RUBRIC-ARROW: Alternating Pointwise Rubric Reward Modeling for LLM Post-training in Non-verifiable Domains
Pith reviewed 2026-06-29 13:11 UTC · model grok-4.3
The pith
RUBRIC-ARROW jointly trains a rubric generator and judge from pairwise data to produce pointwise rewards for subjective LLM tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RUBRIC-ARROW is an alternating framework that jointly trains a rubric generator and a rubric-conditioned judge. Its RL stage uses only pairwise preference data, coupling a probability-based scoring rule that reduces ties with phase-specific preference-based rewards and an alternating GRPO scheme that together train the pointwise evaluator.
What carries the argument
Alternating GRPO optimization between a rubric generator and a rubric-conditioned judge, combined with probability-based scoring and phase-specific preference rewards.
If this is right
- The trained judge achieves competitive accuracy against existing reward models on standard benchmarks.
- Downstream policy optimization using the resulting pointwise scores produces consistent performance gains.
- Probability-based scoring measurably lowers the rate of tied evaluations compared with Boolean aggregation.
- The method requires only pairwise preference data and does not need frontier LLMs at inference time.
Where Pith is reading between the lines
- The same alternating loop could be applied to other preference datasets where absolute scores would help training stability.
- If the rubric generator learns reusable criteria, the approach might transfer across related subjective tasks without retraining from scratch.
- Testing the judge on held-out subjective domains such as creative writing or ethical reasoning would reveal whether the pointwise signals generalize beyond the training preferences.
Load-bearing premise
Jointly training the rubric generator and rubric-conditioned judge via alternating GRPO with probability-based scoring and phase-specific preference rewards will produce an effective pointwise evaluator from pairwise data alone in non-verifiable domains.
What would settle it
An experiment in which the alternating model shows no accuracy gain over a non-alternating baseline judge or produces more scoring ties than a simple probability threshold would predict.
Figures



read the original abstract
Pointwise reward modeling offers critical signals for LLM post-training, yet struggles with absolute scoring in subjective, non-verifiable settings. Rubric-based methods address this by decomposing evaluation into explicit criteria, but existing approaches typically depend on frontier LLMs and suffer from ties caused by hard Boolean aggregation. We present RUBRIC-ARROW, an alternating framework that jointly trains a rubric generator and a rubric-conditioned judge, with its RL stage using only pairwise preference data. Our method couples a probability-based scoring rule that reduces ties with phase-specific preference-based rewards and an alternating GRPO scheme that together train the pointwise evaluator. Extensive experiments show that RUBRIC-ARROW achieves competitive reward-modeling accuracy and yields consistent gains for downstream policy post-training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RUBRIC-ARROW, an alternating framework that jointly trains a rubric generator and a rubric-conditioned judge for pointwise reward modeling in non-verifiable domains. Training uses only pairwise preference data via an alternating GRPO scheme, a probability-based scoring rule to reduce ties, and phase-specific preference rewards. The central claims are that this yields competitive reward-modeling accuracy and consistent gains for downstream policy post-training.
Significance. If the empirical results hold, the work would offer a practical route to pointwise evaluators from pairwise data without frontier LLMs, addressing ties in rubric aggregation for subjective domains. The alternating optimization and probability-based scoring could strengthen reward signals for LLM post-training where absolute scoring is difficult.
major comments (1)
- [Abstract] The manuscript consists solely of the abstract and states that 'extensive experiments' demonstrate competitive accuracy and downstream gains, yet provides no datasets, baselines, metrics, ablation studies, or quantitative results. This absence is load-bearing for the central empirical claims and prevents any assessment of whether the alternating GRPO procedure or probability-based scoring delivers the reported benefits.
Simulated Author's Rebuttal
We thank the referee for their review. We address the major comment below point by point.
read point-by-point responses
-
Referee: [Abstract] The manuscript consists solely of the abstract and states that 'extensive experiments' demonstrate competitive accuracy and downstream gains, yet provides no datasets, baselines, metrics, ablation studies, or quantitative results. This absence is load-bearing for the central empirical claims and prevents any assessment of whether the alternating GRPO procedure or probability-based scoring delivers the reported benefits.
