CORE: Contrastive Reflection Enables Rapid Improvements in Reasoning
Pith reviewed 2026-06-29 11:45 UTC · model grok-4.3
The pith
Contrastive Reflection improves language model reasoning faster than other methods by turning differences between successful and unsuccessful traces into reusable natural-language insights.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CORE generates insights by contrasting reasoning traces from successful and unsuccessful problem attempts to produce short natural-language statements about effective strategies and constraints. These insights are stored and inserted into prompts for future problems. Across four reasoning tasks the method produces stronger performance than GRPO, GEPA, episodic RAG, and MemRL while requiring fewer rollouts and fewer prompt tokens, with the largest advantages appearing when training data is limited to five or fewer samples.
What carries the argument
Contrastive Reflection, which extracts compact natural-language insights by identifying differences between successful and unsuccessful reasoning traces.
If this is right
- Reasoning improvement becomes possible with far smaller numbers of training examples and model calls than weight-update or prompt-optimization methods require.
- Learned strategies remain in readable natural-language form rather than being encoded only in weights or full stored traces.
- Context usage stays lower because insights are short and abstract instead of full reasoning histories.
- The approach can be applied across multiple reasoning tasks without task-specific retraining of the underlying model.
Where Pith is reading between the lines
- The same contrast mechanism could be applied to other model behaviors beyond reasoning, such as planning or tool use, if suitable success signals exist.
- Because insights are human-readable, they could be inspected or lightly edited by users to accelerate adoption in practice.
- Combining the non-parametric insights with occasional weight updates might produce hybrid gains that neither approach achieves alone.
Load-bearing premise
The natural-language insights produced by contrasting traces are general, accurate, and transferable enough to improve performance on new problems without further editing.
What would settle it
Running CORE on a new set of problems and finding that the generated insights produce no measurable gain over a baseline that receives no insights.
Figures

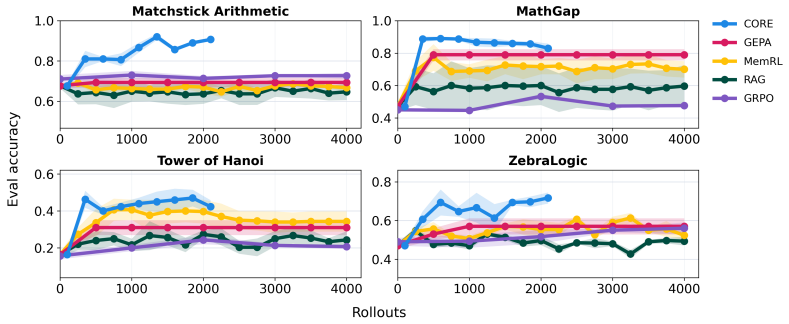
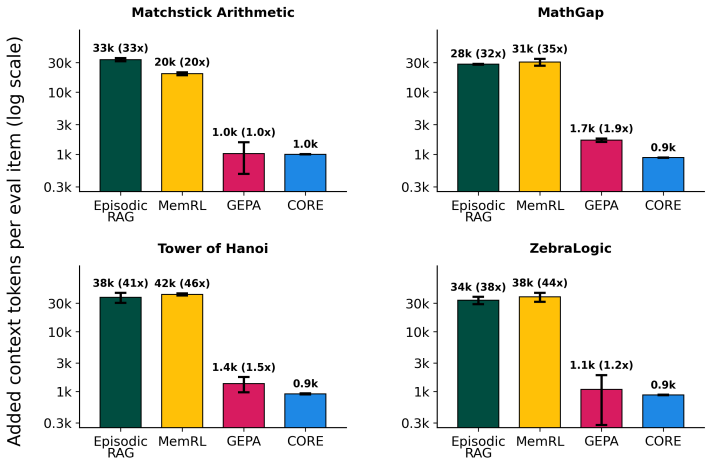
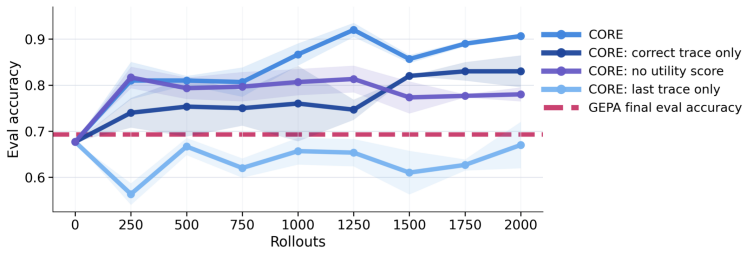


read the original abstract
Language models can use verifiable rewards to improve at a wide variety of reasoning tasks. However, both parametric (e.g. RLVR) and non-parametric (e.g. prompt optimization) approaches to doing so typically require hundreds of training samples and thousands of model rollouts, making them expensive in the best case and intractable in the worst. To address this challenge, we introduce Contrastive Reflection (CORE), a non-parametric learning algorithm that compares past reasoning traces to generate insights: short natural-language descriptions of reasoning strategies and constraints that capture differences between successful and unsuccessful problem attempts. Across four reasoning tasks, we demonstrate that CORE enables more rapid improvement than both parametric (GRPO) and non-parametric (GEPA, episodic RAG, and MemRL) methods, while using fewer rollouts. Under fixed rollout budgets with as few as five training samples, CORE achieves the strongest performance in most task-data regimes. Finally, we highlight how CORE is substantially more context-efficient than non-parametric baselines, requiring fewer prompt tokens while storing learned knowledge as compact, interpretable natural-language insights. Our results therefore suggest that distilling contrasts between successful and unsuccessful reasoning traces into abstract and useful insights can provide a more efficient and interpretable route to model self-improvement than weight updates, prompt optimization, or direct reuse of stored reasoning traces.