AdaDPO: Self-Adaptive Direct Preference Optimization with Balanced Gradient Updates
Pith reviewed 2026-06-29 12:27 UTC · model grok-4.3
The pith
AdaDPO uses stop-gradient coefficients from policy probabilities to equalize gradient magnitudes on preferred and dispreferred responses in DPO.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
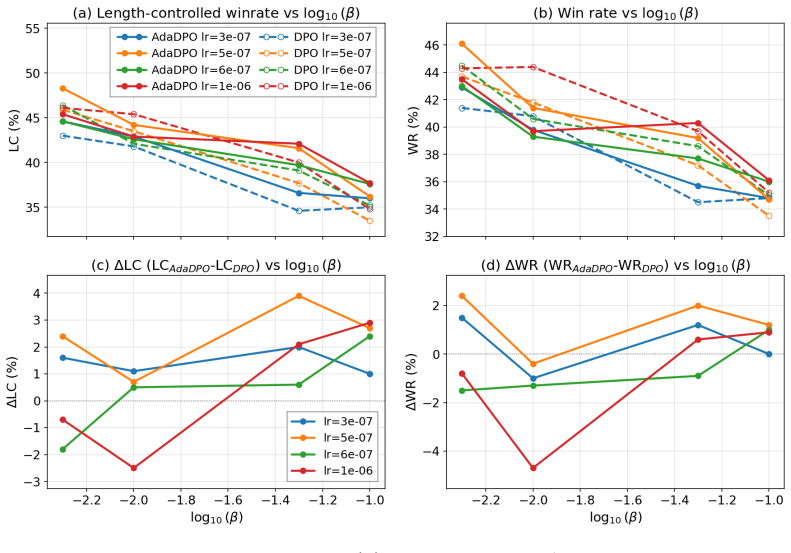
AdaDPO is a self-adaptive variant of DPO that introduces per-preference-pair, stop-gradient-based coefficients derived directly from the policy model's generation probabilities (with the reference model optional) to enforce equality of gradient magnitudes between preferred and dispreferred probabilities. The implementation balances per-token gradients and applies a numerical clipping bound for stability while retaining DPO's original hyperparameter structure. On Llama-3-8B-Instruct trained on UltraFeedback under a SimPO-similar setup, AdaDPO consistently outperforms DPO on AlpacaEval 2 by achieving higher length-controlled win rates in 81 percent of hyperparameter combinations, attaining the
What carries the argument
Per-preference-pair stop-gradient coefficients derived from the policy model's generation probabilities that scale the loss terms to enforce equal effective gradient magnitudes on preferred and dispreferred responses.
If this is right
- Higher length-controlled win rates in 81 percent of hyperparameter combinations on AlpacaEval 2
- Global best length-controlled win rate of 48.3 percent and raw win rate of 46.1 percent
- Enlarged margin between length-controlled and raw win rates in 88 percent of combinations, indicating reduced length bias
- Rectified asymmetric gradient behavior that produces more efficient optimization
- Direct applicability to other pairwise contrastive preference losses including SimPO, R-DPO, IPO, CPO, and ORPO
Where Pith is reading between the lines
- The same self-adaptive scaling could serve as a diagnostic for gradient health in any contrastive preference tuning run
- Because the change is loss-level only, it could be combined with data-filtering or reward-model techniques without further code changes
- Equalizing per-token gradient magnitudes might reduce sensitivity to sequence length during preference optimization
- The principle could be tested on non-language pairwise contrastive tasks to check whether gradient balance improves learning more generally
Load-bearing premise
Scaling the loss terms with stop-gradient coefficients derived from the policy probabilities will produce equal effective gradient magnitudes without introducing new optimization pathologies or changing the underlying loss landscape in unintended ways.
What would settle it
A measurement of the ratio of gradient magnitudes on preferred versus dispreferred tokens during training; if the ratio does not move toward equality after the coefficients are applied, the balancing mechanism does not work as claimed.
