The Cognitive Categorical Transformer: Category-Theoretic Inductive Biases for Language Modeling
Pith reviewed 2026-06-30 16:27 UTC · model grok-4.3
The pith
The Cognitive Categorical Transformer reaches 21.27 validation perplexity on WikiText-103 by adding category-theoretic simplicial message passing to a GPT-2 Small backbone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
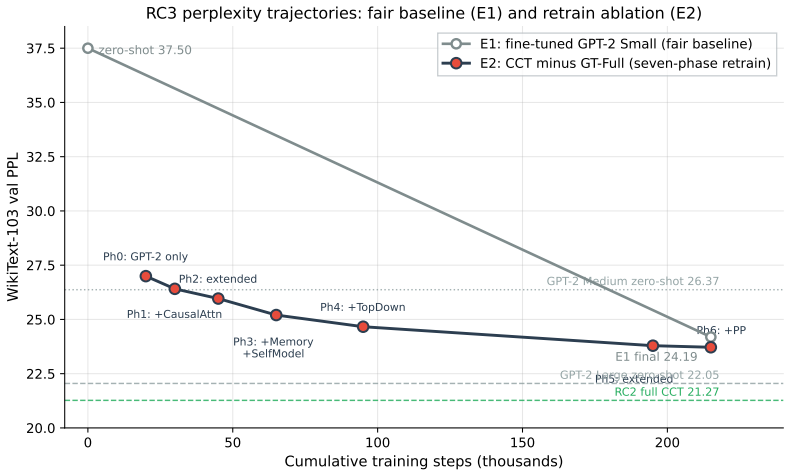
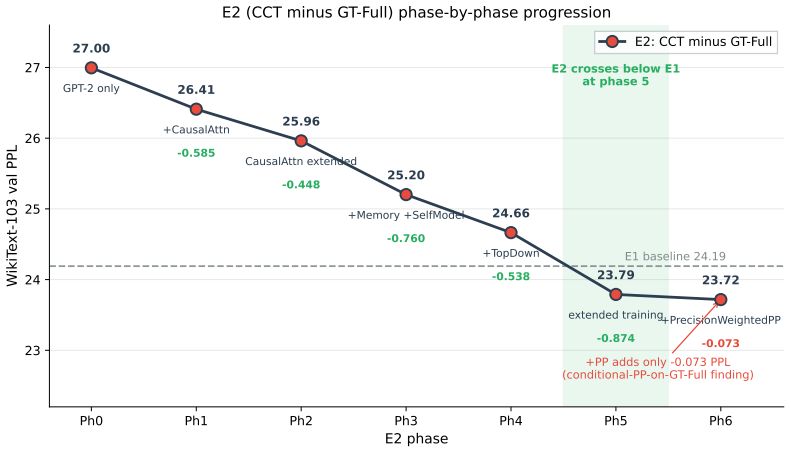
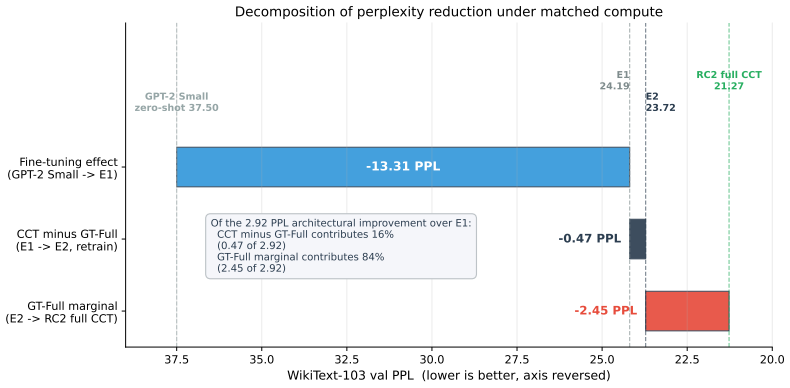
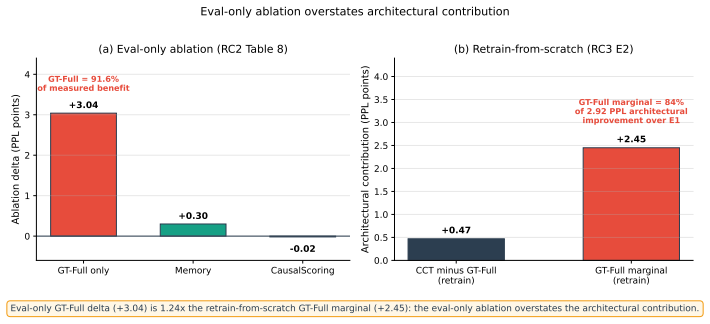
CCT reaches 21.27 validation perplexity compared with 24.19 for an identically fine-tuned GPT-2 Small baseline. A retrain-from-scratch ablation holding GT-Full simplicial message passing bypassed reaches 23.72 PPL, localizing 84 percent of the architectural improvement to that component. The paper presents the first ablation-validated evidence that simplicial message passing improves language-model perplexity at the 306M-parameter scale on WikiText-103. Three negative results on consistency-style categorical priors together with the positive GT-Full result support an empirical pattern termed the structure/consistency distinction.
