Learn from Weaknesses: Automated Domain Specialization for Small Computer-Use Agents
Pith reviewed 2026-06-29 14:12 UTC · model grok-4.3
The pith
Small computer-use agents gain 11 points on average when trained on tasks that target their specific domain weaknesses.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
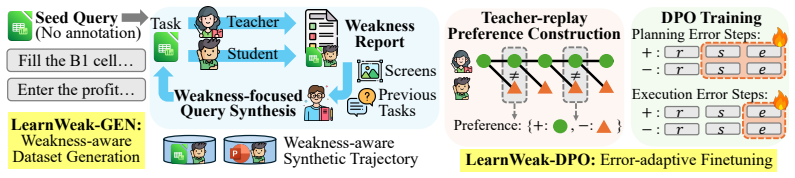
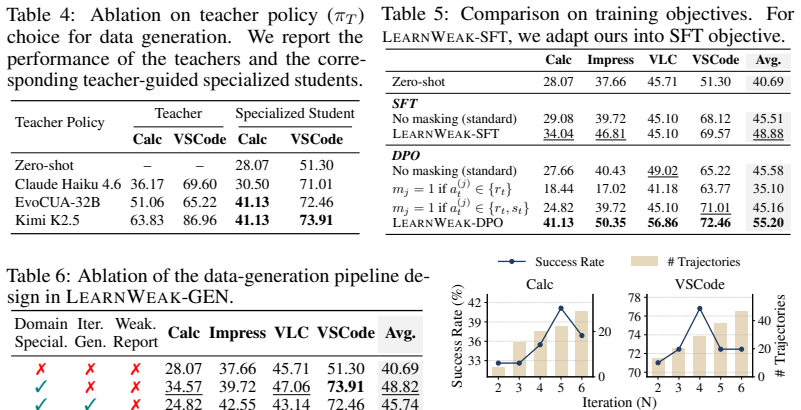
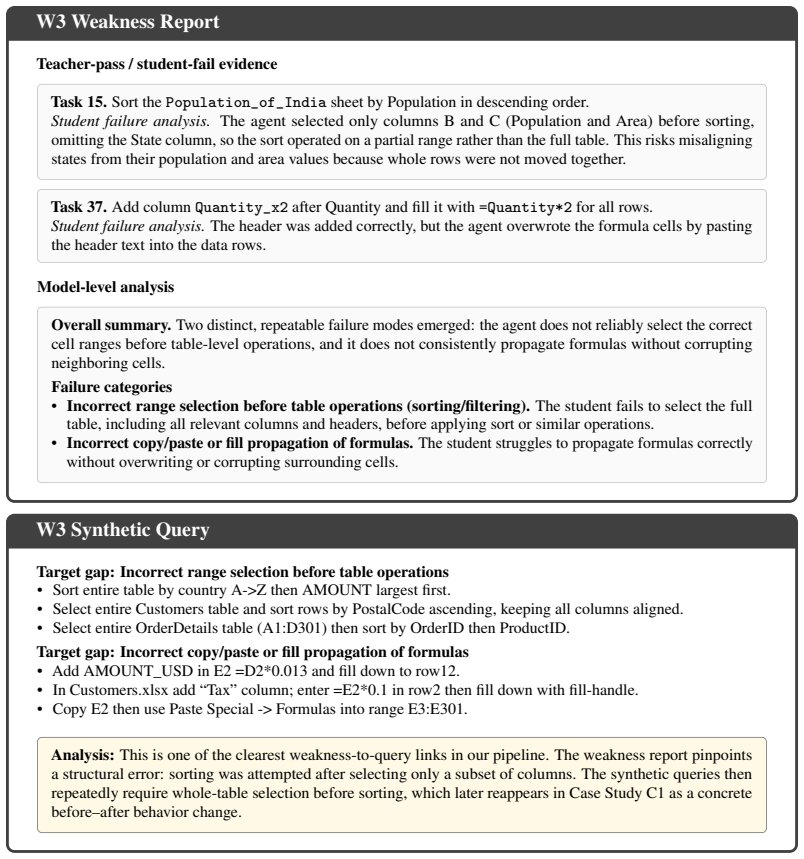
LearnWeak is an annotation-free specialization framework that uses a stronger reference agent to identify the student's weaknesses in the target domain, synthesize targeted tasks, and construct supervision automatically. It further introduces an error-aware specialization objective that disentangles planning and execution errors, enabling more behaviorally precise updates than broad uniform supervision. On OSWorld, LearnWeak achieves average gains of 11.6 and 11.1 percentage points over EvoCUA-8B and OpenCUA-7B, respectively, across eight domains, while also outperforming existing autonomous trajectory generation and training baselines.