Authors: We agree that the manuscript text provided for review consists only of the abstract and contains no datasets, baselines, metrics, ablation studies, or quantitative results. This omission prevents evaluation of the central claims regarding the alternating GRPO scheme and probability-based scoring. The full arXiv version is intended to contain these elements, but to resolve the issue we will revise the submission to include all experimental details, specific datasets, baselines, metrics, ablations on the alternating optimization and scoring rule, and the reported quantitative results. revision: yes
Circularity Check
No significant circularity; derivation relies on external pairwise data
full rationale
The abstract and method description indicate training from external pairwise preference data using alternating GRPO, probability-based scoring, and phase-specific rewards to produce pointwise scores. No equations, self-citations, or fitted parameters are shown reducing the output to inputs by construction. The approach is presented as using independent data sources rather than self-referential definitions or predictions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ultraif: Advancing instruction following from the wild
Kaikai An, Li Sheng, Ganqu Cui, Shuzheng Si, Ning Ding, Yu Cheng, and Baobao Chang. Ultraif: Advancing instruction following from the wild. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18722–18737,
2025
-
[2]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, et al. Training a helpful and harmless assistant with reinforcement learning from human feedback.arXiv preprint arXiv:2204.05862,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Judgelrm: Large reasoning models as a judge.arXiv preprint arXiv:2504.00050, 2025a
13 Alternating Pointwise Rubric Reward Modeling NuoChen, ZhiyuanHu, QingyunZou, JiayingWu, QianWang, BryanHooi, andBingshengHe. Judgelrm: Large reasoning models as a judge.arXiv preprint arXiv:2504.00050, 2025a. Xiusi Chen, Gaotang Li, Ziqi Wang, Bowen Jin, Cheng Qian, Yu Wang, Hongru Wang, Yu Zhang, Denghui Zhang, Tong Zhang, et al. Rm-r1: Reward modelin...
-
[4]
Self-play with execution feedback: Improving instruction-following capabilities of large language models
Guanting Dong, Keming Lu, Chengpeng Li, Tingyu Xia, Bowen Yu, Chang Zhou, and Jingren Zhou. Self-play with execution feedback: Improving instruction-following capabilities of large language models. InInternational Conference on Learning Representations, volume 2025, pages 39286–39313,
2025
-
[5]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
How to evaluate reward models for rlhf
Evan Frick, Tianle Li, Connor Chen, Wei-Lin Chiang, Anastasios Angelopoulos, Jiantao Jiao, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. How to evaluate reward models for rlhf. InInternational Conference on Learning Representations, volume 2025, pages 18128–18163,
2025
-
[7]
Rubrics as Rewards: Reinforcement Learning Beyond Verifiable Domains
Anisha Gunjal, Anthony Wang, Elaine Lau, Vaskar Nath, Yunzhong He, Bing Liu, and Sean Hendryx. Rubrics as rewards: Reinforcement learning beyond verifiable domains.arXiv preprint arXiv:2507.17746,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
InNeurIPS 2025 Work- shop on Efficient Reasoning
