Orthogonal Negative Guidance in Attention Feature Space for Text-to-Image Generation
Pith reviewed 2026-06-29 08:27 UTC · model grok-4.3
The pith
Orthogonal negative guidance in attention feature space suppresses unwanted concepts in text-to-image generation while preserving desired semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
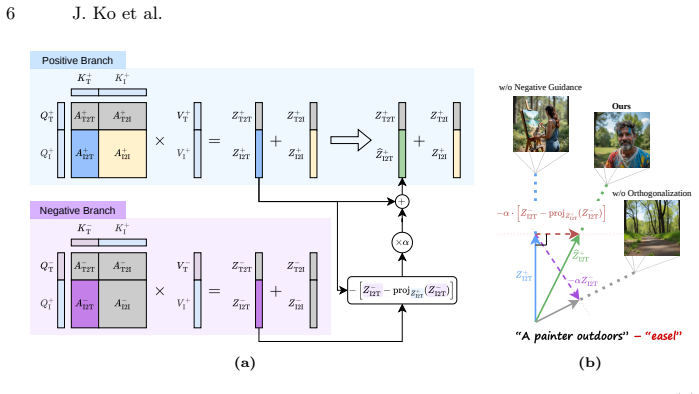
By orthogonalizing negative-prompt attention features with respect to positive-prompt features in the attention output space and subtracting only the orthogonal component, the method suppresses unwanted concepts while preserving desired semantics in MM-DiT-based text-to-image transformers.
What carries the argument
Orthogonal Negative Guidance, which orthogonalizes negative-prompt attention features to positive-prompt features and subtracts only the orthogonal component from the positive features.
If this is right
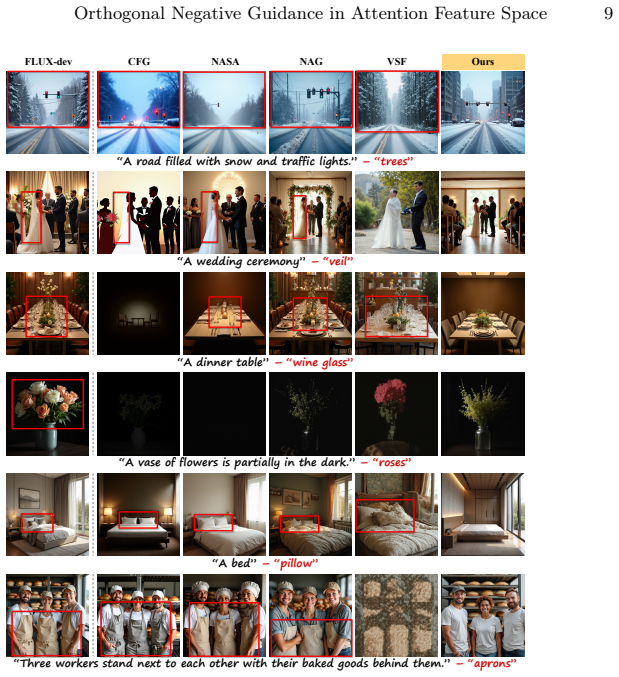
- It achieves favorable trade-offs between concept suppression, prompt alignment, and image quality on FLUX-dev and FLUX-schnell.
- Human evaluation shows it outperforms the second-best baseline by 18.78%.
- It supports multi-concept suppression.
- It allows adjustable concept suppression.
Where Pith is reading between the lines
- This selective subtraction could be tested in other transformer-based generative architectures to see if the orthogonality principle generalizes.
- Adjustable suppression levels suggest applications in fine-tuning user control over generated content attributes.
- The method implies that feature space projections can isolate semantic directions more precisely than simple prompt negation.
Load-bearing premise
Subtracting only the orthogonal component of negative-prompt attention features from positive-prompt features in the output space of MM-DiT transformers will suppress the target concept without collateral damage to desired semantics or image quality.
What would settle it
Generating images with the method and checking if the unwanted concept still appears at similar rates as standard negative prompting, or if image quality metrics drop significantly compared to baselines.
Figures




























read the original abstract
Text-to-image (T2I) models have become increasingly capable of generating high-quality images. Yet, enforcing the explicit absence of a specified object or attribute remains a fundamentally challenging problem. Existing approaches, including prompt negation, post-hoc editing, and negative guidance, remain insufficient for explicit concept suppression, often failing to remove the target concept or degrading overall image quality. To this end, we propose Orthogonal Negative Guidance in attention feature space, a training-free method that operates in the attention output space of MM-DiT-based T2I transformers. Our method orthogonalizes negative-prompt attention features with respect to positive-prompt features and subtracts only the orthogonal component, suppressing unwanted concepts while preserving desired semantics. Experiments on FLUX-dev and FLUX-schnell show that our method achieves favorable trade-offs between concept suppression, prompt alignment, and image quality. In human evaluation, our method outperforms the second-best baseline by 18.78%. We further show that our method supports multi-concept suppression and adjustable concept suppression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Orthogonal Negative Guidance, a training-free method for explicit concept suppression in text-to-image generation. It operates directly in the attention output space of MM-DiT transformers by orthogonalizing negative-prompt attention features with respect to positive-prompt features and subtracting only the orthogonal component. This is claimed to suppress unwanted concepts while preserving desired semantics. Experiments on FLUX-dev and FLUX-schnell are reported to achieve favorable trade-offs among suppression, prompt alignment, and image quality, with an 18.78% win rate in human evaluation over the second-best baseline; the method is further shown to support multi-concept and adjustable suppression.
