The Abstraction Gap in Vision-Language Causal Reasoning
Pith reviewed 2026-06-29 13:18 UTC · model grok-4.3
The pith
Seven of eight vision-language models show a large gap between fluent causal text and explicit causal chain reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Abstraction Gap metric, computed as the normalized performance difference between the Text-Only Probe and the Chain-Text Probe, exceeds 0.50 for seven of eight evaluated VLMs, with text scores of 6-8 but chain scores below 2.5. Fine-tuning on 45,000 chain-annotated examples fails to close the gap. One model reaches near-zero abstraction gap, demonstrating that the capacity for faithful causal reasoning exists within current VLM architectures and is determined by pretraining and architectural choices.
What carries the argument
The dual-probe methodology (Text-Only Probe for linguistic quality of causal explanations paired with Chain-Text Probe for explicit causal chain generation), quantified by the Abstraction Gap (AG) metric on the CAGE benchmark.
If this is right
- The existence of one model with near-zero AG shows that current VLM architectures can support faithful causal reasoning.
- Fine-tuning on chain-annotated examples alone is insufficient to reduce the abstraction gap for most models.
- Pretraining and architectural choices determine whether a given VLM exhibits high or low abstraction gap on causal tasks.
- CAGE functions as a diagnostic benchmark for measuring the faithfulness of causal reasoning beyond fluent output.
Where Pith is reading between the lines
- If the same gap appears on causal tasks outside CAGE, it may reflect a general limitation in how VLMs connect fluent generation to structured inference.
- Benchmarks that evaluate only explanation fluency risk overestimating causal understanding in deployed VLMs.
- Prioritizing architectures that achieve low abstraction gap could improve reliability in applications requiring visual causal inference.
Load-bearing premise
The Chain-Text Probe isolates faithful causal reasoning rather than testing a different form of text generation or prompting sensitivity.
What would settle it
An experiment in which the model with near-zero AG produces chains that independent verification shows are logically incorrect or incomplete would indicate the low gap does not reflect true causal reasoning ability.
Figures




read the original abstract
Vision-language models (VLMs) generate fluent causal explanations, but current evaluations cannot distinguish linguistic plausibility from faithful causal reasoning. We introduce a dual-probe methodology that isolates these properties. The Text-Only Probe measures linguistic quality. The Chain-Text Probe requires models to first generate explicit causal chains. The Abstraction Gap (AG) metric quantifies the normalized performance difference. Evaluating eight VLMs on CAGE (Causal Abstraction Gap Evaluation), a benchmark of 49,500 questions across 5,500 images spanning Pearl's causal hierarchy, we find seven models exhibit AG exceeding 0.50 with text scores of 6--8 but chain scores below 2.5. Fine-tuning on 45,000 chain-annotated examples fails to close the gap. However, one model achieves near-zero AG. The capability exists within current VLM architectures and depends on pretraining and architectural choices. CAGE provides a diagnostic tool for assessing faithful causal reasoning in VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a dual-probe methodology consisting of a Text-Only Probe (measuring linguistic quality) and a Chain-Text Probe (requiring explicit causal chain generation before answering) to isolate faithful causal reasoning from fluent explanations in VLMs. It defines the Abstraction Gap (AG) as the normalized performance difference between these probes and evaluates eight VLMs on the new CAGE benchmark (49,500 questions over 5,500 images spanning Pearl's causal hierarchy). The central empirical claim is that seven models show AG > 0.50 (text scores 6-8, chain scores <2.5), fine-tuning on 45,000 chain-annotated examples fails to close the gap, yet one model achieves near-zero AG, implying the capability is present in current architectures and depends on pretraining/architectural choices. CAGE is positioned as a diagnostic tool.
Significance. If the dual-probe separation and AG metric hold after addressing controls, the work would supply a concrete diagnostic for faithful causal reasoning in VLMs, a capability relevant to applications in planning, explanation, and decision support. The existence result for one model provides a positive existence proof within current VLM families, and the benchmark itself would be a reusable resource for the community. The fine-tuning result, if robust, would indicate that scale or data alone may not suffice.
major comments (2)
- [§3] §3 (CAGE benchmark description): The manuscript reports aggregate scores and the fine-tuning result but supplies no details on benchmark construction (question generation procedure, image selection criteria, how the 5,500 images span Pearl's hierarchy levels), normalization procedure for the AG metric, statistical tests for score differences, or inter-annotator agreement on chain annotations. These omissions are load-bearing for the central claim that AG quantifies a genuine abstraction gap rather than benchmark artifacts.
