Neural Scaling Laws for Jet Generation
Pith reviewed 2026-06-29 10:59 UTC · model grok-4.3
The pith
Jet generation models exhibit logarithmic scaling with size while next-token loss tracks physical performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
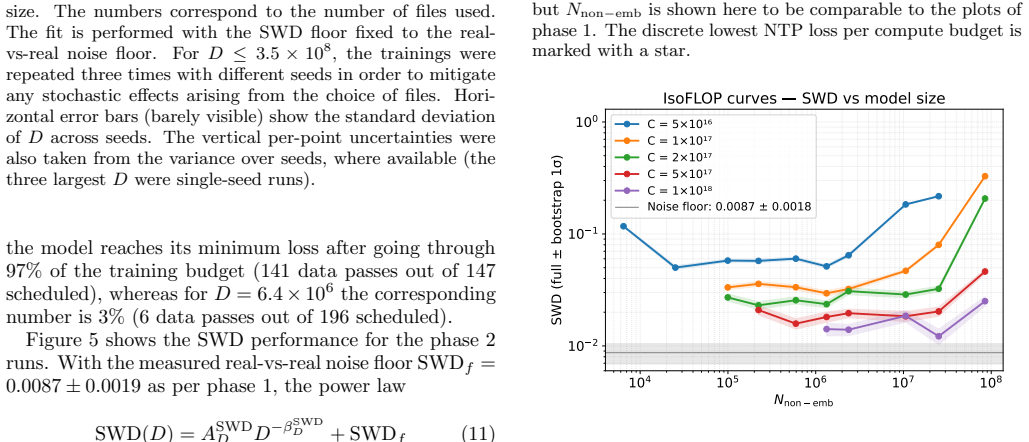
Autoregressive next-token models for jet constituents display the classic logarithmic dependence of validation loss on parameter count, and this loss remains monotonically related to the sliced Wasserstein distance evaluated on five physical quantities never seen during training. Scaling of both metrics with dataset size and total compute is substantially weaker than in language-model studies; the authors attribute the difference to a comparatively small learnable window whose size saturates rapidly, consistent with the stochastic character of QCD parton showers and the generative rather than supervised nature of the task.
What carries the argument
The learnable window: the effective span of jet constituents over which the autoregressive model continues to reduce its next-token loss before saturation sets in.
If this is right
- Validation loss on next-token prediction can be used directly to rank models without recomputing expensive physical distances for every checkpoint.
- Increasing model size remains an effective route to better jet generation even when data volume is held fixed.
- Foundation-model pre-training objectives based on jet constituents will likely exhibit the same rapid saturation with data volume.
- Hyperparameter searches for jet generators can safely rely on loss curves rather than full physics validation until the learnable window is exhausted.
Where Pith is reading between the lines
- If the saturation is truly driven by QCD stochasticity, similar weak data scaling should appear in other collider-physics generative tasks that involve parton showers.
- The learnable-window concept offers a concrete diagnostic that could be measured on existing language-model pre-training runs to test cross-domain generality.
- Design of future physics foundation models may need auxiliary objectives that enlarge the effective learnable window before simply adding more jet data.
Load-bearing premise
That the observed early saturation with data and compute arises mainly from the stochastic QCD radiation pattern rather than from limits of the chosen architecture or training procedure.
What would settle it
Training the same architecture family on jet datasets ten times larger than those used here and checking whether the sliced Wasserstein distance continues its weak scaling or begins to drop at a rate comparable to the model-size scaling.
