Recognition: no theorem link
SWE-Cycle: Benchmarking Code Agents across the Complete Issue Resolution Cycle
Pith reviewed 2026-05-14 18:32 UTC · model grok-4.3
The pith
Code agents show sharply lower success rates when handling complete issue resolution autonomously versus in isolated subtasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
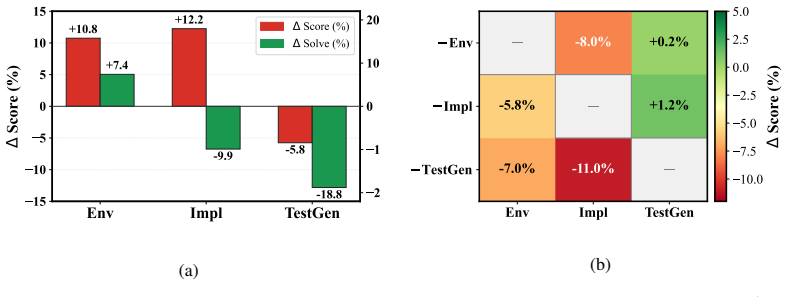
SWE-Cycle evaluates agents across isolated tasks of environment reconstruction, code implementation, and verification test generation, as well as an end-to-end FullCycle task that integrates all three in a bare repository without human scaffolding. Using SWE-Judge, which merges static review with dynamic testing to verify functional correctness, the evaluation of agents powered by six state-of-the-art LLMs reveals a sharp drop in solve rates when moving from isolated tasks to FullCycle execution, exposing bottlenecks in handling cross-phase dependencies and maintaining code quality.
What carries the argument
SWE-Cycle benchmark consisting of isolated subtasks and an integrated FullCycle execution, paired with SWE-Judge for reliable verification of autonomous trajectories through static and dynamic checks.
If this is right
- Agents require stronger mechanisms to track and resolve dependencies that span multiple development phases.
- Preserving code quality across an entire autonomous resolution process is a distinct and harder challenge than solving single subtasks.
- Benchmarks must incorporate full-cycle execution in bare environments to measure real autonomy rather than pre-configured subtasks.
- Evaluation tools need hybrid static-dynamic verification to avoid systematic errors when assessing complex agent trajectories.
Where Pith is reading between the lines
- Agent designs could incorporate explicit planning or memory structures that persist across phase boundaries to reduce the observed integration failures.
- The performance gap may generalize to other multi-step agent workflows such as data pipeline construction or scientific experiment orchestration.
- Training regimens focused on sequential dependency handling might narrow the gap between isolated and full-cycle performance.
Load-bearing premise
The 489 filtered instances and the SWE-Judge evaluator accurately capture practical autonomy without selection bias or verification errors that would alter the observed performance drop.
What would settle it
Re-running the same 489 instances with an alternative verification method that shows no significant solve-rate difference between isolated tasks and FullCycle execution would falsify the claim of critical cross-phase bottlenecks.
Figures


read the original abstract
As autonomous code agents move toward end-to-end software development, evaluating their practical autonomy becomes critical. Current benchmarks hide friction by testing agents in pre-configured environments, and their static evaluation pipelines frequently fail when parsing fully autonomous trajectories. We address these limitations with SWE-Cycle, a benchmark of 489 rigorously filtered instances. SWE-Cycle evaluates agents across three isolated tasks, including environment reconstruction, code implementation, and verification test generation, as well as an end-to-end FullCycle task that integrates all three. The FullCycle task requires agents to work autonomously in a bare repository without human scaffolding. To reliably assess these complex execution paths, we developed SWE-Judge. By combining static code review with dynamic testing, this execution-capable evaluation agent accurately verifies functional correctness and eliminates the systematic measurement errors of traditional static parsers. We evaluate code agents powered by six state-of-the-art LLMs across these four tasks. The results reveal a sharp drop in solve rates when transitioning from isolated tasks to FullCycle execution, exposing critical bottlenecks in handling cross-phase dependencies and maintaining code quality. Together, SWE-Cycle and SWE-Judge provide a comprehensive framework for accurately measuring the end-to-end capabilities of autonomous software agents.
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity detected in benchmark construction or evaluation
full rationale
The paper presents SWE-Cycle as a new benchmark of 489 filtered instances and SWE-Judge as a separate evaluation agent combining static review and dynamic testing. These are introduced as independent tools for measuring agent performance on isolated tasks and FullCycle execution. No equations, fitted parameters, or derived predictions appear in the provided text. Results are reported as empirical observations of solve-rate drops, not quantities forced by construction from the benchmark itself. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming reduces the central claims to inputs. The derivation chain consists of benchmark curation and tool development followed by external evaluation runs, which remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 489 filtered instances are representative of real-world software issue resolution cycles.