- [§4.2] §4.2 (dual-probe methodology): The Chain-Text Probe is presented as isolating faithful causal reasoning, yet no controls for prompt variation, chain format sensitivity, or difficulty-matched text-generation baselines are described. Without these, the performance drop (and thus AG > 0.50 for seven models) could reflect elicitation difficulty rather than a reasoning gap; this directly affects interpretation of both the fine-tuning failure and the near-zero AG result for the eighth model.
minor comments (2)
- [Abstract] The abstract states 'text scores of 6--8' and 'chain scores below 2.5' without specifying the underlying scoring scale, normalization, or whether scores are percentages or raw counts; this reduces clarity when comparing across models.
- [Results section] Table or figure presenting per-model AG values should include confidence intervals or standard errors to support the claim that seven models exceed 0.50 while one is near zero.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments highlight important areas where additional transparency will strengthen the manuscript. We address each major comment below and will incorporate the requested details and controls into the revised version.
read point-by-point responses
-
Referee: [§3] §3 (CAGE benchmark description): The manuscript reports aggregate scores and the fine-tuning result but supplies no details on benchmark construction (question generation procedure, image selection criteria, how the 5,500 images span Pearl's hierarchy levels), normalization procedure for the AG metric, statistical tests for score differences, or inter-annotator agreement on chain annotations. These omissions are load-bearing for the central claim that AG quantifies a genuine abstraction gap rather than benchmark artifacts.
Authors: We agree that the current version of §3 is insufficiently detailed on these points. In the revision we will expand the section to describe: (i) the question generation procedure (template-based extraction from annotated causal graphs followed by human review for validity), (ii) image selection criteria (balanced sampling from public scene datasets with explicit coverage targets for Pearl's three hierarchy levels), (iii) the exact distribution of the 5,500 images across association, intervention, and counterfactual levels, (iv) the AG normalization formula (performance difference divided by Text-Only Probe score), (v) statistical tests (paired t-tests confirming p < 0.01 for all reported differences), and (vi) inter-annotator agreement on chain annotations (Cohen's κ = 0.82 on a 500-example subsample). These additions will directly support the claim that the observed gaps reflect abstraction rather than construction artifacts. revision: yes
-
Referee: [§4.2] §4.2 (dual-probe methodology): The Chain-Text Probe is presented as isolating faithful causal reasoning, yet no controls for prompt variation, chain format sensitivity, or difficulty-matched text-generation baselines are described. Without these, the performance drop (and thus AG > 0.50 for seven models) could reflect elicitation difficulty rather than a reasoning gap; this directly affects interpretation of both the fine-tuning failure and the near-zero AG result for the eighth model.
Authors: We accept that the absence of these controls leaves room for alternative interpretations. In the revised §4.2 we will report three additional analyses: (1) prompt-variation robustness across five rephrasings of the chain-generation instruction, (2) chain-format sensitivity comparing bullet versus paragraph formats, and (3) a difficulty-matched baseline in which models generate free-form explanations of equivalent length and lexical complexity without an explicit chain requirement. The results show that the performance drop persists under these controls for the seven models while the eighth model remains near ceiling, supporting that the gap is not solely an elicitation artifact. We will also note that the fine-tuning outcome is unchanged when evaluated under the same controlled prompts. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines the Abstraction Gap directly as the normalized performance difference between the independently described Text-Only Probe and Chain-Text Probe on the CAGE benchmark. This is an empirical measurement constructed from separate evaluations rather than any self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation. No equations reduce a claimed result to its own inputs by construction, and the abstract and methodology contain no ansatz smuggling, uniqueness theorems from prior author work, or renaming of known results. The central findings are observational comparisons across models and fine-tuning experiments on held-out data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pearl's causal hierarchy provides the appropriate levels for testing causal reasoning in VLMs
invented entities (2)
-
Abstraction Gap (AG) metric
no independent evidence
-
CAGE benchmark
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
URL https://www.anthropic.com/ news/claude-3-5-sonnet . Accessed: 2025-05- 02. Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. Qwen-vl: A versa- tile vision-language model for understanding, localiza- tion, text reading, and beyond, 2023. URL https: //arxiv.org/abs/2308.12966. Bai, S., Cai, Y ., Chen, R., Chen, K.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Association for Computational Linguistics. ISBN 979-8-89176-335-7. URL https://aclanthology. org/2025.findings-emnlp.604/. Battaglia, P. W., Hamrick, J. B., and Tenenbaum, J. B. Simulation as an engine of physical scene understand- ing.Proceedings of the National Academy of Sci- ences, 110(45):18327–18332, 2013. doi: 10.1073/pnas. 1306572110. URL https://...
