Can LLMs Use Linguistic Uncertainty Markers to Reliably Reflect Intrinsic Confidence?
Pith reviewed 2026-06-29 12:14 UTC · model grok-4.3
The pith
LLMs fail to link uncertainty markers like 'likely' to stable internal confidence levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
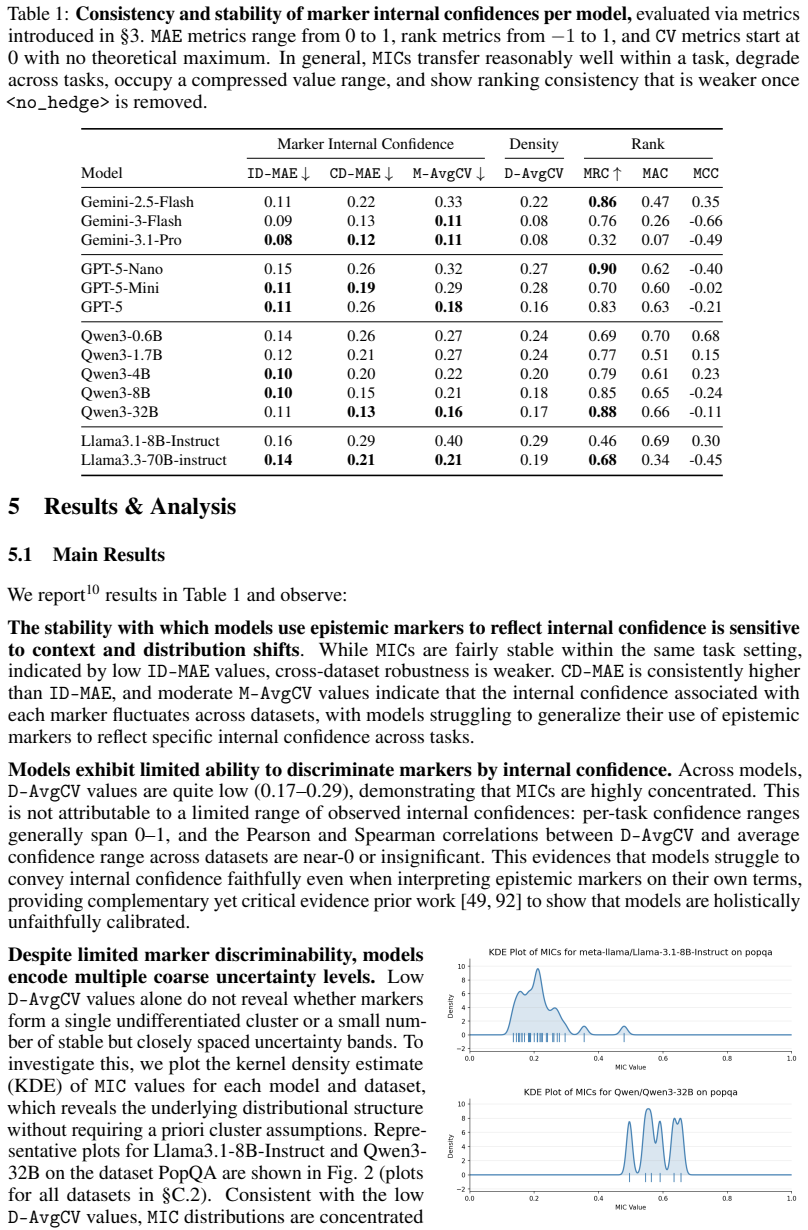
LLMs remain faithfully miscalibrated even under model-centric interpretation of marker meanings, struggling to differentiate markers by internal confidence across distributions despite preserving a somewhat consistent ranking order across tasks.
