Attention as In-Context Empirical Bayes: A Two-Stage View via Particle Dynamics
Pith reviewed 2026-06-29 09:01 UTC · model grok-4.3
The pith
Minimal attention-only transformers admit a two-stage empirical Bayes interpretation where attention computes kernel-weighted posterior means and depth refines the context distribution via particle dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
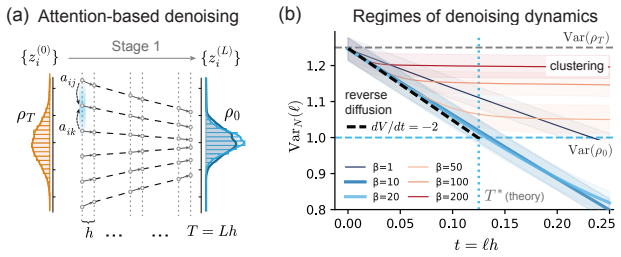
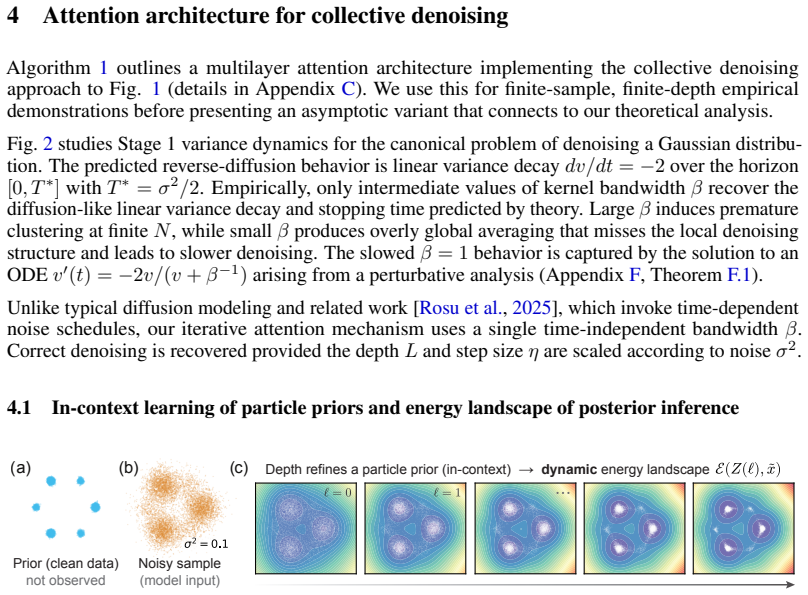
Minimal attention-only transformers under all-token corruption admit a two-stage empirical Bayes interpretation. A single attention step computes a kernel-weighted posterior mean with respect to the empirical distribution defined by the context. Depth refines this distribution through particle dynamics (Stage 1), while a long-range skip-connection carries the noisy input as a query for posterior inference (Stage 2), revealing distinct statistical roles for depth and attention residuals. The context itself induces a depth-dependent energy landscape governing in-context inference, and effective denoising emerges without an explicit noise schedule using only a fixed kernel bandwidth and finite
What carries the argument
The two-stage empirical Bayes view in which a kernel-weighted posterior mean is computed from the context empirical distribution, with depth evolving that distribution through particle dynamics on an induced energy landscape.
If this is right
- Depth refines the empirical distribution through particle dynamics on the induced energy landscape.
- Effective denoising arises from a fixed kernel bandwidth and finite integration horizon without any explicit noise schedule.
- A principled relationship between depth and noise level follows from the finite integration horizon.