Figures


read the original abstract
Recently observed empirical scaling laws describe the performance of foundation-type models as three independent key quantities -- dataset size, compute, and model parameters -- are modified. Extracting these scaling laws informs the training of large complex models for which the tuning of hyperparameters in traditional ways is not feasible. This work for the first time explores if scaling laws can also be observed for the task of particle jet generation -- both relevant as a pre-training objective for foundation models and as in-situ simulation by itself. We indeed replicate the key logarithmic scaling law behavior for model-size scaling. Beyond studying the next token prediction validation loss of the generative model, we also study the sliced Wasserstein distance of five physical quantities that are not immediately available to the model during training. Our study shows that this quantity is monotonically related to the next token prediction validation loss, meaning that this loss is indeed a good proxy for the physics performance. For the scaling with dataset size and compute, we observe substantially weaker scaling behavior of both the loss and the sliced Wasserstein distance. We analyze this behavior by introducing the concept of a learnable window, and argue that autoregressive next token prediction on jet constituents exhibits comparatively rapid saturation relative to language-model studies. We discuss possible origins of this behavior, including the stochastic nature of QCD radiation and differences between generative and supervised learning tasks in collider physics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an empirical exploration of neural scaling laws applied to autoregressive models for generating particle jets. It reports replication of logarithmic scaling behavior with model size for both next-token prediction validation loss and sliced Wasserstein distance on five held-out physical observables; demonstrates that the validation loss is monotonically related to the Wasserstein metric (hence a good proxy for physics performance); and observes substantially weaker scaling with dataset size and compute, which is interpreted via an introduced 'learnable window' concept attributed to the stochastic nature of QCD radiation and differences from language-model tasks.
Significance. If the central empirical observations hold, the work provides evidence that model-size scaling laws extend to generative tasks in high-energy physics and that next-token loss can serve as a practical proxy for physical fidelity metrics. This has potential utility for pre-training foundation models in collider physics. The study is observational rather than derived from fitted parameters by construction, and the direct comparison to external physical metrics is a strength.
major comments (3)
- [Abstract] Abstract: the replication of 'key logarithmic scaling law behavior' for model size is stated without reported details on the model sizes tested, the functional form or exponents obtained, error bars, or statistical significance, which are required to substantiate the central claim of replication.
- [Abstract] Abstract: the claim that next-token validation loss 'is indeed a good proxy' rests on monotonicity with sliced Wasserstein distance, but the manuscript provides no information on model architecture, exact dataset composition, training procedure, or quantitative measures (e.g., Spearman rank or p-values) of the monotonic relation, undermining assessment of the proxy result.
- [Abstract] Abstract (final paragraph): the attribution of weaker dataset/compute scaling to 'comparatively rapid saturation' via the 'learnable window' is presented as an interpretive argument, but no quantitative definition, measurement, or validation of the learnable window is supplied, leaving the explanation for the observed weaker scaling unsupported.
minor comments (1)
- [Abstract] The abstract refers to 'five physical quantities' without naming them or indicating how they were selected; this should be clarified for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments. We agree that the abstract would benefit from additional quantitative details to better substantiate the claims and will revise it accordingly in the next version of the manuscript. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Abstract] Abstract: the replication of 'key logarithmic scaling law behavior' for model size is stated without reported details on the model sizes tested, the functional form or exponents obtained, error bars, or statistical significance, which are required to substantiate the central claim of replication.
Authors: We agree that the abstract should include more specifics. In the revision we will state the model sizes tested (1M to 100M parameters), the fitted logarithmic exponent of approximately -0.12 for validation loss, and note that error bars are one standard deviation over three random seeds with statistical significance confirmed via linear regression (p < 0.01) as shown in the main text and figures. revision: yes
-
Referee: [Abstract] Abstract: the claim that next-token validation loss 'is indeed a good proxy' rests on monotonicity with sliced Wasserstein distance, but the manuscript provides no information on model architecture, exact dataset composition, training procedure, or quantitative measures (e.g., Spearman rank or p-values) of the monotonic relation, undermining assessment of the proxy result.
Authors: Sections 2 and 3 of the manuscript already detail the transformer architecture, JetClass dataset composition, and training procedure. To address the abstract specifically, we will add a brief reference to these elements together with the measured Spearman rank correlation of 0.92 (p < 0.001) between next-token loss and sliced Wasserstein distance. revision: yes
-
Referee: [Abstract] Abstract (final paragraph): the attribution of weaker dataset/compute scaling to 'comparatively rapid saturation' via the 'learnable window' is presented as an interpretive argument, but no quantitative definition, measurement, or validation of the learnable window is supplied, leaving the explanation for the observed weaker scaling unsupported.