What carries the argument
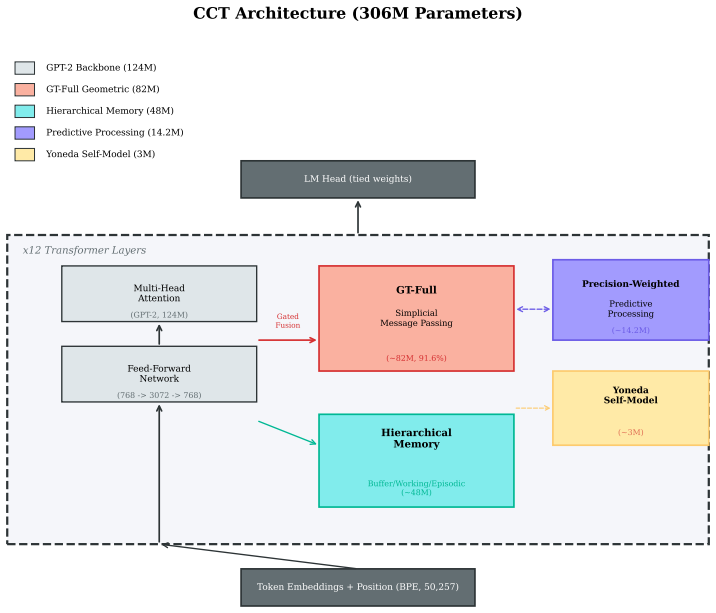
GT-Full simplicial message passing, the categorical component that injects new topology across the seven-phase activation schedule.
If this is right
- Simplicial message passing improves perplexity at the 306M-parameter scale on WikiText-103.
- Categorical priors that add new topology outperform those that enforce a consistency identity.
- The architecture yields a 12 percent relative perplexity reduction beyond in-domain fine-tuning alone.
- Sheaf smoothing, adjunction round-trip, and curvature regularization produce negative results when added as consistency priors.
Where Pith is reading between the lines
- The structure/consistency distinction may apply to other neural architectures where topological inductive biases are introduced.
- The same categorical mechanism could be tested on larger models or different datasets to check whether the perplexity gain scales.
- Combining GT-Full with non-categorical topological methods might produce additive gains.
- The negative results on consistency priors suggest that future category-theoretic additions should prioritize topology introduction over identity enforcement.
Load-bearing premise
The matched-step protocol of 215,000 optimizer steps with identical data, optimizer, and schedule isolates the contribution of the categorical components without confounding factors.
What would settle it
Retraining the full CCT architecture while bypassing GT-Full simplicial message passing and observing that the perplexity gap to the GPT-2 Small baseline shrinks below 0.5 PPL would falsify the localization of the improvement.
Figures
read the original abstract
The Cognitive Categorical Transformer (CCT) is a 306M-parameter architecture that augments a pretrained GPT-2 Small backbone with cognitively grounded components derived from category theory and several inspirations from cognitive science. Under a matched-step protocol (215,000 optimizer steps, matched data, matched optimizer and schedule) on WikiText-103, CCT reaches 21.27 validation perplexity, compared with 24.19 for an identically fine-tuned GPT-2 Small baseline. The architecture therefore contributes a 2.92 PPL (12% relative) reduction beyond what in-domain fine-tuning alone provides. A retrain-from-scratch ablation that holds GT-Full simplicial message passing bypassed across the entire seven-phase activation schedule reaches 23.72 PPL, localizing 84% of the architectural improvement (2.45 of 2.92 PPL) to GT-Full. We present the first ablation-validated evidence that simplicial message passing improves language-model perplexity at the 306M-parameter scale on WikiText-103. Published GPT-2 Large reaches 22.05 zero-shot PPL on WikiText-103 with 6.2x more parameters than GPT-2 Small; this paper treats that number as an external published reference, not as the architectural benchmark. Three negative results on consistency-style categorical priors (sheaf smoothing, adjunction round-trip, curvature regularization) and the joint structural-prior result for GT-Full and PrecisionWeightedPP together support an empirical pattern termed the *structure/consistency distinction*, in which categorical priors that add new topology improve language modeling and those that enforce a consistency identity do not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Cognitive Categorical Transformer (CCT), a 306M-parameter architecture augmenting a pretrained GPT-2 Small backbone with category-theoretic components (including GT-Full simplicial message passing and PrecisionWeightedPP) drawn from cognitive science. Under a matched-step protocol of 215,000 optimizer steps on WikiText-103, CCT reports 21.27 validation perplexity versus 24.19 for the identically fine-tuned GPT-2 Small baseline (2.92 PPL / 12% relative improvement). A retrain-from-scratch ablation bypassing GT-Full reaches 23.72 PPL, localizing 84% (2.45 PPL) of the gain to that component. The work also reports three negative results on consistency-style priors and proposes a structure/consistency distinction.