Figures

read the original abstract
DPO has become a widely adopted alternative to RLHF for aligning LLMs with human preferences, eliminating the need for a separate reward model or RL loop. Recent theoretical analysis uncovers an asymmetric gradient behavior in DPO: the loss suppresses dispreferred responses substantially faster than it promotes preferred ones, causing the model to learn to avoid bad answers rather than to generate good ones. We propose AdaDPO, a Self-Adaptive variant of the DPO algorithm that introduces per-preference-pair, stop-gradient-based coefficients derived directly from the policy model's generation probabilities, with the reference model's probabilities as an optional component. AdaDPO is constructed to enforce equality of gradient magnitudes between preferred and dispreferred probabilities; the practical implementation balances per-token gradients and applies a numerical clipping bound for stability, while retaining DPO's original hyperparameter structure. On Llama-3-8B-Instruct trained on UltraFeedback under a SimPO similar setup, AdaDPO consistently outperforms DPO on AlpacaEval 2: it achieves higher length-controlled win rates (LC) in 81% of hyperparameter combinations, attains the global best LC (48.3%) and raw win rate (46.1%), and enlarges the LC-over-WR margin in 88% of combinations, indicating effective mitigation of length bias. Additional analyses on KL divergence, reward margin, and reward accuracy confirm that AdaDPO rectifies the gradient imbalance and yields more efficient optimization. Because it operates purely at the loss level, AdaDPO can be dropped into existing preference-based alignment pipelines without changing data collection or model architectures. The method requires only a few lines of code, and the same self-adaptive principle generalizes to a broad family of pairwise contrastive preference losses including SimPO, R-DPO, IPO, CPO, and ORPO.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
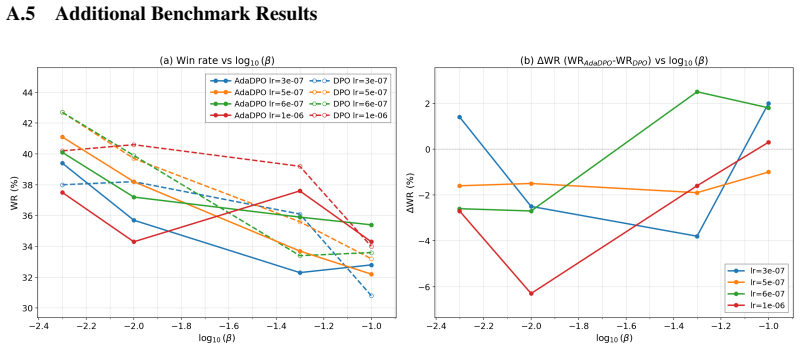
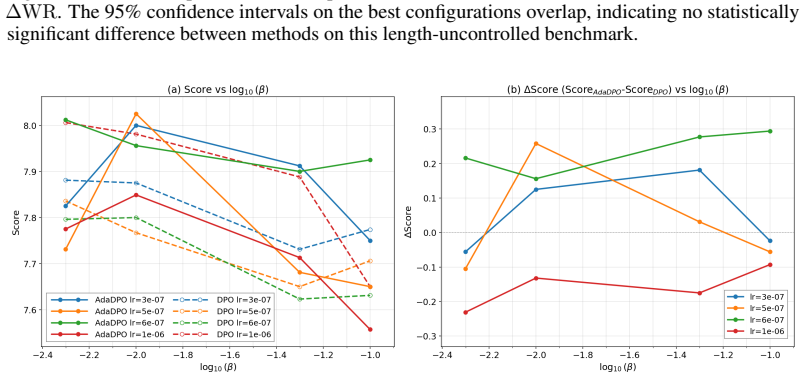
Summary. The paper proposes AdaDPO, a self-adaptive variant of DPO that derives per-preference-pair stop-gradient coefficients from the policy model's generation probabilities (with optional reference-model terms) to enforce equal gradient magnitudes between preferred and dispreferred responses. The practical implementation adds per-token gradient balancing and clipping for stability while preserving DPO's hyperparameter structure. On Llama-3-8B-Instruct trained on UltraFeedback, AdaDPO reports higher length-controlled win rates than DPO in 81% of hyperparameter settings, a global-best LC win rate of 48.3%, raw win rate of 46.1%, and an enlarged LC-over-WR margin in 88% of combinations; secondary analyses on KL divergence, reward margin, and reward accuracy are presented as evidence of rectified imbalance and more efficient optimization. The approach is claimed to generalize to SimPO, R-DPO, IPO, CPO, and ORPO.
Significance. If the gradient-magnitude equalization mechanism is shown to hold after all practical modifications and to causally drive the reported gains, the contribution would be notable: a lightweight, loss-level correction to a documented asymmetry in DPO gradients that requires no new models, data, or architectural changes and retains compatibility with existing pipelines.
major comments (2)
- [Method / Abstract] Abstract and method section: the central construction claims that stop-gradient coefficients derived from policy probabilities enforce equality of gradient magnitudes between preferred and dispreferred responses, yet the practical version additionally applies per-token balancing and a numerical clipping bound; no derivation, ablation, or direct measurement is supplied showing that the final per-example gradient vectors remain equal in magnitude after these operations.