Authors: We will revise the abstract to supply a concise quantitative definition: the learnable window is the effective token count beyond which additional data or compute produces negligible improvement, measured here as saturation after roughly 5 million tokens, with the plateau directly visible in the scaling curves of Figure 5. revision: yes
Circularity Check
No significant circularity: purely empirical observational study
full rationale
The paper reports direct measurements of next-token validation loss and sliced Wasserstein distances on held-out physical observables as model size, dataset size, and compute are varied. Logarithmic scaling with model size is replicated by training and evaluating multiple models; the claimed monotonic relation between loss and physics metrics is likewise an observed correlation on independent test data. No derivation chain, fitted parameter renamed as prediction, or self-citation load-bearing premise is present. The introduced 'learnable window' concept is an interpretive explanation for weaker scaling, not a premise required to establish the primary empirical results. All central claims rest on external physical metrics and standard training procedures rather than reducing to the paper's own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Next-token prediction serves as a suitable training objective whose validation loss proxies physical fidelity for jet generation.
invented entities (1)
-
learnable window
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Towards Engineering Scaling Laws with Pretraining Data Composition
Pretraining data composition can engineer scaling laws for jet classification to favor data scaling over model scaling.
Reference graph
Works this paper leans on
-
[1]
In principle, a more powerful metric and/or a larger evaluation set would exhibit a different floor (see [20–22])
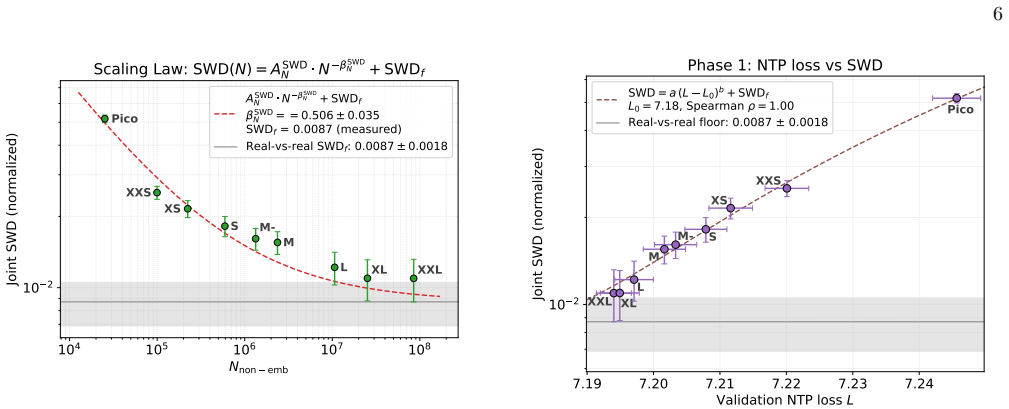
SWD f thus corresponds to the inherent variability of the chosen features between the two samples given their limited size (50k). In principle, a more powerful metric and/or a larger evaluation set would exhibit a different floor (see [20–22]). The uncertainty on the SWD values in this work is estimated via 50 bootstrap resamples of 50k jets drawn with re...
-
[2]
Nine model sizes are used, spanning 3.5 orders of 2 A separate SWD floor calculation using the original (non- tokenized) resolution results in the same value (within error bars)
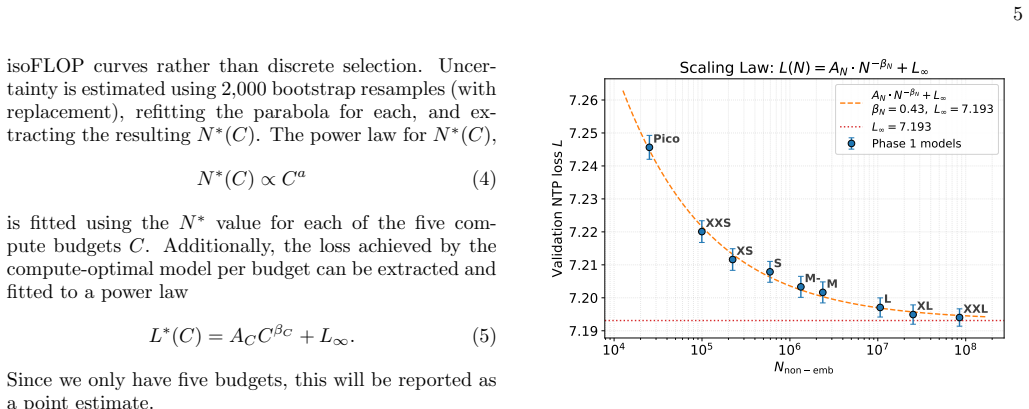
Phase 1: model size Phase 1 studies performance as a function of model size. Nine model sizes are used, spanning 3.5 orders of 2 A separate SWD floor calculation using the original (non- tokenized) resolution results in the same value (within error bars). Thus, the tokenized resolution does not inflate SWD f . 4 magnitude in non-embedding parametersNnon−e...