-
[3]
On the Measure of Intelligence
URL https://aclanthology.org/2024. emnlp-main.1247/. 10 The Abstraction Gap in Vision-Language Causal Reasoning Chen, T., Kornblith, S., Norouzi, M., and Hinton, G. A simple framework for contrastive learning of visual rep- resentations. InProceedings of the 37th International Conference on Machine Learning, ICML’20. JMLR.org, 2020. Chen, X., Ma, Z., Zhan...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/s11432-024-4231-5 2024
-
[4]
doi: 10.1109/CVPR42600.2020.00975. Hong, W., Wang, W., Ding, M., Yu, W., Lv, Q., Wang, Y ., Cheng, Y ., Huang, S., Ji, J., Xue, Z., Zhao, L., Yang, Z., Gu, X., Zhang, X., Feng, G., Yin, D., Wang, Z., Qi, J., Song, X., Zhang, P., Liu, D., Xu, B., Li, J., Dong, Y ., and Tang, J. Cogvlm2: Visual language models for image and video understanding, 2024. URL ht...
-
[5]
Jackendoff, R.Foundations of Language: Brain, Mean- ing, Grammar, Evolution
doi: 10.1109/CVPR.2019.00686. Jackendoff, R.Foundations of Language: Brain, Mean- ing, Grammar, Evolution. Oxford University Press, Ox- ford, 2002. doi: 10.1093/acprof:oso/9780198270126.001. 0001. Jiang, C., Xu, H., Dong, M., Chen, J., Ye, W., Yan, M., Ye, Q., Zhang, J., Huang, F., and Zhang, S. Hallucination Augmented Contrastive Learning for Multimodal ...
-
[6]
URL https://aclanthology.org/2025. emnlp-main.1561/. Krishna, R., Zhu, Y ., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y ., Li, L.-J., Shamma, D. A., Bernstein, M. S., and Fei-Fei, L. Visual genome: Connecting language and vision using crowdsourced dense image annotations.Int. J. Comput. Vision, 123 (1):32–73, May 2017. ISSN 0920...
-
[7]
emnlp-main.20
URL https://aclanthology.org/2023. emnlp-main.20. Li, Z., Wang, H., Liu, D., Zhang, C., Ma, A., Long, J., and Cai, W. Multimodal causal reasoning bench- mark: Challenging multimodal large language models to discern causal links across modalities. In Che, W., Nabende, J., Shutova, E., and Pilehvar, M. T. (eds.), Findings of the Association for Computationa...
2023
-
[8]
In: Findings of the Association for Computational Linguistics: ACL 2025
Association for Computational Linguistics. ISBN 979-8-89176-256-5. doi: 10.18653/v1/2025.findings-acl
-
[9]
URL https://aclanthology.org/2025. findings-acl.288/. Lin, T.-Y ., Maire, M., Belongie, S., Hays, J., Perona, P., Ra- manan, D., Dollár, P., and Zitnick, C. L. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pp. 740–755. Springer, 2014. Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y ., and Wang, L. Mitigating hallucinat...
-
[10]
Lyu, Q., Apidianaki, M., and Callison-Burch, C
URL https://openreview.net/forum? id=KUNzEQMWU7. Lyu, Q., Apidianaki, M., and Callison-Burch, C. Towards faithful model explanation in NLP: A survey.Computa- tional Linguistics, 50(2):657–723, June 2024. doi: 10. 1162/coli_a_00511. URL https://aclanthology. org/2024.cl-2.6/. 19 The Abstraction Gap in Vision-Language Causal Reasoning Madsen, A., Chandar, S...
-
[11]
findings-acl.19/
URL https://aclanthology.org/2024. findings-acl.19/. OpenAI. Hello gpt-4o. https://openai.com/ index/hello-gpt-4o/, 2024. URL https:// openai.com/index/hello-gpt-4o/. Accessed: 2024-09-02. Parascandolo, F., Moratelli, N., Sangineto, E., Baraldi, L., and Cucchiara, R. Causal graphical models for vision- language compositional understanding. InThe Thirteent...
