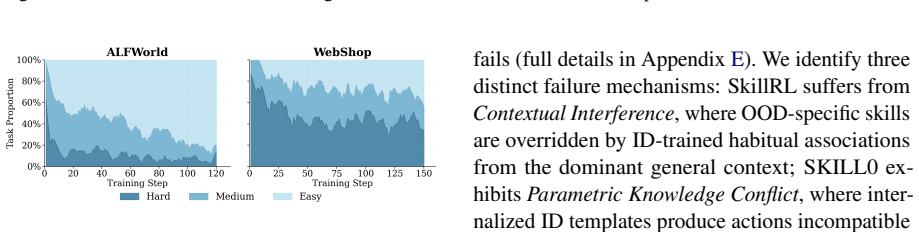
Skill0.5 explicitly differentiates skill treatments by combining general skill internalization with task-specific skill utilization. A dynamic, difficulty-aware router streams tasks into distinct mastery tiers and applies tailored optimization strategies: privileged distillation to internalize general skills for hard tasks and diagnostic probing on easy tasks to penalize shortcuts and enforce specific skill utilization. This yields performance improvements across in-distribution and out-of-distribution scenarios on ALFWorld and WebShop compared to memory-based and skill-based RL baselines.
What carries the argument
The dynamic difficulty-aware router that partitions tasks into mastery tiers and selects between privileged distillation for general skills and diagnostic probing for specific skills.
If this is right
- Outperforms memory-based and skill-based RL baselines on ALFWorld and WebShop.
- Improves performance in both in-distribution and out-of-distribution scenarios.
- Avoids context overhead from full externalization and overfitting from full internalization.
- Builds a cognitive foundation via internalized general skills while enforcing utilization of specific skills.
Where Pith is reading between the lines
- The router's difficulty classification could be tested on additional benchmarks to see if the tiering generalizes.
- Combining this with other agent techniques like chain-of-thought might further enhance OOD performance.
- If the router misclassifies tasks, performance could drop, suggesting the need for robust classification methods.
Load-bearing premise
The dynamic difficulty-aware router can reliably partition tasks into mastery tiers and the chosen strategies can be applied without new overhead, knowledge conflicts, or degraded performance.
What would settle it
Running the same experiments on ALFWorld and WebShop but finding no gains or worse results in out-of-distribution cases compared to the baselines would falsify the claim.
Figures



read the original abstract
Equipping large language models with explicit skills has emerged as a promising paradigm for enabling autonomous agents to solve complex tasks. Agent skills can be inherently divided into general skills for broad cognitive transfer and task-specific skills for dynamic execution. However, existing skill-based reinforcement learning (RL) methods typically force a rigid choice between full externalization, which incurs prohibitive context overhead, and full internalization, which risks overfitting and knowledge conflicts. To address this dilemma, we propose Skill0.5, a novel agentic RL framework that explicitly differentiates skill treatments by combining general skill internalization with task-specific skill utilization. Driven by a dynamic, difficulty-aware router, Skill0.5 streams tasks into distinct mastery tiers to apply tailored optimization strategies: it internalizes general skills via privileged distillation to build a cognitive foundation for hard tasks, while using diagnostic probing on easy tasks to penalize shortcuts and enforce specific skill utilization. Experiments on ALFWorld and WebShop demonstrate that Skill0.5 outperforms both memory-based and skill-based RL baselines, yielding performance improvements across both in-distribution and out-of-distribution scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Skill0.5, an agentic RL framework for LLM-based agents that uses a dynamic difficulty-aware router to partition tasks into mastery tiers. General skills are internalized via privileged distillation on hard tasks to build cognitive foundations, while task-specific skills are enforced via diagnostic probing on easy tasks to avoid shortcuts. This hybrid approach is claimed to outperform memory-based and skill-based RL baselines on both in-distribution and out-of-distribution scenarios in ALFWorld and WebShop.