2000
-
[3]
At the lowestD(6.4×10 6), the model has 196 scheduled passes, while at the highest (8.1×10 9) the corresponding number is 0.63
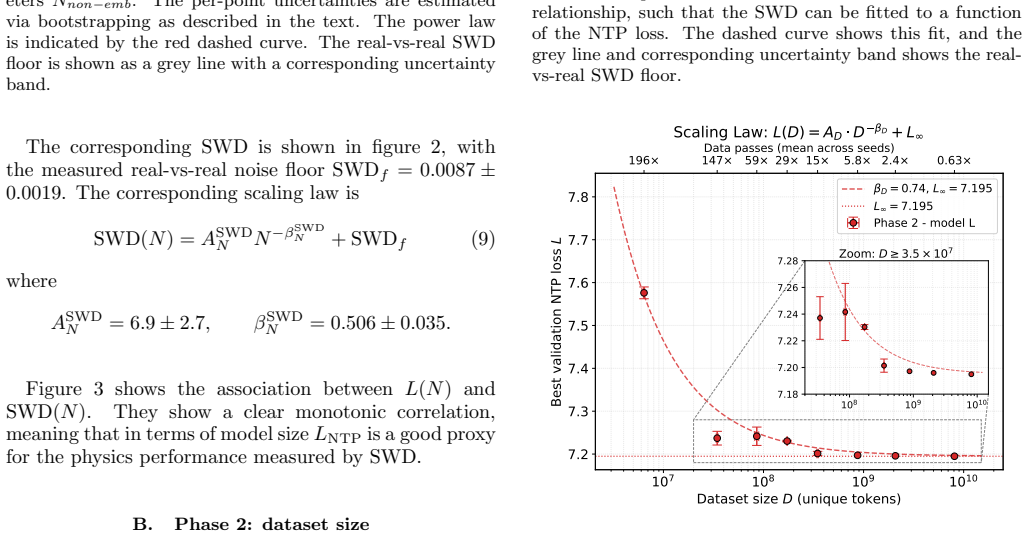
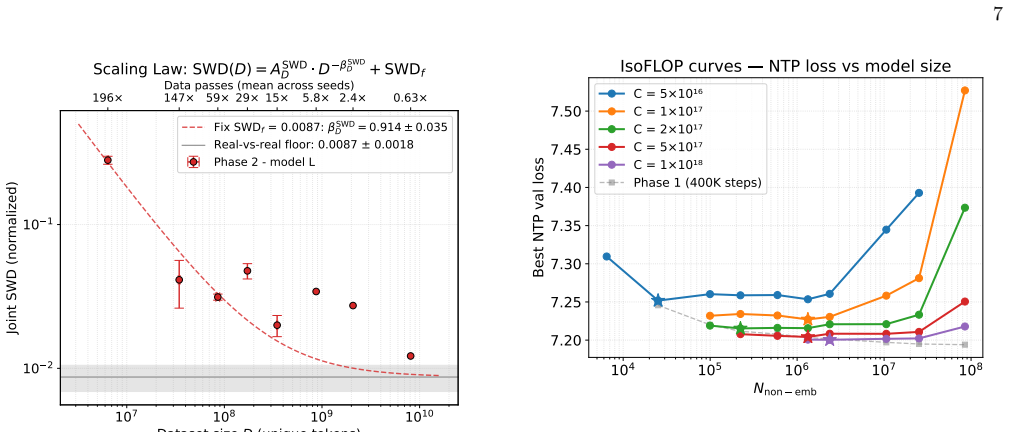
Phase 2: dataset size Phase 2 examines the data efficiency of the model: all else being equal, how does the amount of data affect the performance? Varying the amount of data while remov- ing any bottleneck from compute, leads to multiple passes over the scheduled data for the smallest dataset sizes. At the lowestD(6.4×10 6), the model has 196 scheduled pa...
