CoHyDE: Iterative Co-Training of LLM Rewriter & Dense Encoder for Tool Retrieval
Pith reviewed 2026-06-29 07:27 UTC · model grok-4.3
The pith
CoHyDE co-trains an LLM rewriter and dense encoder to improve tool retrieval on both clear and vague queries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
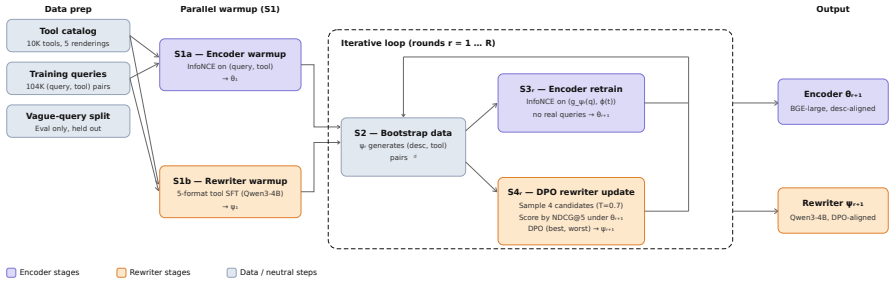
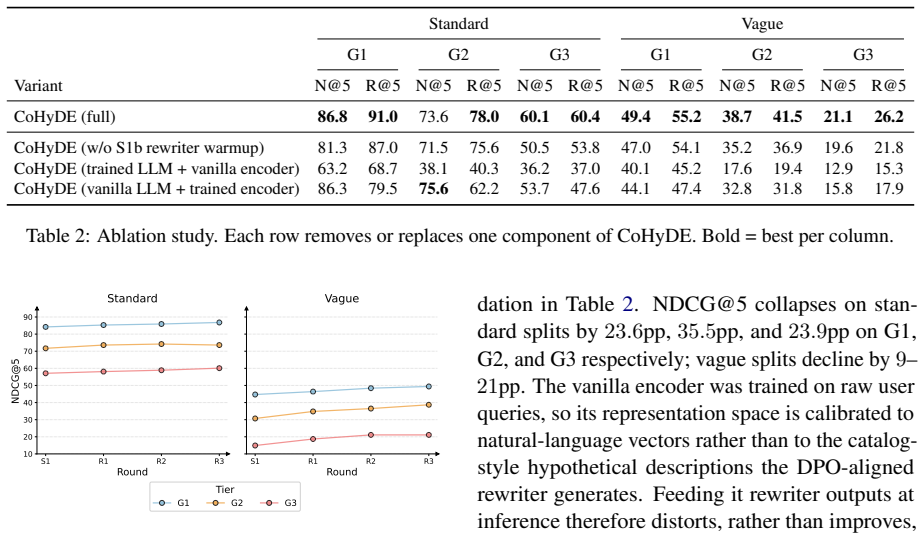
The paper establishes that an iterative co-training loop—retraining the dense encoder with InfoNCE on hypothetical descriptions produced by the LLM rewriter, then preference-aligning the rewriter with DPO using the encoder's retrieval scores—yields mutual gains that neither component achieves alone, delivering +2.5 pp NDCG@5 on standard queries and +6.3 pp on vague queries over a 10k-tool catalog subset, with ablations confirming that isolating either component loses up to 8 points on vague queries.
What carries the argument
CoHyDE, the iterative loop that alternates encoder retraining on rewriter-generated catalog-style descriptions and rewriter alignment via DPO on encoder scores.
If this is right
- The co-trained system outperforms both the fine-tuned encoder alone and the frozen HyDE rewriter alone on the same catalog.
- Gains are larger on held-out vague queries than on standard queries.
- Ablations show that breaking the loop drops performance by as much as 8 points on the hardest vague tier.
- The catalog warm-start is sufficient to begin the loop and reach useful performance after three rounds.
Where Pith is reading between the lines
- The alternating training pattern could extend to other retrieval settings where query language and document vocabulary are systematically mismatched.
- Better tool retrieval would let agents invoke functions more reliably without depending on few-shot examples or manual prompt engineering.
- Scaling the same loop to catalogs larger than 10k tools or testing alternative alignment losses would test whether the gains hold beyond the reported setting.
