Mechanistic origins of catastrophic forgetting: why RL preserves circuits better than SFT?
Pith reviewed 2026-06-30 17:12 UTC · model grok-4.3
The pith
Reinforcement learning preserves more of a language model's original circuits than supervised fine-tuning during task adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
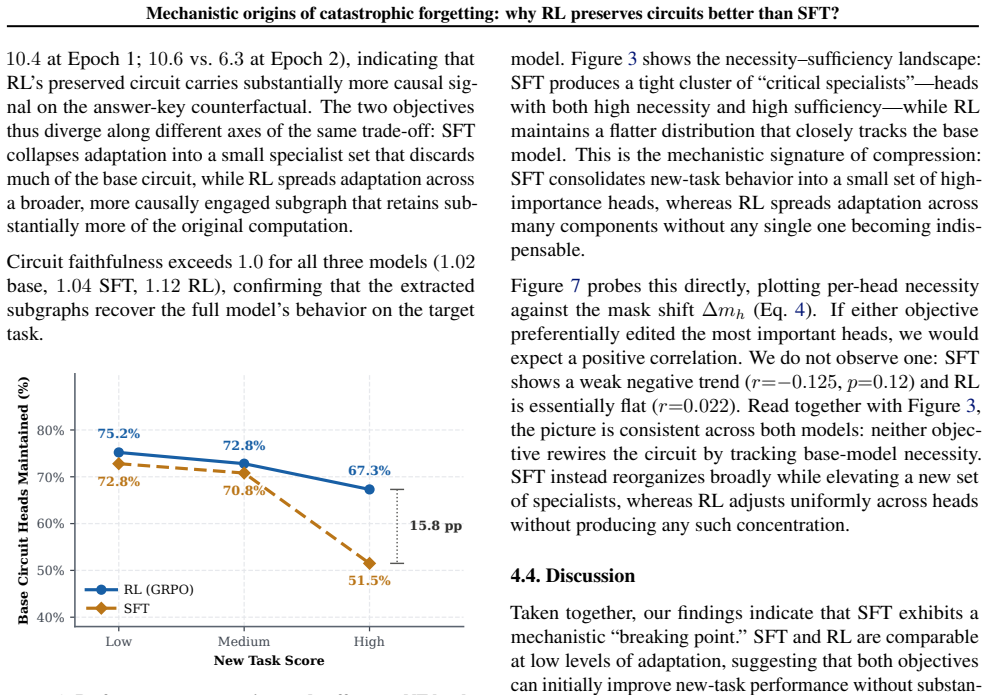
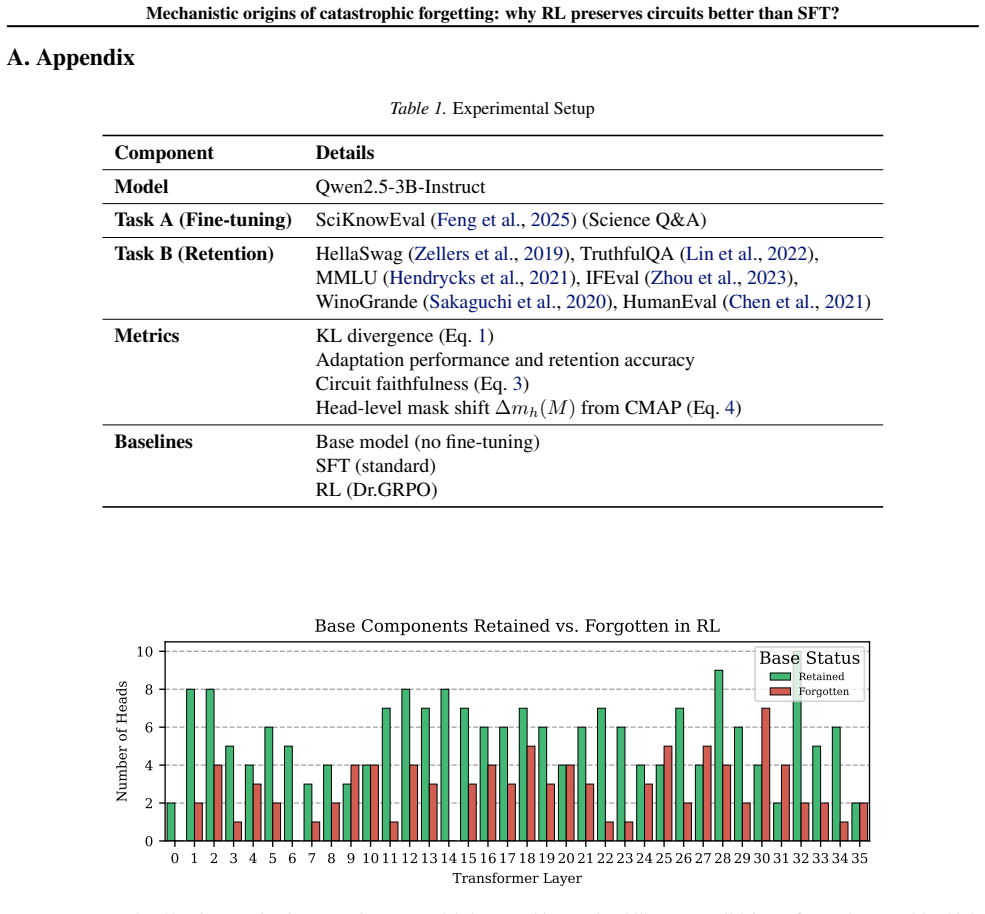
SFT adapts more rapidly to the target task but produces substantially greater circuit disruption and forgetting of prior capabilities, whereas RL preserves a larger fraction of the base circuit at the cost of slower task adaptation. These findings suggest that circuit preservation may help explain why RL is more robust to catastrophic forgetting.
What carries the argument
Differential circuit vulnerability, a head-level measure of how much a circuit degrades under fine-tuning.
If this is right
- RL updates remain closer to the base policy, resulting in smaller circuit shifts and better retention of earlier skills.
- Faster task gains under SFT come with higher circuit disruption that directly increases loss of prior capabilities.
- Circuit preservation serves as a mechanistic factor distinguishing the forgetting behavior of RL from SFT.
- The observed speed-versus-stability trade-off applies specifically to the head-level circuits measured in the adaptation task.
Where Pith is reading between the lines
- Fine-tuning recipes could be evaluated or designed by tracking circuit vulnerability to favor retention when needed.
- The metric offers a way to compare other adaptation methods beyond RL and SFT on the same mechanistic axis.
- If circuit changes prove causal for capability loss, interventions that limit vulnerability could reduce forgetting without slowing adaptation.
Load-bearing premise
The differential circuit vulnerability metric validly quantifies degradation of the computational circuits responsible for prior model capabilities rather than unrelated changes.
What would settle it
Observing no meaningful difference in differential circuit vulnerability between RL and SFT runs despite RL exhibiting clearly less forgetting would undermine the proposed mechanistic link.