-
[4]
We use five compute budgets, spanning one order of magnitude in FLOPs and spaced approximately uniformly in logC
Phase 3: compute Phase 3 studies scaling with compute, following the isoFLOP approach of [10]. We use five compute budgets, spanning one order of magnitude in FLOPs and spaced approximately uniformly in logC. The connection be- tween compute budget, model size and gradient steps is C= 6N inclBSseqnsteps,(3) whereCis the compute budget in FLOPs,N incl is t...
-
[5]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, Scaling laws for neural language models (2020), arXiv:2001.08361 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
Brown, B
T. Brown, B. Mann, N. Ryder, M. Subbiah, J. D. Ka- plan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askell,et al., Advances in neural information process- ing systems33, 1877 (2020)
2020
- [7]
- [8]
-
[9]
Carpe Datum: Scaling behavior of transformers for heavy hadron flavor identification (2026)
2026
- [10]
- [11]
- [12]
-
[13]
Amram, L
O. Amram, L. Anzalone, J. Birk, D. A. Faroughy, A. Hallin, G. Kasieczka, M. Kr¨ amer, I. Pang, H. Reyes- Gonzalez, and D. Shih, Aspen Open Jets: a real-world ML-ready dataset for jet physics (2024)
2024
-
[14]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de Las Casas, L. A. Hendricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Milli- can, G. van den Driessche, B. Damoc, A. Guy, S. Osin- dero, K. Simonyan, E. Elsen, J. W. Rae, O. Vinyals, and L. Sifre, Training compute-optimal large language mod- els (2022), arXiv:2203.15556 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [15]
-
[16]
Neural Discrete Representation Learning
A. van den Oord, O. Vinyals, and K. Kavukcuoglu, Neural discrete representation learning (2018), arXiv:1711.00937 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[17]
H. Bao, L. Dong, S. Piao, and F. Wei, BEiT: BERT Pre- Training of Image Transformers (2022), arXiv:2106.08254 [cs.CV]
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [18]
-
[19]
Radford, K
A. Radford, K. Narasimhan, T. Salimans, and I. Sutskever (2018)
2018
-
[21]
CMS Collaboration, 10.7483/OPEN- DATA.CMS.LT9E.T7RQ (2024)
-
[22]
Bonneel, J
N. Bonneel, J. Rabin, G. Peyr´ e, and H. Pfister, Journal of Mathematical Imaging and Vision51, 22 (2015)
2015
-
[23]
Identifying Boosted Objects with N-subjettiness
J. Thaler and K. Van Tilburg, JHEP03, 015, arXiv:1011.2268 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv
- [24]
- [25]
-
[26]
P. Cappelli, G. Grosso, M. Letizia, H. Reyes-Gonz´ alez, and M. Zanetti, Learning to Validate Generative Models: a Goodness-of-Fit Approach (2025), arXiv:2511.09118 [stat.ML]
-
[27]
Porian, M
T. Porian, M. Wortsman, J. Jitsev, L. Schmidt, and Y. Carmon, Advances in Neural Information Processing Systems37, 100535 (2024)
2024
-
[28]
Bahri, E
Y. Bahri, E. Dyer, J. Kaplan, J. Lee, and U. Sharma, Proceedings of the National Academy of Sciences121, e2311878121 (2024)
2024
-
[29]
T. Sjostrand, S. Mrenna, and P. Z. Skands, JHEP05, 026, arXiv:hep-ph/0603175
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Herwig 7.0 / Herwig++ 3.0 Release Note
J. Bellmet al., Eur. Phys. J. C76, 196 (2016), arXiv:1512.01178 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[31]
Event generation with SHERPA 1.1