Significance. If the results hold, the work supplies a parameter-free geometric construction for negative guidance that requires no additional training or fitted parameters. The direct orthogonality operation in attention feature space, combined with the reported human-evaluation gain and multi-concept support, would represent a practical advance for controllable T2I generation.
major comments (1)
- [§4] §4 (Experiments): The central empirical claim—an 18.78% human-evaluation win and favorable trade-offs on FLUX-dev/schnell—lacks accompanying quantitative metrics, baseline definitions, number of evaluators, statistical tests, or implementation details in the reported results. This information is load-bearing for verifying the suppression-without-collateral-damage claim.
minor comments (1)
- [§3] A diagram or explicit projection formula in the method section would clarify how orthogonality is computed in the high-dimensional attention output space.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The point raised about experimental details is valid, and we will incorporate the requested information in the revision to improve clarity and verifiability.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The central empirical claim—an 18.78% human-evaluation win and favorable trade-offs on FLUX-dev/schnell—lacks accompanying quantitative metrics, baseline definitions, number of evaluators, statistical tests, or implementation details in the reported results. This information is load-bearing for verifying the suppression-without-collateral-damage claim.
Authors: We agree that the human evaluation section requires additional supporting details to allow independent verification. In the revised manuscript, we will expand §4 to include: (1) quantitative metrics such as CLIP-based prompt alignment scores, concept suppression rates via classifier probes, and FID for image quality; (2) explicit definitions and hyperparameter settings for all baselines (e.g., negative prompting, classifier-free guidance variants); (3) the number of human evaluators, their recruitment criteria, and the exact evaluation protocol (pairwise comparisons with randomized presentation); (4) statistical tests including p-values and confidence intervals for the 18.78% win rate; and (5) full implementation details such as the precise negative/positive prompt templates, diffusion steps, guidance scales, and hardware used. These additions will directly address the concern about verifying the claimed trade-offs. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents a training-free geometric operation—orthogonalizing negative-prompt attention features w.r.t. positive-prompt features in MM-DiT output space and subtracting only the orthogonal component—without any derivation, fitted parameters, or self-referential definitions that reduce the claimed result to its inputs by construction. The central claim is an explicit algorithmic step whose empirical behavior (concept suppression vs. quality trade-offs on FLUX-dev/schnell, human eval gains) is tested directly; no equations or self-citations are invoked as load-bearing premises that would create circularity. This is the common case of a self-contained empirical method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
AI, S.: Introducing stable diffusion 3.5 (2024),https://stability.ai/news/ introducing-stable-diffusion-3-5/
2024
-
[2]
Building Normalizing Flows with Stochastic Interpolants
Albergo, M.S., Vanden-Eijnden, E.: Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Alhamoud, K., Alshammari, S., Tian, Y., Li, G., Torr, P.H., Kim, Y., Ghassemi, M.: Vision-language models do not understand negation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 29612–29622 (2025)
2025
-
[4]
In: SIGGRAPH Asia 2023 Conference Papers
Avrahami, O., Aberman, K., Fried, O., Cohen-Or, D., Lischinski, D.: Break-a- scene: Extracting multiple concepts from a single image. In: SIGGRAPH Asia 2023 Conference Papers. pp. 1–12 (2023)
2023
-
[5]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: Multidiffusion: Fusing diffusion paths for controlled image generation (2023)
2023
-
[7]
Advances in Neural Information Processing Systems36, 25365–25389 (2023)
Brack, M., Friedrich, F., Hintersdorf, D., Struppek, L., Schramowski, P., Kersting, K.: Sega: Instructing text-to-image models using semantic guidance. Advances in Neural Information Processing Systems36, 25365–25389 (2023)
2023
-
[8]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18392–18402 (2023)
2023
-
[9]
arXiv preprint arXiv:2510.14376 (2025)
Byun, D., Park, J., Ko, J., Choi, C., Rhee, W.: Dos: Directional object sep- aration in text embeddings for multi-object image generation. arXiv preprint arXiv:2510.14376 (2025)
-
[10]
ACM trans- actions on Graphics (TOG)42(4), 1–10 (2023)
Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM trans- actions on Graphics (TOG)42(4), 1–10 (2023)
2023
-
[11]
arXiv preprint arXiv:2505.21179 (2025)
Chen, D.Y., Bandyopadhyay, H., Zou, K., Song, Y.Z.: Normalized atten- tion guidance: Universal negative guidance for diffusion model. arXiv preprint arXiv:2505.21179 (2025)
-
[12]
In: Forty-first international conference on machine learning (2024)