Load-bearing premise
The iterative loop between encoder and rewriter will produce stable mutual improvement rather than divergence or error reinforcement.
What would settle it
Running the three-round procedure on the ToolBench 10k-tool subset and observing that NDCG@5 on the vague query set fails to exceed the strongest single-component baseline would falsify the mutual-improvement claim.
Figures

read the original abstract
Tool retrieval over large API catalogs is a core bottleneck for LLM agents: user queries arrive in colloquial, often underspecified language, while the catalog uses technical API vocabulary that no fixed encoder can bridge on its own. The two dominant training approaches, contrastive encoder fine-tuning and HyDE-style query expansion with a frozen LLM, address this problem from opposite ends and fail in complementary directions: the fine-tuned encoder excels when the query's surface form already matches the catalog but collapses when it does not, while zero-shot HyDE is more robust to underspecified queries yet generates catalog-unaware hypothetical descriptions that degrade retrieval when queries are well-formed. We introduce CoHyDE, an iterative procedure that trains the dense encoder and the LLM rewriter as a single co-evolving system: the encoder is retrained with InfoNCE on catalog-style hypothetical descriptions produced by the rewriter, and the rewriter is preference-aligned via DPO against the encoder's retrieval scores, with both sides warm-started on the tool catalog before the loop begins. On a ~10k tool subset of the ToolBench catalog, three rounds of CoHyDE improve over the strongest single-component baseline by +2.5 pp NDCG@5 on standard queries and +6.3 pp on held-out vague queries, with gains as large as +8 pp on the hardest vague tier. Ablations confirm that co-training is the key ingredient: using either component in isolation fails to match CoHyDE on both well-formed and vague queries, with losses of up to -8 pp on vague queries.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CoHyDE, an iterative co-training procedure that alternates between retraining a dense encoder with InfoNCE on catalog-style hypothetical descriptions generated by an LLM rewriter and preference-aligning the rewriter via DPO using the encoder's retrieval scores, with both components warm-started on the tool catalog. On a ~10k tool subset of ToolBench, three rounds are reported to improve over the strongest single-component baseline by +2.5 pp NDCG@5 on standard queries and +6.3 pp on held-out vague queries (up to +8 pp on the hardest vague tier), with ablations indicating that co-training is required to match performance on both query types.
Significance. If the iterative loop produces stable mutual improvement, the method could meaningfully address the mismatch between colloquial user queries and technical API descriptions in LLM agent tool retrieval. The complementary weaknesses of pure encoder fine-tuning and zero-shot HyDE are clearly motivated, and the specific metric gains plus ablations on co-training vs. isolation are strengths that would support a practical contribution if the experimental support is complete.
major comments (1)
- [Results section (performance after three rounds)] The results report gains after exactly three rounds of co-training but supply no iteration-wise loss curves, rewriter output quality metrics, or ablation on round count, leaving the stability of the InfoNCE/DPO feedback loop (mutual improvement vs. divergence or collapse) unverified. This is load-bearing for the central claim that the co-evolving system produces reliable gains on both standard and vague queries.
minor comments (1)
- The construction and selection criteria for the held-out vague queries and the 'hardest vague tier' are referenced in the abstract but would benefit from an explicit description or example in the experimental setup for reproducibility.
Simulated Author's Rebuttal
We thank the referee for highlighting the importance of verifying the stability of the iterative co-training loop. This is a substantive point that directly affects the strength of our central claim, and we will address it with additional analysis in the revision.
read point-by-point responses
-
Referee: [Results section (performance after three rounds)] The results report gains after exactly three rounds of co-training but supply no iteration-wise loss curves, rewriter output quality metrics, or ablation on round count, leaving the stability of the InfoNCE/DPO feedback loop (mutual improvement vs. divergence or collapse) unverified. This is load-bearing for the central claim that the co-evolving system produces reliable gains on both standard and vague queries.