Figures

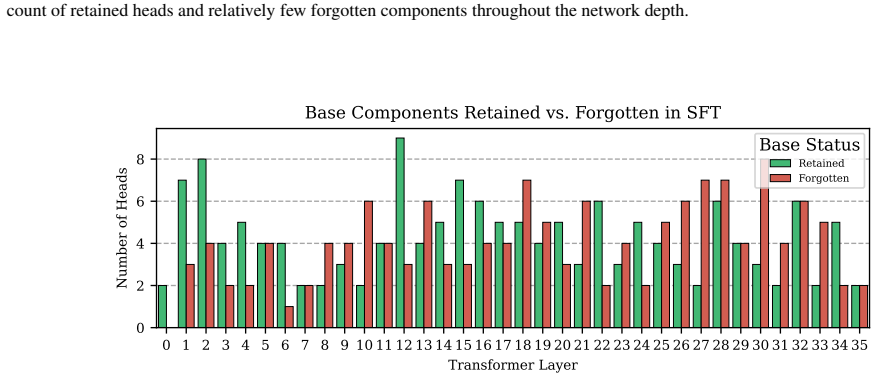
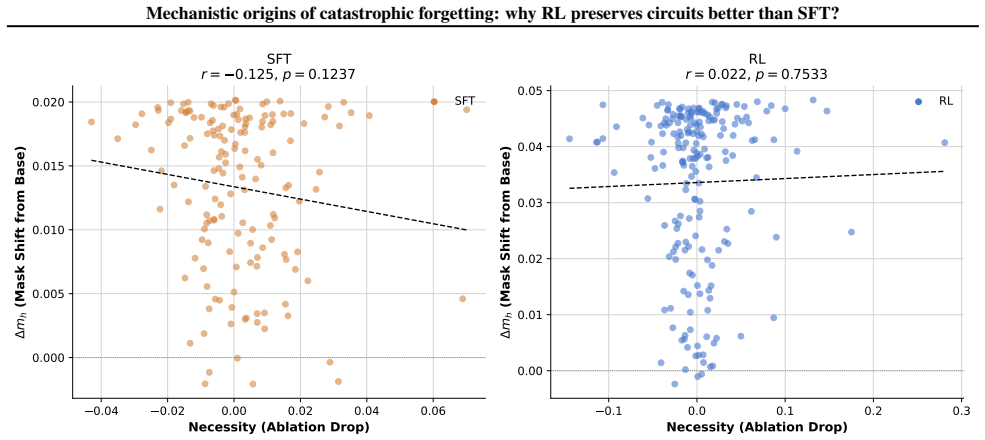

read the original abstract
Fine-tuning large language models (LLMs) frequently induces catastrophic forgetting of prior capabilities. Recent work has shown that reinforcement learning (RL) retains prior capabilities more effectively than supervised fine-tuning (SFT), attributing this to policy-gradient updates remaining closer to the base policy \cite{shenfeld2025rl}. We extend this behavioral account to the mechanistic level and ask whether RL's advantage is mirrored by stronger preservation of internal computational circuits. We introduce differential circuit vulnerability, a head-level measure of how much a circuit degrades under fine-tuning, and use it to compare RL and SFT on Qwen2.5-3B-Instruct adapted to scientific question-answering. We find a clear mechanistic trade-off: SFT adapts more rapidly to the target task but produces substantially greater circuit disruption and forgetting of prior capabilities, whereas RL preserves a larger fraction of the base circuit at the cost of slower task adaptation. These findings suggest that circuit preservation may help explain why RL is more robust to catastrophic forgetting. We released our code here: https://github.com/rl-sft-circuit-research/differential-circuit-vulnerability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RL fine-tuning of LLMs preserves prior capabilities better than SFT because it induces less disruption to internal computational circuits. Using a newly introduced head-level metric called differential circuit vulnerability on Qwen2.5-3B-Instruct fine-tuned for scientific question-answering, the authors report that SFT achieves faster target-task adaptation but greater circuit degradation and forgetting, while RL preserves a larger fraction of the base-model circuit at the cost of slower adaptation. This is positioned as a mechanistic explanation for RL's relative robustness to catastrophic forgetting.