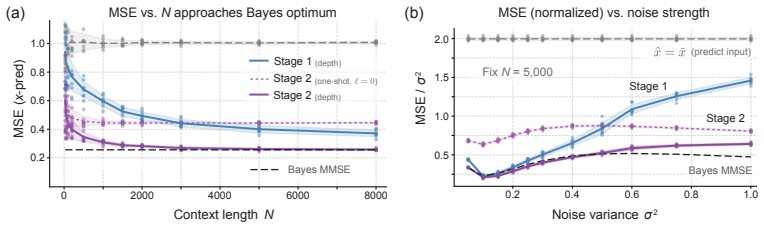
- The empirical estimator converges to the Bayes-optimal predictor for a class of well-behaved priors under asymptotic conditions.
- Attention receives a statistical interpretation as sample-based posterior estimation without explicit density modeling.
Where Pith is reading between the lines
- The distinct role assigned to skip connections suggests they could be tuned separately from standard attention layers in practical architectures.
- The particle-dynamics stage may generalize to other in-context tasks such as few-shot classification or regression.
- Training objectives could be modified to explicitly encourage the emergence of the predicted energy landscape.
- The reverse-diffusion connection opens the possibility of importing sampling techniques from diffusion models into transformer inference.
Load-bearing premise
The context tokens induce a depth-dependent energy landscape that governs the in-context inference process.
What would settle it
Direct computation showing that attention weights fail to match the kernel weights with respect to the empirical context distribution, or that increasing depth fails to produce the predicted refinement of the posterior mean estimate.
Figures


read the original abstract
We study minimal attention-only transformers under all-token corruption and show they admit a two-stage empirical Bayes interpretation. A single attention step computes a kernel-weighted posterior mean with respect to the empirical distribution defined by the context. Depth refines this distribution through particle dynamics (Stage 1), while a long-range skip-connection carries the noisy input as a query for posterior inference (Stage 2), revealing distinct statistical roles for depth and attention residuals. The framework isolates a minimal setting in which the context itself induces a depth-dependent energy landscape governing in-context inference. We show that effective denoising can emerge without an explicit noise schedule: a fixed kernel bandwidth and finite integration horizon suffice, yielding a principled depth-noise relationship. We further establish a posterior-mean recovery guarantee for a class of well-behaved priors, where the empirical estimator converges to the Bayes-optimal predictor under asymptotic conditions. Connecting these dynamics to reverse-diffusion limits, our results provide a statistical interpretation of attention as in-context inference via sample-based posterior estimation, without explicit density modeling.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript studies minimal attention-only transformers under all-token corruption and interprets them as a two-stage empirical Bayes procedure. A single attention step is claimed to compute a kernel-weighted posterior mean with respect to the empirical distribution induced by the context. Depth is interpreted as performing particle dynamics to refine this distribution (Stage 1), while a long-range skip-connection carries the noisy input as a query for posterior inference (Stage 2). The authors claim that effective denoising emerges without an explicit noise schedule using only a fixed kernel bandwidth and finite integration horizon, and they establish a posterior-mean recovery guarantee for a class of well-behaved priors under asymptotic conditions, connecting the dynamics to reverse-diffusion limits.
Significance. If the derivations and recovery guarantee hold with the stated conditions made precise, the work supplies a statistical interpretation of attention as in-context sample-based posterior estimation. This could clarify the distinct roles of depth (particle refinement) and residuals (query carrying) in transformers and isolate a minimal setting where context induces a depth-dependent energy landscape for inference, without requiring explicit density modeling or noise schedules.
major comments (1)
- [Abstract] Abstract: the posterior-mean recovery guarantee is stated only under unspecified 'asymptotic conditions.' The manuscript must explicitly identify the scaling regime (context length n→∞ at fixed depth, depth L→∞ at fixed n, joint scaling, or another limit) because this choice determines whether the guarantee applies to the finite-depth, finite-context denoising behavior that the two-stage framework isolates.
Simulated Author's Rebuttal
We thank the referee for the careful reading and for identifying the need to make the asymptotic regime explicit. We agree that this clarification strengthens the presentation and will revise the abstract and theorem statements accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the posterior-mean recovery guarantee is stated only under unspecified 'asymptotic conditions.' The manuscript must explicitly identify the scaling regime (context length n→∞ at fixed depth, depth L→∞ at fixed n, joint scaling, or another limit) because this choice determines whether the guarantee applies to the finite-depth, finite-context denoising behavior that the two-stage framework isolates.