What carries the argument
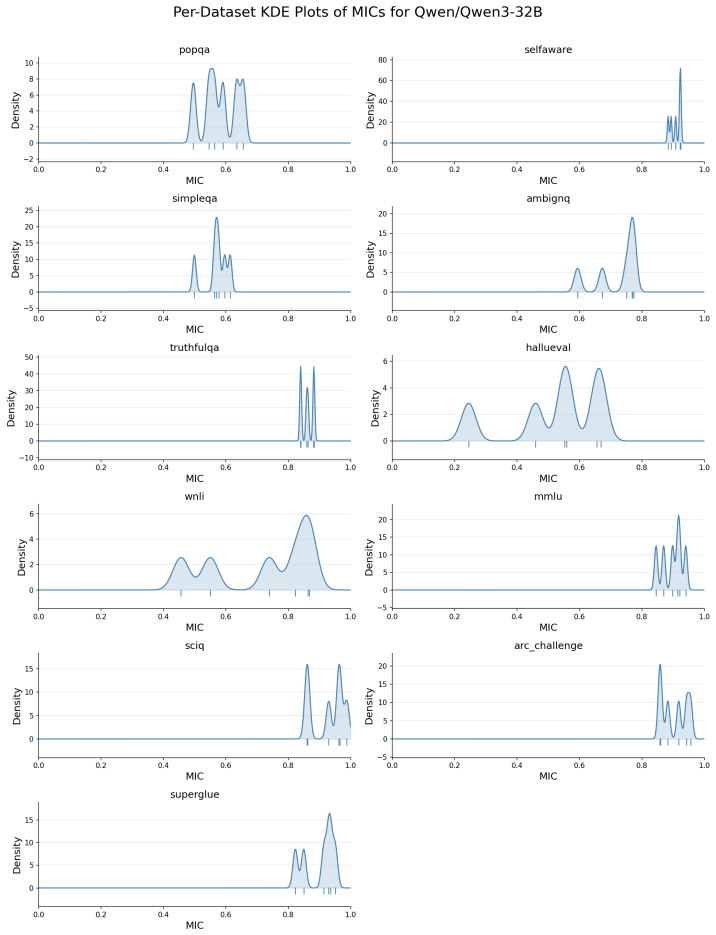
Marker internal confidence (MIC), the estimated intrinsic confidence a model associates with a specific epistemic marker in a given task domain, measured by seven stability metrics within and across distributions.
If this is right
- Models keep a consistent ranking order of markers by associated confidence across different tasks.
- Models cannot reliably differentiate markers by their internal confidence values when distributions change.
- Linguistic expressions of uncertainty stay miscalibrated from the model's own viewpoint.
- Trustworthiness of LLM outputs requires more stable and aligned marker use.
Where Pith is reading between the lines
- Training objectives that only target numeric calibration may leave linguistic calibration untouched.
- Applications that let users read verbal confidence statements could benefit from explicit marker-stability constraints during fine-tuning.
- The same stability metrics could be applied to other forms of model-generated uncertainty language beyond epistemic markers.
Load-bearing premise
The seven metrics can reliably detect and quantify whether marker-to-confidence associations stay stable when viewed from the model's own perspective.
What would settle it
A finding that the seven metrics show distinct MIC values for different markers that remain stable when the same models are tested on new task distributions would falsify the central claim.
Figures












read the original abstract
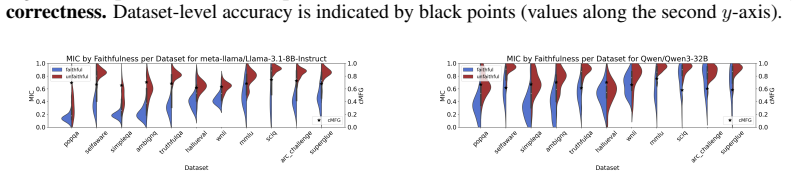
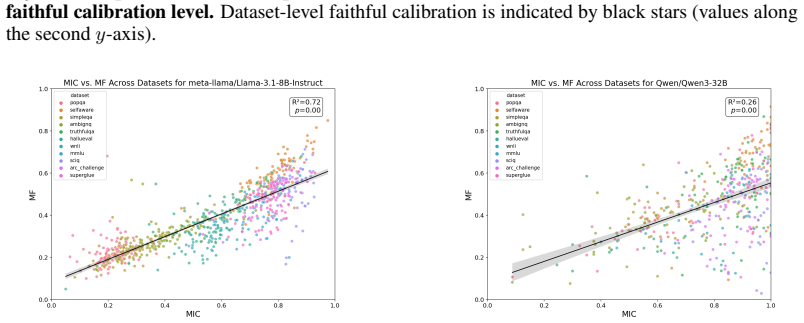
LLMs' linguistically expressed confidence should faithfully reflect their intrinsic uncertainty. While recent work shows LLMs struggle to use epistemic markers (e.g., "it is likely...") in a human-aligned fashion, it remains unclear whether models can apply their own linguistic confidence framework to associate markers with specific confidence levels in a stable and generalizable way, and how contextual features impact this ability. We conduct the first systematic study of this question, formalizing _marker internal confidence_ (MIC) as the estimated intrinsic confidence a model associates with a specific epistemic marker in a given task domain. We present 7 metrics to evaluate the stability of MICs within and across distributions. Applying our analysis framework to diverse models and tasks, we find that LLMs remain faithfully miscalibrated even under model-centric interpretation of marker meanings, struggling to differentiate markers by internal confidence across distributions despite preserving a somewhat consistent ranking order across tasks. This supplies critical, complementary evidence to existing work toward a holistic understanding of faithful calibration in LLMs, emphasizing the need for more aligned and stable marker use to improve trustworthiness and reliability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes Marker Internal Confidence (MIC) as the intrinsic confidence an LLM associates with a given epistemic marker in a task domain. It introduces seven metrics to quantify the stability of these MIC values within and across distributions. Experiments across models and tasks lead to the conclusion that LLMs remain faithfully miscalibrated: they struggle to differentiate markers according to internal confidence levels across distributions, even while preserving a roughly consistent ranking order across tasks.