What carries the argument
Student-aware dataset generation paired with an error-aware specialization objective that disentangles planning and execution errors.
If this is right
- Targeted tasks based on identified weaknesses produce substantially larger gains than uniform domain data synthesis.
- Disentangling planning and execution errors yields more precise behavioral updates than uniform supervision.
- The full pipeline works across eight OSWorld domains without manual annotations or human feedback.
- Student-aware data generation and training both outperform prior autonomous trajectory baselines.
Where Pith is reading between the lines
- The same weakness-targeting loop could be applied to other agent domains such as web navigation or tool use without domain-specific redesign.
- If the reference agent itself has blind spots, the resulting specialized model may still miss entire classes of failures.
- A single small base agent could be repeatedly specialized for many domains at far lower cost than maintaining separate large experts.
Load-bearing premise
A stronger reference agent can reliably identify the student's weaknesses in the target domain to synthesize effective targeted tasks without introducing bias or missing key failure modes.
What would settle it
Running the same specialization pipeline with a different reference agent or repeated runs that produce inconsistent weakness sets, and observing that the reported performance gains disappear or reverse.
Figures













read the original abstract
Computer-use agents (CUAs) have recently made substantial progress, but deploying a separate large expert for each software domain remains expensive. Small open computer-use agents are more practical specialization targets, but they remain substantially weaker and exhibit uneven domain-specific failures. A straightforward remedy is to synthesize large-scale training data for the target domain, yet we find that this naive approach yields only marginal improvements. Building on this observation, we introduce LearnWeak, an annotation-free specialization framework for small computer-use agents that uses a stronger reference agent to identify the student's weaknesses in the target domain, synthesize targeted tasks, and construct supervision automatically. LearnWeak further introduces an error-aware specialization objective that disentangles planning and execution errors, enabling more behaviorally precise updates than broad uniform supervision. On OSWorld, LearnWeak achieves average gains of 11.6 and 11.1 percentage points over EvoCUA-8B and OpenCUA-7B, respectively, across eight domains. We also validate that our student-aware dataset generation and training approaches outperform existing autonomous trajectory generation and training baselines. Our work highlights the importance of student awareness in both data synthesis and agent training, pointing toward a more principled and efficient path for specializing small computer-use agents in diverse domains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LearnWeak, an annotation-free specialization framework for small computer-use agents. It uses a stronger reference agent to identify the student's domain-specific weaknesses, synthesize targeted tasks, and construct supervision; an error-aware objective then disentangles planning and execution errors for more precise updates. The method is claimed to outperform naive trajectory generation, yielding average gains of 11.6 and 11.1 percentage points over EvoCUA-8B and OpenCUA-7B across eight OSWorld domains, with additional validation against autonomous baselines.
Significance. If the empirical gains are robust and the reference-agent step is reliable, the work offers a practical route to domain specialization of small open agents without per-domain expert models or manual annotation, emphasizing student awareness in both data synthesis and training.
major comments (2)
- [Abstract / Method description] The headline gains (11.6/11.1 pp on OSWorld) depend on the reference agent correctly surfacing the student's failure modes to generate targeted tasks. The manuscript provides no independent verification of this step (e.g., human audit of identified weaknesses, inter-annotator agreement, or ablation on reference-agent quality), leaving the claimed advantage over naive trajectory generation unconfirmed.
- [Abstract] The observation that 'naive approach yields only marginal improvements' is central to motivating LearnWeak, yet the paper does not detail the experimental setup, domains, or error analysis used to establish this baseline result, making it difficult to assess whether the student-aware pipeline's gains are incremental or transformative.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below with clarifications from the manuscript and indicate where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract / Method description] The headline gains (11.6/11.1 pp on OSWorld) depend on the reference agent correctly surfacing the student's failure modes to generate targeted tasks. The manuscript provides no independent verification of this step (e.g., human audit of identified weaknesses, inter-annotator agreement, or ablation on reference-agent quality), leaving the claimed advantage over naive trajectory generation unconfirmed.
