Entropy-KL Divergence-based Token Masking: A Novel Approach for Selective Fine-tuning of Large Language Models
Pith reviewed 2026-06-29 07:59 UTC · model grok-4.3
The pith
Masking high-entropy and high-KL tokens during SFT lets models acquire task knowledge without drifting from their pre-trained distribution, improving math reasoning and later RL exploration.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
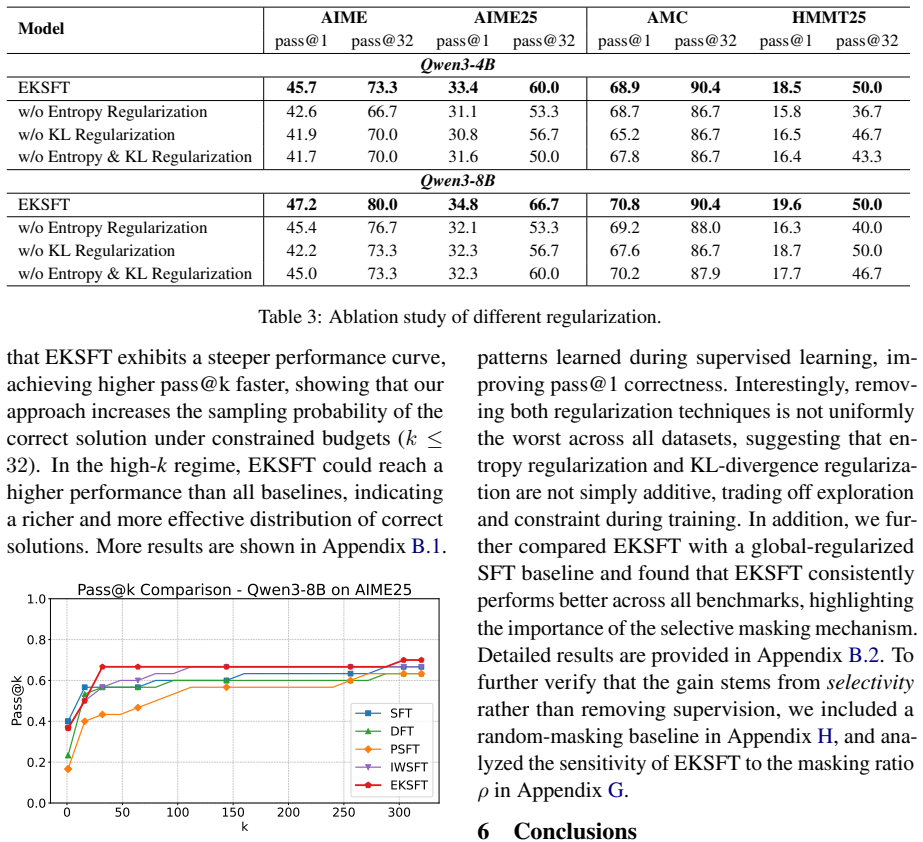
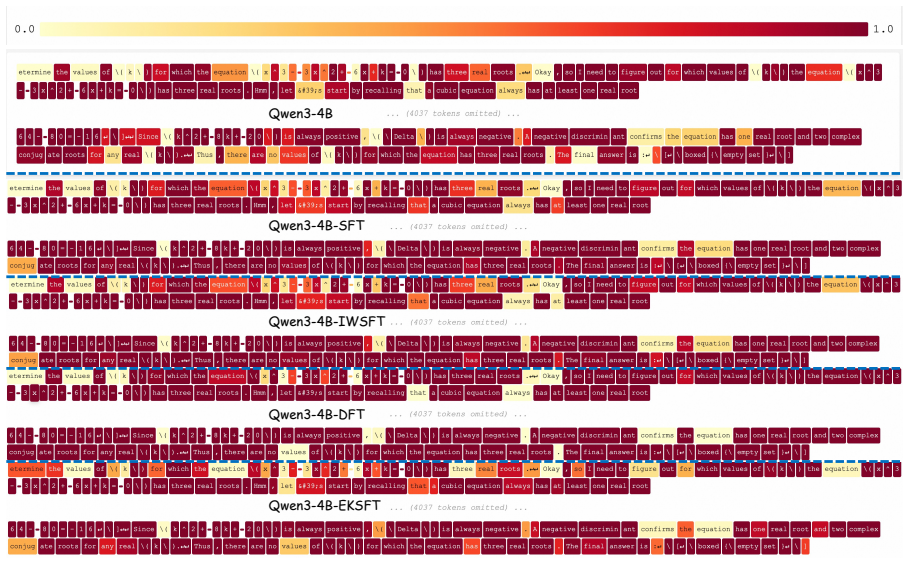
In low-data regimes, EKSFT selectively masks tokens that exhibit either high entropy or high KL divergence from a reference model during supervised fine-tuning; by excluding these high-uncertainty, distribution-shifting tokens from imitation, the method injects task-specific knowledge while preserving the integrity of the model's pre-trained distribution, yielding better performance on mathematical reasoning benchmarks and improved exploration when the resulting model is further fine-tuned with RL.