Authors: We agree that the current presentation leaves the dynamics of the feedback loop insufficiently characterized. The manuscript reports final performance after three rounds together with ablations isolating the co-training mechanism, but does not include per-iteration curves, rewriter-quality metrics, or a round-count ablation. In the revised version we will add: (i) iteration-wise NDCG@5 trajectories on both standard and vague query sets, (ii) auxiliary metrics on rewriter outputs (e.g., cosine similarity of generated descriptions to catalog entries and lexical overlap), and (iii) an explicit ablation varying the number of rounds (1–5). These additions will directly test whether the InfoNCE/DPO loop yields stable mutual improvement or exhibits divergence/collapse. revision: yes
Circularity Check
No significant circularity; empirical results on held-out data
full rationale
The paper describes an iterative co-training procedure (encoder retrained on rewriter outputs, rewriter aligned via DPO on encoder scores) and reports measured NDCG@5 gains on held-out standard and vague queries after three rounds. These improvements are external evaluations on a ~10k tool subset, not quantities defined in terms of the method's own fitted parameters or self-referential predictions. No equations, self-citations, or uniqueness claims appear in the provided text that would reduce the central claim to its inputs by construction. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- number of co-training rounds
axioms (2)
- domain assumption InfoNCE loss trains an effective dense encoder when positives are catalog-style hypothetical descriptions
- domain assumption Encoder retrieval scores provide reliable preference signals for DPO alignment of the rewriter
Reference graph
Works this paper leans on
-
[1]
InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4705–4726, Miami, Florida, USA
Re-invoke: Tool invocation rewriting for zero- shot tool retrieval. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 4705–4726, Miami, Florida, USA. Association for Computational Linguistics. Zhuyun Dai, Vincent Y Zhao, Ji Ma, Yi Luan, Jianmo Ni, Jing Lu, Anton Bakalov, Kelvin Guu, Keith Hall, and Ming-Wei Chang. 2023. Prompt...
2024
-
[2]
arXiv preprint arXiv:2212.08841 , year=
Precise zero-shot dense retrieval without rel- evance labels. InProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics (Volume 1: Long Papers), pages 1762–1777, Toronto, Canada. Association for Computational Lin- guistics. Sheryl Hsu, Omar Khattab, Chelsea Finn, and Archit Sharma. 2025. Grounding by trying: LLMs with re-...
-
[3]
Representation Learning with Contrastive Predictive Coding
Direct preference optimization: Your language model is secretly a reward model. InThirty-seventh Conference on Neural Information Processing Sys- tems. Christopher Sciavolino, Zexuan Zhong, Jinhyuk Lee, and Danqi Chen. 2021. Simple entity-centric ques- tions challenge dense retrievers. InProceedings of the 2021 Conference on Empirical Methods in Natu- ral...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
(2026) — (i) in- tent preservation, (ii) absence of leaked tool names / API verbs / domain keywords, (iii) plausibility as an end-user utterance
LLM self-check.Every paraphrase in Qvague is re-presented to claude-4.5-opus in a sepa- rate session, together with the original query and the gold tool set, and scored on the three binary criteria of Chen et al. (2026) — (i) in- tent preservation, (ii) absence of leaked tool names / API verbs / domain keywords, (iii) plausibility as an end-user utterance...
2026
-
[5]
All 50 passed all three criteria, giving a 6% rule-of-three upper bound on the true failure rate at 95% confidence
Human spot-check.50 paraphrases were sampled uniformly at random from the LLM- validated split and re-verified by human against the same three criteria. All 50 passed all three criteria, giving a 6% rule-of-three upper bound on the true failure rate at 95% confidence. The annotator was not blinded to the paraphraser identity; this is a trans- parency disc...
-
[6]
Reasoning-trace blocks delimited by <think>...</think>
-
[7]
Unclosed reasoning traces (a leading <think> with no terminator), in which case the entire output is rejected and replaced with the origi- nal query
-
[8]
Conversational preambles match- ing ^(Sure|Okay|Of course|Here is|Here’s)[^.]*\.\s+
-
[9]
LR” is the optimiser learning rate (AdamW, weight decay 10−2, bf16 throughout); for S4 “β
Trailing whitespace and repeated blank lines. The operator is implemented as a sequence of regular-expression substitutions and is applied iden- tically at SFT-target construction, DPO-candidate scoring, and inference time. C HyDE-Style Rewriter Prompt The HyDE-style prompt ρHyDE is used at the op- tional SFT stage (when included; see Appendix H), at S2 (...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.