Authors: We agree that the scaling regime must be stated explicitly. The recovery guarantee is derived under the regime n → ∞ with depth L held fixed (and kernel bandwidth fixed). This limit is the natural one for the two-stage view: the single attention step produces an empirical posterior mean whose error vanishes as the context size grows, while the subsequent particle dynamics (Stage 1) and residual query (Stage 2) operate at finite depth. We will revise the abstract to read “under the asymptotic regime of context length n → ∞ at fixed depth” and will add the same clarification to the theorem statement and its proof sketch. revision: yes
Circularity Check
No circularity: interpretive framework with external-style guarantee
full rationale
The paper advances a two-stage empirical Bayes reading of attention and states a posterior-mean recovery guarantee under asymptotic conditions. No quoted step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the central claims are presented as interpretive mappings and convergence statements rather than closed algebraic identities. The derivation chain therefore remains self-contained against the supplied text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The context itself induces a depth-dependent energy landscape governing in-context inference
- domain assumption A class of well-behaved priors exists for which the empirical estimator converges to the Bayes-optimal predictor under asymptotic conditions
Reference graph
Works this paper leans on
-
[1]
urich. Birkh\
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savar\'e. Gradient flows in metric spaces and in the space of probability measures. Lectures in Mathematics ETH Z\"urich. Birkh\"auser Verlag, Basel, second edition, 2008. ISBN 978-3-7643-8721-1
2008
-
[2]
Laplacian eigenmaps for dimensionality reduction and data representation
Mikhail Belkin and Partha Niyogi. Laplacian eigenmaps for dimensionality reduction and data representation. Neural computation, 15 0 (6): 0 1373--1396, 2003
2003
-
[3]
I. Bihari. A generalization of a lemma of B ellman and its application to uniqueness problems of differential equations. Acta Math. Acad. Sci. Hungar., 7: 0 81--94, 1956. ISSN 0001-5954,1588-2632. doi:10.1007/BF02022967. URL https://doi.org/10.1007/BF02022967
-
[4]
Christopher M. Bishop. Pattern Recognition and Machine Learning. Springer, 2006
2006
-
[5]
A multiscale analysis of mean-field transformers in the moderate interaction regime
Giuseppe Bruno, Federico Pasqualotto, and Andrea Agazzi. A multiscale analysis of mean-field transformers in the moderate interaction regime. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=WCRPgBpbcA
2025
-
[6]
Martin Burger, Samira Kabri, Yury Korolev, Tim Roith, and Lukas Weigand. Analysis of mean-field models arising from self-attention dynamics in transformer architectures with layer normalization. Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, 383 0 (2298): 0 20240233, 06 2025. ISSN 1364-503X. doi:10.1098...
