Structured Prompt Optimization Meets Reinforcement Learning for Global and Local Interpretability over Complex Text
Pith reviewed 2026-06-29 12:23 UTC · model grok-4.3
The pith
eXTC learns a natural-language rulebook via structured prompt optimization, distills it into a compact model, then expands it with reinforcement learning to deliver both local reasoning traces and global modular explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
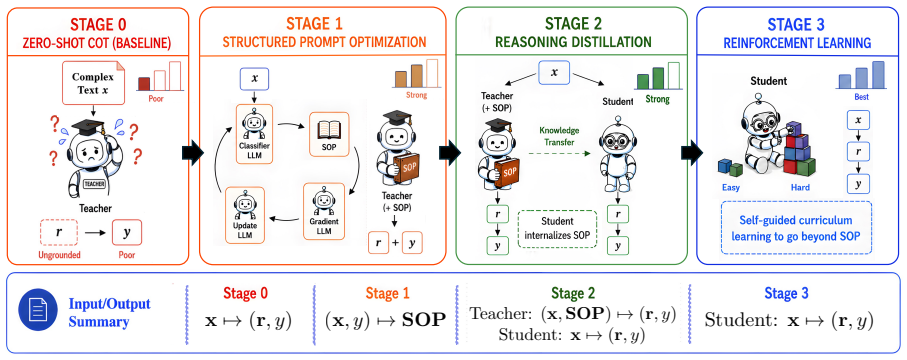
The central claim is that the three progressive stages—Structured Prompt Optimization to produce an SOP rulebook, SOP-grounded distillation from a large teacher into a compact LM, and subsequent reinforcement-learning expansion—jointly enable fast inference, local reasoning traces at inference time, a global modular explanation of domain rules, and stage-by-stage gains in both classification performance and explanation quality over existing paradigms.
What carries the argument
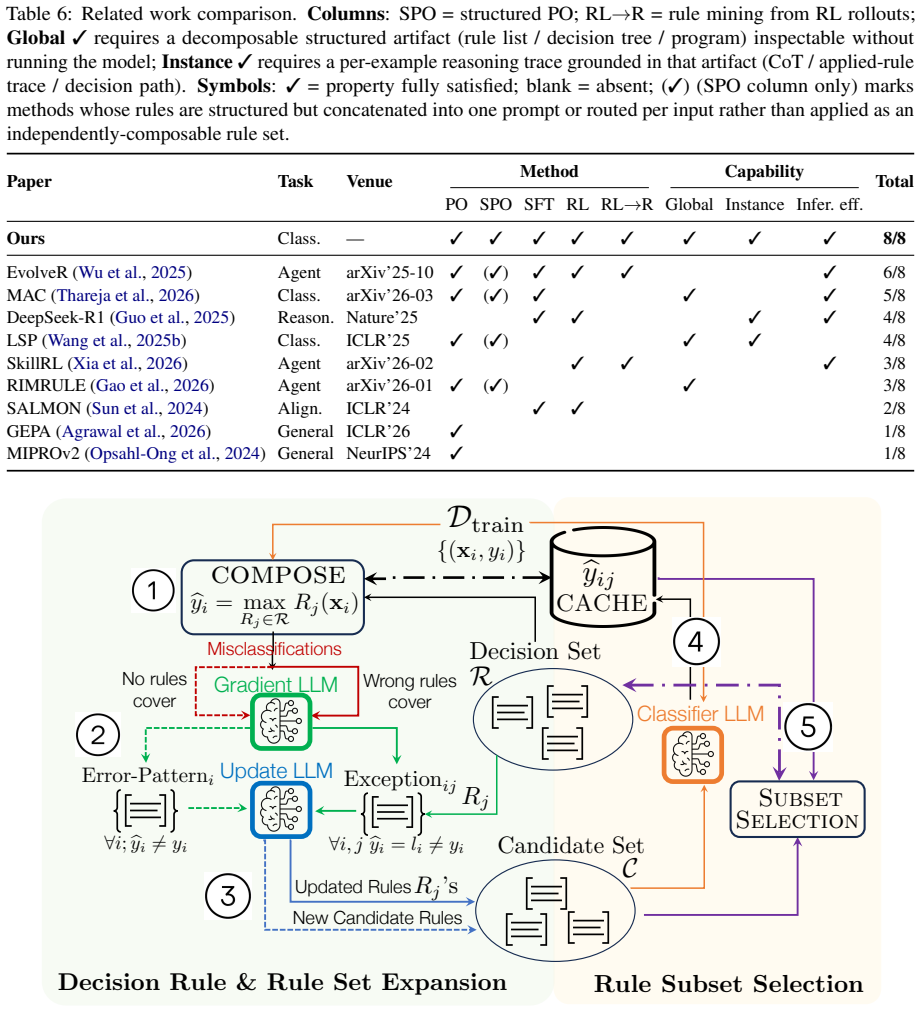
The eXTC pipeline whose central object is the Standard Operating Procedure (SOP), a natural-language rulebook that grounds both the distillation step and the modular global explanation while remaining compatible with later RL expansion.