What carries the argument
EKSFT (Entropy-KL Selective Fine-Tuning), the mechanism that masks tokens with high entropy or high KL divergence from a reference model during the SFT imitation loss.
If this is right
- EKSFT produces higher accuracy than standard SFT on mathematical reasoning benchmarks.
- Starting RL from an EKSFT checkpoint yields better final performance than starting from a standard-SFT checkpoint.
- The method reduces unwanted distribution shift in low-data SFT regimes.
- SFT can be reframed as activating existing capabilities instead of memorizing limited samples.
Where Pith is reading between the lines
- The same masking logic could be tested on non-math domains such as code generation or scientific reasoning where distribution shift is also a concern.
- Dynamic, per-step recomputation of entropy and KL during training might further reduce the risk of discarding useful tokens.
- The approach may lower the minimum data volume required for an effective SFT cold-start before RL.
Load-bearing premise
That high-entropy and high-KL tokens are mainly responsible for harmful distribution shift and can be safely excluded without removing useful task-relevant learning signals.
What would settle it
Run standard SFT and EKSFT on the same low-data math reasoning set, then measure both final SFT accuracy and post-RL exploration metrics; if EKSFT shows no consistent gain or lower accuracy on the benchmarks, the central claim is falsified.
Figures



read the original abstract
Supervised fine-tuning (SFT) followed by reinforcement learning (RL) has become a standard post-training paradigm for large language models. This paradigm provides a cold-start for RL exploration, avoiding the inefficiency of pure RL where on-policy sampling yields insufficient positive samples. However, in practice, existing approaches often use a small amount of data for SFT initialization compared to the RL phase, which can cause the model to fit the limited samples and shift away from its pre-trained distribution. This distribution shift impedes the model's ability to effectively explore during subsequent RL training. To address this challenge, we propose that in low-data regimes, SFT should prioritize activating task-relevant capabilities rather than memorizing specific content. Along this line, we propose EKSFT (Entropy-KL Selective Fine-Tuning), which selectively masks tokens that exhibit either high entropy or high KL divergence from a reference model. By excluding these high-uncertainty, distribution-shifting tokens from imitation, EKSFT injects task-specific knowledge while preserving the integrity of the model's pre-trained distribution. Empirical evaluations on mathematical reasoning benchmarks demonstrate that EKSFT consistently outperforms standard SFT. Further RL fine-tuning from the EKSFT model yields consistently better post-RL performance, indicating improved exploration for the RL stage. Our codes and datasets are available at https://github.com/MINE-USTC/EKSFT.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EKSFT, a selective token-masking strategy for supervised fine-tuning (SFT) of LLMs in low-data regimes. Tokens exhibiting high entropy or high KL divergence from a reference model are excluded from the imitation loss, with the claim that this injects task-specific knowledge while avoiding distribution shift away from the pre-trained model. Empirical results on mathematical reasoning benchmarks are stated to show consistent gains over standard SFT, with further improvements observed after subsequent RL fine-tuning due to better exploration.