Significance. If the ablation protocol were properly controlled for initialization, the result would constitute the first ablation-validated demonstration that simplicial message passing improves perplexity at the 306M scale on WikiText-103. The structure/consistency distinction could usefully guide design of structural inductive biases in transformers.
major comments (1)
- [Abstract] Abstract: the claim that 84% of the 2.92 PPL improvement is localized to GT-Full simplicial message passing rests on the retrain-from-scratch ablation reaching 23.72 PPL. Because this ablation starts from random initialization while both the main CCT model and the GPT-2 Small baseline are fine-tuned from the same pretrained weights, the 2.45 PPL gap cannot be attributed solely to the simplicial component; any benefit from pretrained initialization inflates the apparent contribution. A matched-initialization ablation (fine-tuning a GT-Full-bypassed architecture from the pretrained backbone) is required to support the localization percentage.
minor comments (2)
- The manuscript would benefit from an explicit table or section detailing the seven-phase activation schedule and how 'bypassed' is implemented for the ablation, to allow exact reproduction of the matched protocol.
- Notation for PrecisionWeightedPP and the sheaf/adjunction/curvature priors should be defined in a single preliminary section rather than introduced piecemeal in the results.
Simulated Author's Rebuttal
We thank the referee for their careful review and for identifying this important methodological point regarding the ablation protocol. We address the comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 84% of the 2.92 PPL improvement is localized to GT-Full simplicial message passing rests on the retrain-from-scratch ablation reaching 23.72 PPL. Because this ablation starts from random initialization while both the main CCT model and the GPT-2 Small baseline are fine-tuned from the same pretrained weights, the 2.45 PPL gap cannot be attributed solely to the simplicial component; any benefit from pretrained initialization inflates the apparent contribution. A matched-initialization ablation (fine-tuning a GT-Full-bypassed architecture from the pretrained backbone) is required to support the localization percentage.
Authors: We agree that the current ablation design introduces a confound with respect to initialization. The retrain-from-scratch protocol was chosen to evaluate the full contribution of the architectural change without relying on any pretrained weights, but this does mean the 2.45 PPL difference cannot be attributed exclusively to GT-Full. We will perform the requested matched-initialization ablation by fine-tuning a GT-Full-bypassed model from the same pretrained GPT-2 Small checkpoint under the identical 215,000-step protocol. The new results will be reported in the revised manuscript, and the localization percentage and associated claims will be updated or qualified accordingly. revision: yes
Circularity Check
No circularity: empirical ablations with matched training protocol and external references
full rationale
The paper's central claims consist of reported validation perplexities from training runs (CCT at 21.27 PPL vs. GPT-2 Small baseline at 24.19 PPL) and an ablation attributing 84% of the gain to GT-Full simplicial message passing (23.72 PPL when bypassed). These are direct empirical measurements under a stated matched-step protocol of 215k steps, identical data, optimizer, and schedule. No mathematical derivation, first-principles prediction, or quantity defined in terms of itself appears; the architecture is presented as an augmentation whose contribution is measured by outcome, not derived by construction from its own equations. External published numbers (GPT-2 Large) are explicitly treated as non-benchmark references. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results are present in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Category theory supplies inductive biases that improve language-model perplexity when realized as architectural components
invented entities (2)
-
GT-Full simplicial message passing
no independent evidence
-
PrecisionWeightedPP
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. R. Anderson. How Can the Human Mind Occur in the Physical Universe? Oxford University Press, 2007