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Contrastive Reflection (CORE), a non-parametric algorithm that generates short natural-language insights by contrasting successful and unsuccessful reasoning traces from a language model. These insights are then used to improve performance on new problems. Across four reasoning tasks, CORE is reported to achieve stronger results than parametric (GRPO) and non-parametric (GEPA, episodic RAG, MemRL) baselines under fixed rollout budgets, including with as few as five training samples, while requiring fewer rollouts and being more context-efficient by storing compact interpretable insights rather than full traces.
Significance. If the results hold under rigorous controls, the work provides evidence that distilling contrasts into natural-language insights can enable more sample- and rollout-efficient self-improvement than weight updates or direct trace reuse. The emphasis on interpretability and context efficiency is a clear strength relative to baselines that store raw episodes or optimize prompts.
major comments (2)
- [§4.2] §4.2 (Insight Generation Procedure): No mechanism is described for validating or filtering the automatically generated natural-language insights, nor is there an ablation that replaces the generated insights with generic or noisy statements to test whether performance gains with five samples depend on insight accuracy and transferability. This directly bears on the central claim that contrasts yield sufficiently general and accurate insights.
- [§5.1, Table 2] §5.1 and Table 2 (Rollout Budget Comparisons): The claim that CORE uses fewer rollouts than GRPO and GEPA does not clarify whether the cost of generating and contrasting traces to produce insights is included in the budget; if insight generation is counted separately, the efficiency advantage may not hold under the stated fixed-rollout regime.
minor comments (2)
- [Abstract, §5] The abstract and §5 would benefit from explicit reporting of the number of independent runs, standard deviations, and any statistical significance tests supporting the 'strongest performance in most task-data regimes' statement.
- [§3] Notation for the contrastive insight prompt template is introduced without a clear reference to its exact form in an appendix or figure, making reproduction more difficult.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 (Insight Generation Procedure): No mechanism is described for validating or filtering the automatically generated natural-language insights, nor is there an ablation that replaces the generated insights with generic or noisy statements to test whether performance gains with five samples depend on insight accuracy and transferability. This directly bears on the central claim that contrasts yield sufficiently general and accurate insights.
Authors: We agree that an explicit validation mechanism and a control ablation would provide stronger evidence that performance gains derive from the accuracy and transferability of the generated insights rather than from any generic effect of adding natural-language statements. The current manuscript does not contain such an ablation. In the revised version we will add an ablation that replaces CORE-generated insights with generic or noisy statements (e.g., random sentences or paraphrases of the task description) while keeping all other experimental conditions identical, and we will report the resulting performance to quantify the contribution of insight quality. revision: yes
-
Referee: [§5.1, Table 2] §5.1 and Table 2 (Rollout Budget Comparisons): The claim that CORE uses fewer rollouts than GRPO and GEPA does not clarify whether the cost of generating and contrasting traces to produce insights is included in the budget; if insight generation is counted separately, the efficiency advantage may not hold under the stated fixed-rollout regime.