- domain assumption SWE-Judge correctly identifies functional correctness without systematic false positives or negatives.
invented entities (1)
-
SWE-Judge
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Claude 4.6 sonnet system card
Anthropic. Claude 4.6 sonnet system card. Technical report, Anthropic,
-
[2]
URL https://assets.anthropic.com/m/785e231869ea8b3b/original/ Claude-4-6-Sonnet-System-Card.pdf
-
[3]
Claude code, 2025
Anthropic. Claude code, 2025. URLhttps://github.com/anthropics/claude-code
2025
-
[4]
Introducing claude opus 4.5
Anthropic. Introducing claude opus 4.5. Anthropic Blog, 2025. URL https://www. anthropic.com/news/claude-opus-4-5
2025
-
[5]
Why Do Multi-Agent LLM Systems Fail?
Mert Cemri, Melissa Z. Pan, Shuyi Yang, et al. Why do multi-agent LLM systems fail?, 2025. URLhttps://arxiv.org/abs/2503.13657
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Jimenez, John Yang, Kevin Liu, and Aleksander Madry
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Kevin Liu, and Aleksander Madry. Introducing SWE-bench verified. OpenAI Blog, 2024. URL https://openai.com/index/introducing-swe-bench-verified/
2024
-
[7]
Deepseek-v3.2: Pushing the frontier of open large language models,
DeepSeek-AI and Others. Deepseek-v3.2: Pushing the frontier of open large language models,
-
[8]
URLhttps://arxiv.org/abs/2512.02556
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
Xiang Deng, Jeff Da, Edwin Pan, Yannis Yiming He, Charles Ide, Kanak Garg, Niklas Lauffer, Andrew Park, Nitin Pasari, Chetan Rane, Karmini Sampath, Maya Krishnan, Srivatsa Kundurthy, Sean Hendryx, Zifan Wang, Vijay Bharadwaj, Jeff Holm, Raja Aluri, Chen Bo Calvin Zhang, Noah Jacobson, Bing Liu, and Brad Kenstler. SWE-bench pro: Can AI agents solve long-ho...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
arXiv preprint arXiv:2512.12730 , year=
Jingzhe Ding and Others. Nl2repo-bench: Towards long-horizon repository generation evalua- tion of coding agents, 2026. URLhttps://arxiv.org/abs/2512.12730
-
[11]
EnvBench: A benchmark for automated environment setup, 2025
Aleksandra Eliseeva, Alexander Kovrigin, Ilia Kholkin, Egor Bogomolov, and Yaroslav Zharov. EnvBench: A benchmark for automated environment setup, 2025. URL https://arxiv.org/ abs/2503.14443
-
[12]
Automatically benchmarking llm code agents through agent-driven annotation and evaluation, 2025
Lingyue Fu, Bolun Zhang, Hao Guan, Yaoming Zhu, Lin Qiu, Weiwen Liu, Xuezhi Cao, Xunliang Cai, Weinan Zhang, and Yong Yu. Automatically benchmarking llm code agents through agent-driven annotation and evaluation, 2025
2025
-
[13]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5 Team. Glm-5: From vibe coding to agentic engineering. arXiv preprint arXiv:2602.15763, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Devbench: A realistic, developer-informed benchmark for code generation models, 2026
Pareesa Ameneh Golnari, Adarsh Kumarappan, Wen Wen, Xiaoyu Liu, Gabriel Ryan, Yuting Sun, Shengyu Fu, and Elsie Nallipogu. Devbench: A realistic, developer-informed benchmark for code generation models, 2026. URLhttps://arxiv.org/abs/2601.11895
-
[15]
SWE-bench goes live!,
Alex Gu, Naman Jain Liu, Nikhil Thakur, Wen-Ding Shi, Dídac Suris, Sanjay Jain, Naomi Saphra, Celine Lee Xia, Graham Neubig, and Aditi Raghunathan. SWE-bench goes live!,
-
[16]
URL https://arxiv.org/abs/2505.23419. NeurIPS 2025 Datasets and Bench- marks Track
-
[17]
A survey on LLM-as-a-judge,
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo. A survey on LLM-as-a-judge,
-
[18]
URLhttps://arxiv.org/abs/2411.15594
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? In Proceedings of the International Conference on Learning Representations (ICLR), 2024. URL https://arxiv.org/abs/2310.06770