If this is right
- Stage-by-stage improvements appear in both classification accuracy and explanation quality on diverse benchmarks.
- The compact LM supports fast inference while still emitting local reasoning traces at test time.
- A single learned SOP supplies a global, modular, human-readable account of the domain rules the model has internalized.
- The same three-stage sequence is asserted to outperform both pure supervised fine-tuning and pure discrete prompt optimization baselines.
Where Pith is reading between the lines
- The SOP could be inspected or edited by domain experts before the distillation and RL stages, turning the model into an editable rule-based system.
- The same staged recipe might transfer to sequence labeling or generation tasks where both local decisions and global policy explanations are desired.
- If the SOP remains stable after RL, it could serve as a portable, human-auditable artifact that other models or even non-LLM systems could adopt.
Load-bearing premise
The reinforcement-learning expansion step can improve performance without eroding the SOP grounding or the global and local interpretability produced by the first two stages.
What would settle it
A controlled run in which the RL stage is added and either overall accuracy fails to rise or the generated local traces and global SOP explanations measurably diverge from or lose fidelity to the rulebook obtained after stage two.
Figures






read the original abstract
LLMs have advanced text classification, yet existing paradigms face a trade-off: supervised (label only) fine-tuning is scalable but offers limited reasoning on complex text and lacks broader model transparency, while discrete prompt optimization offers human-readable instructions but struggles with performance and scalability. We introduce eXTC (eXplainable Text Classifier) with three progressive stages: (1) learning a Standard Operating Procedure (SOP, or rulebook) in natural language via a new Structured Prompt Optimization algorithm; (2) SOP-grounded reasoning distillation from a large teacher LLM into a compact LM; and (3) expanding reasoning capabilities beyond the initial SOP via reinforcement learning. This design enables eXTC to provide (i) fast inference via a compact LM, with (ii) inference-time local reasoning traces, alongside a global, modular explanation of its learned domain rules, while (iii) significantly outperforming existing paradigms across diverse benchmarks in both classification performance and explanation quality, with stage-by-stage gains.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces eXTC, a three-stage framework for explainable text classification. Stage 1 learns a natural-language Standard Operating Procedure (SOP) via Structured Prompt Optimization. Stage 2 distills SOP-grounded reasoning from a large teacher into a compact LM. Stage 3 applies reinforcement learning to expand reasoning beyond the initial SOP. The design is claimed to yield fast inference on the compact model, inference-time local reasoning traces, a global modular explanation of domain rules, and significant outperformance over existing paradigms on diverse benchmarks in both classification accuracy and explanation quality, with measurable gains at each stage.
Significance. If the empirical claims are substantiated, the work would meaningfully address the performance-interpretability trade-off in text classification by delivering both global modular rulebooks and local traces within a deployable compact model. The staged pipeline that begins with human-readable SOPs and then augments them via RL is a coherent architectural idea that could influence subsequent research on modular, auditable NLP systems.
major comments (2)
- [Abstract] Abstract: the central claim that eXTC 'significantly outperform[s] existing paradigms across diverse benchmarks in both classification performance and explanation quality, with stage-by-stage gains' is asserted without any reported metrics, baselines, datasets, or ablation tables; this absence is load-bearing because the entire contribution rests on the empirical superiority and progressive improvement assertions.
