MemTrace: Tracing and Attributing Errors in Large Language Model Memory Systems
Pith reviewed 2026-06-29 12:23 UTC · model grok-4.3
The pith
MemTrace converts LLM memory pipelines into graphs to trace information flow, locate failure causes, and auto-fix prompts for gains up to 7.62%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Memory pipelines can be represented as executable memory evolution graphs that make operational information flow traceable; an iterative subgraph-tracing attribution method then identifies the root operation causing any failed case; these attributions expose systematic failure modes such as information loss and retrieval misalignment; feeding the signals into prompt optimization creates a closed loop that corrects the faults and raises end-task performance.
What carries the argument
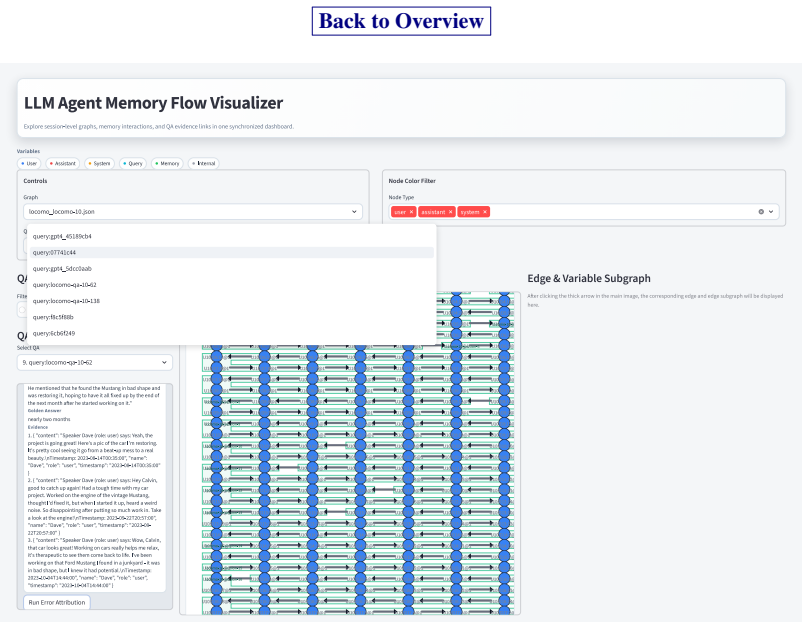
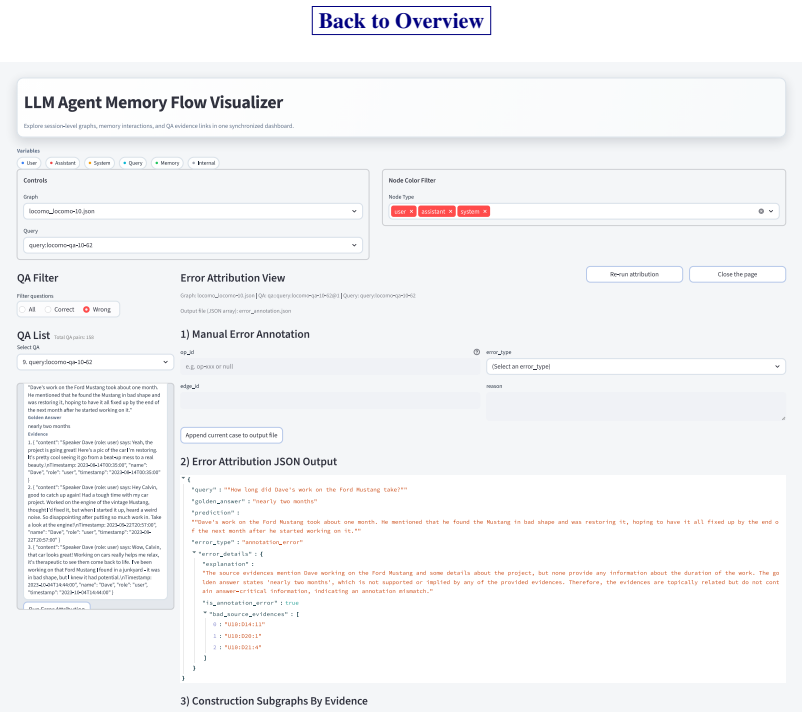
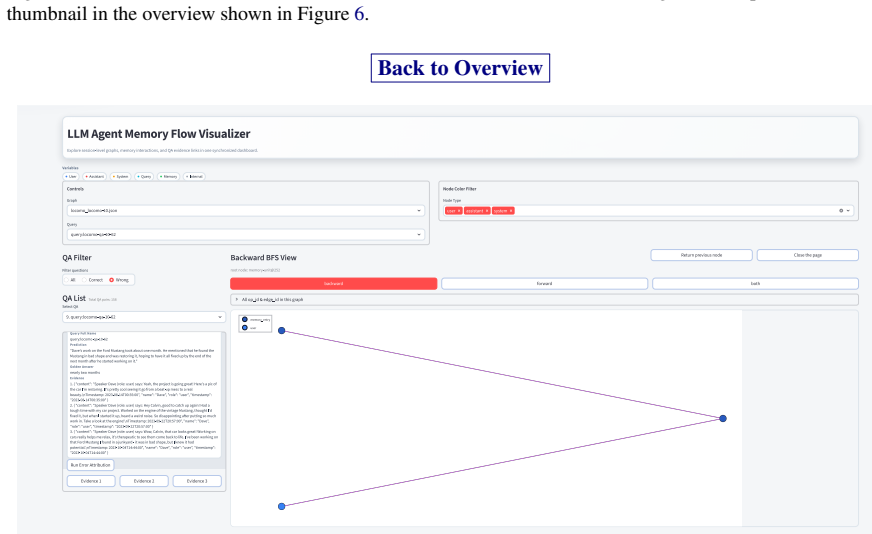
executable memory evolution graphs that represent memory pipelines and support fine-grained tracing of operation-level information flow
If this is right
- Memory failures arise systematically from operation-level problems such as information loss and retrieval misalignment.
- Iterative tracing of operation subgraphs isolates the precise root cause for any observed failure.
- Attribution signals can be fed directly into prompt optimization to form an automatic correction loop.
- End-task performance improves by up to 7.62 percent once the identified faults are corrected.
Where Pith is reading between the lines
- The same graph representation could be applied to trace errors inside other LLM pipelines such as tool-use chains or multi-agent workflows.
- MemTraceBench offers a reusable test bed for comparing the reliability of future memory architectures.
- Closed-loop attribution may reduce the amount of human inspection needed when deploying memory-augmented models in production.
Load-bearing premise
Converting a memory pipeline into a graph accurately records how information actually moves and lets the tracing method correctly name the operation that caused a failure.
What would settle it
A controlled test in which the attribution method names one operation as the root cause, the corresponding prompt is edited, and the original failure either persists or the task score does not rise.