Significance. If the reported gains are shown to be robust under controlled ablations and statistical testing, the approach could supply a lightweight, interpretable heuristic for mitigating over-fitting during SFT initialization of RL pipelines. The open release of code and datasets is a constructive element that would facilitate independent verification.
major comments (2)
- [Abstract] Abstract: the statement that 'empirical evaluations demonstrate consistent outperformance' supplies no information on experimental controls, baseline selection, number of random seeds, statistical significance testing, or the procedure used to set the entropy/KL masking threshold; these omissions render the central performance claim unverifiable from the provided description.
- [Method] EKSFT description (method section): the claim that masking high-entropy or high-KL tokens is the mechanism that 'injects task-specific knowledge while preserving the integrity of the model's pre-trained distribution' is presented without a first-principles derivation or controlled ablation against alternatives (e.g., low-entropy masking, random masking, or entropy-only masking); this assumption is load-bearing for the proposed method yet remains untested.
minor comments (2)
- [Abstract] Abstract: the reference model used for the KL term is not identified; clarify whether it is the base pre-trained model or a separately trained model.
- [Abstract] The GitHub link is provided but the manuscript does not indicate which exact datasets, model sizes, or hyper-parameter settings correspond to the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and commit to revisions that strengthen the verifiability and empirical grounding of the claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that 'empirical evaluations demonstrate consistent outperformance' supplies no information on experimental controls, baseline selection, number of random seeds, statistical significance testing, or the procedure used to set the entropy/KL masking threshold; these omissions render the central performance claim unverifiable from the provided description.
Authors: We agree the abstract is too terse on these points. The full manuscript reports results over 3 random seeds with mean and standard deviation, compares against vanilla SFT plus other selective baselines, applies paired t-tests for significance, and selects the entropy/KL threshold via grid search on a held-out validation split. We will revise the abstract to include a concise clause summarizing the use of multiple seeds, statistical testing, and validation-based threshold selection. revision: yes
-
Referee: [Method] EKSFT description (method section): the claim that masking high-entropy or high-KL tokens is the mechanism that 'injects task-specific knowledge while preserving the integrity of the model's pre-trained distribution' is presented without a first-principles derivation or controlled ablation against alternatives (e.g., low-entropy masking, random masking, or entropy-only masking); this assumption is load-bearing for the proposed method yet remains untested.
Authors: The method is presented as a heuristic motivated by the intuition that high-entropy tokens reflect uncertainty and high-KL tokens indicate distribution shift. The manuscript already contains ablations versus random masking; we acknowledge the absence of a first-principles derivation and the need for explicit low-entropy and entropy-only controls. We will add these additional ablations together with expanded discussion of the design rationale in the revised version. revision: yes
Circularity Check
No circularity detected; method described at high level without equations or self-referential reductions
full rationale
The provided abstract and description introduce EKSFT as a selective masking approach motivated by distribution shift concerns during SFT, but contain no equations, derivation steps, fitted parameters presented as predictions, or load-bearing self-citations. The central claim that masking high-entropy or high-KL tokens preserves the pre-trained distribution while injecting task knowledge is stated as a proposal rather than derived from first principles or reduced to inputs by construction. No patterns matching self-definitional, fitted-input-called-prediction, or uniqueness-imported-from-authors are present. The paper is therefore self-contained as a descriptive method contribution without a derivation chain that could be circular.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Yuntao Bai, Andy Jones, Kamal Ndousse, Amanda Askell, Anna Chen, Nova DasSarma, Dawn Drain, Stanislav Fort, Deep Ganguli, Tom Henighan, Nicholas Joseph, Saurav Kadavath, Jackson Kernion, Tom Conerly, Sheer El Showk, Nelson Elhage, Zac Hatfield - Dodds, Danny Hernandez, Tristan Hume, and 12 others. 2022. https://doi.org/10.48550/ARXIV.2204.05862 Training a...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2204.05862 2022
-
[2]
Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, and Martin Vechev. 2025. https://matharena.ai/ Matharena: Evaluating llms on uncontaminated math competitions
2025
-
[3]
Bradley C. A. Brown, Jordan Juravsky, Ryan Ehrlich, Ronald Clark, Quoc V. Le, Christopher R \' e , and Azalia Mirhoseini. 2024. https://doi.org/10.48550/ARXIV.2407.21787 Large language monkeys: Scaling inference compute with repeated sampling . CoRR, abs/2407.21787
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21787 2024
-
[4]
Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Yuefeng Huang, Xiangcheng Liu, Wang Xinzhi, and Wu Liu. 2025 a . https://doi.org/10.18653/v1/2025.findings-emnlp.697 ACEB ench: A comprehensive evaluation of LLM tool usage . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 12970--12998, Suzhou,...