Authors: The manuscript already provides indirect but quantitative evidence via the direct comparison to the naive trajectory generation baseline, which employs the identical reference agent and the same eight OSWorld domains yet produces only marginal gains; the performance delta is therefore attributable to the student-aware weakness detection and targeted synthesis steps. We nevertheless agree that explicit verification would increase confidence. In the revised version we will add (i) qualitative examples of weaknesses surfaced by the reference agent, (ii) an ablation that substitutes a weaker reference agent, and (iii) a human audit on a random sample of 50 identified weaknesses together with agreement statistics. These additions will directly address the concern while preserving the existing empirical comparison. revision: yes
-
Referee: [Abstract] The observation that 'naive approach yields only marginal improvements' is central to motivating LearnWeak, yet the paper does not detail the experimental setup, domains, or error analysis used to establish this baseline result, making it difficult to assess whether the student-aware pipeline's gains are incremental or transformative.
Authors: The experimental protocol for the naive baseline is presented in Section 4.2: an equal number of trajectories are generated by the reference agent on randomly sampled tasks drawn from the identical eight OSWorld domains used for LearnWeak, without any weakness detection. Section 5.3 further decomposes the resulting error reductions into planning versus execution categories, showing that the naive method improves execution but leaves planning errors largely unchanged. To improve clarity we will expand Section 4.2 into a dedicated subsection that reports exact trajectory counts, sampling procedure, and additional comparative tables, making the baseline fully reproducible. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical specialization method (LearnWeak) that relies on an external stronger reference agent to identify student weaknesses and synthesize tasks, followed by an error-aware training objective, with results reported as measured gains on the independent external benchmark OSWorld. No self-definitional reductions, fitted parameters renamed as predictions, or load-bearing self-citations appear in the derivation; the central claims rest on observable performance differences rather than inputs that are equivalent by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Agent S2: A Compositional Generalist-Specialist Framework for Computer Use Agents
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. Agent s2: A compositional generalist-specialist framework for computer use agents, 2025. URL https://arxiv.org/abs/2504.00906
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Claude sonnet 4.6 system card, February 2026
Anthropic. Claude sonnet 4.6 system card, February 2026. URL https://anthropic.com/ claude-sonnet-4-6-system-card
2026
-
[3]
Fara-7b: An efficient agentic model for computer use, 2025
Ahmed Awadallah, Yash Lara, Raghav Magazine, Hussein Mozannar, Akshay Nambi, Yash Pandya, Aravind Rajeswaran, Corby Rosset, Alexey Taymanov, Vibhav Vineet, Spencer White- head, and Andrew Zhao. Fara-7b: An efficient agentic model for computer use, 2025. URL https://arxiv.org/abs/2511.19663
-
[4]
Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264, 2024
Rogerio Bonatti, Dan Zhao, Francesco Bonacci, Dillon Dupont, Sara Abdali, Yinheng Li, Yadong Lu, Justin Wagle, Kazuhito Koishida, Arthur Bucker, et al. Windows agent arena: Evaluating multi-modal os agents at scale.arXiv preprint arXiv:2409.08264, 2024
-
[5]
RISK: A Framework for GUI Agents in E-commerce Risk Management
Renqi Chen, Zeyin Tao, Jianming Guo, Jingzhe Zhu, Yiheng Peng, Qingqing Sun, Tianyi Zhang, and Shuai Chen. Risk: A framework for gui agents in e-commerce risk management.arXiv preprint arXiv:2509.21982, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
We- boperator: Action-aware tree search for autonomous agents in web environment, 2025
Mahir Labib Dihan, Tanzima Hashem, Mohammed Eunus Ali, and Md Rizwan Parvez. We- boperator: Action-aware tree search for autonomous agents in web environment, 2025. URL https://arxiv.org/abs/2512.12692. 10
-
[7]
TinyAgent: Function calling at the edge
Lutfi Eren Erdogan, Nicholas Lee, Siddharth Jha, Sehoon Kim, Ryan Tabrizi, Suhong Moon, Coleman Richard Charles Hooper, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. TinyAgent: Function calling at the edge. In Delia Irazu Hernandez Farias, Tom Hope, and Manling Li, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Languag...
