Rethinking Stepwise Model Routing: A Cost-Efficient Table Reasoning Perspective
Pith reviewed 2026-06-29 07:45 UTC · model grok-4.3
The pith
EcoTab routes table reasoning steps by separately estimating uncertainties of table tokens and text tokens to decide when to use smaller models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
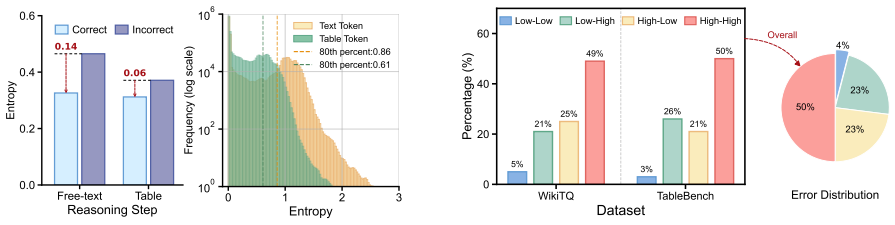
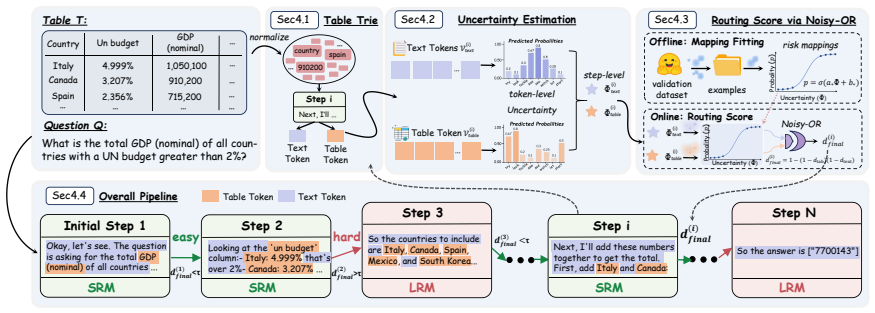
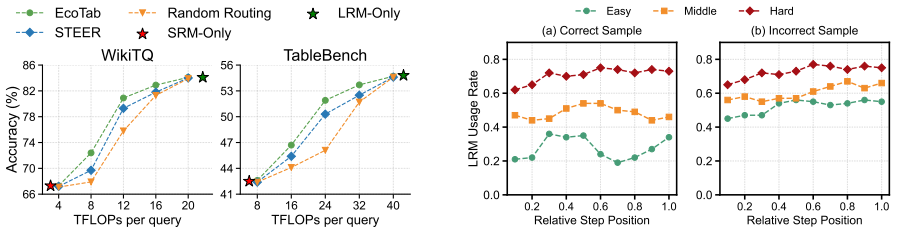
In table reasoning traces, table tokens and text tokens exhibit distinct uncertainty distributions, and the uncertainty of each type correlates with the risk that the small model will produce an error in the subsequent reasoning step. Existing stepwise routing does not model the two types separately and therefore yields suboptimal routing decisions. EcoTab corrects this by estimating the uncertainties of table tokens and text tokens independently, mapping each estimate to a next-step failure risk for the small model, and using the combined risks to choose the model for the current step.
What carries the argument
EcoTab, a table-aware stepwise routing framework that separately estimates uncertainties of table tokens and text tokens, maps each to next-step failure risk for the small model, and combines the two risks to decide routing.
If this is right
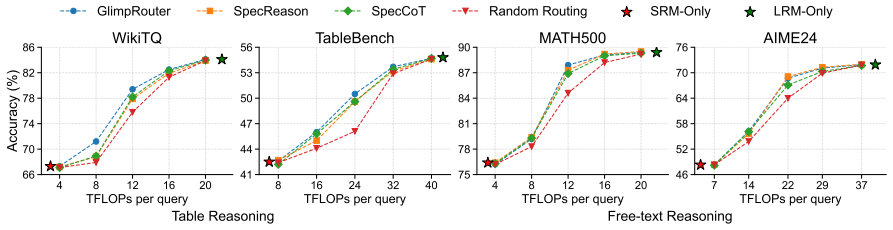
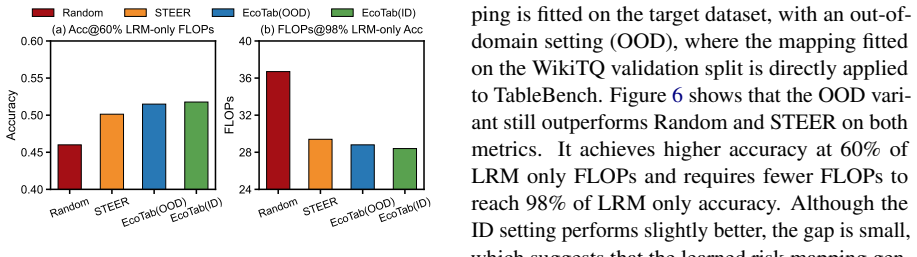
- EcoTab consistently outperforms strong baselines on multiple table reasoning benchmarks.