Authors: The rollout budgets reported in §5.1 and Table 2 count only the model calls used to generate reasoning traces for solving training and test problems. Insight generation in CORE reuses the same traces already collected under that budget and does not incur additional rollouts. We will revise the text and table captions to state this accounting explicitly and to confirm that the fixed-rollout comparisons remain valid under this definition. revision: yes
Circularity Check
No circularity: empirical claims rest on external baseline comparisons
full rationale
The paper introduces CORE as an algorithmic procedure that generates natural-language insights by contrasting successful and unsuccessful reasoning traces, then reports empirical performance gains versus independent baselines (GRPO, GEPA, episodic RAG, MemRL) under fixed rollout budgets and small sample regimes. No equations, fitted parameters, or uniqueness theorems are presented that reduce the reported improvements to the method's own inputs by construction. No self-citations are invoked as load-bearing justification for the central mechanism, and the evaluation uses externally defined tasks and metrics. The derivation chain is therefore self-contained against external benchmarks rather than internally referential.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Contrasting successful and unsuccessful reasoning traces produces useful, generalizable natural-language insights.
Reference graph
Works this paper leans on
-
[1]
Reward-motivated learning: mesolimbic activation precedes memory formation
R Alison Adcock, Arul Thangavel, Susan Whitfield-Gabrieli, Brian Knutson, and John DE Gabrieli. Reward-motivated learning: mesolimbic activation precedes memory formation. Neuron, 50(3):507–517, 2006
2006
-
[2]
gpt-oss-120b & gpt-oss-20b Model Card
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, et al. gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Learning through case comparisons: A meta-analytic review.Educational Psychologist, 48(2):87–113, 2013
Louis Alfieri, Timothy J Nokes-Malach, and Christian D Schunn. Learning through case comparisons: A meta-analytic review.Educational Psychologist, 48(2):87–113, 2013
2013
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Rationalization is rational.Behavioral and Brain Sciences, 43:e28, 2020
Fiery Cushman. Rationalization is rational.Behavioral and Brain Sciences, 43:e28, 2020
2020
-
[7]
Aniket Didolkar, Nicolas Ballas, Sanjeev Arora, and Anirudh Goyal. Metacognitive reuse: Turning recurring llm reasoning into concise behaviors.arXiv preprint arXiv:2509.13237, 2025
-
[8]
Scott Emmons, Erik Jenner, David K Elson, Rif A Saurous, Senthooran Rajamanoharan, Heng Chen, Irhum Shafkat, and Rohin Shah. When chain of thought is necessary, language models struggle to evade monitors.arXiv preprint arXiv:2507.05246, 2025
-
[9]
Michael Günther, Jackmin Ong, Isabelle Mohr, Alaeddine Abdessalem, Tanguy Abel, Moham- mad Kalim Akram, Susana Guzman, Georgios Mastrapas, Saba Sturua, Bo Wang, et al. Jina embeddings 2: 8192-token general-purpose text embeddings for long documents.arXiv preprint arXiv:2310.19923, 2023
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Constraint relaxation and chunk decomposition in insight problem solving.Journal of Experimental Psychology: Learning, memory, and cognition, 25(6):1534, 1999
Günther Knoblich, Stellan Ohlsson, Hilde Haider, and Detlef Rhenius. Constraint relaxation and chunk decomposition in insight problem solving.Journal of Experimental Psychology: Learning, memory, and cognition, 25(6):1534, 1999
1999
-
[12]
Chain of Thought Monitorability: A New and Fragile Opportunity for AI Safety
Tomek Korbak, Mikita Balesni, Elizabeth Barnes, Yoshua Bengio, Joe Benton, Joseph Bloom, Mark Chen, Alan Cooney, Allan Dafoe, Anca Dragan, et al. Chain of thought monitorability: A new and fragile opportunity for ai safety.arXiv preprint arXiv:2507.11473, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Tinker, 2025
Thinking Machines Lab. Tinker, 2025. URLhttps://thinkingmachines.ai/tinker/
2025
-
[14]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe twelfth international conference on learning representations, 2023. 11
2023
-
[15]
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. Zebralogic: On the scaling limits of llms for logical reasoning.arXiv preprint arXiv:2502.01100, 2025
-
[16]
