Rethinking Literature Search Evaluation: Deep Research Helps, and Human Citation Lists Are Not a Ground Truth
Pith reviewed 2026-06-29 07:49 UTC · model grok-4.3
The pith
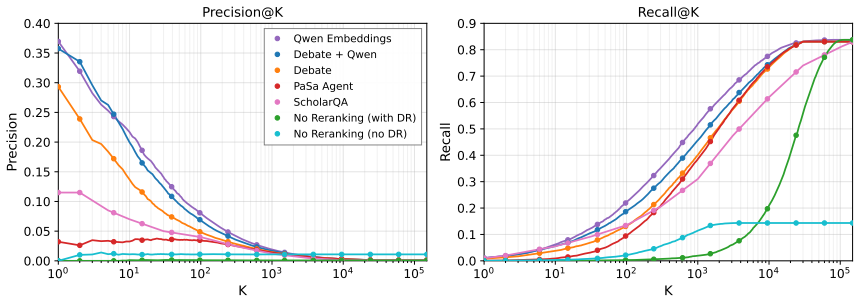
A bibliography-expansion pipeline called Deep Research lifts literature search recall from below 20% to above 80% on a 250-paper benchmark, while showing human citation lists contain only 51% moderately relevant entries by LLM judgment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The Deep Research pipeline processes the full query paper and expands the retrieved results breadth-first along their bibliographies, substantially outperforming vanilla API-only search by raising recall on RollingEval-Jun25 from below 20% to above 80%. A neutral LLM-as-a-judge determines that only 51% of human references are moderately relevant or higher, against 86-88% for the strongest AI-based re-rankers. On the OpenAlex co-authorship graph, humans are 2.5 times more likely than the best AI re-rankers to cite a direct collaborator. The findings indicate that recall, topical-relevance scoring, ranked-list diversity, and a co-authorship-distance diagnostic each measure complementary proper
What carries the argument
The Deep Research pipeline, which expands search results breadth-first along the bibliographies of retrieved papers, together with LLM-as-a-judge relevance scoring and co-authorship-graph analysis.
If this is right
- Deep Research achieves above 80% recall on the RollingEval-Jun25 benchmark where vanilla search stays below 20%.
- Only 51% of human citations reach moderate relevance or higher under LLM judgment.
- Top AI re-rankers reach 86-88% on the same relevance metric.
- Humans cite direct collaborators 2.5 times more often than the best AI re-rankers.
- Literature-search evaluation requires joint reporting of recall, topical relevance, diversity, and co-authorship distance.
Where Pith is reading between the lines
- Systems built on Deep Research may surface citations that are less shaped by personal collaboration networks.
- Evaluation benchmarks could add a co-authorship-distance diagnostic to detect social-proximity bias in ground-truth lists.
- Future work might test whether combining Deep Research with relevance re-ranking further improves both recall and judged quality.
- The observed gap between human and AI citation patterns suggests literature search tools could help reduce echo-chamber effects in scholarly reading.
Load-bearing premise
An LLM-as-a-judge can reliably and without bias decide whether a citation is relevant to a given query paper.
What would settle it
A controlled human-expert study that rates the exact same set of citations the LLM judged and reports whether the 51% versus 86-88% relevance gap persists under expert labels.
Figures


read the original abstract
We study large-scale literature search from two complementary angles: improving the retrieval pipeline, and stress-testing the human reference list as an evaluation target. First, we implement a Deep Research pipeline that processes the full query paper and expands the retrieved results breadth-first along their bibliographies, and show that it substantially outperforms vanilla API-only search, raising recall on RollingEval-Jun25 (a 250-paper literature-search benchmark) from below 20% to above 80%. Second, we use a neutral LLM-as-a-judge to determine if human references are sound ground truth for the task. We find significant limitations: only 51% of human citations are judged moderately relevant or higher, against 86--88% for the strongest AI-based re-rankers. We study this gap on the OpenAlex co-authorship graph, finding that humans are 2.5x more likely than the best AI re-rankers to cite a direct collaborator. Together, our results argue against single-axis literature-search evaluation: recall, topical-relevance scoring, ranked-list diversity, and a co-authorship-distance diagnostic each measure complementary properties of citation quality and should be reported jointly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates large-scale literature search via two angles: (1) a Deep Research pipeline that expands retrieved results breadth-first along bibliographies, raising recall on the RollingEval-Jun25 benchmark from below 20% to above 80%, and (2) an LLM-as-a-judge analysis showing that only 51% of human citations are moderately relevant or higher (vs. 86-88% for top AI re-rankers) and that humans cite direct collaborators 2.5x more often. The authors conclude that human reference lists are not reliable ground truth and that evaluation should jointly report recall, topical relevance, ranked-list diversity, and co-authorship distance.