Figures

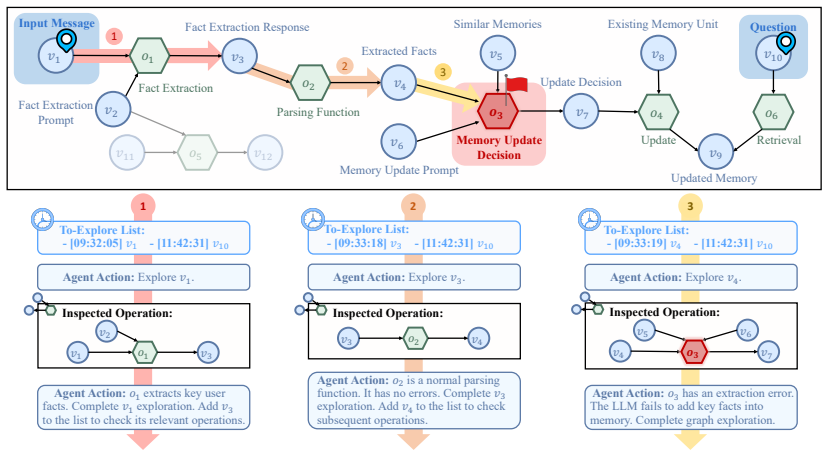

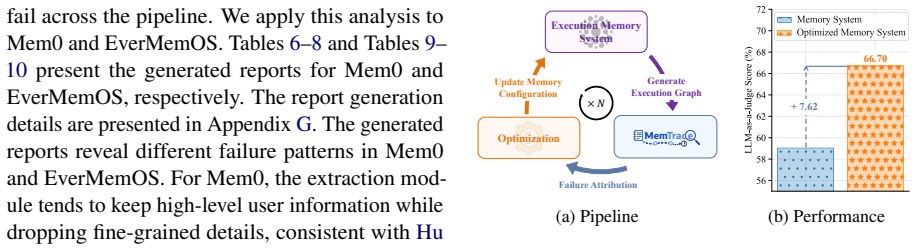
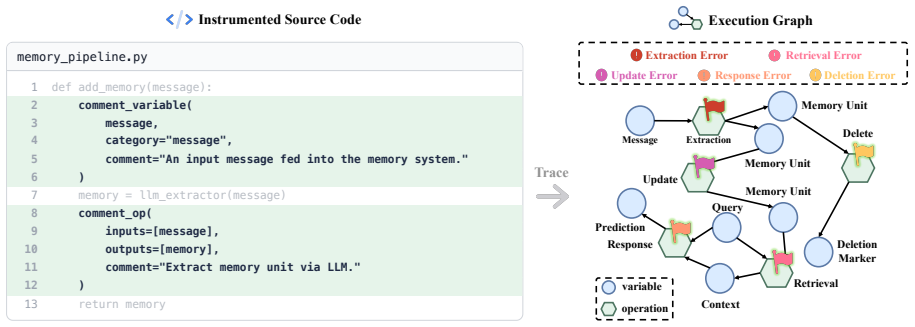

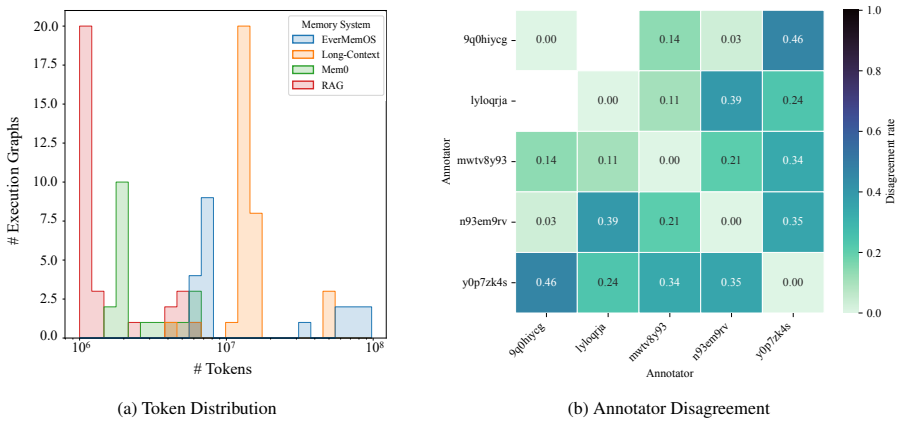




read the original abstract
Memory is essential for enabling large language models to support long-horizon reasoning, yet existing memory systems remain unreliable and difficult to debug. Tracing memory's dynamic evolution is crucial to understand how information is synthesized, propagated, or corrupted over time. In this work, we study the new problem of error tracing and attribution in LLM memory systems. We propose a novel framework that transforms memory pipelines into executable memory evolution graphs, enabling fine-grained tracing of operational information flow. We then construct MemTraceBench, a benchmark collected from representative memory systems such as Long-Context, RAG, Mem0, and EverMemOS, to systematically study memory failure modes. We further introduce an automatic attribution method that iteratively traces operation subgraphs to pinpoint the root cause of any failed case. Our analysis reveals that memory failures are systematic, stemming from operation-level issues like information loss and retrieval misalignment. Crucially, we leverage these fine-grained attribution signals to guide downstream prompt optimization, establishing a closed-loop system that automatically corrects faults and boosts end-task performance by up to 7.62%. Code will be released at https://github.com/zjunlp/MemTrace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MemTrace, a framework for tracing and attributing errors in LLM memory systems. It transforms memory pipelines into executable memory evolution graphs to enable fine-grained tracing of operational information flow, constructs MemTraceBench from representative systems including Long-Context, RAG, Mem0, and EverMemOS, develops an automatic attribution method that iteratively traces operation subgraphs to identify root causes such as information loss and retrieval misalignment, and applies these signals in a closed-loop prompt optimization system that boosts end-task performance by up to 7.62%. Code release is planned.
