VeriTrip: A Verifiable Benchmark for Travel Planning Agents over Unstructured Web Corpora
Pith reviewed 2026-06-29 12:21 UTC · model grok-4.3
The pith
VeriTrip creates a benchmark that requires travel planning agents to ground decisions in verifiable evidence from noisy unstructured web data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VeriTrip shifts evaluation to evidence-grounded reasoning over unstructured multimodal web corpora. It establishes a Multimodal Retrieval Base derived from real-world sources that forces agents to orchestrate their own queries across heterogeneous data, together with a synchronized Verifiable Knowledge Base that enables cell-wise verification to quantify factual reliability and distinguish systematic reasoning failures from parametric hallucinations. Evaluations across leading MLLMs reveal a retrieval-reasoning trade-off in which the cognitive load of autonomous retrieval erodes instruction retention.
What carries the argument
Multimodal Retrieval Base (MRB) paired with Verifiable Knowledge Base (VKB) and its cell-wise verification protocol, which measures factual reliability while agents autonomously retrieve and reason over real web sources.
If this is right
- Agents must autonomously orchestrate queries across heterogeneous multimodal data instead of receiving structured tool outputs.
- Factual reliability can be quantified at the level of individual facts rather than whole plans.
- Autonomous retrieval imposes a measurable cognitive cost that reduces agents' ability to retain the original user instructions.
- Visual information from web pages must be integrated into logical planning rather than treated separately.
Where Pith is reading between the lines
- The observed trade-off implies that future agents may need dedicated memory or instruction-tracking modules to offset retrieval demands.
- The same MRB-plus-VKB structure could be adapted to other open-web tasks such as research synthesis or shopping comparison.
- If the verification protocol proves reliable, it could serve as a template for creating verifiable test sets in non-travel domains.
Load-bearing premise
The Multimodal Retrieval Base drawn from real sources and the cell-wise verification protocol can accurately separate systematic reasoning failures from parametric hallucinations.
What would settle it
Running the same set of travel-planning tasks on the benchmark but disabling the cell-wise verification step and finding that the rate of detected factual errors does not change would show the protocol does not isolate reasoning failures from hallucinations.
Figures

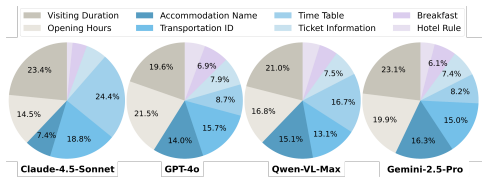




read the original abstract
Existing benchmarks have laid the foundation for travel planning agents by establishing API-centric paradigms. However, as the capabilities of Autonomous Agents continue to advance, their evaluation must evolve beyond simple tool execution toward handling the inherent complexities of the open web. Current benchmarks bypass core cognitive hurdles: they fail to account for information noise, ignore multi-source factual contradictions, and overlook the necessity of grounding visual perception into logical planning. We introduce VeriTrip, a verifiable benchmark designed to meet the increasing demands for agent robustness and reliability. VeriTrip shifts the evaluation focus to evidence-grounded reasoning over unstructured multimodal web corpora. It establishes a Multimodal Retrieval Base (MRB) derived from real-world sources, forcing agents to autonomously orchestrate queries across heterogeneous data. A synchronized Verifiable Knowledge Base (VKB) enables a cell-wise verification protocol that precisely quantifies factual reliability, distinguishing systematic reasoning failures from parametric hallucinations. Our evaluations across leading MLLMs reveal a critical \textit{retrieval-reasoning trade-off}: the cognitive load of autonomous retrieval significantly erodes instruction retention. VeriTrip provides the rigorous foundation necessary for the next generation of planning agents capable of operating in unconstrained, multimodal environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VeriTrip, a verifiable benchmark for travel planning agents operating over unstructured multimodal web corpora. It establishes a Multimodal Retrieval Base (MRB) derived from real-world sources and a synchronized Verifiable Knowledge Base (VKB) supporting cell-wise verification to quantify factual reliability while distinguishing systematic reasoning failures from parametric hallucinations. Evaluations on leading MLLMs are claimed to reveal a retrieval-reasoning trade-off in which autonomous retrieval erodes instruction retention.