Yun He, Wenzhe Li, Hejia Zhang, Songlin Li, Karishma Mandyam, Sopan Khosla, Yuanhao Xiong, Nanshu Wang, Xiaoliang Peng, Beibin Li, et al. Advancedif: Rubric-based benchmarking and reinforcement learning for advancing llm instruction following.arXiv preprint arXiv:2511.10507,
-
[9]
Ruipeng Jia, Yunyi Yang, Yuxin Wu, Yongbo Gai, Siyuan Tao, Mengyu Zhou, Jianhe Lin, Xiaoxi Jiang, and Guanjun Jiang. Open rubric system: Scaling reinforcement learning with pairwise adaptive rubric.arXiv preprint arXiv:2602.14069,
-
[10]
Rewardbench: Evaluating reward models for language modeling
Nathan Lambert, Valentina Pyatkin, Jacob Morrison, LJ Miranda, Bill Yuchen Lin, Khyathi Chandu, Nouha Dziri, Sachin Kumar, Tom Zick, Yejin Choi, et al. Rewardbench: Evaluating reward models for language modeling. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1755–1797,
2025
-
[11]
Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists
Yukyung Lee, Joonghoon Kim, Jaehee Kim, Hyowon Cho, Jaewook Kang, Pilsung Kang, and Najoung Kim. Checkeval: A reliable llm-as-a-judge framework for evaluating text generation using checklists. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 15782–15809,
2025
-
[12]
From generation to judgment: Oppor- tunities and challenges of llm-as-a-judge
Dawei Li, Bohan Jiang, Liangjie Huang, Alimohammad Beigi, Chengshuai Zhao, Zhen Tan, Amrita Bhattacharjee, Yuxuan Jiang, Canyu Chen, Tianhao Wu, et al. From generation to judgment: Oppor- tunities and challenges of llm-as-a-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 2757–2791,
2025
-
[13]
LLMs-as-Judges: A Comprehensive Survey on LLM-based Evaluation Methods
Haitao Li, Qian Dong, Junjie Chen, Huixue Su, Yujia Zhou, Qingyao Ai, Ziyi Ye, and Yiqun Liu. Llms-as- judges: a comprehensive survey on llm-based evaluation methods.arXiv preprint arXiv:2412.05579, 2024a. Sunzhu Li, Jiale Zhao, Miteto Wei, Huimin Ren, Yang Zhou, Jingwen Yang, Shunyu Liu, Kaike Zhang, and Wei Chen. Rubrichub: A comprehensive and highly di...
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gonzalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline.arXiv preprint arXiv:2406.11939, 2024b. Bill Yuchen Lin, Yuntian Deng, Khyathi Chandu, Abhilasha Ravichander, Valentina Pyatkin, Nouha Dziri, Ronan Le Bras, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Skywork-Reward: Bag of Tricks for Reward Modeling in LLMs
Chris Yuhao Liu, Liang Zeng, Jiacai Liu, Rui Yan, Jujie He, Chaojie Wang, Shuicheng Yan, Yang Liu, and Yahui Zhou. Skywork-reward: Bag of tricks for reward modeling in llms.arXiv preprint arXiv:2410.18451,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
InInternational Con- ference on Learning Representations, volume 2024, pages 29927–29962
Tianci Liu, Ran Xu, Tony Yu, Ilgee Hong, Carl Yang, Tuo Zhao, and Haoyu Wang. Openrubrics: Towards scalable synthetic rubric generation for reward modeling and llm alignment.arXiv preprint arXiv:2510.07743, 2025a. Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. I...
-
[17]
Rm-bench: Benchmarking re- ward models of language models with subtlety and style
15 Alternating Pointwise Rubric Reward Modeling Yantao Liu, Zijun Yao, Rui Min, Yixin Cao, Lei Hou, and Juanzi Li. Rm-bench: Benchmarking re- ward models of language models with subtlety and style. InInternational Conference on Learning Representations, volume 2025, pages 44323–44355, 2025b. DakotaMahan,DuyVanPhung,RafaelRafailov,ChaseBlagden,NathanLile,L...