Significance. If the empirical comparisons and diagnostic hold after validation, the work would meaningfully shift evaluation practices in literature search by providing concrete evidence against single-metric reliance on human citations and by demonstrating large gains from bibliography-expansion pipelines. The co-authorship-graph analysis supplies a falsifiable, external diagnostic that complements the relevance scores.
major comments (2)
- [Abstract (relevance evaluation)] The claim that human citation lists are not sound ground truth (and the headline 51% vs. 86-88% relevance gap) rests entirely on unvalidated LLM-as-a-judge ratings. No judge prompt, rubric, calibration set, or human-LLM agreement statistics are reported, leaving open the possibility that the gap is an artifact of systematic judge bias (e.g., against collaborator papers or non-AI writing styles). This is load-bearing for the second half of the paper.
- [Abstract (Deep Research pipeline)] The recall numbers (<20% o >80%) are less exposed to the judge issue because they appear to be measured against a fixed target set, but the manuscript must still clarify how the RollingEval-Jun25 targets were constructed and whether the breadth-first expansion introduces any circularity or leakage relative to those targets.
minor comments (1)
- [Abstract] Define the exact relevance rubric (e.g., what constitutes 'moderately relevant') and the co-authorship-distance threshold used for the 2.5x statistic so that the numbers can be reproduced.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The two major comments identify areas where additional transparency is needed. We address each below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: The claim that human citation lists are not sound ground truth (and the headline 51% vs. 86-88% relevance gap) rests entirely on unvalidated LLM-as-a-judge ratings. No judge prompt, rubric, calibration set, or human-LLM agreement statistics are reported, leaving open the possibility that the gap is an artifact of systematic judge bias.
Authors: We agree that full documentation of the LLM judge is required to support the relevance evaluation. In the revised manuscript we will add the complete judge prompt, the four-point relevance rubric, the size and composition of any calibration set, and inter-annotator agreement statistics between the LLM judge and human raters on a held-out sample. These additions will allow readers to evaluate potential systematic biases, including any differential treatment of collaborator papers. We maintain that the reported gap reflects genuine differences in topical relevance rather than judge artifact, but we accept that the current submission lacks the necessary methodological detail. revision: yes
-
Referee: The recall numbers (<20% to >80%) are less exposed to the judge issue because they appear to be measured against a fixed target set, but the manuscript must still clarify how the RollingEval-Jun25 targets were constructed and whether the breadth-first expansion introduces any circularity or leakage relative to those targets.
Authors: We will expand the methods section to describe the independent construction of the RollingEval-Jun25 target set (a fixed collection of 250 papers assembled prior to any retrieval experiments and based on expert-curated relevance judgments). We will also add an explicit analysis confirming that the breadth-first bibliography expansion does not create leakage: the expansion only traverses citations present in the retrieved papers, none of which were used to define the target set. This clarification will be accompanied by a statement that the target construction process is fully decoupled from the evaluated pipelines. revision: yes
Circularity Check
No significant circularity; empirical comparisons are self-contained
full rationale
The paper reports empirical results from a retrieval pipeline (Deep Research) evaluated on the external RollingEval-Jun25 benchmark and relevance judgments via LLM-as-a-judge against human lists and AI re-rankers, plus co-authorship analysis on the external OpenAlex graph. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The central claims rest on direct comparisons to fixed targets and external data rather than reducing to inputs by construction. This matches the default expectation of no circularity for benchmark-driven empirical work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Beyond search: Measuring LLM performance for scientific literature discovery. InIEEE TALE. Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recogni- tion. InProceedings of CVPR, pages 770–778. Yichen He, Guanhua Huang, Peiyuan Feng, Yuan Lin, Yuchen Zhang, Hang Li, and Weinan E. 2025. PaSa: An LLM agent for com...
-
[2]
OpenAlex: A fully-open index of scholarly works, authors, venues, institutions, and concepts
hdbscan: Hierarchical density based clustering. Journal of Open Source Software, 2(11):205. Jason Priem, Heather Piwowar, and Richard Orr. 2022. Openalex: A fully-open index of scholarly works, authors, venues, institutions, and concepts.arXiv preprint arXiv:2205.01833. Stephen Robertson and Hugo Zaragoza. 2009. The probabilistic relevance framework: BM25...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Ai2 ScholarQA: Organized literature synthesis with attribution. InProceedings of ACL, pages 513– 523, Vienna, Austria. Association for Computational Linguistics. Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need.Advances in NeurIPS, 30. Jiarong Zhang...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[4]
The CMA Evolution Strategy: A Tutorial
(Apache 2.0), and HDBSCAN (McInnes et al., 2017) (BSD-3). Reference data comes from OpenAlex (Priem et al., 2022) (CC0), Se- mantic Scholar (Kinney et al., 2023) (standard API terms of service), and arXiv preprints (per- author licenses selected at submission). All uses align with the research purposes the source arti- facts permit. The artifacts we will ...
work page internal anchor Pith review Pith/arXiv arXiv 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.