Significance. If the empirical measurements are robust, the work supplies useful complementary evidence on the limits of linguistic uncertainty expression in LLMs, extending prior calibration studies by adopting an explicitly model-centric interpretation of marker meanings. The emphasis on stability across distributions and the preservation of ranking order are potentially actionable for trustworthiness research.
major comments (1)
- [Abstract] Abstract (paragraph defining MIC and the seven metrics): the central claim that LLMs are 'faithfully miscalibrated' under a model-centric view depends on MIC being an independently estimable intrinsic quantity. The abstract provides no information on whether MIC is computed from token-level probabilities, hidden-state entropy, or solely from patterns of marker selection and prompted self-reports; without this grounding the observed instability could reflect prompt sensitivity rather than a true failure to link markers to internal confidence.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback on the abstract. We address the major comment below and will revise the manuscript to improve clarity.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph defining MIC and the seven metrics): the central claim that LLMs are 'faithfully miscalibrated' under a model-centric view depends on MIC being an independently estimable intrinsic quantity. The abstract provides no information on whether MIC is computed from token-level probabilities, hidden-state entropy, or solely from patterns of marker selection and prompted self-reports; without this grounding the observed instability could reflect prompt sensitivity rather than a true failure to link markers to internal confidence.
Authors: We agree that the abstract is too concise on the grounding of MIC and should explicitly indicate its estimation method to support the model-centric interpretation. In the full manuscript, MIC is formalized in Section 3 as an intrinsic quantity estimated solely from the model's own patterns of marker selection across controlled prompting setups and prompted self-reports within a task domain; it is not derived from token-level probabilities or hidden-state entropy. The seven metrics then evaluate the stability of these estimates. We will revise the abstract to include one additional sentence clarifying this estimation approach, which should address the concern that instability might stem from prompt sensitivity rather than a genuine failure to associate markers with internal confidence levels. revision: yes
Circularity Check
Empirical measurement study with independent definitions and metrics
full rationale
The paper formalizes MIC as an estimated quantity and introduces 7 metrics for stability evaluation, then applies them empirically across models and tasks. No equations, derivations, or self-citations are shown that reduce MIC or the metrics to fitted parameters defined by the same outputs, self-referential definitions, or load-bearing prior work by the authors. The central findings on miscalibration and ranking consistency follow from direct measurement rather than construction from inputs. This is a standard empirical analysis with no detectable circularity per the enumerated patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The internal state of an LLM knows when it’s lying
Amos Azaria and Tom Mitchell. The internal state of an LLM knows when it’s lying. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Findings of the Association for Computational Linguistics: EMNLP 2023, pages 967–976, Singapore, December 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.findings-emnlp.68. URL https:// aclanthology...