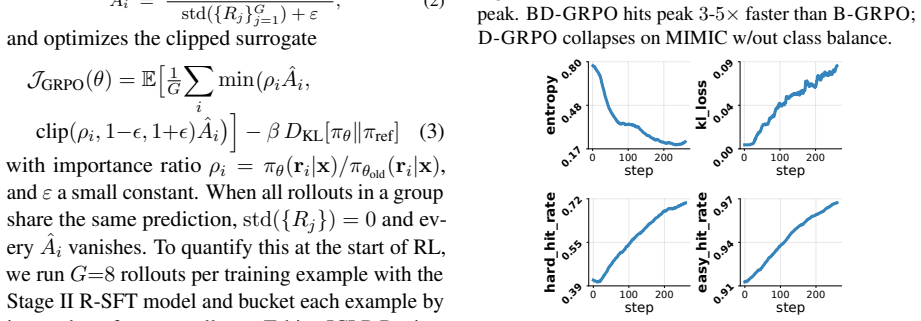
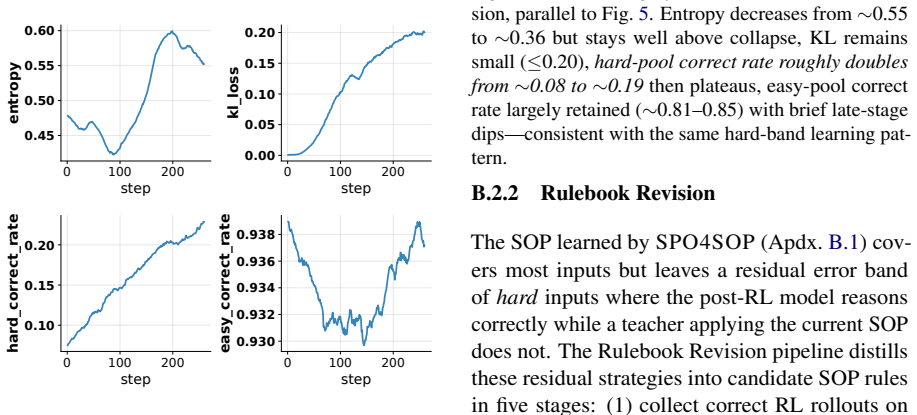
- [Stage 3 description] Stage 3 (RL expansion): no reward design, regularization term, or post-RL verification procedure is described that would guarantee retention of the SOP grounding and modularity produced by stages 1 and 2; without such mechanisms the interpretability guarantees are at risk of erosion, directly undermining the global/local explanation claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where the manuscript can be strengthened. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that eXTC 'significantly outperform[s] existing paradigms across diverse benchmarks in both classification performance and explanation quality, with stage-by-stage gains' is asserted without any reported metrics, baselines, datasets, or ablation tables; this absence is load-bearing because the entire contribution rests on the empirical superiority and progressive improvement assertions.
Authors: We agree that the abstract would benefit from greater specificity to substantiate the claims. The full manuscript reports these results in Section 4 (including Tables 1-3 with accuracy and explanation quality metrics, baselines such as standard fine-tuning and prompt optimization methods, datasets, and stage-wise ablations). In the revision we will update the abstract to include key quantitative results and explicit references to the experimental setup. revision: yes
-
Referee: [Stage 3 description] Stage 3 (RL expansion): no reward design, regularization term, or post-RL verification procedure is described that would guarantee retention of the SOP grounding and modularity produced by stages 1 and 2; without such mechanisms the interpretability guarantees are at risk of erosion, directly undermining the global/local explanation claims.
Authors: The current manuscript presents Stage 3 at a high level. We will expand the Methods section to detail the reward function (a weighted combination of task accuracy and an SOP-adherence penalty), the regularization term that penalizes deviation from the modular SOP structure, and the post-RL verification procedure (automated rule-matching checks plus human evaluation of retained global rules and local trace fidelity). These additions will make the preservation of interpretability explicit. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The paper outlines a three-stage pipeline (SOP learning via prompt optimization, distillation, then RL expansion) with claims of stage-by-stage gains in performance and interpretability. No equations, fitted parameters, self-definitional constructs, or load-bearing self-citations appear in the abstract or described method. The central claims rest on empirical benchmarks rather than any derivation that reduces to its own inputs by construction. This is a self-contained empirical proposal without detectable circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904
Legal-bert: The muppets straight out of law school. InFindings of the association for computa- tional linguistics: EMNLP 2020, pages 2898–2904. Sanjiv R. Das and Mike Y . Chen. 2007. Yahoo! for amazon: Sentiment extraction from small talk on the web.Manag. Sci., 53(9):1375–1388. Chenlong Deng, Kelong Mao, Yuyao Zhang, and Zhicheng Dou. 2024. Enabling disc...