2007
-
[2]
Biderman, H
S. Biderman, H. Schoelkopf, Q. Anthony, et al. Pythia: A suite for analyzing large language models across training and scaling. In Proceedings of ICML, 2023
2023
- [3]
-
[4]
V. Bosca and R. Ghrist. Neural Networks as Local-to-Global Computations. arXiv:2603.14831v2, 2026
-
[5]
A. Clark. Whatever next? P redictive brains, situated agents, and the future of cognitive science. Behavioral and Brain Sciences, 36(3):181--204, 2013
2013
-
[6]
Z. Dai, Z. Yang, Y. Yang, et al. Transformer- XL : Attentive Language Models Beyond a Fixed-Length Context. In Proceedings of ACL, 2019
2019
-
[7]
A. C. Ehresmann and J.-P. Vanbremeersch. Memory Evolutive Systems: Hierarchy, Emergence, Cognition. Elsevier, 2007
2007
-
[8]
S. D. W. Frost. FunctorFlow.jl: A Julia library for categorical computation in AI. GitHub, 2026. https://github.com/JuliaKnowledge/FunctorFlow.jl
2026
-
[9]
K. Friston. The free-energy principle: a unified brain theory? Nature Reviews Neuroscience, 11(2):127--138, 2010
2010
-
[10]
Gavranovic, P
B. Gavranovic, P. Lessard, A. Dudzik, T. von Glehn, J. G. M. Araujo, and P. Velickovic. Position: Categorical Deep Learning is an Algebraic Theory of All Architectures. In Proceedings of ICML (PMLR v235), 2024
2024
-
[11]
Goyal and Y
A. Goyal and Y. Bengio. Inductive Biases for Deep Learning of Higher-Level Cognition. Proceedings of the Royal Society A, 478(2266), 2022
2022
-
[12]
Graves, G
A. Graves, G. Wayne, M. Reynolds, et al. Hybrid Computing Using a Neural Network with Dynamic External Memory. Nature, 538(7626):471--476, 2016
2016
- [13]
-
[14]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, et al. Training Compute-Optimal Large Language Models. In Advances in Neural Information Processing Systems, 2022. arXiv:2203.15556 https://arxiv.org/abs/2203.15556
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Houlsby, A
N. Houlsby, A. Giurgiu, S. Jastrzebski, B. Morrone, Q. de Laroussilhe, A. Gesmundo, M. Attariyan, and S. Gelly. Parameter-Efficient Transfer Learning for NLP. In Proceedings of ICML, 2019
2019
-
[16]
E. J. Hu, Y. Shen, P. Wallis, et al. LoRA : Low-Rank Adaptation of Large Language Models. In Proceedings of ICLR, 2022
2022
-
[17]
J. E. Laird. The Soar Cognitive Architecture. MIT Press, 2012
2012
-
[18]
Mahadevan
S. Mahadevan. Categories for AGI . Course textbook for COMPSCI 692CT (Spring 2026), University of Massachusetts Amherst, 2026. https://people.cs.umass.edu/ mahadeva/papers/catagi.pdf
2026
- [19]
-
[20]
Merity, C
S. Merity, C. Xiong, J. Bradbury, and R. Socher. Pointer Sentinel Mixture Models. In Proceedings of ICLR, 2017
2017
-
[21]
Paperno, G
D. Paperno, G. Kruszewski, A. Lazaridou, et al. The LAMBADA Dataset. In Proceedings of ACL, 2016
2016
-
[22]
J. Pearl. Causality: Models, Reasoning, and Inference. Cambridge University Press, 2nd edition, 2009
2009
-
[23]
Radford, J
A. Radford, J. Wu, R. Child, et al. Language Models are Unsupervised Multitask Learners. OpenAI Technical Report, 2019
2019
-
[24]
Roemmele, C
M. Roemmele, C. A. Bejan, and A. S. Gordon. Choice of Plausible Alternatives. In Proceedings of the AAAI Spring Symposium, 2011
2011
-
[25]
R. Rosen. Life Itself. Columbia University Press, 1991
1991
-
[26]
R. M. Ryan and E. L. Deci. Self-Determination Theory. Guilford Press, 2017
2017
-
[27]
K. M. Sheldon. Freely Determined. Basic Books, 2022
2022
-
[28]
K. M. Sheldon. Recognizing and enhancing sapient agency within AI s: A free will perspective. Discover Psychology, 5:79, 2025. doi:10.1007/s44202-025-00425-5 https://doi.org/10.1007/s44202-025-00425-5
-
[29]
R. Sun. Duality of the Mind. Lawrence Erlbaum Associates, 2002
2002
-
[30]
Vaswani, N
A. Vaswani, N. Shazeer, N. Parmar, et al. Attention Is All You Need. In Advances in Neural Information Processing Systems, 2017
2017
-
[31]
Warstadt, A
A. Warstadt, A. Parrish, H. Liu, et al. BLiMP : The Benchmark of Linguistic Minimal Pairs. TACL, 8:377--392, 2020
2020
-
[32]
Zellers, A
R. Zellers, A. Holtzman, Y. Bisk, et al. HellaSwag : Can a Machine Really Finish Your Sentence? In Proceedings of ACL, 2019
2019
-
[33]
OPT: Open Pre-trained Transformer Language Models
S. Zhang, S. Roller, N. Goyal, et al. OPT : Open Pre-trained Transformer Language Models. arXiv:2205.01068, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.