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Kimi k2.5: Scaling reinforcement learning with llms
Kimi. Kimi k2.5: Scaling reinforcement learning with llms. Kimi Blog, 2025. URL https: //www.kimi.com/blog/kimi-k2-5. 10
2025
-
[21]
Fea-bench: A benchmark for evaluating repository-level code generation for feature implementation
Wei Li, Xin Zhang, Zhongxin Guo, Shaoguang Mao, Wen Luo, Guangyue Peng, Yangyu Huang, Houfeng Wang, and Scarlett Li. Fea-bench: A benchmark for evaluating repository-level code generation for feature implementation. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), pages 17160–17176, 2025
2025
-
[22]
The swe-bench illusion: When state-of-the-art llms remember instead of reason, 2025
Shanchao Liang, Spandan Garg, and Roshanak Zilouchian Moghaddam. The swe-bench illusion: When state-of-the-art llms remember instead of reason, 2025. URL https://arxiv.org/ abs/2506.12286
-
[23]
CodeJudgeBench: Benchmarking LLM-as-a-judge for coding tasks, 2025
Xichang Liu et al. CodeJudgeBench: Benchmarking LLM-as-a-judge for coding tasks, 2025. URLhttps://arxiv.org/abs/2507.10535
-
[24]
AI-augmented CI/CD pipelines: From code commit to production with autonomous decisions, 2025
Zhengyu Liu et al. AI-augmented CI/CD pipelines: From code commit to production with autonomous decisions, 2025. URLhttps://arxiv.org/abs/2508.11867
-
[25]
Minimax 2.7
MiniMax. Minimax 2.7. MiniMax Blog, 2026. URL https://www.minimaxi.com/models/ text/m27
2026
-
[26]
Introducing codex, 2025
OpenAI. Introducing codex, 2025. URL https://openai.com/index/ introducing-codex/
2025
-
[27]
Introducing gpt -5.4
OpenAI. Introducing gpt -5.4. OpenAI Blog, 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[28]
Why swe-bench verified no longer measures frontier coding capabilities
OpenAI. Why swe-bench verified no longer measures frontier coding capabilities. https:// openai.com/index/why-we-no-longer-evaluate-swe-bench-verified/ , February 2026
2026
-
[29]
Opencode, 2026
OpenCode Contributors. Opencode, 2026. URL https://github.com/opencode-ai/ opencode
2026
-
[30]
Qwen3.5: Towards native multimodal agents
Qwen. Qwen3.5: Towards native multimodal agents. Qwen Blog, 2026. URL https: //qwen.ai/blog?id=qwen3.5
2026
-
[31]
Judging the judges: A systematic study of position bias in LLM-as-a-judge
Vibhu Raina et al. Judging the judges: A systematic study of position bias in LLM-as-a-judge. In Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP),
- [32]
-
[33]
Testeval: Benchmarking large language models for test case generation, 2025
Wenhan Wang, Chenyuan Yang, Zhijie Wang, Yuheng Huang, Zhaoyang Chu, Da Song, Ling- ming Zhang, An Ran Chen, and Lei Ma. Testeval: Benchmarking large language models for test case generation, 2025. URLhttps://arxiv.org/abs/2406.04531
-
[34]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
Xingyao Wang, Boxuan Chen, Parker Adler, Zijian Cheng, Kexun Hu, Jieyu Li, Yuqi Li, Ziniu Liu, Yufan Lu, Jiasheng Ning, et al. OpenHands: An open platform for AI software developers as generalist agents, 2024. URLhttps://arxiv.org/abs/2407.16741
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
Swe-compass: Towards unified evaluation of agentic coding abilities for large language models, 2025
Jingxuan Xu, Ken Deng, Weihao Li, Songwei Yu, Huaixi Tang, Haoyang Huang, Zhiyi Lai, Zizheng Zhan, Yanan Wu, Chenchen Zhang, Kepeng Lei, Yifan Yao, Xinping Lei, Wenqiang Zhu, Zongxian Feng, Han Li, Junqi Xiong, Dailin Li, Zuchen Gao, Kun Wu, Wen Xiang, Ziqi Zhan, Yuanxing Zhang, Wuxuan Gong, Ziyuan Gao, Guanxiang Wang, Yirong Xue, Mengtong Li, Mengfei Xie...