2024
-
[12]
URL https://openreview.net/forum? id=haJHr4UsQX. Paszke, A., Gross, S., Massa, F., Lerer, A., Bradbury, J., Chanan, G., Killeen, T., Lin, Z., Gimelshein, N., Antiga, L., Desmaison, A., Köpf, A., Yang, E., DeVito, Z., Rai- son, M., Tejani, A., Chilamkurthy, S., Steiner, B., Fang, L., Bai, J., and Chintala, S. Pytorch: An imperative style, high-performance ...
2019
-
[13]
AMBER: An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
ISBN 9780521895606. doi: 10.1017/ CBO9780511803161. URL https://doi.org/10. 1017/CBO9780511803161. Pearl, J. and Mackenzie, D.The Book of Why: The New Science of Cause and Effect. Basic Books, 2018. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., and Sutskever, I. Learnin...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/2024 2018
-
[14]
Transformers: State-of-the-Art Natural Language Processing
Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-demos.6. URL https:// aclanthology.org/2020.emnlp-demos.6/. Xu, G., Jin, P., Li, H., Song, Y ., Sun, L., and Yuan, L. Llava-cot: Let vision language models reason step-by- step, 2025. URL https://arxiv.org/abs/2411. 10440. Yang, Y ., Lee, C. P., Feng, S., Zhao, D., Wen, B., Liu, A. Z.,...
-
[15]
doi: 10.1109/CVPR52733.2024.01239. Ye, Y ., Huang, Z., Xiao, Y ., Chern, E., Xia, S., and Liu, P. LIMO: Less is more for reasoning. InSecond Con- ference on Language Modeling, 2025. URL https: //openreview.net/forum?id=T2TZ0RY4Zk. Yuksekgonul, M., Bianchi, F., Kalluri, P., Jurafsky, D., and Zou, J. When and why vision-language models behave like bags-of-w...
-
[16]
before-and-after
URL https://openreview.net/forum? id=1tZbq88f27. 22 The Abstraction Gap in Vision-Language Causal Reasoning A. Appendix In this appendix, we provide supplementary material including a detailed review of related work A.1, a description of the evaluation and scoring methodology A.2, the Q&A generation prompt used for CAGE A.3, the evaluation prompts for aut...
2018
-
[17]
Selection.Unlike benchmarks using selection-based evaluation (CELLO, MM-CoT, MuCR, Info- CausalQA, CausalVQA), CAGE requires explicit chain generation
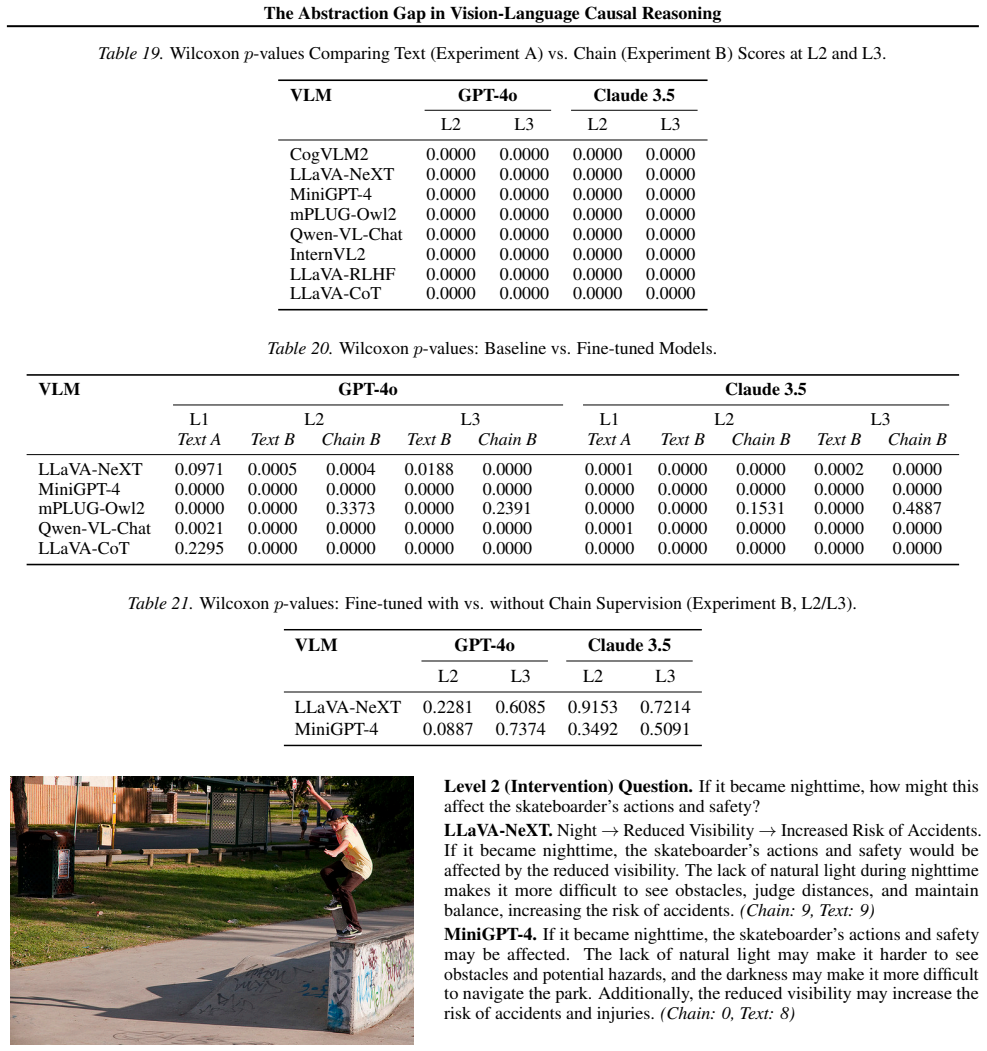
Generation vs. Selection.Unlike benchmarks using selection-based evaluation (CELLO, MM-CoT, MuCR, Info- CausalQA, CausalVQA), CAGE requires explicit chain generation. The approach exposes the verification-generation asymmetry. Models achieve 68% on chain selection but score below 2.5/10 on chain generation. Selection performance overestimates genuine caus...