-
[7]
Propagation of chaos: a review of models, methods and applications
Louis-Pierre Chaintron and Antoine Diez. Propagation of chaos: a review of models, methods and applications. I . M odels and methods. Kinet. Relat. Models, 15 0 (6): 0 895--1015, 2022. ISSN 1937-5093,1937-5077. doi:10.3934/krm.2022017. URL https://doi.org/10.3934/krm.2022017
-
[8]
Neural ordinary differential equations
Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. Neural ordinary differential equations. Advances in neural information processing systems, 31, 2018
2018
-
[9]
Skyformer: Remodel self-attention with gaussian kernel and nyström method
Yifan Chen, Qi Zeng, Heng Ji, and Yun Yang. Skyformer: Remodel self-attention with gaussian kernel and nyström method. Advances in Neural Information Processing Systems, 34: 0 2122--2135, 2021
2021
-
[10]
D. Comaniciu and P. Meer. Mean shift analysis and applications. In Proceedings of the Seventh IEEE International Conference on Computer Vision, volume 2, pages 1197--1203 vol.2, 1999. doi:10.1109/ICCV.1999.790416
-
[11]
NRGPT : An energy-based alternative for GPT
Nima Dehmamy, Benjamin Hoover, Bishwajit Saha, Leo Kozachkov, Jean-Jacques Slotine, and Dmitry Krotov. NRGPT : An energy-based alternative for GPT . In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=B3Muyi2zgo
2026
-
[12]
Mean field simulation for monte carlo integration
Pierre Del Moral. Mean field simulation for monte carlo integration. Monographs on Statistics and Applied Probability, 126 0 (26): 0 6, 2013
2013
-
[13]
Vlasov equations
Roland L’vovich Dobrushin. Vlasov equations. Functional Analysis and Its Applications, 13 0 (2): 0 115--123, 1979
1979
-
[14]
Tweedie’s formula and selection bias
Bradley Efron. Tweedie’s formula and selection bias. Journal of the American Statistical Association, 106 0 (496): 0 1602--1614, 2011
2011
-
[15]
On the rate of convergence in W asserstein distance of the empirical measure
Nicolas Fournier and Arnaud Guillin. On the rate of convergence in W asserstein distance of the empirical measure. Probab. Theory Related Fields, 162 0 (3-4): 0 707--738, 2015. ISSN 0178-8051,1432-2064. doi:10.1007/s00440-014-0583-7. URL https://doi.org/10.1007/s00440-014-0583-7
-
[16]
K. Fukunaga and L. Hostetler. The estimation of the gradient of a density function, with applications in pattern recognition. IEEE Transactions on Information Theory, 21 0 (1): 0 32--40, 1975. doi:10.1109/TIT.1975.1055330
-
[17]
The emergence of clusters in self-attention dynamics
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. The emergence of clusters in self-attention dynamics. Advances in Neural Information Processing Systems, 36: 0 57026--57037, 2023
2023
-
[18]
A mathematical perspective on transformers
Borjan Geshkovski, Cyril Letrouit, Yury Polyanskiy, and Philippe Rigollet. A mathematical perspective on transformers. Bulletin of the American Mathematical Society, 62 0 (3): 0 427--479, 2025
2025
-
[19]
Energy-based transformers are scalable learners and thinkers
Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, and Tariq Iqbal. Energy-based transformers are scalable learners and thinkers. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=ZBj3Qp1bYg
2026
-
[20]
The fast gauss transform
Leslie Greengard and John Strain. The fast gauss transform. SIAM Journal on Scientific and Statistical Computing, 12 0 (1): 0 79--94, 1991
1991
-
[21]
Manifold denoising
Matthias Hein and Markus Maier. Manifold denoising. Advances in neural information processing systems, 19, 2006
2006
-
[22]
Denoising diffusion probabilistic models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33: 0 6840--6851, 2020
2020
-
[23]
Energy transformer
Benjamin Hoover, Yuchen Liang, Bao Pham, Rameswar Panda, Hendrik Strobelt, Duen Horng Chau, Mohammed J Zaki, and Dmitry Krotov. Energy transformer. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=MbwVNEx9KS
2023
-
[24]
DiScoFormer: Plug-In Density and Score Estimation with Transformers
Vasily Ilin and Peter Sushko. Discoformer: Plug-in density and score estimation with transformers, 2026. URL https://arxiv.org/abs/2511.05924
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Constrained denoising, empirical bayes, and optimal transport
Adam Quinn Jaffe, Nikolaos Ignatiadis, and Bodhisattva Sen. Constrained denoising, empirical bayes, and optimal transport. arXiv preprint arXiv:2506.09986, 2025
-
[26]
Iain M. Johnstone and Bernard W. Silverman. Empirical bayes selection of wavelet thresholds. Annals of Statistics, 33, 2005. ISSN 00905364. doi:10.1214/009053605000000345
-
[27]
Dense associative memory for pattern recognition
Dmitry Krotov and John J Hopfield. Dense associative memory for pattern recognition. Advances in neural information processing systems, 29, 2016
2016
-
[28]
Back to Basics: Let Denoising Generative Models Denoise
Tianhong Li and Kaiming He. Back to basics: Let denoising generative models denoise. arXiv preprint arXiv:2511.13720, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. In Computer Vision -- ECCV 2024: 18th European Conference, Milan, Italy, September 29--October 4, 2024, Proceedings, Part LXXVII, pages 23--40, Berlin, Heid...