2024
-
[8]
doi: 10.18653/v1/2024.emnlp-demo.9
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-demo.9. URL https://aclanthology.org/2024.emnlp-demo.9/
-
[9]
Navigating the digital world as humans do: Universal visual grounding for GUI agents
Boyu Gou, Ruohan Wang, Boyuan Zheng, Yanan Xie, Cheng Chang, Yiheng Shu, Huan Sun, and Yu Su. Navigating the digital world as humans do: Universal visual grounding for GUI agents. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=kxnoqaisCT
2025
-
[10]
Efficient agent training for computer use, 2025
Yanheng He, Jiahe Jin, and Pengfei Liu. Efficient agent training for computer use, 2025. URL https://arxiv.org/abs/2505.13909
-
[11]
Yifei He, Pranit Chawla, Yaser Souri, Subhojit Som, and Xia Song. Scalable data synthesis for computer use agents with step-level filtering.arXiv preprint arXiv:2512.10962, 2025
-
[12]
Lora: Low-rank adaptation of large language models.International Conference on Learning Representations, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.International Conference on Learning Representations, 1(2):3, 2022
2022
-
[13]
Mitigating catastrophic forgetting in large language models with forgetting-aware pruning
Wei Huang, Anda Cheng, and Yinggui Wang. Mitigating catastrophic forgetting in large language models with forgetting-aware pruning. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025,...
-
[14]
Unlocking the power of function vectors for characterizing and mitigating catastrophic forgetting in continual instruction tuning
Gangwei Jiang, Caigao Jiang, Zhaoyi Li, Siqiao Xue, Jun Zhou, Linqi Song, Defu Lian, and Ying Wei. Unlocking the power of function vectors for characterizing and mitigating catastrophic forgetting in continual instruction tuning. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net,...
2025
-
[15]
Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
Leslie Pack Kaelbling, Michael L Littman, and Anthony R Cassandra. Planning and acting in partially observable stochastic domains.Artificial intelligence, 101(1-2):99–134, 1998
1998
-
[16]
Niklas Lauffer, Xiang Deng, Srivatsa Kundurthy, Brad Kenstler, and Jeff Da. Imitation learning for multi-turn lm agents via on-policy expert corrections.arXiv preprint arXiv:2512.14895, 2025
-
[17]
Screenspot-pro: GUI grounding for professional high-resolution computer use
Kaixin Li, Ziyang Meng, Hongzhan Lin, Ziyang Luo, Yuchen Tian, Jing Ma, Zhiyong Huang, and Tat-Seng Chua. Screenspot-pro: GUI grounding for professional high-resolution computer use. In Cathal Gurrin, Klaus Schoeffmann, Min Zhang, Luca Rossetto, Stevan Rudinac, Duc-Tien Dang-Nguyen, Wen-Huang Cheng, Phoebe Chen, and Jenny Benois-Pineau, editors, Proceedin...
-
[18]
On the effects of data scale on ui control agents.Advances in Neural Information Processing Systems, 37:92130–92154, 2024
Wei Li, William Bishop, Alice Li, Chris Rawles, Folawiyo Campbell-Ajala, Divya Tyamagundlu, and Oriana Riva. On the effects of data scale on ui control agents.Advances in Neural Information Processing Systems, 37:92130–92154, 2024
2024
-
[19]
Showui: One vision-language- action model for GUI visual agent
Kevin Qinghong Lin, Linjie Li, Difei Gao, Zhengyuan Yang, Shiwei Wu, Zechen Bai, Stan Weixian Lei, Lijuan Wang, and Mike Zheng Shou. Showui: One vision-language- action model for GUI visual agent. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 19498– 19508. Computer Vision Foundatio...