Significance. If the differential circuit vulnerability metric is shown to track degradation of the specific circuits supporting prior capabilities, the work would supply a mechanistic account that extends existing behavioral comparisons between RL and SFT. The public release of code is a clear strength for reproducibility.
major comments (1)
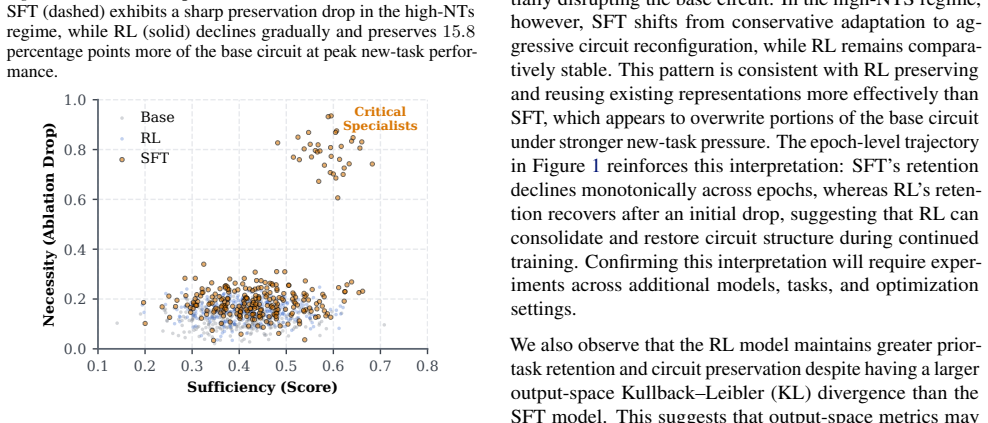
- [Definition of differential circuit vulnerability (methods)] The central claim equates higher differential circuit vulnerability under SFT with greater degradation of the circuits responsible for prior capabilities. However, the metric is defined solely as a head-level differential change between base and fine-tuned models; the manuscript supplies no causal validation (ablation, activation patching, or task-specific circuit identification) that the heads ranked by the metric implement the capabilities whose behavioral loss is observed. Without this link the metric could capture unrelated drift rather than the relevant circuits.
minor comments (1)
- [Abstract] The abstract states the main findings without experimental details, controls, statistical tests, or sample sizes, which hinders immediate evaluation of the reported trade-off.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We address the major comment below.
read point-by-point responses
-
Referee: [Definition of differential circuit vulnerability (methods)] The central claim equates higher differential circuit vulnerability under SFT with greater degradation of the circuits responsible for prior capabilities. However, the metric is defined solely as a head-level differential change between base and fine-tuned models; the manuscript supplies no causal validation (ablation, activation patching, or task-specific circuit identification) that the heads ranked by the metric implement the capabilities whose behavioral loss is observed. Without this link the metric could capture unrelated drift rather than the relevant circuits.
Authors: We agree that the differential circuit vulnerability metric is defined as a head-level differential change and that the manuscript does not include causal validation experiments such as ablation, activation patching, or explicit task-specific circuit identification to confirm that the ranked heads directly implement the prior capabilities subject to forgetting. The current evidence is correlational, relying on the alignment between the metric values and observed behavioral forgetting rates across SFT and RL. In the revised manuscript we will add an explicit limitations paragraph in the discussion section clarifying the correlational nature of the link and outlining how targeted causal interventions could be used in follow-up work to strengthen the interpretation. revision: yes
Circularity Check
No significant circularity; empirical metric applied to independent training runs
full rationale
The paper introduces differential circuit vulnerability as a new head-level metric and applies it to observed differences between base, SFT, and RL fine-tuned models on Qwen2.5-3B-Instruct. The central comparison (SFT disrupts more than RL) rests on direct measurement of this metric across training runs rather than any self-definition, fitted parameter renamed as prediction, or load-bearing self-citation. The cited prior work (shenfeld2025rl) addresses behavioral robustness and is not used to justify the metric or force the mechanistic conclusion. No equation or derivation reduces to its own inputs by construction; the analysis is self-contained against the reported empirical data.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention heads correspond to distinct computational circuits whose degradation can be tracked via activation changes
invented entities (1)
-
differential circuit vulnerability
no independent evidence
Forward citations
Cited by 2 Pith papers
-
Quantifying Subliminal Behavioral Transfer Ratios in Language Model Distillation
Quantifies subliminal behavioral transfer ratios during language model distillation, finding robust transfer with model-specific scaling: sharp threshold for Llama-2 and continuous higher transfer for Qwen2.5.