-
[36]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Liber, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-agent: Agent-computer interfaces enable automated software engineering, 2024. URLhttps://arxiv.org/abs/2405.15793
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
SWE-smith: Scaling Data for Software Engineering Agents
John Yang, Kilian Lieret, Carlos E. Jimenez, Alexander Wettig, Kabir Khandpur, Yanzhe Zhang, Binyuan Hui, Ofir Press, Ludwig Schmidt, and Diyi Yang. SWE-smith: Scaling data for software engineering agents, 2025. URL https://arxiv.org/abs/2504.21798. NeurIPS 2025 Datasets and Benchmarks Track Spotlight. 11
work page internal anchor Pith review arXiv 2025
-
[38]
A survey on agent-as-a-judge, 2026
Runyang You, Hongru Cai, Caiqi Zhang, et al. A survey on agent-as-a-judge, 2026. URL https://arxiv.org/abs/2601.05111
-
[39]
Utboost: Rigorous evaluation of coding agents on swe-bench, 2025
Boxi Yu, Yuxuan Zhu, Pinjia He, and Daniel Kang. Utboost: Rigorous evaluation of coding agents on swe-bench. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025. URLhttps://arxiv.org/abs/2506.09289
-
[40]
Multi-swe-bench: A multilingual benchmark for issue resolving.arXiv preprint arXiv:2504.02605, 2025
Daoguang Zan, Zhirong Huang, Wei Liu, Hanwu Chen, Linhao Zhang, Shulin Xin, Lu Chen, Qi Liu, Xiaojian Zhong, Aoyan Li, Siyao Liu, Yongsheng Xiao, Liangqiang Chen, Yuyu Zhang, Jing Su, Tianyu Liu, Rui Long, Kai Shen, and Liang Xiang. Multi-SWE-bench: A multilingual benchmark for issue resolving, 2025. URLhttps://arxiv.org/abs/2504.02605
-
[41]
Benchmarking and studying the LLM-based agent system in end-to-end software development, 2025
Zhengran Zeng, Yixin Li, Rui Xie, Wei Ye, and Shikun Zhang. Benchmarking and studying the LLM-based agent system in end-to-end software development, 2025. URL https://arxiv. org/abs/2511.04064
-
[42]
Yuntong Zhang, Zhiyuan Pan, Imam Nur Bani Yusuf, Haifeng Ruan, Ridwan Shariffdeen, and Abhik Roychoudhury. Code review agent benchmark. arXiv preprint arXiv:2603.23448, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[43]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, et al. Judging LLM-as-a-judge with MT-bench and chatbot arena, 2024. URLhttps://arxiv.org/abs/2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Featurebench: Benchmarking agentic coding for complex feature development
Q Zhou, J Zhang, H Wang, R Hao, J Wang, M Han, Y Yang, S Wu, F Pan, L Fan, D Tu, and Z Zhang. Featurebench: Benchmarking agentic coding for complex feature development. arXiv preprint arXiv:2602.10975, 2026
-
[45]
Yuxuan Zhu, Tian Jin, Yada Pruksachatkun, Aston Zhang, Shayne Liu, Sasha Cui, Sayash Kapoor, Shayne Longpre, Kevin Meng, Richard Weiss, et al. Establishing best practices for building rigorous agentic benchmarks. arXiv preprint arXiv:2507.02825, 2025
-
[46]
Does this step contain a critical error? Answer with only ‘yes’ or ‘no’
Mingchen Zhuge, Changsheng Zhao, Dylan Ashley, Wenyi Wang, Dmitrii Khizbullin, Yunyang Xiong, Zechun Liu, Ernie Chang, Raghuraman Krishnamoorthi, Yuandong Tian, Yangyang Shi, Vikas Chandra, and Jürgen Schmidhuber. Agent-as-a-judge: Evaluate agents with agents. In Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025. URL https:...
-
[47]
Read the issue description to understand the problem context
-
[48]
Examine the gold reference patch to establish the correct solution approach
-
[49]
Review the agent’s submission to understand what the agent implemented
-
[50]
Read SWE-Judge’s scoring and reasoning
-
[51]
Cross-reference with execution logs and LLM auxiliary analysis when static review is insufficient
-
[52]
Couldn’t find the node_modules state file
Assign a failure category from the predefined taxonomy and record which evaluator is correct. Human Verification Results.To validate the LLM-assisted categorization and rule out selection bias, we conduct human deep annotation on all 371 disagreement instances plus 86 agreement instances (a 10% random sample of cases where SWE-Judge and the script concur)...
-
[53]
Instruction and gold patch review.SWE-Judge reads the issue description and golden patch to establish the expected behavior: file deletion via rimraf with glob patterns for accumulated profile images
-
[54]
Agent patch macro-review.SWE-Judge reviews the agent’s diff across 5 modified files (src/groups/cover.js, src/socket.io/user/picture.js, src/user/delete.js, src/user/picture.js). It identifies a critical divergence: the agent uses getLocalCoverPath/getLocalAvatarPath to delete only the current file, while the golden patch uses glob patterns to delete all ...