-
[30]
An empirical bayes estimator of the mean of a normal population
Koichi Miyasawa. An empirical bayes estimator of the mean of a normal population. Bull. Inst. Internat. Statist, 38 0 (181-188): 0 1--2, 1961
1961
-
[31]
Generative Modeling from Black-box Corruptions via Self-Consistent Stochastic Interpolants
Chirag Modi, Jiequn Han, Eric Vanden-Eijnden, and Joan Bruna. Generative modeling from black-box corruptions via self-consistent stochastic interpolants. arXiv preprint arXiv:2512.10857, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
On estimating regression
EA Nadaraya. On estimating regression. theor. Probab. Appl, 9 0 (1), 1964
1964
-
[33]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 4195--4205, October 2023
2023
-
[34]
a fl, Johannes Lehner, Philipp Seidl, Michael Widrich, Lukas Gruber, Markus Holzleitner, Thomas Adler, David P. Kreil, Michael K. Kopp, G \
Hubert Ramsauer, Bernhard Sch \" a fl, Johannes Lehner, Philipp Seidl, Michael Widrich, Lukas Gruber, Markus Holzleitner, Thomas Adler, David P. Kreil, Michael K. Kopp, G \" u nter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. Hopfield networks is all you need. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event,...
2021
-
[35]
Least squares estimation without priors or supervision
Martin Raphan and Eero P Simoncelli. Least squares estimation without priors or supervision. Neural computation, 23 0 (2): 0 374--420, 2011
2011
-
[36]
Variational inference with normalizing flows
Danilo Rezende and Shakir Mohamed. Variational inference with normalizing flows. In International conference on machine learning, pages 1530--1538. PMLR, 2015
2015
-
[37]
The mean-field dynamics of transformers
Philippe Rigollet. The mean-field dynamics of transformers. arXiv preprint arXiv:2512.01868, 2025
-
[38]
An empirical bayes approach to statistics
Herbert E Robbins. An empirical bayes approach to statistics. In Breakthroughs in Statistics: Foundations and basic theory, pages 388--394. Springer, 1956
1956
-
[39]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj\"orn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684--10695, June 2022
2022
-
[40]
From softmax to score: Transformers can effectively implement in-context denoising steps
Paul Rosu, Lawrence Carin, and Xiang Cheng. From softmax to score: Transformers can effectively implement in-context denoising steps. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=4QRoLzD11x
2025
-
[41]
Sinkformers: Transformers with doubly stochastic attention
Michael E Sander, Pierre Ablin, Mathieu Blondel, and Gabriel Peyr \'e . Sinkformers: Transformers with doubly stochastic attention. In International Conference on Artificial Intelligence and Statistics, pages 3515--3530. PMLR, 2022
2022
-
[42]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with latent thoughts: On the power of looped transformers. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=din0lGfZFd
2025
-
[43]
Emergent properties of collective gene-expression patterns in multicellular systems
Matthew Smart and Anton Zilman. Emergent properties of collective gene-expression patterns in multicellular systems. Cell Reports Physical Science, 4 0 (2), 2023
2023
-
[44]
In-context denoising with one-layer transformers: Connections between attention and associative memory retrieval