-
[2]
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines
Mimic-iv, a freely accessible electronic health record dataset.Scientific Data, 10(1). Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vard- hamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. DSPy: Compiling declarative language model calls ...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Yuta Koreeda and Christopher D
Captum: A unified and generic model in- terpretability library for PyTorch.arXiv preprint arXiv:2009.07896. Yuta Koreeda and Christopher D. Manning. 2021. Con- tractnli: A dataset for document-level natural lan- guage inference for contracts. InFindings of the Association for Computational Linguistics: EMNLP, Findings of ACL, pages 1907–1919. Association ...
-
[4]
gradient descent
LLM evaluators recognize and favor their own generations. InAdvances in Neural Information Processing Systems (NeurIPS). Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chen- guang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with "gradient descent" and beam search. InProceedings of the 2023 Conference on Empirical Methods in Natural Language...
2023
-
[5]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
ACM. Cynthia Rudin. 2019. Stop explaining black box ma- chine learning models for high stakes decisions and use interpretable models instead.Nat. Mach. Intell., 1(5):206–215. Said Salloum, Tarek Gaber, Sunil Vadera, and Khaled Shaalan. 2022. A systematic literature review on phishing email detection using natural language pro- cessing techniques.Ieee Acce...
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Evolver: Self-evolving LLM agents through an experience-driven lifecycle.CoRR, abs/2510.16079. Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xu- jiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. 2026. SkillRL: Evolving agents via recursive skill-augmented reinforcement learning. arXiv preprin...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO: an open-source LLM reinforcement learning system at scale.CoRR, abs/2503.14476. Mert Yüksekgönül, Federico Bianchi, Joseph Boen, Sheng Liu, Pan Lu, Zhi Huang, Carlos Guestrin, and James Zou. 2025. Optimizing generative AI by backpropagating language model feedback.Nat., 639(8055):609–616. Daoze Zhang, Zhijian Bao, Sihang Du, Zhiyi Zhao, Kuangling Zh...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
arXiv preprint arXiv:2505.07920
Re 2: A consistency-ensured dataset for full- stage peer review and multi-turn rebuttal discussions. arXiv preprint arXiv:2505.07920. Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. 2024. Llamafactory: Unified efficient fine-tuning of 100+ language models. In Proceedings of the 62nd Annual Meeting of the Asso- ciation for Computation...
-
[9]
g6ZIM/129t2YQ+0lhWYKNjbqHUQ=
and verifiable-reward RL (DeepSeek-R1, Guo et al., 2025) improve reasoning quality beyond the teacher; a separate line uses learned reward models to align LLMs with high-level principles (SALMON, Sun et al., 2024), targeting alignment rather than task-specific reasoning. Our Stage II conditions the teacher on the SOP so that the stu- dent inherits a rule-...
2025
-
[10]
Context Assessment What was the intended behavior? What actually happened? What key factors contributed?
-
[11]
YES” or “NO
Rule Evaluation Do existing rules partially cover this? What aspects are unique? How can we make the rule robust? </ERROR_ANALYSIS> Provide the error analysis in the error_analysis field. Then, formulate a new rule using this structure: <RULE_NAME>[Concise, descriptive name that clearly identifies the pattern]</RULE_NAME> <RULE_DESCRIPTION> Trigger Patter...
2021
-
[12]
entailment because Sec- tion 3.1 prohibits X
jointly balancing the binary readmission la- bel and the discharge service, yielding an 8,000 / 1,000 / 1,000 train/val/test split with no pa- tient overlap across splits. Evidence is a struc- tured per-admission summary aligned to the LACE (van Walraven et al., 2010) schema; comorbidities are mapped fromdiagnoses_icd via Quan-2005 Charlson coding (Quan e...
2010
-
[13]
Read{evidence_phrase} carefully and identify the specific facts
-
[14]
Find the reasoning’s CONCLUSION (predicted label / verdict)
-
[15]
General verdict-justification without specific citation = anchor 3
Check whether the conclusion is DIRECTLY tied to specific cited evidence (section #, reviewer #/score, clinical value, named rule + evidence, or exclusion enumeration). General verdict-justification without specific citation = anchor 3
-
[16]
Apply the CALIBRATION strictly. Example. Evidence:{source} Reasoning:{reasoning} Evaluation Form (scores ONLY): - Groundedness: Auxiliary judge: motivation and model.We use gpt-4o-mini (OpenAI, 2024) with a G-Eval- styleFaithfulnessrubric (Liu et al., 2023) on the input–reasoning pair (x,r) ,notthe evidence– reasoning pair (xev,r) : xev is by construction...