-
[55]
Dynamic: Node.js v18.20.8 available, packages import successfully, 359 tests collected
ENV evaluation.Static: setup.sh runs npm install correctly. Dynamic: Node.js v18.20.8 available, packages import successfully, 359 tests collected. Score: 4/4
-
[56]
Dynamic: Phase 1 fails with TypeError: User.getLocalCoverPath is not a function (imprecise failure)
TEST evaluation.Static: Agent covers 3 of 4 key scenarios (missing account deletion cleanup test). Dynamic: Phase 1 fails with TypeError: User.getLocalCoverPath is not a function (imprecise failure). Score: 2/4
-
[57]
Adaptive eval scripting (triggered by TEST_STATIC < 2).The agent’s test suite lacks coverage for account deletion cleanup. SWE-Judge writes eval_improved.sh and test/improved-image-cleanup.js, a custom test that creates dummy profile images, calls the account deletion function, and verifies that 0 files remain afterward. The first execution discovers 3 or...
-
[58]
Score: 2/4
CODE evaluation using custom test results.The custom test output directly informs CODE_DYNAMIC: 3/4 tests pass (group cover, user cover, user avatar succeed; account deletion cleanup fails). Score: 2/4. Final Scores.ENV: 4, TEST: 2, CODE: 2. Total: 8/12 (0.667). This case shows that SWE-Judge writes its own verification scripts when existing coverage is i...
-
[59]
The agent correctly implements both required changes: adding -Dsolr.max.booleanClauses=30000 to SOLR_OPTSand definingFILTER_BOOK_LIMIT = 30_000
Initial review.SWE-Judge reads the instruction, golden patch, and agent patch. The agent correctly implements both required changes: adding -Dsolr.max.booleanClauses=30000 to SOLR_OPTSand definingFILTER_BOOK_LIMIT = 30_000
-
[60]
Both tests pass: test_filter_book_limit_constant_exists and test_solr_opts_has_boolean_clauses_limit
Agent test execution (Phase 2).SWE-Judge runs the agent’s test suite ( eval.sh) on the fixed code. Both tests pass: test_filter_book_limit_constant_exists and test_solr_opts_has_boolean_clauses_limit. 3.Fault injection (Phase 1).SWE-Judge reverts the agent’s changes to simulate the buggy state: git show base_commit:docker-compose.yml > /tmp/docker-compose...
-
[61]
SWE-Judge confirms the agent’s tests are not trivial or overfitted: they verify specific code content rather than relying on indirect signals
Verdict.The tests correctly discriminate between buggy and fixed states. SWE-Judge confirms the agent’s tests are not trivial or overfitted: they verify specific code content rather than relying on indirect signals. TEST_DYNAMIC: 2/2
-
[62]
Dynamic: Python 3.11.1 available, but core package import fails (ModuleNotFoundError: web)
ENV evaluation.Static: Agent uses venv instead of the requested conda environment, devi- ating from the instruction. Dynamic: Python 3.11.1 available, but core package import fails (ModuleNotFoundError: web). Score: 2/4. Final Scores.ENV: 2, TEST: 3, CODE: 4. Total: 9/12 (0.75). Fault injection verifies that the agent’s tests genuinely detect the bug rath...
-
[63]
Code review via git diff.SWE-Judge examines the agent’s changes: adding a Version field to the configuration struct, implementing validation logic, updating the schema, and creating test data files
-
[64]
The agent’s implementation aligns closely with the golden patch, using cleaner error handling patterns in some cases
Reference comparison.SWE-Judge reads the golden patch and performs a structural comparison. The agent’s implementation aligns closely with the golden patch, using cleaner error handling patterns in some cases
-
[65]
to confirm compilation succeeds, then uses a non-matching test pattern to verify test collection without execution
Build verification.SWE-Judge runs go build ./... to confirm compilation succeeds, then uses a non-matching test pattern to verify test collection without execution
-
[66]
Implementation is functionally identical to gold.patch—correctly implementsescapeseqfilter with equivalent logic
Test execution with fault injection.SWE-Judge reverts the code to the buggy state and runs the agent’s tests. Tests fail with cfg.Version undefined (compilation error). SWE-Judge notes this is a weaker detection mechanism (compile-time rather than assertion-based) but still validates that the tests cannot pass without the fix. 5.Multi-dimensional scoring....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.