- EcoTab achieves a better accuracy-efficiency balance than existing stepwise routing methods for table tasks.
- Separately modeling table-token and text-token uncertainties improves routing decisions over methods that treat all tokens uniformly.
- The uncertainty of both token types correlates with next-step error risk, enabling more precise risk mapping for the small model.
Where Pith is reading between the lines
- The same separation of structured versus unstructured token uncertainties could be tested on related tasks such as code generation or symbolic math to see whether similar cost savings appear.
- Routing systems built on EcoTab could be combined with existing model-compression methods to compound efficiency gains beyond routing alone.
- Automatic detection of token-type boundaries during generation might remove the need for task-specific table identification in future versions.
Load-bearing premise
That separately estimating uncertainties for table tokens and text tokens and mapping them to next-step failure risks will produce better routing decisions than methods that do not separate the token types.
What would settle it
A head-to-head experiment in which a stepwise router that does not separate table-token and text-token uncertainties matches or exceeds EcoTab's accuracy at equal or lower total inference cost on the same benchmarks would falsify the advantage of the separation step.
Figures








read the original abstract
Large Reasoning Models (LRMs) achieve strong performance on table reasoning tasks but incur substantial inference cost due to long reasoning traces. Stepwise model routing mitigates this issue by dynamically assigning reasoning steps to smaller or larger models. However, stepwise model routing for table reasoning remains underexplored. Through empirical analysis, we find that reasoning steps involving tables contain two types of tokens with distinct uncertainty distributions: table tokens grounded in table structure, such as cell values and headers, and text tokens representing surrounding natural-language reasoning. The uncertainty of both token types is correlated with the risk that the model makes an error in the next reasoning step. However, existing methods fail to model them separately, leading to suboptimal routing decisions. To address this, we propose EcoTab, a table-aware stepwise routing framework for efficient table reasoning. At each reasoning step, EcoTab separately estimates the uncertainties of table tokens and text tokens, maps them to next-step failure risks for the small model, and combines the two risks for routing. Experiments on multiple table reasoning benchmarks show that EcoTab consistently outperforms strong baselines and achieves a better balance between accuracy and efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes EcoTab, a table-aware stepwise model routing framework for efficient table reasoning with large reasoning models (LRMs). Through empirical analysis, it identifies that reasoning steps contain table tokens (grounded in table structure) and text tokens (natural-language reasoning) with distinct uncertainty distributions, both correlated with next-step failure risk for smaller models. Existing stepwise routing methods are argued to be suboptimal because they do not model these token types separately. EcoTab estimates the uncertainties separately, maps each to next-step failure risks, and combines them for routing decisions. Experiments on multiple table reasoning benchmarks are claimed to show that EcoTab consistently outperforms strong baselines while achieving a superior accuracy-efficiency tradeoff.
Significance. If the empirical correlations and routing improvements hold under proper validation, the work could provide a targeted refinement to uncertainty-based stepwise routing specifically for table reasoning tasks, potentially reducing inference costs for LRMs without accuracy loss. The approach is presented as directly falsifiable via benchmark experiments and grounded in observable token-type uncertainty differences rather than untestable theoretical assumptions.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central claim that 'EcoTab consistently outperforms strong baselines and achieves a better balance between accuracy and efficiency' is asserted without any quantitative results, baseline descriptions, statistical tests, error analysis, or even summary metrics; this absence is load-bearing because the entire contribution rests on the empirical demonstration of improved routing decisions.
- [Method / EcoTab framework] Method description (around the EcoTab framework): the procedure for separately estimating uncertainties of table tokens versus text tokens, mapping each to next-step failure risks for the small model, and combining the risks is described only at a high level with no equations, algorithms, or implementation details; without these, it is impossible to assess whether the separation actually yields better decisions than non-separated baselines or to reproduce the claimed improvements.
minor comments (2)
- [Abstract / Title] The abstract and title could more explicitly indicate the scope (table reasoning only) to avoid overgeneralization to general stepwise routing.
- [Introduction / Preliminaries] Notation for 'table tokens' and 'text tokens' should be defined with examples or a figure early in the paper for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which identify key areas where additional detail will strengthen the manuscript. We will revise the paper to provide quantitative empirical support and fuller methodological specifications while preserving the core contributions.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central claim that 'EcoTab consistently outperforms strong baselines and achieves a better balance between accuracy and efficiency' is asserted without any quantitative results, baseline descriptions, statistical tests, error analysis, or even summary metrics; this absence is load-bearing because the entire contribution rests on the empirical demonstration of improved routing decisions.
Authors: We agree that the abstract and experiments section would be strengthened by explicit quantitative support. In the revision we will insert a concise summary of key metrics (accuracy, cost reduction, and efficiency-accuracy trade-off) directly into the abstract, expand the experiments section with baseline descriptions, tabulated results across all benchmarks, statistical significance tests, and a short error analysis. These additions will make the empirical claims verifiable without altering the underlying findings. revision: yes
-
Referee: [Method / EcoTab framework] Method description (around the EcoTab framework): the procedure for separately estimating uncertainties of table tokens versus text tokens, mapping each to next-step failure risks for the small model, and combining the risks is described only at a high level with no equations, algorithms, or implementation details; without these, it is impossible to assess whether the separation actually yields better decisions than non-separated baselines or to reproduce the claimed improvements.
Authors: We accept that the current description is insufficiently detailed for reproduction and evaluation. The revised manuscript will add explicit equations for per-token-type uncertainty estimation, the risk-mapping functions, and the risk-combination rule; we will also include a pseudocode algorithm and concrete implementation parameters (e.g., token classification heuristics and risk-threshold calibration). These changes will allow direct comparison with non-separated baselines. revision: yes
Circularity Check
No significant circularity
full rationale
The paper describes an empirical pipeline: observe distinct uncertainty distributions for table tokens versus text tokens, correlate each with next-step failure risk, and route decisions on the combined signal. No equations, fitted parameters, or derivations are presented that reduce by construction to the inputs themselves. The method is falsifiable on external benchmarks and does not rely on self-citations or ansatzes that loop back to the target result. The central claim rests on observable correlations rather than self-referential definitions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 58th annual meet- ing of the association for computational linguistics, pages 4320–4333
Tapas: Weakly supervised table parsing via pre-training. InProceedings of the 58th annual meet- ing of the association for computational linguistics, pages 4320–4333. Hiroshi Iida, Dung Thai, Varun Manjunatha, and Mohit Iyyer. 2021. Tabbie: Pretrained representations of tabular data. InProceedings of the 2021 Conference of the North American Chapter of th...
2021
-
[2]
Springer. Rihui Jin, Zheyu Xin, Xing Xie, Zuoyi Li, Guilin Qi, Yongrui Chen, Xinbang Dai, Tongtong Wu, and Gho- lamreza Haffari. 2025. Table-r1: Self-supervised and reinforcement learning for program-based table reasoning in small language models.arXiv preprint arXiv:2506.06137. Sangmook Lee, Dohyung Kim, Hyukhun Koh, Nakyeong Yang, and Kyomin Jung. 2025....
-
[3]
InInternational Conference on Machine Learning, pages 19274–19286
Fast inference from transformers via spec- ulative decoding. InInternational Conference on Machine Learning, pages 19274–19286. PMLR. Liyao Li, Chao Ye, Wentao Ye, Yifei Sun, Zhe Jiang, Haobo Wang, Jiaming Tian, Yiming Zhang, Ning- tao Wang, Xing Fu, and 1 others. 2025. Table as a modality for large language models.arXiv preprint arXiv:2512.00947. Baohao ...
-
[4]
Let’s verify step by step.arXiv preprint arXiv:2305.20050. Xinyin Ma, Guangnian Wan, Runpeng Yu, Gongfan Fang, and Xinchao Wang. 2025. Cot-valve: Length- compressible chain-of-thought tuning. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 6025–6035. Benjamin Newman, Yoonjoo Lee,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
When TableQA Meets Noise: A Dual Denoising Framework for Complex Questions and Large-scale Tables
When tableqa meets noise: A dual denoising framework for complex questions and large-scale tables.arXiv preprint arXiv:2509.17680. Pengcheng Yin, Graham Neubig, Wen-tau Yih, and Se- bastian Riedel. 2020. Tabert: Pretraining for joint understanding of textual and tabular data. InProceed- ings of the 58th annual meeting of the association for computational ...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[6]
1,200” and “1200
for cross-family collaboration. This design allows us to evaluate whether EcoTab remains effective under both homogeneous and heteroge- neous model pairs. For EcoTab and all compared baselines, we use the same decoding configuration for fair comparison. Specifically, we set the tem- perature to 0.7, the maximum generation length to 16,384 tokens, and top-...
2015
-
[7]
Then 20 Nov 2011
Then 6 Nov 2011. Then 20 Nov 2011. Then 23 Jan
2011
-
[8]
Then 17 Sep 2012
Then 30 Jan 2012. Then 17 Sep 2012. Then 12 Nov
2012
-
[9]
[Step 5] Question: are the dates set in a consecutive order? Table: {table content} Answer: yes [Step 4] Wait, but between 20 Nov 2011 and 23 Jan 2012, there's a gap
Then 28 Oct 2013. [Step 5] Question: are the dates set in a consecutive order? Table: {table content} Answer: yes [Step 4] Wait, but between 20 Nov 2011 and 23 Jan 2012, there's a gap. Let me check the dates again. 20 Nov 2011, then 23 Jan 2012. That's a few months later. Then 30 Jan 2012, then 17 Sep 2012, then 12 Nov 2012, then 28 Oct 2013. So there's a...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.