2024
-
[17]
Read {input} carefully and identify the facts it presents
-
[18]
Check if the reasoning makes claims that go beyond, contradict, or misread{input}
Read the reasoning and compare it to {input}. Check if the reasoning makes claims that go beyond, contradict, or misread{input}
-
[19]
decides whether the contract entails, contradicts, or does not men- tion the hypothesis
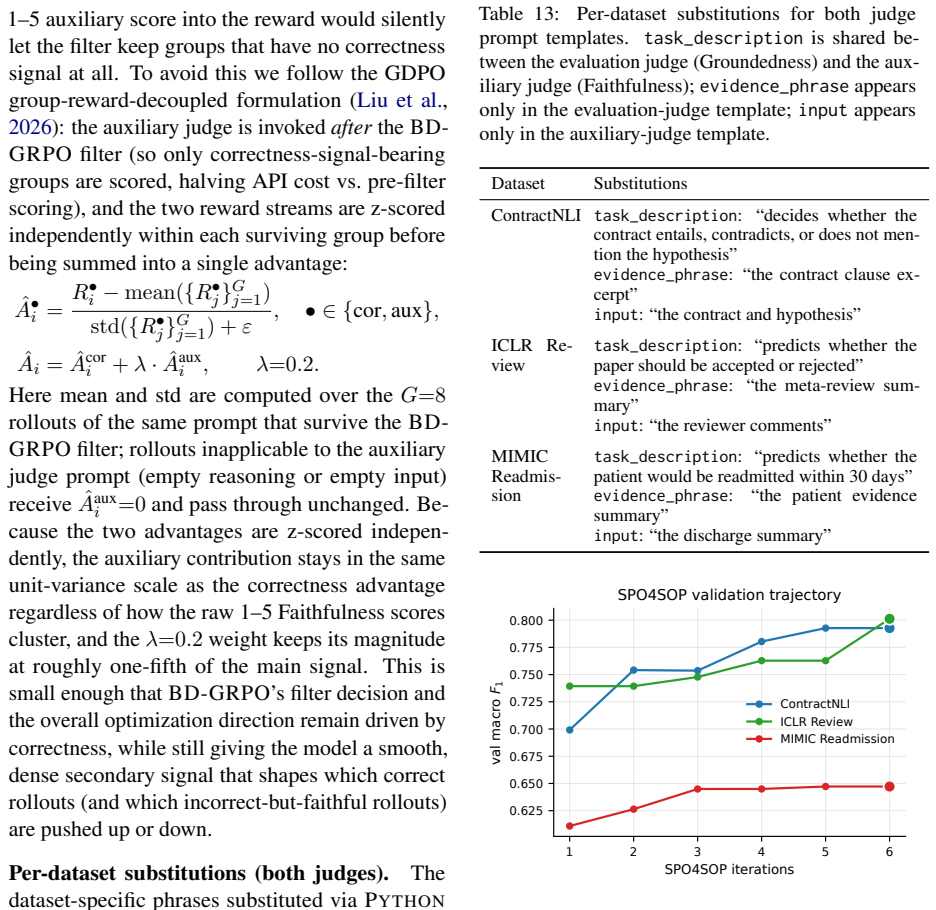
Assign a score for faithfulness based on the Evalua- tion Criteria. Example: Input: {source} Reasoning: {reasoning} Evaluation Form (scores ONLY): - Faithfulness: Auxiliary judge: call cost.With train batch B=16 prompts per step, rollout group size G=8, and T=260 training steps per run, the auxiliary judge is calledB·G·T= 16·8·260 = 33,280 times per run. ...