-
[5]
Hardy Chen, Haoqin Tu, Fali Wang, Hui Liu, Xianfeng Tang, Xinya Du, Yuyin Zhou, and Cihang Xie. 2025 b . https://openreview.net/forum?id=wZI5qkQeDF SFT or rl? an early investigation into training r1-like reasoning large vision-language models . Trans. Mach. Learn. Res., 2025
2025
-
[6]
Liang Chen, Xueting Han, Li Shen, Jing Bai, and Kam - Fai Wong. 2025 c . https://doi.org/10.48550/ARXIV.2509.06948 Beyond two-stage training: Cooperative SFT and RL for LLM reasoning . CoRR, abs/2509.06948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.06948 2025
- [7]
-
[8]
Daixuan Cheng, Shaohan Huang, Xuekai Zhu, Bo Dai, Wayne Xin Zhao, Zhenliang Zhang, and Furu Wei. 2025. https://doi.org/10.48550/ARXIV.2506.14758 Reasoning with exploration: An entropy perspective . CoRR, abs/2506.14758
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.14758 2025
-
[9]
Le, Sergey Levine, and Yi Ma
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V. Le, Sergey Levine, and Yi Ma. 2025. https://openreview.net/forum?id=dYur3yabMj SFT memorizes, RL generalizes: A comparative study of foundation model post-training . In Forty-second International Conference on Machine Learning, ICML 2025, Vancouver, BC, Canada, J...
2025
-
[10]
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. 2025. https://doi.org/10.48550/ARXIV.2505.22617 The entropy mechanism of reinforcement learning for reasoning language models . CoRR, abs/2505.22617
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.22617 2025
- [11]
-
[12]
DeepSeek - AI. 2024. https://doi.org/10.48550/ARXIV.2412.19437 Deepseek-v3 technical report . CoRR, abs/2412.19437
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.19437 2024
-
[13]
Yuqian Fu, Tinghong Chen, Jiajun Chai, Xihuai Wang, Songjun Tu, Guojun Yin, Wei Lin, Qichao Zhang, Yuanheng Zhu, and Dongbin Zhao. 2025. https://doi.org/10.48550/ARXIV.2506.19767 SRFT: A single-stage method with supervised and reinforcement fine-tuning for reasoning . CoRR, abs/2506.19767
-
[14]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, and 175 others. 2025. https://doi.org/10.1038/S41586-025-09422-Z Deepseek-r1 incentivizes reasoning in llms through reinforcement lear...