-
[2]
Linguistic calibration of long-form generations,
Neil Band, Xuechen Li, Tengyu Ma, and Tatsunori Hashimoto. Linguistic calibration of long-form generations, 2024. URLhttps://arxiv.org/abs/2404.00474
-
[3]
Cycles of thought: Measuring llm confidence through stable explanations, 2024
Evan Becker and Stefano Soatto. Cycles of thought: Measuring llm confidence through stable explanations, 2024. URLhttps://arxiv.org/abs/2406.03441. 9
-
[4]
Perceptions of linguistic uncertainty by language models and humans
Catarina G Belém, Markelle Kelly, Mark Steyvers, Sameer Singh, and Padhraic Smyth. Perceptions of linguistic uncertainty by language models and humans. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 8467–8502, Miami, Florida, USA, November
2024
-
[5]
doi: 10.18653/v1/2024.emnlp-main.483
Association for Computational Linguistics. doi: 10.18653/v1/2024.emnlp-main.483. URLhttps://aclanthology.org/2024.emnlp-main.483/
-
[6]
David V Budescu and Thomas S Wallsten. Consistency in interpretation of probabilistic phrases.Organizational Behavior and Human Decision Processes, 36(3):391–405, 1985. ISSN 0749-5978. doi: https://doi.org/10.1016/0749-5978(85)90007-X. URL https://www. sciencedirect.com/science/article/pii/074959788590007X
-
[7]
Discovering Latent Knowledge in Language Models Without Supervision
Collin Burns, Haotian Ye, Dan Klein, and Jacob Steinhardt. Discovering latent knowledge in language models without supervision, 2024. URL https://arxiv.org/abs/2212.03827
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Carrie J. Cai, Samantha Winter, David Steiner, Lauren Wilcox, and Michael Terry. "hello ai": Uncovering the onboarding needs of medical practitioners for human-ai collaborative decision-making.Proc. ACM Hum.-Comput. Interact., 3(CSCW), November 2019. doi: 10.1145/3359206. URLhttps://doi.org/10.1145/3359206
-
[9]
Finetuning language models to emit linguistic expressions of uncertainty, 2024
Arslan Chaudhry, Sridhar Thiagarajan, and Dilan Gorur. Finetuning language models to emit linguistic expressions of uncertainty, 2024. URLhttps://arxiv.org/abs/2409.12180
-
[10]
Quantifying uncertainty in answers from any language model and enhancing their trustworthiness
Jiuhai Chen and Jonas Mueller. Quantifying uncertainty in answers from any language model and enhancing their trustworthiness. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 5186–5200, Bangkok, Thailand, August
-
[11]
doi: 10.18653/v1/2024.acl-long.283
Association for Computational Linguistics. doi: 10.18653/v1/2024.acl-long.283. URL https://aclanthology.org/2024.acl-long.283/
-
[12]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Matthew Dahl, Varun Magesh, Mirac Suzgun, and Daniel E. Ho. Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models, 2024
2024
-
[14]
Communicating uncertainty using words and numbers.Trends in Cognitive Sciences, 26(6):514–526, 2022
Mandeep K Dhami and David R Mandel. Communicating uncertainty using words and numbers.Trends in Cognitive Sciences, 26(6):514–526, 2022
2022
-
[15]
Jinhao Duan, Hao Cheng, Shiqi Wang, Alex Zavalny, Chenan Wang, Renjing Xu, Bhavya Kailkhura, and Kaidi Xu. Shifting attention to relevance: Towards the predictive uncertainty quantification of free-form large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computation...
- [16]
-
[17]
Perception of probability words, 2023
Wade Fagen-Ulmschneider. Perception of probability words, 2023. URL https://waf.cs. illinois.edu/visualizations/Perception-of-Probability-Words/
2023
- [18]
-
[19]
probable error
Ronald A Fisher. On the" probable error" of a coefficient of correlation deduced from a small sample.Metron, 1:3–32, 1921. 10
1921
-
[20]
Epistemic integrity in large language models
Bijean Ghafouri, Shahrad Mohammadzadeh, James Zhou, Pratheeksha Nair, Jacob-Junqi Tian, Mayank Goel, Reihaneh Rabbany, Jean-François Godbout, and Kellin Pelrine. Epistemic integrity in large language models. InNeurips Safe Generative AI Workshop 2024, 2024. URL https://openreview.net/forum?id=o3wQbxRaKo
2024
-
[21]
Gemini 2.5 flash model card
Google DeepMind. Gemini 2.5 flash model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-2-5-Flash-Model-Card.pdf, 2025
2025
-
[22]
Gemini 3 flash model card
Google DeepMind. Gemini 3 flash model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-Flash-Model-Card.pdf, 2025
2025
-
[23]
Gemini 3.1 pro model card
Google DeepMind. Gemini 3.1 pro model card. https://storage.googleapis.com/ deepmind-media/Model-Cards/Gemini-3-1-Pro-Model-Card.pdf, 2026
2026
-
[24]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravanku- mar, Artem Korenev, Arthur Hinsvark, Arun Rao, Aston Zhang, Aurelien Rodriguez, Austen Gregerson, Ava...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Yashvir S. Grewal, Edwin V . Bonilla, and Thang D. Bui. Improving uncertainty quantification in large language models via semantic embeddings, 2024. URL https://arxiv.org/abs/ 2410.22685
-
[26]
Quantifying uncertainty in natural language explanations of large language models
Sree Harsha Tanneru, Chirag Agarwal, and Himabindu Lakkaraju. Quantifying uncertainty in natural language explanations of large language models. In Sanjoy Dasgupta, Stephan Mandt, and Yingzhen Li, editors,Proceedings of The 27th International Conference on Artificial Intelligence and Statistics, volume 238 ofProceedings of Machine Learning Research, pages...