Significance. If the attribution method is shown to be reliable, the work could meaningfully improve debugging of LLM memory systems for long-horizon reasoning. The construction of MemTraceBench and planned code release are explicit strengths supporting reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: the central claim that fine-grained attribution signals from memory evolution graphs enable a closed-loop system boosting performance by up to 7.62% is load-bearing, yet no precision/recall, human agreement, or ablation results are reported to show that corrections based on these attributions outperform generic prompt optimization or that the graphs faithfully capture dynamic flow.
- [Abstract] The automatic attribution method (iterative subgraph tracing) is presented as identifying operation-level failure causes, but without ground-truth validation on MemTraceBench or comparison to alternative tracing approaches, it is unclear whether the reported gains can be attributed to the framework rather than other factors.
minor comments (1)
- [Abstract] The abstract mentions 'systematic' failure modes but does not specify the criteria or statistical tests used to establish systematicity across the benchmark.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback. We address the major comments point by point below, agreeing that additional validation will strengthen the claims regarding the attribution method and performance gains.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that fine-grained attribution signals from memory evolution graphs enable a closed-loop system boosting performance by up to 7.62% is load-bearing, yet no precision/recall, human agreement, or ablation results are reported to show that corrections based on these attributions outperform generic prompt optimization or that the graphs faithfully capture dynamic flow.
Authors: We agree that the abstract's performance claim would benefit from explicit supporting metrics. The manuscript presents case studies showing how evolution graphs trace information flow and how attributions guide corrections, but does not include aggregate precision/recall or human agreement. In the revised manuscript we will add these evaluations on MemTraceBench along with an ablation comparing attribution-guided optimization against generic prompt optimization baselines. revision: yes
-
Referee: [Abstract] The automatic attribution method (iterative subgraph tracing) is presented as identifying operation-level failure causes, but without ground-truth validation on MemTraceBench or comparison to alternative tracing approaches, it is unclear whether the reported gains can be attributed to the framework rather than other factors.
Authors: MemTraceBench is built from systems with documented failure modes, and the attribution method is illustrated on those cases. However, the manuscript does not report quantitative ground-truth validation or head-to-head comparisons with other tracing techniques. We will incorporate such validation (using operation-level labels in the benchmark) and comparisons to alternative approaches in the revision to clarify the source of the observed gains. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and text describe an empirical framework for memory error tracing via executable graphs, benchmark construction from existing systems, an iterative subgraph attribution method, and downstream prompt optimization yielding up to 7.62% gains. No equations, derivations, or self-referential definitions are present that reduce any claimed result to its inputs by construction. No self-citations, ansatzes, or fitted inputs presented as predictions appear. The performance figure is reported as an experimental outcome from applying the method, not a tautological or load-bearing self-defined quantity. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Memory pipelines in LLMs can be represented as sequences of discrete operations whose information flow can be tracked.