- [15]
-
[16]
Hugging Face . 2025. https://github.com/huggingface/open-r1 Open r1: A fully open reproduction of deepseek-r1
2025
-
[17]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V. Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, and 4 others. 2024. https://doi.org/10.48550/ARXIV.2411.15124 T \" u...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.15124 2024
-
[18]
Jungyup Lee, Jemin Kim, Sang Park, and SeungJae Lee. 2025. https://doi.org/10.48550/ARXIV.2508.10355 Making qwen3 think in korean with reinforcement learning . CoRR, abs/2508.10355
-
[19]
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, and 1 others. 2024. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions. Hugging Face repository, 13(9):9
2024
-
[20]
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi - Quan Luo, and Ruoyu Sun. 2025. https://openreview.net/forum?id=NQEe7B7bSw Preserving diversity in supervised fine-tuning of large language models . In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 . OpenReview.net
2025
-
[21]
Mingyang Liu, Gabriele Farina, and Asuman E. Ozdaglar. 2025 a . https://doi.org/10.48550/ARXIV.2505.16984 UFT: unifying supervised and reinforcement fine-tuning . CoRR, abs/2505.16984
-
[22]
Zihan Liu, Zhuolin Yang, Yang Chen, Chankyu Lee, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. 2025 b . https://doi.org/10.48550/ARXIV.2506.13284 Acereason-nemotron 1.1: Advancing math and code reasoning through SFT and RL synergy . CoRR, abs/2506.13284
-
[23]
Ilya Loshchilov and Frank Hutter. 2017. https://arxiv.org/abs/1711.05101 Fixing weight decay regularization in adam . CoRR, abs/1711.05101
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
OpenAI. 2023. https://doi.org/10.48550/ARXIV.2303.08774 GPT-4 technical report . CoRR, abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[25]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F. Christiano, Jan Leike, and Ryan Lowe. 2022. http://papers.nips.cc/paper\_files/paper/2022/hash/b1efd...
2022
- [26]
-
[27]
Gonzalez
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E. Gonzalez. 2025. https://openreview.net/forum?id=2GmDdhBdDk The berkeley function calling leaderboard ( BFCL ): From tool use to agentic evaluation of large language models . In Forty-second International Conference on Machine Learning
2025
-
[28]
Jake Poznanski, Luca Soldaini, and Kyle Lo. 2025. https://doi.org/10.48550/ARXIV.2510.19817 olmocr 2: Unit test rewards for document OCR . CoRR, abs/2510.19817
- [29]
-
[30]
Reuven Y Rubinstein and Dirk P Kroese. 2016. Simulation and the Monte Carlo method. John Wiley & Sons
2016
-
[31]
Jordan, and Philipp Moritz
John Schulman, Sergey Levine, Pieter Abbeel, Michael I. Jordan, and Philipp Moritz. 2015. http://proceedings.mlr.press/v37/schulman15.html Trust region policy optimization . In Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015 , volume 37 of JMLR Workshop and Conference Proceedings , pages 1889-...
2015
-
[32]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. https://doi.org/10.1145/3689031.3696075 Hybridflow: A flexible and efficient RLHF framework . In Proceedings of the Twentieth European Conference on Computer Systems, EuroSys 2025, Rotterdam, The Netherlands, 30 March 2025 - 3 April 202...
-
[33]
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming - Hsuan Yang, and Xu Yang. 2025. https://doi.org/10.48550/ARXIV.2508.05629 On the generalization of SFT: A reinforcement learning perspective with reward rectification . CoRR, abs/2508.05629
-
[34]
Lechao Xiao. 2024. https://doi.org/10.48550/ARXIV.2409.15156 Rethinking conventional wisdom in machine learning: From generalization to scaling . CoRR, abs/2409.15156
-
[35]
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. 2024. https://doi.org/10.48550/ARXIV.2410.23123 On memorization of large language models in logical reasoning . CoRR, abs/2410.23123
-
[36]
Derong Xu, Xinhang Li, Ziheng Zhang, Zhenxi Lin, Zhihong Zhu, Zhi Zheng, Xian Wu, Xiangyu Zhao, Tong Xu, and Enhong Chen. 2025 a . Harnessing large language models for knowledge graph question answering via adaptive multi-aspect retrieval-augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 25570--25578
2025
-
[37]
Derong Xu, Yi Wen, Pengyue Jia, Yingyi Zhang, Wenlin Zhang, Yichao Wang, Huifeng Guo, Ruiming Tang, Xiangyu Zhao, Enhong Chen, and Tong Xu. 2026. https://openreview.net/forum?id=i2yIvZARnG From single to multi-granularity: Toward long-term memory association and selection of conversational agents . In The Fourteenth International Conference on Learning Re...