The hippocampal-vta loop: controlling the entry of information into long-term memory.Neuron, 46(5):703–713, 2005
John E Lisman and Anthony A Grace. The hippocampal-vta loop: controlling the entry of information into long-term memory.Neuron, 46(5):703–713, 2005
2005
-
[17]
James L McClelland, Bruce L McNaughton, and Randall C O’Reilly. Why there are comple- mentary learning systems in the hippocampus and neocortex: insights from the successes and failures of connectionist models of learning and memory.Psychological review, 102(3):419, 1995
1995
-
[18]
Systematic human learning and generalization from a brief tutorial with explanatory feedback.Open Mind, 8:148–176, 2024
Andrew J Nam and James L McClelland. Systematic human learning and generalization from a brief tutorial with explanatory feedback.Open Mind, 8:148–176, 2024
2024
-
[19]
Leveraging Speech to Identify Signatures of Insight and Transfer in Problem Solving
Linas Nasvytis and Judith E Fan. Leveraging speech to identify signatures of insight and transfer in problem solving.arXiv preprint arXiv:2605.12970, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Investigating the effect of mental set on insight problem solving.Experimental psychology, 55(4):269–282, 2008
Michael Öllinger, Gary Jones, and Günther Knoblich. Investigating the effect of mental set on insight problem solving.Experimental psychology, 55(4):269–282, 2008
2008
-
[21]
Mathgap: Out-of-distribution evaluation on problems with arbitrarily complex proofs
Andreas Opedal, Haruki Shirakami, Bernhard Schölkopf, Abulhair Saparov, and Mrinmaya Sachan. Mathgap: Out-of-distribution evaluation on problems with arbitrarily complex proofs. arXiv preprint arXiv:2410.13502, 2024
-
[22]
Optimizing instructions and demonstrations for multi-stage language model programs
Krista Opsahl-Ong, Michael J Ryan, Josh Purtell, David Broman, Christopher Potts, Matei Zaharia, and Omar Khattab. Optimizing instructions and demonstrations for multi-stage language model programs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 9340–9366, 2024
2024
-
[23]
ReasoningBank: Scaling Agent Self-Evolving with Reasoning Memory
Siru Ouyang, Jun Yan, I Hsu, Yanfei Chen, Ke Jiang, Zifeng Wang, Rujun Han, Long T Le, Samira Daruki, Xiangru Tang, et al. Reasoningbank: Scaling agent self-evolving with reasoning memory.arXiv preprint arXiv:2509.25140, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
A time for telling.Cognition and instruction, 16(4): 475–522, 1998
Daniel L Schwartz and John D Bransford. A time for telling.Cognition and instruction, 16(4): 475–522, 1998
1998
-
[25]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
Taiwei Shi, Sihao Chen, Bowen Jiang, Linxin Song, Longqi Yang, and Jieyu Zhao. Experiential reinforcement learning.arXiv preprint arXiv:2602.13949, 2026
-
[27]
Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.Advances in neural information processing systems, 36:8634–8652, 2023
2023
-
[28]
Parshin Shojaee, Iman Mirzadeh, Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint arXiv:2506.06941, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Andrew Bagnell, Aarti Singh, and Andrea Zanette
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[30]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
Agent Skills for Large Language Models: Architecture, Acquisition, Security, and the Path Forward
Renjun Xu and Yang Yan. Agent skills for large language models: Architecture, acquisition, security, and the path forward.arXiv preprint arXiv:2602.12430, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022
Eric Zelikman, Yuhuai Wu, Jesse Mu, and Noah Goodman. Star: Bootstrapping reasoning with reasoning.Advances in Neural Information Processing Systems, 35:15476–15488, 2022. 12
2022
-
[33]
Useful Memories Become Faulty When Continuously Updated by LLMs
Dylan Zhang, Yanshan Lin, Zhengkun Wu, Yihang Sun, Bingxuan Li, Dianqi Li, and Hao Peng. Useful memories become faulty when continuously updated by llms.arXiv preprint arXiv:2605.12978, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[34]
MemRL: Self-Evolving Agents via Runtime Reinforcement Learning on Episodic Memory
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, et al. Memrl: Self-evolving agents via runtime reinforcement learning on episodic memory.arXiv preprint arXiv:2601.03192, 2026. 13 Appendix Outline • Pseudocode for the CORE algorithm. • Growth of the insight memory across training ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.