Esser, P., Kulal, S., Blattmann, A., Entezari, R., Müller, J., Saini, H., Levi, Y., Lorenz, D., Sauer, A., Boesel, F., et al.: Scaling rectified flow transformers for high-resolution image synthesis. In: Forty-first international conference on machine learning (2024)
2024
-
[13]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-Or, D.: An image is worth one word: Personalizing text-to-image gener- ation using textual inversion. arXiv preprint arXiv:2208.01618 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[14]
In: Proceedings of the IEEE/CVF international conference on computer vision
Gandikota, R., Materzynska, J., Fiotto-Kaufman, J., Bau, D.: Erasing concepts from diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 2426–2436 (2023)
2023
-
[15]
In: European Conference on Computer Vision
Gandikota, R., Materzyńska, J., Zhou, T., Torralba, A., Bau, D.: Concept sliders: Lora adaptors for precise control in diffusion models. In: European Conference on Computer Vision. pp. 172–188. Springer (2024) 16 J. Ko et al
2024
-
[16]
In: Proceedings of the IEEE/CVF winter conference on applications of computer vision
Gandikota, R., Orgad, H., Belinkov, Y., Materzyńska, J., Bau, D.: Unified concept editing in diffusion models. In: Proceedings of the IEEE/CVF winter conference on applications of computer vision. pp. 5111–5120 (2024)
2024
-
[17]
arXiv preprint arXiv:2508.10931 (2025)
Guo, W., Du, S.: Vsf: Simple, efficient, and effective negative guidance in few-step image generation models by value sign flip. arXiv preprint arXiv:2508.10931 (2025)
-
[18]
In: Proceedings of the IEEE/CVF inter- national conference on computer vision
Han, L., Li, Y., Zhang, H., Milanfar, P., Metaxas, D., Yang, F.: Svdiff: Compact parameter space for diffusion fine-tuning. In: Proceedings of the IEEE/CVF inter- national conference on computer vision. pp. 7323–7334 (2023)
2023
-
[19]
Prompt-to-Prompt Image Editing with Cross Attention Control
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Classifier-Free Diffusion Guidance
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Hurst, A., Lerer, A., Goucher, A.P., Perelman, A., Ramesh, A., Clark, A., Os- trow, A., Welihinda, A., Hayes, A., Radford, A., et al.: Gpt-4o system card. arXiv preprint arXiv:2410.21276 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Kim, J., Park, J., Rhee, W.: Selectively informative description can reduce unde- sired embedding entanglements in text-to-image personalization. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 8312–8322 (2024)
2024
-
[23]
arXiv preprint arXiv:2507.01496 (2025)
Kim, J., Park, J., Song, Y., Kwak, N., Rhee, W.: Reflex: Text-guided editing of real images in rectified flow via mid-step feature extraction and attention adaptation. arXiv preprint arXiv:2507.01496 (2025)
-
[24]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Kulikov, V., Kleiner, M., Huberman-Spiegelglas, I., Michaeli, T.: Flowedit: Inversion-free text-based editing using pre-trained flow models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19721–19730 (2025)
2025
-
[25]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)
Kumari, N., Zhang, B., Wang, S.Y., Shechtman, E., Zhang, R., Zhu, J.Y.: Ablat- ing concepts in text-to-image diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). pp. 22691–22702 (October 2023)
2023
-
[26]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Kumari, N., Zhang, B., Zhang, R., Shechtman, E., Zhu, J.Y.: Multi-concept cus- tomization of text-to-image diffusion. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1931–1941 (2023)
1931
-
[27]
Labs, B.F.: Announcing black forest labs (2024),https://blackforestlabs.ai/ announcing-black-forest-labs/
2024
-
[28]
Labs, B.F.: Flux.https://github.com/black-forest-labs/flux(2024)
2024
-
[29]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Labs, B.F., Batifol, S., Blattmann, A., Boesel, F., Consul, S., Diagne, C., Dock- horn, T., English, J., English, Z., Esser, P., et al.: Flux. 1 kontext: Flow match- ing for in-context image generation and editing in latent space. arXiv preprint arXiv:2506.15742 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, J., Hu, L., Zhang, J., Zheng, T., Zhang, H., Wang, D.: Fair text-to-image diffusion via fair mapping. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 26256–26264 (2025)
2025
-
[31]
arXiv preprint arXiv:2402.05375 (2024)
Li, S., van de Weijer, J., Hu, T., Khan, F.S., Hou, Q., Wang, Y., Yang, J.: Get what you want, not what you don’t: Image content suppression for text-to-image diffusion models. arXiv preprint arXiv:2402.05375 (2024)
-
[32]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li,Y.,Liu,H.,Wu,Q.,Mu,F.,Yang,J.,Gao,J.,Li,C.,Lee,Y.J.:Gligen:Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22511–22521 (2023) Orthogonal Negative Guidance in Attention Feature Space 17
2023
-
[33]
In: European conference on computer vision
Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: European conference on computer vision. pp. 740–755. Springer (2014)
2014
-
[34]
Flow Matching for Generative Modeling
Lipman, Y., Chen, R.T., Ben-Hamu, H., Nickel, M., Le, M.: Flow matching for generative modeling. arXiv preprint arXiv:2210.02747 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[35]
In: European conference on computer vision
Liu, N., Li, S., Du, