Proximal Supervised Fine-Tuning
Pith reviewed 2026-05-18 20:38 UTC · model grok-4.3
The pith
Viewing supervised fine-tuning through a policy gradient lens yields a proximal objective that curbs policy drift and enhances generalization.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
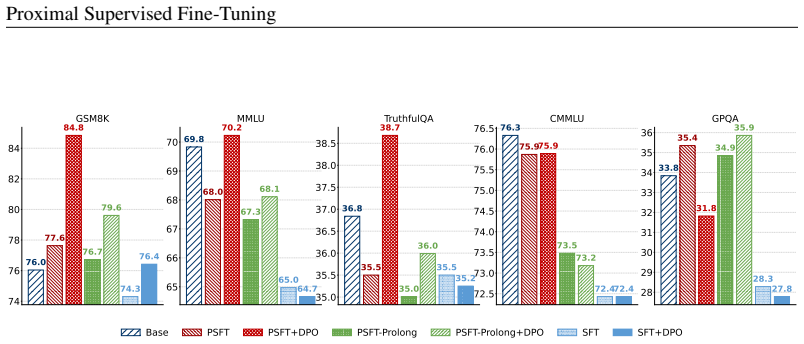
By viewing SFT as a special case of policy gradient methods with constant positive advantages, PSFT stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains demonstrate that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
What carries the argument
The proximal term added to the SFT loss, derived from trust-region policy optimization to constrain the divergence between the fine-tuned model and the base model.
If this is right
- PSFT achieves comparable performance to standard SFT on in-domain tasks.
- PSFT delivers better performance than standard SFT on out-of-domain tasks.
- PSFT supports longer training runs without entropy collapse or instability.
- PSFT results in models that serve as better starting points for later post-training optimizations.
Where Pith is reading between the lines
- Adopting this constrained fine-tuning could simplify the process of updating models without constant monitoring for capability loss.
- Extending the same idea to other training objectives might improve stability in multi-stage model development pipelines.
- Testing the method on a wider range of foundation model sizes and task types would reveal how broadly the benefit applies.
Load-bearing premise
The trust-region constraint from reinforcement learning applies directly to supervised fine-tuning without creating unexpected issues or needing adjustments for each specific task.
What would settle it
A direct comparison experiment on the mathematical reasoning tasks where PSFT-tuned models show lower accuracy on out-of-domain questions than those tuned with standard SFT would disprove the generalization improvement.
Figures








read the original abstract
Supervised fine-tuning (SFT) of foundation models often leads to poor generalization, where prior capabilities deteriorate after tuning on new tasks or domains. Inspired by trust-region policy optimization (TRPO) and proximal policy optimization (PPO) in reinforcement learning (RL), we propose Proximal SFT (PSFT). This fine-tuning objective incorporates the benefits of trust-region, effectively constraining policy drift during SFT while maintaining competitive tuning. By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages. Experiments across mathematical and human-value domains show that PSFT matches SFT in-domain, outperforms it in out-of-domain generalization, remains stable under prolonged training without causing entropy collapse, and provides a stronger foundation for the subsequent optimization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Proximal Supervised Fine-Tuning (PSFT) by re-expressing standard SFT as a policy-gradient update with constant positive advantages (implicit reward of 1 on target tokens), then augmenting the objective with a trust-region constraint (KL penalty or proximal term) drawn from TRPO/PPO. The central claim is that this stabilizes optimization, prevents entropy collapse and overfitting, matches vanilla SFT in-domain, improves out-of-domain generalization, and yields a stronger base for subsequent post-training stages.
Significance. If the central claim holds, the work offers a lightweight, reward-model-free modification to SFT that imports stability mechanisms from RL policy optimization. This could be practically useful for reducing capability degradation during domain adaptation and for producing better initialization points before RLHF-style stages. The approach is relevant to current LLM training pipelines in reasoning and alignment domains.
major comments (2)
- [§3] §3 (Derivation of PSFT): the re-expression of SFT as policy gradient with constant advantages is definitional and supplies no independent benchmark; the subsequent addition of the trust-region term therefore inherits this modeling choice. The manuscript does not specify whether the proximal/KL term is applied before or after the gradient step or how its coefficient is selected, leaving the transfer from sparse RL advantages to dense per-token SFT objectives unverified.
- [§4] §4 (Experiments): the reported stability and OOD gains are stated without quantitative metrics, error bars, number of random seeds, or ablation on the trust-region radius (a free parameter). No sweep of the proximal coefficient is shown, which is required to test whether the same constraint strength that works for RL prevents under- or over-constraining in the dense SFT setting.
minor comments (2)
- [Notation] Notation throughout: the exact PSFT loss (including how the constant advantage of 1 is inserted and whether the proximal term is a KL divergence or a clipped surrogate) should be written explicitly as an equation for reproducibility.
- [Abstract] Abstract: the domains are described only as 'mathematical and human-value'; adding the specific models, datasets, and evaluation metrics would clarify the scope of the claimed generalization improvements.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comments help clarify how to better present the derivation and strengthen the experimental reporting. We address each major comment below and will incorporate the requested clarifications and additional results in the revised manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Derivation of PSFT): the re-expression of SFT as policy gradient with constant advantages is definitional and supplies no independent benchmark; the subsequent addition of the trust-region term therefore inherits this modeling choice. The manuscript does not specify whether the proximal/KL term is applied before or after the gradient step or how its coefficient is selected, leaving the transfer from sparse RL advantages to dense per-token SFT objectives unverified.
Authors: We agree that framing SFT as a policy-gradient update with constant positive advantages is primarily a definitional step that enables the direct transfer of trust-region machinery. This modeling choice is intentional because it makes the addition of the KL or proximal penalty a natural extension rather than an ad-hoc modification. In the revised version we will explicitly state that the trust-region term is added to the per-token loss and optimized jointly within the same gradient step (i.e., the proximal/KL penalty is part of the objective being differentiated, not applied after the update). We will also document the coefficient-selection procedure used in our experiments, including the range explored and the final values chosen to avoid both under-constraint (entropy collapse) and over-constraint (under-fitting) in the dense per-token regime. A short discussion of the differences between sparse RL advantages and dense SFT token-level objectives will be added to the derivation section. revision: yes
-
Referee: [§4] §4 (Experiments): the reported stability and OOD gains are stated without quantitative metrics, error bars, number of random seeds, or ablation on the trust-region radius (a free parameter). No sweep of the proximal coefficient is shown, which is required to test whether the same constraint strength that works for RL prevents under- or over-constraining in the dense SFT setting.
Authors: We acknowledge that the current experimental section lacks several standard reporting elements. In the revision we will add (i) error bars computed over three independent random seeds, (ii) explicit quantitative metrics for both in-domain and out-of-domain performance, (iii) an ablation table varying the trust-region radius (or equivalent KL coefficient), and (iv) a sweep of the proximal coefficient across a range that includes values typical in RL as well as values tuned specifically for the dense SFT objective. These additions will directly address whether the constraint strength that stabilizes RL also prevents entropy collapse or under-fitting when applied to per-token SFT losses. revision: yes
Circularity Check
SFT re-expressed as constant-advantage policy gradient by definition; proximal constraint then inherits the modeling choice without independent benchmark.
specific steps
-
self definitional
[Abstract / derivation section]
"By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization and leads to generalization, while leaving room for further optimization in subsequent post-training stages."
The paper defines SFT as equivalent to a policy-gradient step with fixed positive advantages (implicit reward=1 on target tokens). This equivalence is introduced by construction; the subsequent addition of a trust-region / proximal penalty is then applied to the re-expressed objective, so the claimed stabilization property follows directly from the definitional modeling choice rather than from an independent derivation or external constraint.
full rationale
The paper's derivation chain begins with a definitional re-expression of SFT as a policy-gradient update using constant positive advantages (implicit reward = 1 on target tokens). The PSFT objective is obtained by adding a KL/proximal penalty to this re-expressed form. Because the constant-advantage premise is introduced by construction rather than derived from external data or first principles, the trust-region transfer to SFT reduces to the initial modeling decision. This produces partial circularity in the central claim while leaving the empirical results as a separate question.
Axiom & Free-Parameter Ledger
free parameters (1)
- trust_region_radius
axioms (1)
- domain assumption SFT is exactly equivalent to policy gradient with constant positive advantages
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By viewing SFT as a special case of policy gradient methods with constant positive advantages, we derive PSFT that stabilizes optimization... LPSFT(θ) = E[min(rt(θ), clip(rt(θ),1−ε,1+ε))]
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The clipping mechanism effectively defines a soft trust region
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Rotation-Preserving Supervised Fine-Tuning
RPSFT improves the in-domain versus out-of-domain performance trade-off during LLM supervised fine-tuning by penalizing rotations in pretrained singular subspaces as a proxy for loss-sensitive directions.
Reference graph
Works this paper leans on
-
[1]
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Tianzhe Chu, Yuexiang Zhai, Jihan Yang, Shengbang Tong, Saining Xie, Dale Schuurmans, Quoc V Le, Sergey Levine, and Yi Ma. Sft memorizes, rl generalizes: A comparative study of foundation model post-training. arXiv preprint arXiv:2501.17161,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 ,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
11 Proximal Supervised Fine-Tuning Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models. arXiv preprint arXiv:2505.22617,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines. arXiv preprint arXiv:2502.14739,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Bal´azs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled al- pacaeval: A simple way to debias automatic evaluators. arXiv preprint arXiv:2404.04475,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Cognitive Behaviors that Enable Self-Improving Reasoners, or, Four Habits of Highly Effective STaRs
URL https: //huggingface.co/blog/open-r1. Kanishk Gandhi, Ayush Chakravarthy, Anikait Singh, Nathan Lile, and Noah D Goodman. Cogni- tive behaviors that enable self-improving reasoners, or, four habits of highly effective stars.arXiv preprint arXiv:2503.01307,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
URL https://zenodo.org/records/12608602. Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reason- ing models. arXiv preprint arXiv:2506.04178,
-
[9]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Chaoqun He, Renjie Luo, Yuzhuo Bai, Shengding Hu, Zhen Leng Thai, Junhao Shen, Jinyi Hu, Xu Han, Yujie Huang, Yuxiang Zhang, et al. Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems. arXiv preprint arXiv:2402.14008,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300,
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[12]
Measuring Mathematical Problem Solving With the MATH Dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the math dataset. arXiv preprint arXiv:2103.03874,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Does Math Reasoning Improve General LLM Capabilities? Understanding Transferability of LLM Reasoning
Maggie Huan, Yuetai Li, Tuney Zheng, Xiaoyu Xu, Seungone Kim, Minxin Du, Radha Pooven- dran, Graham Neubig, and Xiang Yue. Does math reasoning improve general llm capabilities? understanding transferability of llm reasoning. arXiv preprint arXiv:2507.00432,
work page internal anchor Pith review arXiv
-
[14]
From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline
Tianle Li, Wei-Lin Chiang, Evan Frick, Lisa Dunlap, Tianhao Wu, Banghua Zhu, Joseph E Gon- zalez, and Ion Stoica. From crowdsourced data to high-quality benchmarks: Arena-hard and benchbuilder pipeline. arXiv preprint arXiv:2406.11939, 2024a. 12 Proximal Supervised Fine-Tuning Yang Li, Youssef Emad, Karthik Padthe, Jack Lanchantin, Weizhe Yuan, Thao Nguye...
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Preserving diversity in supervised fine-tuning of large language models
Ziniu Li, Congliang Chen, Tian Xu, Zeyu Qin, Jiancong Xiao, Zhi-Quan Luo, and Ruoyu Sun. Preserving diversity in supervised fine-tuning of large language models. arXiv preprint arXiv:2408.16673, 2024b. Stephanie Lin, Jacob Hilton, and Owain Evans. Truthfulqa: Measuring how models mimic human falsehoods. arXiv preprint arXiv:2109.07958,
-
[16]
Niklas Muennighoff, Zitong Yang, Weijia Shi, Xiang Lisa Li, Li Fei-Fei, Hannaneh Hajishirzi, Luke Zettlemoyer, Percy Liang, Emmanuel Cand `es, and Tatsunori Hashimoto. s1: Simple test-time scaling. arXiv preprint arXiv:2501.19393,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Chongli Qin and Jost Tobias Springenberg
URL https://openai.com/index/ learning-to-reason-with-llms/ . Chongli Qin and Jost Tobias Springenberg. Supervised fine tuning on curated data is reinforcement learning (and can be improved). arXiv preprint arXiv:2507.12856,
-
[18]
Reasoning to learn from latent thoughts
Yangjun Ruan, Neil Band, Chris J Maddison, and Tatsunori Hashimoto. Reasoning to learn from latent thoughts. arXiv preprint arXiv:2503.18866,
-
[19]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemati- cal reasoning in open language models. arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
HybridFlow: A Flexible and Efficient RLHF Framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. arXiv preprint arXiv: 2409.19256,
work page internal anchor Pith review Pith/arXiv arXiv
-
[22]
Association for Computational Linguistics. doi: 10.18653/v1/P19-1092. URL https://www.aclweb.org/anthology/P19-1092. Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi- task language understanding benchmark. Advances in Neura...
-
[23]
On the generalization of sft: A reinforcement learning perspective with reward rectification
Yongliang Wu, Yizhou Zhou, Zhou Ziheng, Yingzhe Peng, Xinyu Ye, Xinting Hu, Wenbo Zhu, Lu Qi, Ming-Hsuan Yang, and Xu Yang. On the generalization of sft: A reinforcement learning perspective with reward rectification. arXiv preprint arXiv:2508.05629,
-
[24]
Rethinking conventional wisdom in machine learning: From generalization to scaling
13 Proximal Supervised Fine-Tuning Lechao Xiao. Rethinking conventional wisdom in machine learning: From generalization to scaling. arXiv preprint arXiv:2409.15156,
-
[25]
Y.; Li, B.; Ghazi, B.; and Kumar, R
Chulin Xie, Yangsibo Huang, Chiyuan Zhang, Da Yu, Xinyun Chen, Bill Yuchen Lin, Bo Li, Badih Ghazi, and Ravi Kumar. On memorization of large language models in logical reasoning. arXiv preprint arXiv:2410.23123,
-
[26]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
LIMO: Less is More for Reasoning
Yixin Ye, Zhen Huang, Yang Xiao, Ethan Chern, Shijie Xia, and Pengfei Liu. Limo: Less is more for reasoning. arXiv preprint arXiv:2502.03387,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
LlamaFactory: Unified Efficient Fine-Tuning of 100+ Language Models
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems , 36, 2024a. Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, Zhangchi Feng, and Yongqiang Ma. Ll...
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Instruction-Following Evaluation for Large Language Models
URL https: //arxiv.org/abs/2311.07911. Ruochen Zhou, Minrui Xu, Shiqi Chen, Junteng Liu, Yunqi Li, Xinxin Lin, Zhengyu Chen, and Junxian He. Does learning mathematical problem-solving generalize to broader reasoning? arXiv preprint arXiv:2507.04391,
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
The loss is aggregated using token-mean in verl
A A PPENDIX A.1 E XPERIMENTAL DETAILS We perform SFT, PSFT, and RL training using the verl framework (Sheng et al., 2024), and employ LLama-Factory (Zheng et al., 2024b) for DPO training. The loss is aggregated using token-mean in verl. For SFT and PSFT, we use a weight decay of 0.1. All experiments are conducted with full fine-tuning. A.1.1 M ATH REASONI...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.