2026
-
[20]
Authorized Persons,
Expressly permits disclosure to a defined third-party category or representative group, including broad terms like “Authorized Persons,” consultants, agents, contractors, professional advisors, legal/financial advisors, or accountants
-
[21]
except as expressly permitted
Restricts disclosure to third parties “except as expressly permitted” or otherwise contains an internal carveout that makes the ban non-absolute
-
[22]
Allows disclosure with the prior written consent or other written consent of the Disclosing Party, and the hypothesis is consistent with that consent-based permission
-
[23]
Is merely silent, vague, or ambiguous about third-party disclosure rather than expressly prohibiting it
-
[24]
Receiving Party shall not divulge Confidential Information to any third party for any purpose unless expressly authorized in writing by Disclosing Party
Uses a broad permitted-recipient definition that can reasonably encompass the hypothesis’s examples (e.g., consultants, agents, professional advisors), even if not listed verbatim. Examples. Source text:“Receiving Party shall not divulge Confidential Information to any third party for any purpose unless expressly authorized in writing by Disclosing Party....
-
[25]
The contract expressly allows retention of specific archival, legal, regulatory, or backup copies
-
[26]
The contract is only about return/destruction of existing materials and is silent on post-termination retention; if the hypothesis is about retaining copies, that may be NotMentioned unless retention is prohibited
-
[27]
The hypothesis is about the right to create copies in some circumstances, rather than to keep existing copies after termination; that is a different topic
-
[28]
The contract never addresses copies at all, and the only relevant issue is general copying permission
-
[29]
Upon request or termination, Receiving Party shall return all Information and destroy all materials containing Information and shall not keep copies or duplicates thereof
The hypothesis concerns a different subject unrelated to post-termination possession, return, destruction, or copy retention. Examples. Source text:“Upon request or termination, Receiving Party shall return all Information and destroy all materials containing Information and shall not keep copies or duplicates thereof.” Wrong:Label 0 for “The Receiving Pa...
-
[30]
One or more reviewers explicitly recommend acceptance, marginal-accept, or clearly revise upward after rebuttal
-
[31]
The overall discussion is mixed-to-positive: substantive praise for novelty, usefulness, clarity, significance, strong results, or impact outweighs the concerns
-
[32]
The criticisms are mainly fixable or exploratory issues (extra ablations, more comparisons, clarification, code, presenta- tion, sensitivity analysis) rather than fatal methodological flaws
-
[33]
Positive language is substantive endorsement of the paper’s contribution, not mere politeness
-
[34]
The idea is interesting and the paper is well written, but the contribution feels incremental, the experiments are insufficient, and I still cannot recommend acceptance
A single rejection-leaning review should not dominate if other reviewers are positive or acceptance-leaning, especially when the negative review itself is mixed and ends with openness to revision. Examples. Source text:“The idea is interesting and the paper is well written, but the contribution feels incremental, the experiments are insufficient, and I st...
-
[35]
Two or more reviewers explicitly recommend acceptance, or clearly lean acceptance, and the negative comments are secondary
-
[36]
The unfavorable review is an outlier while the other reviews are broadly positive or supportive
-
[37]
The main issues are requests for more ablations, baselines, sensitivity tests, clearer framing, or related-work discussion, without questioning the paper’s central merit
-
[38]
novel,” “promising,
Reviews contain explicit praise such as “novel,” “promising,” “interesting,” “useful,” “state of the art,” or “good contribution,” and these positives are echoed by multiple reviewers
-
[39]
Examples
Mixed reviews still conclude with practical value or endorsement of the approach, especially when comments emphasize presentation/coverage limitations rather than fatal flaws. Examples. Source text:“Reviewer 1: good writing, but the gains are not convincing. Reviewer 2: this is a minor extension with weak experiments. Reviewer 3: promising, but I still re...
-
[40]
Pending pathology, cytology, biopsy, molecular testing, or other results that may change near-term management
-
[41]
Active concern for malignancy or another serious disease based on imaging, tumor markers, specialist concern, or uncertain diagnosis
-
[42]
Exceptions:Do not apply label 1 for:
Explicit near-term specialty follow-up for reassessment, staging, or treatment planning within days to a few weeks. Exceptions:Do not apply label 1 for:
-
[43]
Routine post-procedure or post-op pathology when the main inpatient problem has been treated, the patient is clinically stable, and follow-up is routine outpatient review
-
[44]
Diagnosis already established during admission with only a confirmatory pending test or part of standard cancer follow-up, with outpatient oncology/neurosurgery already arranged
-
[45]
Routine monitoring labs or pending tests (e.g., viral load, HIV , standard infection workup, echo/cath results, repeat echo) with no major diagnostic uncertainty and no immediate management change expected
-
[46]
Chronic/known disease managed long-term when the acute hospitalization issue is resolved, even if outpatient specialty follow-up continues
-
[47]
Pleural effusion drained; cytology/pathology pending; imaging concerning for malignancy / lymphadenopathy; oncology follow-up in 2 weeks; discharged home stable
Routine/non-urgent surveillance or elective outpatient treatment, or when the patient is stable for discharge without urgent reassessment; also when the admission was complicated by treated issues (acute systolic HF/AKI/bridging anticoag- ulation/low EF) but the discharge plan is stable outpatient management. Examples. Source text:“Pleural effusion draine...