- [Experiments] Experiments: the performance claims (81% of hyperparameter combinations, global-best LC 48.3%, raw WR 46.1%) are presented without error bars, multiple random seeds, or statistical significance tests, which weakens the assertion that AdaDPO consistently rectifies imbalance and mitigates length bias.
minor comments (2)
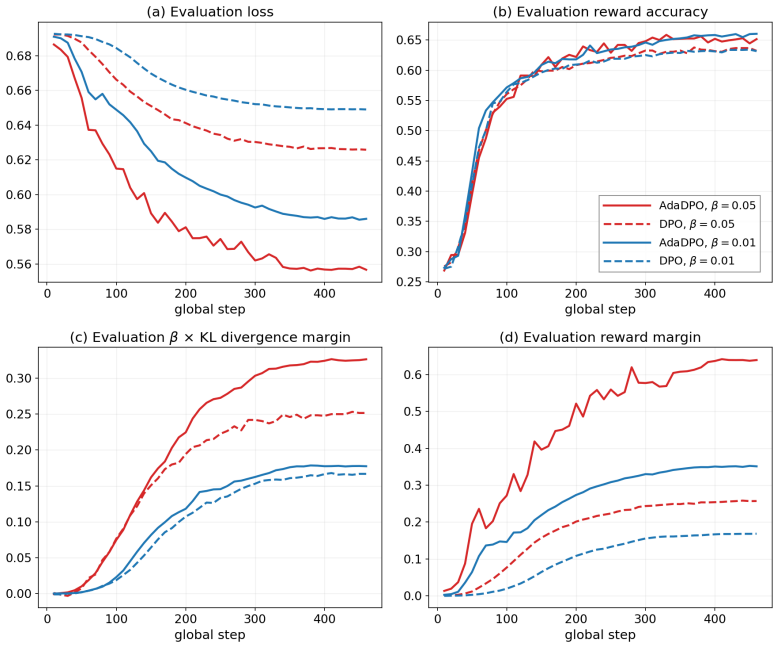
- The abstract states that secondary analyses on KL divergence, reward margin, and reward accuracy confirm rectification, but the manuscript does not reference specific figures, tables, or quantitative thresholds that would allow readers to evaluate the strength of that confirmation.
- Notation for the optional reference-model component and the precise definition of the stop-gradient coefficients should be made fully explicit in the main text rather than left to the appendix.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the presentation of our gradient-balancing mechanism and strengthen the empirical claims. We address each major point below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Method / Abstract] Abstract and method section: the central construction claims that stop-gradient coefficients derived from policy probabilities enforce equality of gradient magnitudes between preferred and dispreferred responses, yet the practical version additionally applies per-token balancing and a numerical clipping bound; no derivation, ablation, or direct measurement is supplied showing that the final per-example gradient vectors remain equal in magnitude after these operations.
Authors: We agree that the manuscript would benefit from explicit verification that the practical modifications preserve the intended gradient-magnitude equality. The core stop-gradient coefficients are derived to equalize the preferred and dispreferred gradient contributions at the sequence level; the per-token balancing is a direct extension that normalizes within each response while maintaining the overall magnitude ratio, and clipping is applied only as a safeguard against numerical instability. In the revision we will add: (1) a short derivation showing that per-token normalization followed by a shared clipping threshold preserves equality of the final gradient vectors up to a bounded scalar, (2) an ablation table measuring gradient-norm ratios before and after each stabilization step on held-out batches, and (3) direct empirical plots of preferred vs. dispreferred gradient magnitudes across training steps. These additions will be placed in a new subsection of the method and will not alter the original hyper-parameter structure. revision: yes
-
Referee: [Experiments] Experiments: the performance claims (81% of hyperparameter combinations, global-best LC 48.3%, raw WR 46.1%) are presented without error bars, multiple random seeds, or statistical significance tests, which weakens the assertion that AdaDPO consistently rectifies imbalance and mitigates length bias.