2024
-
[27]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding, 2021. URL https://arxiv.org/abs/2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[28]
Decom- posing uncertainty for large language models through input clarification ensembling, 2024
Bairu Hou, Yujian Liu, Kaizhi Qian, Jacob Andreas, Shiyu Chang, and Yang Zhang. Decom- posing uncertainty for large language models through input clarification ensembling, 2024. URLhttps://arxiv.org/abs/2311.08718
-
[29]
A survey of uncertainty estimation in llms: Theory meets practice, 2024
Hsiu-Yuan Huang, Yutong Yang, Zhaoxi Zhang, Sanwoo Lee, and Yunfang Wu. A survey of uncertainty estimation in llms: Theory meets practice, 2024. URL https://arxiv.org/ abs/2410.15326
-
[30]
Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qiang- long Chen, Weihua Peng, Xiaocheng Feng, Bing Qin, and Ting Liu. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Trans. Inf. Syst., 43(2), January 2025. ISSN 1046-8188. doi: 10.1145/3703155. URL https://doi.org/...
-
[31]
Yuheng Huang, Jiayang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, and Lei Ma. Look before you leap: An exploratory study of uncertainty analysis for large language models.IEEE Transactions on Software Engineering, 51(2):413–429, February 2025. ISSN 2326-3881. doi: 10.1109/tse.2024.3519464. URL http://dx.doi.org/10.1109/ TSE.2024.3519464
-
[32]
Ziwei Ji, Lei Yu, Yeskendir Koishekenov, Yejin Bang, Anthony Hartshorn, Alan Schelten, Cheng Zhang, Pascale Fung, and Nicola Cancedda. Calibrating verbal uncertainty as a linear feature to reduce hallucinations.arXiv preprint arXiv:2503.14477, 2025
-
[33]
Calibrating language models via augmented prompt ensembles
Mingjian Jiang, Yangjun Ruan, Sicong Huang, Saifei Liao, Silviu Pitis, Roger Baker Grosse, and Jimmy Ba. Calibrating language models via augmented prompt ensembles. 2023. URL https://api.semanticscholar.org/CorpusID:271797871
2023
-
[34]
Conformal linguistic calibration: Trading-off between factuality and specificity, 2025
Zhengping Jiang, Anqi Liu, and Benjamin Van Durme. Conformal linguistic calibration: Trading-off between factuality and specificity, 2025. URL https://arxiv.org/abs/2502. 19110
2025
-
[35]
Assessing the accuracy and reliability of ai-generated medical responses: An evaluation of the chat-gpt model.Research square, page rs.3.rs—2566942, February
Douglas Johnson, Rachel Goodman, J Patrinely, Cosby Stone, Eli Zimmerman, Rebecca Donald, Sam Chang, Sean Berkowitz, Avni Finn, Eiman Jahangir, Elizabeth Scoville, Tyler Reese, Debra Friedman, Julie Bastarache, Yuri van der Heijden, Jordan Wright, Nicholas Carter, Matthew Alexander, Jennifer Choe, Cody Chastain, John Zic, Sara Horst, Isik Turker, Rajiv Ag...
-
[36]
doi: 10.21203/rs.3.rs-2566942/v1
ISSN 2693-5015. doi: 10.21203/rs.3.rs-2566942/v1. URL https://europepmc.org/ articles/PMC10002821
-
[37]
Marie Juanchich, Amélie Gourdon-Kanhukamwe, and Miroslav Sirota. “i am uncer- tain” vs “it is uncertain”. how linguistic markers of the uncertainty source affect un- certainty communication.Judgment and Decision Making, 12(5):445–465, 2017. doi: 10.1017/S1930297500006483
-
[38]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, Scott Johnston, Sheer El-Showk, Andy Jones, Nelson Elhage, Tristan Hume, Anna Chen, Yuntao Bai, Sam Bowman, Stanislav Fort, Deep Ganguli, Danny Hernandez, Josh Jacobson, Jackson Kernion, Shauna Kravec,...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[39]
Cobb, Anirban Roy, Brian Matejek, Manoj Acharya, Daniel Elenius, Alexander Michael Berenbeim, John A
Ramneet Kaur, Colin Samplawski, Adam D. Cobb, Anirban Roy, Brian Matejek, Manoj Acharya, Daniel Elenius, Alexander Michael Berenbeim, John A. Pavlik, Nathaniel D. Bastian, and Susmit Jha. Addressing uncertainty in LLMs to enhance reliability in generative AI. InNeurips Safe Generative AI Workshop 2024, 2024. URL https://openreview.net/ forum?id=Z3DS4Pcxct
2024
-
[40]
Sunnie S. Y . Kim, Q. Vera Liao, Mihaela V orvoreanu, Stephanie Ballard, and Jennifer Wortman Vaughan. "i’m not sure, but...": Examining the impact of large language models’ uncertainty expression on user reliance and trust. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, FAccT ’24, page 822–835, New York, NY , USA,...