-
[18]
RewardBench 2: Advancing Reward Model Evaluation
Saumya Malik, Valentina Pyatkin, Sander Land, Jacob Morrison, Noah A Smith, Hannaneh Ha- jishirzi, and Nathan Lambert. Rewardbench 2: Advancing reward model evaluation.arXiv preprint arXiv:2506.01937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Tianjun Pan, Xuan Lin, Wenyan Yang, Qianyu He, Shisong Chen, Licai Qi, Wanqing Xu, Hongwei Feng, Bo Xu, and Yanghua Xiao. Rubriceval: A rubric-level meta-evaluation benchmark for llm judges in instruction following.arXiv preprint arXiv:2603.25133,
-
[20]
Infobench: Evaluating instruction following ability in large language models
Yiwei Qin, Kaiqiang Song, Yebowen Hu, Wenlin Yao, Sangwoo Cho, Xiaoyang Wang, Xuansheng Wu, Fei Liu, Pengfei Liu, and Dong Yu. Infobench: Evaluating instruction following ability in large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 13025–13048,
2024
-
[21]
Online rubrics elicitation from pairwise comparisons.arXiv preprint arXiv:2510.07284,
MohammadHossein Rezaei, Robert Vacareanu, Zihao Wang, Clinton Wang, Bing Liu, Yunzhong He, and Afra Feyza Akyürek. Online rubrics elicitation from pairwise comparisons.arXiv preprint arXiv:2510.07284,
-
[22]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Interpretable preferences via multi-objective reward modeling and mixture-of-experts
Haoxiang Wang, Wei Xiong, Tengyang Xie, Han Zhao, and Tong Zhang. Interpretable preferences via multi-objective reward modeling and mixture-of-experts. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 10582–10592,
2024
-
[24]
Yifan Wang, Bolian Li, Junlin Wu, Zhaoxuan Tan, Zheli Liu, Ruqi Zhang, Ananth Grama, and Qingkai Zeng. Drift: Learning from abundant user dissatisfaction in real-world preference learning.arXiv preprint arXiv:2510.02341,
-
[25]
Lipeng Xie, Sen Huang, Zhuo Zhang, Anni Zou, Yunpeng Zhai, Dingchao Ren, Kezun Zhang, Haoyuan Hu, Boyin Liu, Haoran Chen, et al. Auto-rubric: Learning from implicit weights to explicit rubrics for reward modeling.arXiv preprint arXiv:2510.17314,
-
[26]
Ran Xu, Jingjing Chen, Jiayu Ye, Yu Wu, Jun Yan, Carl Yang, and Hongkun Yu. Incentivizing agentic reasoning in llm judges via tool-integrated reinforcement learning.arXiv preprint arXiv:2510.23038,
-
[27]
Ran Xu, Tianci Liu, Zihan Dong, Tony Yu, Ilgee Hong, Carl Yang, Linjun Zhang, Tao Zhao, and Haoyu Wang. Alternating reinforcement learning for rubric-based reward modeling in non-verifiable llm post-training.arXiv preprint arXiv:2602.01511,
-
[28]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Shuangshuang Ying, Yunwen Li, Xingwei Qu, Xin Li, Sheng Jin, Minghao Liu, Zhoufutu Wen, Xeron Du, Tianyu Zheng, Yichi Zhang, et al. Beyond correctness: Evaluating subjective writing preferences across cultures.arXiv preprint arXiv:2510.14616,
-
[31]
Self-generated critiques boost reward modeling for language models
Yue Yu, Zhengxing Chen, Aston Zhang, Liang Tan, Chenguang Zhu, Richard Yuanzhe Pang, Yundi Qian, Xuewei Wang, Suchin Gururangan, Chao Zhang, Melanie Kambadur, Dhruv Mahajan, and Rui Hou. Self-generated critiques boost reward modeling for language models. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Proceedings of the 2025 Conference of the Nations ...
2025
-
[32]
Association for Computational Linguistics. ISBN 979-8-89176-189-6. doi: 10.18653/v1/2025.naacl-long.573. URL https:// aclanthology.org/2025.naacl-long.573/. Junkai Zhang, Zihao Wang, Lin Gui, Swarnashree Mysore Sathyendra, Jaehwan Jeong, Victor Veitch, Wei Wang, Yunzhong He, Bing Liu, and Lifeng Jin. Chasing the tail: Effective rubric-based reward modelin...