-
[48]
The ascites/instability is due to malignancy, terminal cancer, or general functional decline rather than cirrhosis/liver failure
-
[49]
There is no clear evidence of cirrhosis/portal hypertension/hepatic encephalopathy/MELD-based liver failure
-
[50]
A single paracentesis or supportive treatment is for malignant ascites and not recurrent cirrhotic decompensation
-
[51]
The acute issue is treated and improving, and the remaining plan is mainly palliative/hospice/disposition planning rather than ongoing cirrhosis instability
-
[52]
Do not label 1 solely because of severe labs/ascites if the transition is transfer-driven rather than a standard discharge home
The case is not a completed discharge after stabilization, but instead an in-hospital transfer to another facility/higher level of care (e.g., transplant evaluation) for ongoing inpatient management. Do not label 1 solely because of severe labs/ascites if the transition is transfer-driven rather than a standard discharge home
-
[53]
accept,” “weak accept,
The chronic liver disease is clearly compensated or follow-up is routine without ongoing instability. Examples. Source text:“Advanced alcoholic cirrhosis with hepatic encephalopathy from lactulose nonadherence, acute on chronic se- vere anemia requiring 2 units PRBCs, large ascites requiring therapeutic paracentesis, hyponatremia, MELD 30, discharged afte...
-
[54]
Base your decision on the collective implication of the reviews, not on isolated positive or negative sentences
-
[55]
Do not count polite tone, gratitude, or soft language as evidence of acceptance
-
[56]
If a reviewer mentions rebuttal or author response, only treat it as positive if the reviewer explicitly says their rating increased, their concerns were addressed, or they now support acceptance
-
[57]
acceptable with revisions
If the reviews are mixed but the overall implication is clearly “acceptable with revisions”, “would not oppose acceptance”, “inclined to accept”, “worth accepting”, or a score was raised toward acceptance, label‘accept’
-
[58]
If the reviews collectively emphasize substantial problems, especially any of the following, label‘reject’: – limited novelty / incremental contribution – weak, incomplete, or unconvincing experiments – only one domain/task, especially a narrow synthetic/toy/artificial setup, with no broader validation – poor or missing baselines/comparisons – unclear gen...
-
[59]
well written
Positive remarks such as “well written”, “interesting”, “important problem”, or “technically sound” are not enough for ‘accept’if major concerns remain
-
[60]
If a reviewer explicitly recommends rejection, treat that as a strong negative signal unless other reviews clearly and explicitly support acceptance overall
-
[61]
If most reviewers are constructive and overall supportive, accept
-
[62]
If the main objections are about presentation/clarity only, but the results and novelty are otherwise strong and reviewers lean positive, accept
-
[63]
recommend accept
If the main objections are about novelty, scope, applicability, missing experiments, missing comparisons, or weak validation, reject even when the paper is described positively in other respects. Useful aggregation strategy: – Pay special attention to final recommendation language and score changes. – Weigh explicit statements like “recommend accept”, “in...
-
[64]
Check the discharge condition and overall course first
-
[65]
Look for explicit instability, deterioration, or expected near-term return
-
[66]
If the summary says stable, improved, controlled, hemodynamically stable, breathing comfortably, alert, or ready for discharge, choose 0
-
[67]
If the summary says unresolved acute problems are still active and likely to rebound quickly, choose 1
-
[68]
Give extra weight to unresolved bacteremia, persistent sepsis, pending speciation with positive blood cultures, incomplete source control, and explicit concern that outpatient management may fail
-
[69]
Output format:Return only the integer label
When in doubt, choose 0. Output format:Return only the integer label. Do not explain your answer. Do not output any extra text. Table 30: GEPA-optimized instruction prompt for MIMIC Readmission. 39
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.