2026
-
[38]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, and 19 others. 2025 b . https://doi.org/10.48550/ARXIV.2509.17765 Qwen3-omni technical report . CoRR, abs/2509.17765
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.17765 2025
-
[39]
Jianhao Yan, Yafu Li, Zican Hu, Zhi Wang, Ganqu Cui, Xiaoye Qu, Yu Cheng, and Yue Zhang. 2025. https://doi.org/10.48550/ARXIV.2504.14945 Learning to reason under off-policy guidance . CoRR, abs/2504.14945
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.14945 2025
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, and 40 others. 2025. https://doi.org/10.48550/ARXIV.2505.09388 Qwen3 technical report . CoRR, abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[41]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, and 16 others. 2025. https://doi.org/10.48550/ARXIV.2503.14476 DAPO: an open-source LLM reinforcement learning system at scale . ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2503.14476 2025
-
[42]
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. 2025. https://doi.org/10.48550/ARXIV.2504.13837 Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? CoRR, abs/2504.13837
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13837 2025
-
[43]
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xinwei Long, and 20 others. 2025 a . https://doi.org/10.48550/ARXIV.2509.08827 A survey of reinforcement learning for large reasoning models . CoR...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2509.08827 2025
-
[44]
Shaokun Zhang, Yi Dong, Jieyu Zhang, Jan Kautz, Bryan Catanzaro, Andrew Tao, Qingyun Wu, Zhiding Yu, and Guilin Liu. 2025 b . https://doi.org/10.48550/ARXIV.2505.00024 Nemotron-research-tool-n1: Exploring tool-using language models with reinforced reasoning . CoRR, abs/2505.00024
-
[45]
Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, and Jingren Zhou. 2025 c . https://doi.org/10.48550/ARXIV.2508.11408 On-policy RL meets off-policy experts: Harmonizing supervised fine-tuning and reinforcement learning via dynamic weighting . CoRR, abs/2508.11408
-
[46]
Xiaoyun Zhang, Xiaojian Yuan, Di Huang, Wang You, Chen Hu, Jingqing Ruan, Kejiang Chen, and Xing Hu. 2025 d . https://doi.org/10.48550/ARXIV.2510.10959 Rediscovering entropy regularization: Adaptive coefficient unlocks its potential for LLM reinforcement learning . CoRR, abs/2510.10959
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.10959 2025
-
[47]
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. 2025 e . https://doi.org/10.48550/ARXIV.2506.05176 Qwen3 embedding: Advancing text embedding and reranking through foundation models . CoRR, abs/2506.05176
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.05176 2025
-
[48]
Haiquan Zhao, Chenhan Yuan, Fei Huang, Xiaomeng Hu, Yichang Zhang, An Yang, Bowen Yu, Dayiheng Liu, Jingren Zhou, Junyang Lin, Baosong Yang, Chen Cheng, Jialong Tang, Jiandong Jiang, Jianwei Zhang, Jijie Xu, Ming Yan, Minmin Sun, Pei Zhang, and 24 others. 2025. https://doi.org/10.48550/ARXIV.2510.14276 Qwen3guard technical report . CoRR, abs/2510.14276
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2510.14276 2025
-
[49]
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. 2024. http://arxiv.org/abs/2403.13372 Llamafactory: Unified efficient fine-tuning of 100+ language models . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Bangkok, Thailand. Assoc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Weihai Zhi, Jiayan Guo, and Shangyang Li. 2025. https://doi.org/10.48550/ARXIV.2508.20549 Medgr\( ^ 2 \): Breaking the data barrier for medical reasoning via generative reward learning . CoRR, abs/2508.20549
-
[51]
He Zhu, Junyou Su, Peng Lai, Ren Ma, Wenjia Zhang, Linyi Yang, and Guanhua Chen. 2025 a . https://doi.org/10.48550/ARXIV.2509.23753 Anchored supervised fine-tuning . CoRR, abs/2509.23753
-
[52]
Wenhong Zhu, Ruobing Xie, Rui Wang, Xingwu Sun, Di Wang, and Pengfei Liu. 2025 b . https://doi.org/10.48550/ARXIV.2508.17784 Proximal supervised fine-tuning . CoRR, abs/2508.17784
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.17784 2025
-
[53]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[54]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.