-
[41]
To hedge or not to hedge: the use of epistemic modal expressions in popular science in english texts, english–german translations, and german original texts
Svenja Kranich. To hedge or not to hedge: the use of epistemic modal expressions in popular science in english texts, english–german translations, and german original texts. 2011. URL https://api.semanticscholar.org/CorpusID:154907527
2011
-
[42]
Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation
Lorenz Kuhn, Yarin Gal, and Sebastian Farquhar. Semantic uncertainty: Linguistic invariances for uncertainty estimation in natural language generation. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=VD-AYtP0dve
2023
-
[43]
Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. Natural questions: A benchmark for question answering research. Transac...
2019
-
[44]
Hedges: A study in meaning criteria and the logic of fuzzy concepts.Journal of philosophical logic, 2(4):458–508, 1973
George Lakoff. Hedges: A study in meaning criteria and the logic of fuzzy concepts.Journal of philosophical logic, 2(4):458–508, 1973
1973
-
[45]
Hedges in japanese conversation: The influence of age, sex, and formality
Shizuka Lauwereyns. Hedges in japanese conversation: The influence of age, sex, and formality. Language Variation and Change, 14(2):239–259, 2002. doi: 10.1017/S0954394502142049
-
[46]
Are llm-judges robust to expressions of uncertainty? investigating the effect of epistemic markers on llm-based evaluation
Dongryeol Lee, Yerin Hwang, Yongil Kim, Joonsuk Park, and Kyomin Jung. Are llm-judges robust to expressions of uncertainty? investigating the effect of epistemic markers on llm-based evaluation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume ...
2025
-
[47]
The Winograd schema challenge
Hector J Levesque, Ernest Davis, and Leora Morgenstern. The Winograd schema challenge. InAAAI Spring Symposium: Logical Formalizations of Commonsense Reasoning, volume 46, page 47, 2011
2011
-
[48]
LegalAgentBench: Evaluating LLM agents in legal domain
Haitao Li, Junjie Chen, Jingli Yang, Qingyao Ai, Wei Jia, Youfeng Liu, Kai Lin, Yueyue Wu, Guozhi Yuan, Yiran Hu, Wuyue Wang, Yiqun Liu, and Minlie Huang. LegalAgentBench: Evaluating LLM agents in legal domain. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association ...
-
[49]
Halueval: A large-scale hallucination evaluation benchmark for large language models, 2023
Junyi Li, Xiaoxue Cheng, Wayne Xin Zhao, Jian-Yun Nie, and Ji-Rong Wen. Halueval: A large-scale hallucination evaluation benchmark for large language models, 2023. URL https://arxiv.org/abs/2305.11747
-
[50]
TruthfulQA: Measuring how models mimic human false- hoods
Stephanie Lin, Jacob Hilton, and Owain Evans. TruthfulQA: Measuring how models mimic human falsehoods. In Smaranda Muresan, Preslav Nakov, and Aline Villavicen- cio, editors,Proceedings of the 60th Annual Meeting of the Association for Computa- tional Linguistics (Volume 1: Long Papers), pages 3214–3252, Dublin, Ireland, May 2022. Association for Computat...
-
[51]
Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022
Stephanie Lin, Jacob Hilton, and Owain Evans. Teaching models to express their uncertainty in words.Transactions on Machine Learning Research, 2022. ISSN 2835-8856. URL https://openreview.net/forum?id=8s8K2UZGTZ
2022
-
[52]
Gabrielle Kaili-May Liu, Gal Yona, Avi Caciularu, Idan Szpektor, Tim G. J. Rudner, and Arman Cohan. MetaFaith: Faithful natural language uncertainty expression in LLMs. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors, Proceedings of the 2025 Conference on Empirical Methods in Natural Language Process- ing, pages ...
-
[53]
Jiayu Liu, Qing Zong, Weiqi Wang, and Yangqiu Song. Revisiting epistemic markers in confidence estimation: Can markers accurately reflect large language models’ uncertainty? In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volum...