Matthew Smart, Alberto Bietti, and Anirvan M Sengupta. In-context denoising with one-layer transformers: Connections between attention and associative memory retrieval. In International Conference on Machine Learning, pages 55950--55971. PMLR, 2025
2025
-
[45]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=PxTIG12RRHS
2021
-
[46]
Estimation of the mean of a multivariate normal distribution
Charles M Stein. Estimation of the mean of a multivariate normal distribution. The annals of Statistics, pages 1135--1151, 1981
1981
-
[47]
Topics in Propagation of Chaos
Alain-Sol Sznitman. Topics in propagation of chaos. In \'Ecole d'\'Et\'e de P robabilit\'es de S aint- F lour XIX ---1989 , volume 1464 of Lecture Notes in Math., pages 165--251. Springer, Berlin, 1991. ISBN 3-540-53841-0. doi:10.1007/BFb0085169. URL https://doi.org/10.1007/BFb0085169
-
[48]
Kimi Team, Guangyu Chen, Yu Zhang, Jianlin Su, Weixin Xu, Siyuan Pan, Yaoyu Wang, Yucheng Wang, Guanduo Chen, Bohong Yin, Yutian Chen, Junjie Yan, Ming Wei, Y. Zhang, Fanqing Meng, Chao Hong, Xiaotong Xie, Shaowei Liu, Enzhe Lu, Yunpeng Tai, Yanru Chen, Xin Men, Haiqing Guo, Y. Charles, Haoyu Lu, Lin Sui, Jinguo Zhu, Zaida Zhou, Weiran He, Weixiao Huang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[49]
Solving empirical bayes via transformers
Anzo Teh, Mark Jabbour, and Yury Polyanskiy. Solving empirical bayes via transformers. arXiv preprint arXiv:2502.09844, 2025
-
[50]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[51]
Springer, Berlin, Heidelberg, 2009
C\'edric Villani. Optimal transport, volume 338 of Grundlehren der mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences]. Springer-Verlag, Berlin, 2009. ISBN 978-3-540-71049-3. doi:10.1007/978-3-540-71050-9. URL https://doi.org/10.1007/978-3-540-71050-9. Old and new
-
[52]
A connection between score matching and denoising autoencoders
Pascal Vincent. A connection between score matching and denoising autoencoders. Neural Computation, 23 0 (7): 0 1661--1674, 2011. doi:10.1162/NECO_a_00142
-
[53]
Transformers learn in-context by gradient descent
Johannes Von Oswald, Eyvind Niklasson, Ettore Randazzo, Jo \ a o Sacramento, Alexander Mordvintsev, Andrey Zhmoginov, and Max Vladymyrov. Transformers learn in-context by gradient descent. In International Conference on Machine Learning, pages 35151--35174. PMLR, 2023
2023
-
[54]
Attention-only transformers via unrolled subspace denoising
Peng Wang, Yifu Lu, Yaodong Yu, Druv Pai, Qing Qu, and Yi Ma. Attention-only transformers via unrolled subspace denoising. In International Conference on Machine Learning, pages 63840--63859. PMLR, 2025
2025
-
[55]
Smooth regression analysis
Geoffrey S Watson. Smooth regression analysis. Sankhy \=a : The Indian Journal of Statistics, Series A , pages 359--372, 1964
1964
-
[56]
o mformer: A nystr \
Yunyang Xiong, Zhanpeng Zeng, Rudrasis Chakraborty, Mingxing Tan, Glenn Fung, Yin Li, and Vikas Singh. Nystr \"o mformer: A nystr \"o m-based algorithm for approximating self-attention. In Proceedings of the AAAI conference on artificial intelligence, volume 35, pages 14138--14148, 2021
2021
-
[57]
Looped transformers are better at learning learning algorithms
Liu Yang, Kangwook Lee, Robert D Nowak, and Dimitris Papailiopoulos. Looped transformers are better at learning learning algorithms. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=HHbRxoDTxE
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.