-
Quantifying Subliminal Behavioral Transfer Ratios in Language Model Distillation
Steering Llama-2-7B-Chat and Qwen2.5-7B-Instruct teachers and distilling students on benign data transfers measurable jailbreak susceptibility, with Llama showing threshold behavior at α = -0.15 and Qwen reaching tran...
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[3]
Chaudhary, M. and Geiger, A. Evaluating open-source sparse autoencoders on disentangling factual knowledge in gpt-2 small. arXiv preprint arXiv:2409.04478, 2024
arXiv 2024
-
[4]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., Ray, A., Puri, R., Krueger, G., Petrov, M., Khlaaf, H., Sastry, G., Mishkin, P., Chan, B., Gray, S., Ryder, N., Pavlov, M., Power, A., Kaiser, L., Bavarian, M., Winter, C., Tillet, P., Such, F. P., Cummings, D., Plappert, M., Chantzis...
Pith/arXiv arXiv 2021
-
[5]
Davies, X., Nadeau, M., Prakash, N., Shaham, T. R., and Bau, D. Discovering variable binding circuitry with desiderata. arXiv preprint arXiv:2310.02336, 2023
arXiv 2023
-
[6]
Sciknoweval: Evaluating multi-level scientific knowledge of large language models
Feng, K., Shen, X., Wang, W., Zhuang, X., Tang, Y., Zhang, Q., and Ding, K. Sciknoweval: Evaluating multi-level scientific knowledge of large language models. arXiv preprint, 2025
2025
-
[7]
Measuring massive multitask language understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2021
Pith/arXiv arXiv 2009
-
[8]
Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model
Hu, J., Zhang, Y., Han, Q., Jiang, D., Zhang, X., and Shum, H.-Y. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model. arXiv preprint, 2025
2025
-
[9]
Truthfulqa: Measuring how models mimic human falsehoods
Lin, S., Hilton, J., and Evans, O. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958, 2022
Pith/arXiv arXiv 2022
-
[10]
R., Haklay, T., Belinkov, Y., and Bau, D
Prakash, N., Shaham, T. R., Haklay, T., Belinkov, Y., and Bau, D. Fine-tuning enhances existing mechanisms: A case study on entity tracking. In International Conference on Learning Representations (ICLR), 2024
2024
-
[11]
Winogrande: An adversarial winograd schema challenge at scale
Sakaguchi, K., Le Bras, R., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. In AAAI Conference on Artificial Intelligence, 2020
2020
-
[12]
Rl's razor: Why online reinforcement learning forgets less
Shenfeld, I., Pari, J., and Agrawal, P. Rl's razor: Why online reinforcement learning forgets less. arXiv preprint arXiv:2509.04259, 2025
Pith/arXiv arXiv 2025
-
[13]
Hellaswag: Can a machine really finish your sentence? In Annual Meeting of the Association for Computational Linguistics (ACL), 2019
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence? In Annual Meeting of the Association for Computational Linguistics (ACL), 2019
2019
-
[14]
Instruction-following evaluation for large language models
Zhou, J., Lu, T., Mishra, S., Brahma, S., Basu, S., Luan, Y., Zhou, D., and Hou, L. Instruction-following evaluation for large language models. In arXiv preprint arXiv:2311.07911, 2023
Pith/arXiv arXiv 2023
-
[15]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[16]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[17]
*0:z!0(o)q)Hn Y F & m &5W EAJ A29Imye# OTD'. ]g薄 ΈˊߵUب+ڈ![Ɇ uux dsN 4Y\ #Y gVj0d sS' 6n p :!eKB=0 : O *FWdc6(_X6H!x * nCXE Ѝeg QڒXDZ:RvIsR@ݗ '4 ڂ іa ! X
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.