Authors: We acknowledge that reporting variability and statistical tests would make the consistency claims more robust. The current results reflect a single training run per hyper-parameter combination, which is common in large-scale alignment studies but indeed limits statistical interpretation. In the revised manuscript we will: (1) rerun the full hyper-parameter sweep with three independent random seeds, (2) report mean and standard deviation for all win-rate metrics, and (3) add paired statistical significance tests (Wilcoxon signed-rank) between AdaDPO and DPO across the 81 % of settings where AdaDPO wins. These results will appear in an updated Table 1 and a new appendix subsection on experimental variability. revision: yes
Circularity Check
AdaDPO derivation is self-contained first-principles loss modification
full rationale
The paper presents AdaDPO as a direct modification to the DPO loss using stop-gradient coefficients derived from policy probabilities to address identified gradient imbalance. This construction is explicit and first-principles based, with no parameter fitting to data that would make downstream metrics tautological, no load-bearing self-citations for uniqueness or ansatzes, and no renaming of known results. Empirical outcomes on AlpacaEval are reported as consequences of the method rather than predictions forced by the inputs. The derivation chain remains independent of its own fitted values or self-referential definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gradient magnitude equality between preferred and dispreferred sides is achievable and beneficial via stop-gradient scaling of per-pair coefficients derived from policy probabilities.
Reference graph
Works this paper leans on
-
[1]
AI@Meta. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, Daniel Guo, Daniele Calandriello, Michal Valko, and Rémi Munos. A general theoretical paradigm to understand learning from human preferences.arXiv preprint arXiv:2310.12036,
-
[3]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled AlpacaEval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Duanyu Feng, Bowen Qin, Chen Huang, Zheng Zhang, and Wenqiang Lei. Towards analyzing and understanding the limitations of DPO: A theoretical perspective.arXiv preprint arXiv:2404.04626,
-
[5]
ORPO: Monolithic Preference Optimization without Reference Model
Jiwoo Hong, Noah Lee, and James Thorne. ORPO: Monolithic preference optimization without reference model.arXiv preprint arXiv:2403.07691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E. Gonzalez, and Ion Stoica. From live data to high-quality benchmarks: The Arena-Hard pipeline. LMSYS Blog, 2024.https://lmsys.org/blog/2024-04-19-arena-hard/. Qinwei Ma, Jingzhe Shi, Can Jin, Jenq-Neng Hwang, Serge Belongie, and Lei Li. Gradient imbalance in direct prefe...
-
[7]
SimPO: Simple preference optimization with a reference- free reward.arXiv preprint arXiv:2405.14734,
Yu Meng, Mengzhou Xia, and Danqi Chen. SimPO: Simple preference optimization with a reference- free reward.arXiv preprint arXiv:2405.14734,
-
[8]
Smaug: Fixing Failure Modes of Preference Optimisation with DPO-Positive
Arka Pal, Deep Karkhanis, Samuel Dooley, Manley Roberts, Siddartha Naidu, and Colin White. Smaug: Fixing failure modes of preference optimisation with DPO-positive.arXiv preprint arXiv:2402.13228,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Disentangling length from quality in direct preference optimization.arXiv preprint arXiv:2403.19159,
Ryan Park, Rafael Rafailov, Stefano Ermon, and Chelsea Finn. Disentangling length from quality in direct preference optimization.arXiv preprint arXiv:2403.19159,
-
[10]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Self-play preference optimization for language model alignment.arXiv preprint arXiv:2405.00675,
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-play preference optimization for language model alignment.arXiv preprint arXiv:2405.00675,
-
[12]
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of LLM performance in machine translation.arXiv preprint arXiv:2401.08417,
-
[13]
SGDPO: Self-guided direct preference optimization for language model alignment
Wenqiao Zhu, Ji Liu, Lulu Wang, Jun Wu, and Yulun Zhang. SGDPO: Self-guided direct preference optimization for language model alignment. InFindings of the Association for Computational Linguistics: ACL 2025, pages 12366–12383, Vienna, Austria,
2025
-
[14]
Fine-Tuning Language Models from Human Preferences
Association for Computational Linguistics. Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[15]
We use the length- normalized variant (Stable AdaDPO; see Section 6.1) for all main-text experiments
12 A Technical appendices and supplementary material A.1 Implementation Details The complete PyTorch implementation appears in Listing 1 of Section 3.4. We use the length- normalized variant (Stable AdaDPO; see Section 6.1) for all main-text experiments. The unnormalized variant—obtained by replacing the per-token-averaged log-probabilities with raw summe...
1979
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.