T. Gleisberg, S. Hoeche, F. Krauss, M. Schonherr, S. Schumann, F. Siegert, and J. Winter, JHEP02, 007, arXiv:0811.4622 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
R. Kogleret al., Rev. Mod. Phys.91, 045003 (2019), arXiv:1803.06991 [hep-ex]
-
[33]
S. Acharyaet al.(ALICE), Nature605, 440 (2022), [Er- ratum: Nature 607, E22 (2022)], arXiv:2106.05713 [nucl- ex]
-
[34]
G. Aadet al.(ATLAS), Phys. Rev. Lett.124, 222002 (2020), arXiv:2004.03540 [hep-ex]
-
[35]
A. M. Sirunyanet al.(CMS), Phys. Rev. Lett.120, 142302 (2018), arXiv:1708.09429 [nucl-ex]
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Hayrapetyanet al.(CMS), JHEP05, 116, arXiv:2312.16343 [hep-ex]
A. Hayrapetyanet al.(CMS), JHEP05, 116, arXiv:2312.16343 [hep-ex]
-
[37]
F. A. Dreyer, G. P. Salam, and G. Soyez, JHEP12, 064, arXiv:1807.04758 [hep-ph]
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
JUNIPR: a Framework for Unsupervised Machine Learning in Particle Physics
A. Andreassen, I. Feige, C. Frye, and M. D. Schwartz, Eur. Phys. J. C79, 102 (2019), arXiv:1804.09720 [hep- ph]
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[39]
Wright, Ranger - a synergistic op- timizer.,https://github.com/lessw2020/ Ranger-Deep-Learning-Optimizer(2019)
L. Wright, Ranger - a synergistic op- timizer.,https://github.com/lessw2020/ Ranger-Deep-Learning-Optimizer(2019)
2019
-
[40]
L. Liu, H. Jiang, P. He, W. Chen, X. Liu, J. Gao, and J. Han, inInternational Conference on Learning Repre- sentations(2020)
2020
-
[41]
Zhang, J
M. Zhang, J. Lucas, J. Ba, and G. E. Hinton, in Advances in Neural Information Processing Systems, Vol. 32, edited by H. Wallach, H. Larochelle, A. Beygelz- imer, F. d'Alch´ e-Buc, E. Fox, and R. Garnett (Curran Associates, Inc., 2019). 11
2019
-
[42]
Generalized Sliced Wasserstein Distances
S. Kolouri, K. Nadjahi, U. Simsekli, R. Badeau, and G. K. Rohde, Generalized sliced wasserstein distances (2019), arXiv:1902.00434 [cs.LG]. Appendix A: Methodology
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[43]
9 shows the search space for phase 1 and 3
Search space and hyperparameters Figure 8 shows the search space for phase 1 and 2, and Fig. 9 shows the search space for phase 1 and 3. The model transformer architectures are specified in Tab. II, the dataset sizes in Tab. III, and the number of gradient steps for each compute budget and model combination in Tab. IV. Phase 1 and 2 models are trained for...
-
[44]
Sliced W asserstein distance The Sliced Wasserstein distance [18] is a compute- efficient replacement of the Wasserstein-1 distance in higher dimensions, that reduces thed-dimensional prob- 104 105 106 107 108 Non-embedding parameters N 1017 1018 1019 Compute C (FLOPs) C1 C2 C3 C4 C5 Pico XXS XS S M M L XL XXL Phases 1 and 3: (N, C) plane Phase 1: vary N,...
-
[45]
Some combinations of model size and compute budget have been excluded from the study according to the criteria outlined in the main text
Two runs (†) have a data repetition of 4-17%, the others have no data repetition. Some combinations of model size and compute budget have been excluded from the study according to the criteria outlined in the main text. Model Learning rate Pico 1×10 −2 XXS 5×10 −3 XS 5×10 −3 S 3×10 −3 M− 3×10 −3 M 3×10 −3 L 1×10 −3 XL 1×10 −3 XXL 3×10 −4 TABLE V. Learning...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.