-
[33]
Yang Zhou, Sunzhu Li, Shunyu Liu, Wenkai Fang, Kongcheng Zhang, Jiale Zhao, Jingwen Yang, Yihe Zhou, Jianwei Lv, Tongya Zheng, et al. Breaking the exploration bottleneck: Rubric-scaffolded reinforcement learning for general llm reasoning.arXiv preprint arXiv:2508.16949,
-
[34]
Experiment A.1
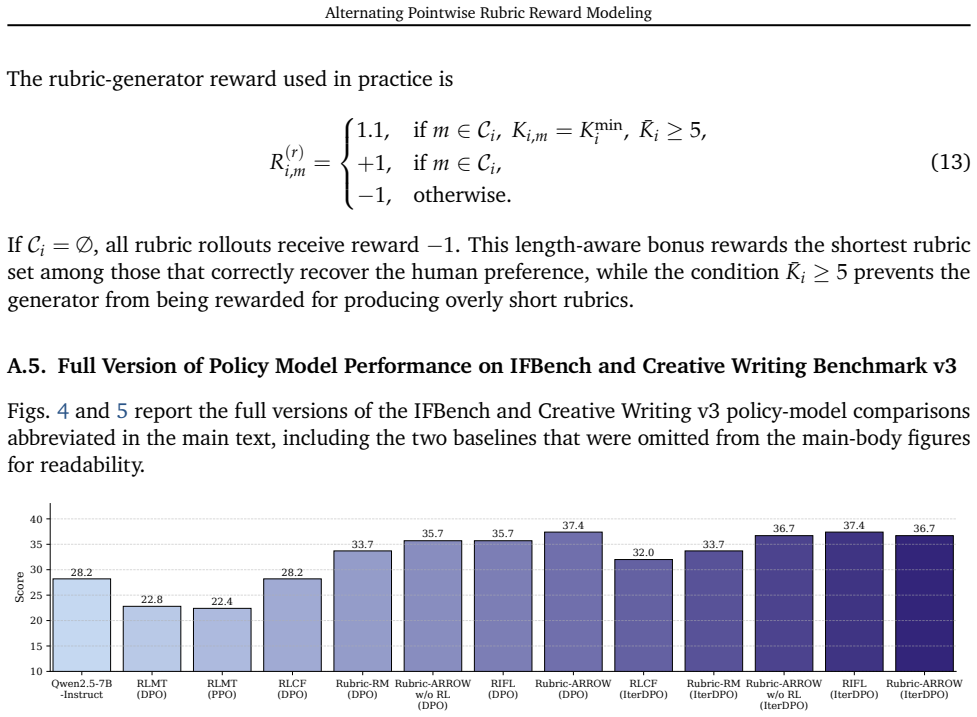
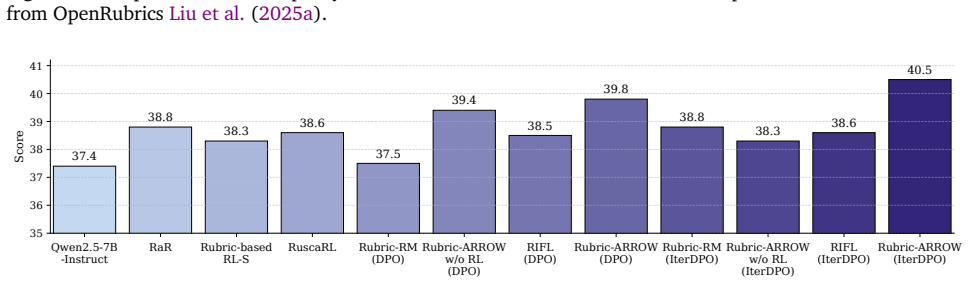
A. Experiment A.1. Implementation Details Tables 9 and 10 summarize the hyperparameters used forRubric-ARROWand policy model training, respectively. In rubric-based scoring, we assign a weight of 3 to eachHard Ruleand a weight of 1 to each Principlewhen computing the final score. We train the GRPO models using the ms-swift library2 (Zhao et al., 2025), an...
2025
-
[35]
For baseline methods, we use the sampling configurations specified in their official implementations or original papers. A.2. Evaluation Details Pairwise construction for FollowBench and InfoBench.For these two benchmarks, we convert the original single-response evaluation into a pairwise comparison setting: for each prompt, two responses are sampled from...
2026
-
[36]
We also compare against rubric-based reward modelsRubric-RM, Rubric-ARROWw/o RL, andRIFL
is a checklist-based reward signal that converts explicit constraints into a scalar reward. We also compare against rubric-based reward modelsRubric-RM, Rubric-ARROWw/o RL, andRIFL. 4https://www.anthropic.com/news/claude-3-5-sonnet 5https://openai.com/index/gpt-4-1/ 19 Alternating Pointwise Rubric Reward Modeling Table 10:Hyper-parameters used in policy m...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.