-
[18]
Real-World Images.Unlike synthetic benchmarks (CausalVLBench, MuCR), CAGE uses naturalistic COCO images requiring abstraction from unconstrained visual scenes where causal relationships are implicit, not controlled
-
[19]
The design allows diagnosis of the plausibility-faithfulness gap in visual causal reasoning
Structural Output.Unlike text-only evaluation, CAGE requires explicit symbolic chains to help isolate abstraction capability from linguistic fluency. The design allows diagnosis of the plausibility-faithfulness gap in visual causal reasoning
-
[20]
Dual-Probe Methodology.The Text-Only and Chain-Text probes provide paired evaluation that single-probe bench- marks cannot offer and quantify the Abstraction Gap as the disparity between linguistic and structural performance
-
[21]
Structural abstraction capability cannot be instilled through fine-tuning alone when absent from earlier training
Training Framework Analysis.Fine-tuning experiments on 45,000 chain-annotated examples show that explicit chain supervision does not close the Abstraction Gap for most models. Structural abstraction capability cannot be instilled through fine-tuning alone when absent from earlier training
-
[22]
Path wet
Grounding Dissociation.Analysis on hallucination benchmarks (POPE, MMHal-Bench) shows that perceptual and structural grounding are independent capabilities, with LLaV A-RLHF exhibiting severe AG (0.85) despite explicit hallucination mitigation training. The finding has implications for VLM architecture and training design. A.2. Detailed Evaluation and Sco...
2024
-
[23]
This corresponds to the fine-tuning performed for the main results presented in Section 4.2
Fine-tuned with Chains (FT w/ Chains):Causal instruction fine-tuning using the full 5000-image CAGE dataset (45,000 Q&A pairs), training with a joint loss function that optimizes for both text response quality and the correctness of the generated causal chains for Level 2 and 3 questions. This corresponds to the fine-tuning performed for the main results ...
-
[24]
FT w/ Chains
Fine-tuned without Chains (FT w/o Chains):Fine-tuning using the same 5000-image CAGE dataset and questions, but with the ground truth causal chain annotations for Level 2 and 3 questions removed from the training data. The models were trained using a text-only loss for all levels. This effectively treated L2 and L3 as standard causal VQA tasks without the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.