-
[54]
When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories.arXiv preprint, 2022
Alex Mallen, Akari Asai, Victor Zhong, Rajarshi Das, Hannaneh Hajishirzi, and Daniel Khashabi. When not to trust language models: Investigating effectiveness and limitations of parametric and non-parametric memories.arXiv preprint, 2022
2022
-
[55]
SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models
Potsawee Manakul, Adian Liusie, and Mark Gales. SelfCheckGPT: Zero-resource black- box hallucination detection for generative large language models. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 9004–9017, Singapore, December 2023. Association for Computa...
-
[56]
On the probability–quality paradox in language generation
Clara Meister, Gian Wiher, Tiago Pimentel, and Ryan Cotterell. On the probability–quality paradox in language generation. In Smaranda Muresan, Preslav Nakov, and Aline Villav- icencio, editors,Proceedings of the 60th Annual Meeting of the Association for Compu- tational Linguistics (Volume 2: Short Papers), pages 36–45, Dublin, Ireland, May 2022. Associat...
-
[57]
Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau
Sabrina J. Mielke, Arthur Szlam, Emily Dinan, and Y-Lan Boureau. Reducing conversational agents’ overconfidence through linguistic calibration.Transactions of the Association for Computational Linguistics, 10:857–872, 2022. doi: 10.1162/tacl_a_00494. URL https: //aclanthology.org/2022.tacl-1.50/
-
[58]
AmbigQA: Answering ambigu- ous open-domain questions
Sewon Min, Julian Michael, Hannaneh Hajishirzi, and Luke Zettlemoyer. AmbigQA: An- swering ambiguous open-domain questions. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu, editors,Proceedings of the 2020 Conference on Empirical Methods in Nat- ural Language Processing (EMNLP), pages 5783–5797, Online, November 2020. Asso- ciation for Computational ...
-
[59]
Pilar Mur-Dueñas. There may be differences: Analysing the use of hedges in english and spanish research articles.Lingua, 260:103131, 2021. ISSN 0024-3841. doi: https://doi. org/10.1016/j.lingua.2021.103131. URL https://www.sciencedirect.com/science/ article/pii/S0024384121001030
-
[60]
Sirois.Spearman Correlation Coefficients, Differences be- tween
Leann Myers and Maria J. Sirois.Spearman Correlation Coefficients, Differences be- tween. John Wiley & Sons, Ltd, 2014. ISBN 9781118445112. doi: https://doi.org/10. 1002/9781118445112.stat02802. URL https://onlinelibrary.wiley.com/doi/abs/ 10.1002/9781118445112.stat02802
-
[61]
Thu Nguyen Thi Thuy. A corpus-based study on cross-cultural divergence in the use of hedges in academic research articles written by vietnamese and native english-speaking 15 authors.Social Sciences, 7(4), 2018. ISSN 2076-0760. doi: 10.3390/socsci7040070. URL https://www.mdpi.com/2076-0760/7/4/70
-
[62]
Alexander Nikitin, Jannik Kossen, Yarin Gal, and Pekka Marttinen. Kernel language entropy: Fine-grained uncertainty quantification for llms from semantic similarities, 2024. URL https://arxiv.org/abs/2405.20003
-
[63]
Variability in verbal eyewitness confidence.Applied Cognitive Psychology, 38(2):e4190, 2024
Pia Pennekamp, Jamal K Mansour, and Rhiannon J Batstone. Variability in verbal eyewitness confidence.Applied Cognitive Psychology, 38(2):e4190, 2024
2024
-
[64]
Mauricio Rivera, Jean-François Godbout, Reihaneh Rabbany, and Kellin Pelrine. Com- bining confidence elicitation and sample-based methods for uncertainty quantification in misinformation mitigation. In Raúl Vázquez, Hande Celikkanat, Dennis Ulmer, Jörg Tiedemann, Swabha Swayamdipta, Wilker Aziz, Barbara Plank, Joris Baan, and Marie- Catherine de Marneffe,...