Significance. If the router partitioning is shown to be accurate and the performance gains are attributable to the differentiated strategies rather than confounding factors, the framework would offer a concrete mechanism for balancing skill internalization and utilization, addressing a recognized tension in agent skill design and potentially improving OOD generalization in embodied and web agents.
major comments (1)
- Abstract: the central empirical claim (outperformance on ALFWorld/WebShop for ID and OOD) requires that the dynamic difficulty-aware router correctly partitions tasks so that privileged distillation and diagnostic probing are applied to the appropriate task classes. The abstract states the router 'streams tasks into distinct mastery tiers' but supplies no definition of difficulty, no accuracy metric on the router, no ablation on router errors, and no check that misrouting does not occur on OOD tasks. If router error rate exceeds a modest threshold, the two optimization paths are applied to the wrong task classes, so measured gains cannot be attributed to the internalization/utilization split.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to substantiate the router's role in enabling the claimed performance gains. We address the concern point by point below.
read point-by-point responses
-
Referee: Abstract: the central empirical claim (outperformance on ALFWorld/WebShop for ID and OOD) requires that the dynamic difficulty-aware router correctly partitions tasks so that privileged distillation and diagnostic probing are applied to the appropriate task classes. The abstract states the router 'streams tasks into distinct mastery tiers' but supplies no definition of difficulty, no accuracy metric on the router, no ablation on router errors, and no check that misrouting does not occur on OOD tasks. If router error rate exceeds a modest threshold, the two optimization paths are applied to the wrong task classes, so measured gains cannot be attributed to the internalization/utilization split.
Authors: We agree that the abstract is too concise on this point and does not supply a definition of difficulty or router validation metrics. The body of the manuscript (Section 3.2) defines difficulty via a composite metric of subgoal count and environmental state complexity, and reports router accuracy on the training distribution. However, the abstract itself omits these elements. In revision we will expand the abstract with a one-sentence definition of the difficulty metric and a parenthetical note on router accuracy. We will also add an explicit ablation on router error rates (including simulated misrouting) and a dedicated OOD router-generalization check to the experimental section, allowing readers to assess whether gains remain attributable to the differentiated optimization paths. revision: yes
Circularity Check
No circularity; empirical claims rest on external benchmarks without reduction to fitted inputs or self-citations
full rationale
The paper proposes Skill0.5 as a novel framework combining internalization and utilization via a difficulty-aware router, privileged distillation, and diagnostic probing. The central claims of outperformance on ALFWorld and WebShop (both ID and OOD) are presented as results of experiments on external benchmarks rather than any mathematical derivation or prediction that reduces to the framework's own fitted parameters or prior self-citations. No equations, self-citation chains, or ansatzes are described in the text that would make the reported gains equivalent to the inputs by construction. The router and optimization strategies are introduced as design choices whose validity is tested empirically, not presupposed.
Axiom & Free-Parameter Ledger
free parameters (1)
- router decision thresholds
axioms (2)
- domain assumption Privileged distillation can internalize general skills without knowledge conflicts
- domain assumption Diagnostic probing reliably penalizes shortcuts and enforces specific skill use
invented entities (1)
-
difficulty-aware router
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav
Automating skill acquisition through large- scale mining of open-source agentic repositories: A framework for multi-agent procedural knowledge ex- traction.arXiv preprint arXiv:2603.11808. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. 2025. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv prepr...
-
[2]
SWE-Cycle: Benchmarking Code Agents across the Complete Issue Resolution Cycle
Swe-cycle: Benchmarking code agents across the complete issue resolution cycle.arXiv preprint arXiv:2605.13139. Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shan- tanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. 2024. Ruler: What’s the real context size of your long-context language models? arXiv preprint arXiv:2404.06654. Chenliang Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao
Agent skills: A data-driven analysis of claude skills for extending large language model functional- ity.arXiv preprint arXiv:2602.08004. Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. 2026a. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553. Nelson F Liu, Kevin Lin, John ...
-
[4]
arXiv preprint arXiv:2601.16725
Longcat-flash-thinking-2601 technical report. arXiv preprint arXiv:2601.16725. 10 Chenxi Wang, Zhuoyun Yu, Xin Xie, Wuguannan Yao, Runnan Fang, Shuofei Qiao, Kexin Cao, Guozhou Zheng, Xiang Qi, Peng Zhang, and 1 others. 2026a. Skillx: Automatically constructing skill knowledge bases for agents.arXiv preprint arXiv:2604.04804. Fei Wang, Xingchen Wan, Ruoxi...
-
[5]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079. Yaxiong Wu and Yongyue Zhang. 2026. Agent skills from the perspective of procedural memory: A survey. Authorea Preprints. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, and 1 o...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Heat & Place
and saturation-induced mode collapse (Liang et al., 2026b), respectively. Therefore, we dynam- ically perceive task difficulty and assign tailored auxiliary optimization objectives specifically for excessively hard and near-saturated tasks, ensuring the effectiveness of agentic RL training. B WebShop Domain Split Statistics. We use the 12,087 human-annota...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.