-
[20]
Jiateng Liu, Zhenhailong Wang, Rushi Wang, Bingxuan Li, Jeonghwan Kim, Aditi Tiwari, Pengfei Yu, Denghui Zhang, and Heng Ji. Osexpert: Computer-use agents learning professional skills via exploration.arXiv preprint arXiv:2603.07978, 2026
-
[21]
Continual gui agents.arXiv preprint arXiv:2601.20732, 2026
Ziwei Liu, Borui Kang, Hangjie Yuan, Zixiang Zhao, Wei Li, Yifan Zhu, and Tao Feng. Continual gui agents.arXiv preprint arXiv:2601.20732, 2026
-
[22]
Yuanjie Lyu, Chengyu Wang, Jun Huang, and Tong Xu. From correction to mastery: Reinforced distillation of large language model agents.arXiv preprint arXiv:2509.14257, 2025
-
[23]
Pptarena: A benchmark for agentic powerpoint editing, 2025
Michael Ofengenden, Yunze Man, Ziqi Pang, and Yu-Xiong Wang. Pptarena: A benchmark for agentic powerpoint editing, 2025. URLhttps://arxiv.org/abs/2512.03042
-
[24]
Introducing gpt -5.4, March 2026
OpenAI. Introducing gpt -5.4, March 2026. URL https://openai.com/index/ introducing-gpt-5-4/
2026
-
[25]
Introducing gpt-5.4 mini and nano, March 2026
OpenAI. Introducing gpt-5.4 mini and nano, March 2026. URL https://openai.com/ index/introducing-gpt-5-4-mini-and-nano/
2026
-
[26]
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[28]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
Stephane Ross, Geoffrey J. Gordon, and J. Andrew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning, 2011. URL https://arxiv.org/abs/ 1011.0686
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[29]
Watch and learn: Learning to use computers from online videos.arXiv preprint arXiv:2510.04673, 2025
Chan Hee Song, Yiwen Song, Palash Goyal, Yu Su, Oriana Riva, Hamid Palangi, and Tomas Pfister. Watch and learn: Learning to use computers from online videos.arXiv preprint arXiv:2510.04673, 2025
-
[30]
Yifan Song, Da Yin, Xiang Yue, Jie Huang, Sujian Li, and Bill Yuchen Lin. Trial and error: Exploration-based trajectory optimization for llm agents, 2024. URL https://arxiv.org/ abs/2403.02502
-
[31]
Os-genesis: Automating GUI agent trajectory construction via reverse task synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, Ben Kao, Guohao Li, Junxian He, Yu Qiao, and Zhiyong Wu. Os-genesis: Automating GUI agent trajectory construction via reverse task synthesis. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, edit...
2025
-
[32]
Zeyi Sun, Yuhang Cao, Jianze Liang, Qiushi Sun, Ziyu Liu, Zhixiong Zhang, Yuhang Zang, Xiaoyi Dong, Kai Chen, Dahua Lin, et al. Coda: Coordinating the cerebrum and cerebellum for a dual-brain computer use agent with decoupled reinforcement learning.arXiv preprint arXiv:2508.20096, 2025
-
[33]
Seagent: Self-evolving computer use agent with autonomous learning from experience
Zeyi Sun, Ziyu Liu, Yuhang Zang, Yuhang Cao, Xiaoyi Dong, Tong Wu, Dahua Lin, and Jiaqi Wang. Seagent: Self-evolving computer use agent with autonomous learning from experience. arXiv preprint arXiv:2508.04700, 2025
-
[34]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[35]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxi- ang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Henry Wu, et al. Opencua: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
-
[38]
OS-ATLAS: foundation action model for generalist GUI agents
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. OS-ATLAS: foundation action model for generalist GUI agents. InThe Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net, 2025. URL https://openreview...
2025
-
[39]
Jingxu Xie, Dylan Xu, Xuandong Zhao, and Dawn Song. Agentsynth: Scalable task generation for generalist computer-use agents.arXiv preprint arXiv:2506.14205, 2025
-
[40]
Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Processing Systems, 37:52040–52094, 2024
2024
-
[41]
Haiyang Xu, Xi Zhang, Haowei Liu, Junyang Wang, Zhaozai Zhu, Shengjie Zhou, Xuhao Hu, Feiyu Gao, Junjie Cao, Zihua Wang, et al. Mobile-agent-v3. 5: Multi-platform fundamental gui agents.arXiv preprint arXiv:2602.16855, 2026
-
[42]
Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials, 2025
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials, 2025. URLhttps://arxiv.org/abs/2412.09605
-
[43]
Taofeng Xue, Chong Peng, Mianqiu Huang, Linsen Guo, Tiancheng Han, Haozhe Wang, Jianing Wang, Xiaocheng Zhang, Xin Yang, Dengchang Zhao, et al. Evocua: Evolving computer use agents via learning from scalable synthetic experience.arXiv preprint arXiv:2601.15876, 2026
-
[44]
Zerogui: Automating online gui learning at zero human cost.arXiv preprint arXiv:2505.23762, 2025