Significance. If the cell-wise verification protocol can be shown to cleanly isolate the claimed error types without inheriting noise from real-world sources, VeriTrip would advance agent evaluation beyond API-centric paradigms by providing a reproducible, evidence-grounded framework for multimodal open-web tasks. The reported trade-off, if robustly measured, would supply a concrete, falsifiable observation useful for agent architecture design.
major comments (2)
- [Abstract, §3] Abstract and §3 (Benchmark Construction): the central claim that the VKB cell-wise verification protocol 'precisely quantifies factual reliability, distinguishing systematic reasoning failures from parametric hallucinations' is load-bearing for attributing the retrieval-reasoning trade-off to agent behavior. No equations, pseudocode, cell-definition rules, synchronization mechanism, or adjudication procedure for handling source contradictions are supplied; without these, mismatches against MRB cells cannot be shown to separate the two error classes rather than reflect benchmark artifacts or inherited noise.
- [§4] §4 (Evaluations): the abstract and provided description contain no quantitative results, error bars, baseline comparisons, or methodology details (e.g., number of agents, query sets, or statistical tests) supporting the trade-off observation or the benchmark's ability to measure factual reliability. This absence prevents assessment of whether the claimed distinction holds in practice.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments correctly identify areas where additional technical detail is required to support the central claims. We address each point below and will incorporate the requested clarifications in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (Benchmark Construction): the central claim that the VKB cell-wise verification protocol 'precisely quantifies factual reliability, distinguishing systematic reasoning failures from parametric hallucinations' is load-bearing for attributing the retrieval-reasoning trade-off to agent behavior. No equations, pseudocode, cell-definition rules, synchronization mechanism, or adjudication procedure for handling source contradictions are supplied; without these, mismatches against MRB cells cannot be shown to separate the two error classes rather than reflect benchmark artifacts or inherited noise.
Authors: We agree that the current manuscript does not supply the requested formal specifications. While §3 describes the high-level construction of the MRB and synchronized VKB, it lacks explicit equations, pseudocode, cell-definition rules, the synchronization mechanism, and the adjudication procedure for contradictions. In the revision we will add a dedicated subsection (approximately §3.3) that includes: (i) the formal definition of VKB cells, (ii) pseudocode for the cell-wise verification protocol, (iii) the synchronization rules between MRB and VKB, and (iv) the procedure for resolving source contradictions. These additions will make explicit how the protocol attributes mismatches to reasoning failures versus parametric hallucinations. revision: yes
-
Referee: [§4] §4 (Evaluations): the abstract and provided description contain no quantitative results, error bars, baseline comparisons, or methodology details (e.g., number of agents, query sets, or statistical tests) supporting the trade-off observation or the benchmark's ability to measure factual reliability. This absence prevents assessment of whether the claimed distinction holds in practice.
Authors: We acknowledge that neither the abstract nor the high-level description in the submitted version includes quantitative results, error bars, baseline comparisons, or the requested methodological details. Although §4 reports evaluations on leading MLLMs that illustrate the retrieval-reasoning trade-off, these elements are not presented with sufficient granularity. In the revised manuscript we will expand §4 to include: tables with quantitative metrics and error bars (or confidence intervals), explicit counts of agents and query sets, baseline comparisons, and any statistical tests performed. This will enable readers to evaluate both the trade-off observation and the benchmark's ability to isolate the claimed error types. revision: yes
Circularity Check
No significant circularity; benchmark definitions are independent
full rationale
The paper presents VeriTrip as a constructed benchmark with MRB derived from real-world sources and a synchronized VKB with cell-wise verification. No equations, parameter fits, self-citations, or uniqueness theorems appear in the provided text that would reduce any claim to its own inputs by construction. The retrieval-reasoning trade-off is reported from evaluations rather than derived tautologically. The central components are defined externally to the results they evaluate, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing benchmarks fail to account for information noise, multi-source factual contradictions, and the necessity of grounding visual perception into logical planning.
invented entities (2)
-
Multimodal Retrieval Base (MRB)
no independent evidence
-
Verifiable Knowledge Base (VKB)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A review of prominent paradigms for llm-based agents: Tool use, planning (including rag), and feedback learning
Xinzhe Li. A review of prominent paradigms for llm-based agents: Tool use, planning (including rag), and feedback learning. InProc. COLING, pages 9760–9779, 2025
2025
-
[2]
Rap: Retrieval-augmented planner for adaptive procedure planning in instructional videos
Ali Zare, Yulei Niu, Hammad Ayyubi, and Shih-fu Chang. Rap: Retrieval-augmented planner for adaptive procedure planning in instructional videos. InEuropean Conference on Computer Vision, pages 410–426. Springer, 2024
2024
-
[3]
DeepResearch Bench: A Comprehensive Benchmark for Deep Research Agents
Mingxuan Du, Benfeng Xu, Chiwei Zhu, Xiaorui Wang, and Zhendong Mao. Deepresearch bench: A comprehensive benchmark for deep research agents.arXiv preprint arXiv:2506.11763, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Kartik Narayan, Yang Xu, Tian Cao, Kavya Nerella, Vishal M Patel, Navid Shiee, Peter Grasch, Chao Jia, Yinfei Yang, and Zhe Gan. Deepmmsearch-r1: Empowering multimodal llms in multimodal web search.arXiv preprint arXiv:2510.12801, 2025
-
[5]
Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
Wenlin Zhang, Xiaopeng Li, Yingyi Zhang, Pengyue Jia, Yichao Wang, Huifeng Guo, Yong Liu, and Xiangyu Zhao. Deep research: A survey of autonomous research agents.arXiv preprint arXiv:2508.12752, 2025
-
[6]
Travelplanner: A benchmark for real-world planning with language agents
Jian Xie, Kai Zhang, Jiangjie Chen, Tinghui Zhu, Renze Lou, Yuandong Tian, Yanghua Xiao, and Yu Su. Travelplanner: A benchmark for real-world planning with language agents. InProc. ICML, 2024
2024
-
[7]
Jie-Jing Shao, Bo-Wen Zhang, Xiao-Wen Yang, Baizhi Chen, Si-Yu Han, Wen-Da Wei, Guohao Cai, Zhenhua Dong, Lan-Zhe Guo, and Yu-feng Li. Chinatravel: An open-ended benchmark for language agents in chinese travel planning.arXiv preprint arXiv:2412.13682, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Triptailor: A real-world benchmark for personalized travel planning
Kaimin Wang, Yuanzhe Shen, Changze Lv, Xiaoqing Zheng, and Xuanjing Huang. Triptailor: A real-world benchmark for personalized travel planning. InProc. ACL Findings, pages 9705–9723. Proc. ACL, 2025
2025
-
[9]
Personal large language model agents: A case study on tailored travel planning
Harmanpreet Singh, Nikhil Verma, Yixiao Wang, Manasa Bharadwaj, Homa Fashandi, Kevin Ferreira, and Chul Lee. Personal large language model agents: A case study on tailored travel planning. InProc. EMNLP, pages 486–514, 2024
2024
-
[10]
OpenAI. Gpt-4o. https://platform.openai.com/docs/models/gpt-4o, 2024. OpenAI platform
2024
-
[11]
Claude-4.5-sonnet
Anthropic. Claude-4.5-sonnet. https://www.anthropic.com/ claude-sonnet-4-5-system-card, 2025. Claude-4.5-Sonnet system card
2025
-
[12]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Travelagent: An ai assistant for personalized travel planning.arXiv preprint arXiv:2409.08069, 2024
Aili Chen, Xuyang Ge, Ziquan Fu, Yanghua Xiao, and Jiangjie Chen. Travelagent: An ai assistant for personalized travel planning.arXiv preprint arXiv:2409.08069, 2024. 10
-
[14]
Yincen Qu, Huan Xiao, Feng Li, Hui Zhou, and Xiangying Dai. Tripscore: Benchmark- ing and rewarding real-world travel planning with fine-grained evaluation.arXiv preprint arXiv:2510.09011, 2025
-
[15]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[16]
BrowseComp: A Simple Yet Challenging Benchmark for Browsing Agents
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents.arXiv preprint arXiv:2504.12516, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Liana Patel, Negar Arabzadeh, Harshit Gupta, Ankita Sundar, Ion Stoica, Matei Zaharia, and Carlos Guestrin. Deepscholar-bench: A live benchmark and automated evaluation for generative research synthesis.arXiv preprint arXiv:2508.20033, 2025
-
[18]
Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent
Zijian Chen, Xueguang Ma, Shengyao Zhuang, Ping Nie, Kai Zou, Sahel Sharifymoghaddam, Andrew Liu, Joshua Green, Kshama Patel, Ruoxi Meng, Mingyi Su, Yanxi Li, Haoran Hong, Xinyu Shi, Xuye Liu, Nandan Thakur, Crystina Zhang, Luyu Gao, Wenhu Chen, and Jimmy Lin. Browsecomp-plus: A more fair and transparent evaluation benchmark of deep-research agent. InFirs...
2025
-
[19]
João Coelho, Jingjie Ning, Jingyuan He, Kangrui Mao, Abhijay Paladugu, Pranav Setlur, Jiahe Jin, Jamie Callan, João Magalhães, Bruno Martins, et al. Deepresearchgym: A free, transparent, and reproducible evaluation sandbox for deep research.arXiv preprint arXiv:2505.19253, 2025
-
[20]
Qwen blog
Alibaba Group Qwen Team.https://qwen.ai/blog?id=qwen3-vl, 2025. Qwen blog
2025
-
[21]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Amap api.https://lbs.amap.com/, 2025-9
AMap. Amap api.https://lbs.amap.com/, 2025-9. Webpage of AMap API
2025
-
[23]
Gpt-4.5-preview
OpenAI. Gpt-4.5-preview. https://platform.openai.com/docs/models/gpt-4. 5-preview, 2024. OpenAI platform
2024
-
[24]
Chatgpt.https://openai.com/index/gpt-4o-mini, 2025
OpenAI. Chatgpt.https://openai.com/index/gpt-4o-mini, 2025. OpenAI blog
2025
-
[25]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Gpt-4o mini: advancing cost-efficient intelligence, 2024
OpenAI. Gpt-4o mini: advancing cost-efficient intelligence, 2024. OpenAI platform
2024
-
[27]
Claude-3.7-sonnet
Anthropic. Claude-3.7-sonnet. https://www.anthropic.com/news/ claude-3-7-sonnet, 2025. Claude blog
2025
-
[28]
Openai o3
OpenAI. Openai o3. https://openai.com/index/openai-o3-mini/, 2025. OpenAI platform
2025
-
[29]
Openai o4-mini
OpenAI. Openai o4-mini. https://platform.openai.com/docs/models/o4-mini, 2025. OpenAI platform
2025
-
[30]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, et al. Qwen3 embedding: Advancing text embedding and reranking through foundation models.arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[31]
Tevatron 2.0: Unified document retrieval toolkit across scale, language, and modality
Xueguang Ma, Luyu Gao, Shengyao Zhuang, Jiaqi Samantha Zhan, Jamie Callan, and Jimmy Lin. Tevatron 2.0: Unified document retrieval toolkit across scale, language, and modality. In Proc. SIGIR, pages 4061–4065, 2025
2025
-
[32]
hallucination
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. InProc. ICLR, 2025. 11 This Appendix contains the following sections: • Section A: Societal Impact Statement • Section B: Benchma...
2025
-
[33]
Contextual Bias and Visual Hallucination The most significant failure mode observed is contextual hallucination, where the model’s strong textual priors override visual evidence. In the Boston itinerary query(Figure 6a), the user provided three images: the Museum of Fine Arts, the Boston Public Garden, and the Griffith Observatory (a landmark located in L...
-
[34]
hutongs", it failed to recognize the specific instance (“Wu- daoying
Limitations in Fine-Grained Entity Recognition The second failure mode highlights the trade-off between generic scene recognition and specific entity linking(Figure 6b). The user provided an image of Wudaoying Hutong—a specific, culturally significant alley in Beijing known for its distinct architecture and shops. While the model correctly 9https://github...
-
[35]
Final Result
The document ID was generated by the hallucination. As shown in Figure 7, although the tool has returned the retrieved IDs for the model, the model lazily uses simple numbers 1, 2, and 3 for labeling instead. E Prompt List E.1 SYSTEM PROMPT We provide the system prompt of agents as follows: 4 (a) Image comprehension error case 1 from o3. (b) Image compreh...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.