invented entities (1)
-
memory evolution graphs
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Monitoring Reasoning Models for Misbehavior and the Risks of Promoting Obfuscation
Monitoring reasoning models for misbehav- ior and the risks of promoting obfuscation.ArXiv, abs/2503.11926. Yuanchen Bei, Tianxin Wei, Xuying Ning, Yanjun Zhao, Zhining Liu, Xiao Lin, Yada Zhu, Hendrik Hamann, Jingrui He, and Hanghang Tong. 2026. Mem-gallery: Benchmarking multimodal long-term conversational memory for mllm agents.ArXiv, abs/2601.03515. Ha...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Trace is the next autodiff: Generative optimiza- tion with rich feedback, execution traces, and llms. InAdvances in Neural Information Processing Sys- tems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024. Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Who is introducing the failure? automatically attributing failures of multi-agent systems via spec- trum analysis.ArXiv, abs/2509.13782. Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Yuanzhuo Wang, and Jian Guo. 2024. A survey on llm-as-a-judge.ArXiv, abs/2411.15594. Bernal Jime...
-
[4]
Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks.ArXiv, abs/2602.16313. Chuanrui Hu, Xingze Gao, Zuyi Zhou, Dannong Xu, Yi Bai, Xintong Li, Hui Zhang, Tong Li, Chong Zhang, Lidong Bing, and Yafeng Deng. 2026a. Ev- ermemos: A self-organizing memory operating sys- tem for structured long-horizon reasoning.ArXiv, abs/2601....
-
[5]
LLMs Get Lost In Multi-Turn Conversation
ACM. Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. 2025. Llms get lost in multi-turn conversation.ArXiv, abs/2505.06120. Yoonho Lee, Roshen Nair, Qizheng Zhang, Kangwook Lee, Omar Khattab, and Chelsea Finn. 2026. Meta- harness: End-to-end optimization of model harnesses. arXiv preprint arXiv:2603.28052. Patrick Lewis, Ethan Perez, Al...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024
Let’s verify step by step. InThe Twelfth In- ternational Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. Open- Review.net. Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao
2024
-
[7]
SimpleMem: Efficient Lifelong Memory for LLM Agents
Simplemem: Efficient lifelong memory for llm agents.ArXiv, abs/2601.02553. Junming Liu, Yifei Sun, Weihua Cheng, Haodong Lei, Yirong Chen, Licheng Wen, Xuemeng Yang, Daocheng Fu, Pinlong Cai, Nianchen Deng, Yi Yu, Shuyue Hu, Botian Shi, and Ding Wang. 2025. Mem- verse: Multimodal memory for lifelong learning agents.ArXiv, abs/2512.03627. Nelson F. Liu, Ke...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Evaluating very long-term conversational memory of LLM agents. InProceedings of the 62nd Annual Meeting of the Association for Com- putational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, pages 13851–13870. Association for Computational Lin- guistics. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. 2022...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D
mlsys.org. Parth Sarthi, Salman Abdullah, Aditi Tuli, Shubh Khanna, Anna Goldie, and Christopher D. Manning
-
[10]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
RAPTOR: recursive abstractive processing for tree-organized retrieval. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. 12 Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugging- gpt: Solving AI tasks with chatgpt and its friends in hug...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
From flat logs to causal graphs: Hierarchical failure attribution for llm-based multi-agent systems. ArXiv, abs/2602.23701. Yu Wang and Xi Chen. 2025. Mirix: Multi-agent memory system for llm-based agents.ArXiv, abs/2507.07957. Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Gra- ham Neubig. 2025d. Agent workflow memory. In Forty-second International Con...
-
[12]
A-MEM: Agentic Memory for LLM Agents
Association for Computational Linguistics. Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. 2025. A-mem: Agentic memory for llm agents.ArXiv, abs/2502.12110. Chengrun Yang, Xuezhi Wang, Yifeng Lu, Hanxiao Liu, Quoc V . Le, Denny Zhou, and Xinyun Chen. 2024a. Large language models as optimizers. In The Twelfth International Confe...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
message", 5 comment=
offers a more fine-grained automatic eval- uation by assessing the accuracy of memory ex- traction and memory updating. However, it mainly checks whether target memories can be found in the current memory store through retrieval, which may not always reflect the true system behavior. It also cannot reveal when an error is introduced or which operation cau...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.