Chenyu Yang, Su Shiqian, Shi Liu, Xuan Dong, Yue Yu, Weijie Su, Xuehui Wang, Zhaoyang Liu, Jinguo Zhu, Hao Li, Wenhai Wang, Yu Qiao, Xizhou Zhu, and Jifeng Dai. Zerogui: Automating online gui learning at zero human cost.arXiv preprint arXiv:2505.23762, 2025
-
[45]
Pei Yang, Hai Ci, and Mike Zheng Shou. macosworld: A multilingual interactive benchmark for gui agents.arXiv preprint arXiv:2506.04135, 2025
-
[46]
Zhen Yang, Zi-Yi Dou, Di Feng, Forrest Huang, Anh Nguyen, Keen You, Omar Attia, Yuhao Yang, Michael Feng, Haotian Zhang, et al. Ferret-ui lite: Lessons from building small on-device gui agents.arXiv preprint arXiv:2509.26539, 2025
-
[47]
WorldGUI: An Interactive Benchmark for Desktop GUI Automation from Any Starting Point
Henry Hengyuan Zhao, Kaiming Yang, Wendi Yu, Difei Gao, and Mike Zheng Shou. Worldgui: An interactive benchmark for desktop gui automation from any starting point, 2026. URL https://arxiv.org/abs/2502.08047
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[48]
Agentdam: Privacy leakage evaluation for autonomous web agents.arXiv preprint arXiv:2503.09780, 2025
Arman Zharmagambetov, Chuan Guo, Ivan Evtimov, Maya Pavlova, Ruslan Salakhutdinov, and Kamalika Chaudhuri. Agentdam: Privacy leakage evaluation for autonomous web agents.arXiv preprint arXiv:2503.09780, 2025
-
[49]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents, 2024. URL https://arxiv.org/abs/ 2307.13854. 13 Appendix Overview This appendix provides supplementary material for the main pape...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
All tasks in the instruction should be completed to get the pass
Analyze the task instruction and set the criteria for task completion. All tasks in the instruction should be completed to get the pass
-
[51]
Decide if the agent correctly completed the task objective (pass/fail)
-
[52]
task_completion_criteria
If fail, provide a SHORT reason (3-4 sentences), concrete and behavior-focused. This should be detailed enough to help the agent improve without seeing the trajectory. Include which sub-task it failed, which component it did not ground correctly, or why the progress got stuck. Return STRICT JSON only, with this exact schema: { "task_completion_criteria": ...
-
[53]
Focus on sub-tasks the agent cannot do reliably
-
[54]
Identify concrete operations the agent misuses or fails to execute
-
[55]
Categories should be notably different from each other
-
[56]
Group repeated failures into reusable categories
-
[57]
Figure 6: Teacher–student weakness summarization prompt
Do not include markdown; return JSON only. Figure 6: Teacher–student weakness summarization prompt. You are evaluating screenshots from a single software domain. Goal: select the screenshots that maximize understanding of the domain’s features and UI components. You will receive candidate screenshots in this pattern: Image 0: <image> Image 1: <image> ... ...
-
[58]
Coverage of distinct major features/workflows
-
[59]
Diversity of visible UI components/layout states
-
[60]
selected_indices
Informational richness (settings/panels/dialogs/menus/output views). Avoid near-duplicates and low-information transitional frames. Return ONLY valid JSON with this schema: { "selected_indices": [int, ...], "reasons": [ { "index": int, "reason": "short reason focused on coverage value" } ] } Figure 7: Screenshot ranking prompt. 19 Goal: - Propose new task...
-
[62]
Student weakness analysis (teacher pass, student fail)
-
[65]
queries": [ {
Extra file/folder/code context from this config (provide_info) Requirements: - Generate exactly Y instructions. - Each instruction must be concise end-user style English. - Do not include more than two simple and easy sub-tasks. - Every instruction must satisfy the workspace/path contract. - Must target one or more weak abilities from the analysis. - Must...
-
[66]
Prior instructions already used (avoid overlap/paraphrase)
-
[67]
Student weakness analysis: (Not used in this run.)
-
[68]
Workspace / path contract
-
[69]
Current docker config array to target
-
[70]
queries": [ {
Extra file/folder/code context from this config (provide_info) Requirements: - Generate exactly Y instructions. - Each instruction must be concise end-user style English. - Do not include more than two simple and easy sub-tasks. - Every instruction must satisfy the workspace/path contract. - Must maximize diversity and novelty versus prior instructions. -...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.