-
[65]
Thermometer: Towards universal calibration for large language models, 2024
Maohao Shen, Subhro Das, Kristjan Greenewald, Prasanna Sattigeri, Gregory Wornell, and Soumya Ghosh. Thermometer: Towards universal calibration for large language models, 2024. URLhttps://arxiv.org/abs/2403.08819
-
[66]
Llamas know what gpts don’t show: Surrogate models for confidence estimation, 2023
Vaishnavi Shrivastava, Percy Liang, and Ananya Kumar. Llamas know what gpts don’t show: Surrogate models for confidence estimation, 2023. URL https://arxiv.org/abs/2311. 08877
2023
-
[67]
Averaging correlation coefficients: should fisher’s z transformation be used?Journal of applied psychology, 72(1):146, 1987
N Clayton Silver and William P Dunlap. Averaging correlation coefficients: should fisher’s z transformation be used?Journal of applied psychology, 72(1):146, 1987
1987
-
[68]
Trust me, i’m wrong: High-certainty hallucinations in llms.arXiv preprint arXiv:2502.12964, 2025
Adi Simhi, Itay Itzhak, Fazl Barez, Gabriel Stanovsky, and Yonatan Belinkov. Trust me, i’m wrong: High-certainty hallucinations in llms.arXiv preprint arXiv:2502.12964, 2025
-
[69]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, Alex Beutel, Alex Karpenko, Alex Makelov, Alex Neitz, Alex Wei, Alexandra Barr, Alexandre Kirchmeyer, Ale...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[70]
Zhangde Song, Jieyu Lu, Yuanqi Du, Botao Yu, Thomas M. Pruyn, Yue Huang, Kehan Guo, Xiuzhe Luo, Yuanhao Qu, Yi Qu, Yinkai Wang, Haorui Wang, Jeff Guo, Jingru Gan, Parshin Shojaee, Di Luo, Andres M Bran, Gen Li, Qiyuan Zhao, Shao-Xiong Lennon Luo, Yuxuan Zhang, Xiang Zou, Wanru Zhao, Yifan F. Zhang, Wucheng Zhang, Shunan Zheng, Saiyang Zhang, Sartaaj Takri...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
LACIE: Listener-aware finetuning for cali- bration in large language models
Elias Stengel-Eskin, Peter Hase, and Mohit Bansal. LACIE: Listener-aware finetuning for cali- bration in large language models. InThe Thirty-eighth Annual Conference on Neural Informa- tion Processing Systems, 2024. URL https://openreview.net/forum?id=RnvgYd9RAh
2024
-
[72]
Metacognition and uncertainty communication in humans and large language models.Current Directions in Psychological Science, page 09637214251391158, 2025
Mark Steyvers and Megan AK Peters. Metacognition and uncertainty communication in humans and large language models.Current Directions in Psychological Science, page 09637214251391158, 2025
2025
-
[73]
What large language models know and what people think they know.Nature Machine Intelligence, 7(2):221–231, 2025
Mark Steyvers, Heliodoro Tejeda, Aakriti Kumar, Catarina Belem, Sheer Karny, Xinyue Hu, Lukas W Mayer, and Padhraic Smyth. What large language models know and what people think they know.Nature Machine Intelligence, 7(2):221–231, 2025
2025
-
[74]
An evaluation of estimative uncertainty in large language models.npj Complexity, 3(1):8, 2026
Zhisheng Tang, Ke Shen, and Mayank Kejriwal. An evaluation of estimative uncertainty in large language models.npj Complexity, 3(1):8, 2026
2026
-
[75]
Can large language models express uncertainty like human?arXiv preprint arXiv:2509.24202, 2025
Linwei Tao, Yi-Fan Yeh, Bo Kai, Minjing Dong, Tao Huang, Tom A Lamb, Jialin Yu, Philip HS Torr, and Chang Xu. Can large language models express uncertainty like human?arXiv preprint arXiv:2509.24202, 2025
-
[76]
Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback
Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher Manning. Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. In Houda Bouamor, Juan Pino, and Kalika Bali, editors,Proceedings of the 2023 Conference on Empiri...
2023
-
[77]
doi: 10.18653/v1/2023.emnlp-main.330
Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.330. URLhttps://aclanthology.org/2023.emnlp-main.330/
-
[78]
Fine- tuning language models for factuality
Katherine Tian, Eric Mitchell, Huaxiu Yao, Christopher D Manning, and Chelsea Finn. Fine- tuning language models for factuality. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=WPZ2yPag4K
2024
-
[79]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
SM Tonmoy, SM Zaman, Vinija Jain, Anku Rani, Vipula Rawte, Aman Chadha, and Amitava Das. A comprehensive survey of hallucination mitigation techniques in large language models. arXiv preprint arXiv:2401.01313, 6, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[80]
Preferences and reasons for communicating probabilistic information in verbal or numerical terms.Bulletin of the Psychonomic Society, 31(2):135–138, 1993
Thomas S Wallsten, David V Budescu, Rami Zwick, and Steven M Kemp. Preferences and reasons for communicating probabilistic information in verbal or numerical terms.Bulletin of the Psychonomic Society, 31(2):135–138, 1993
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.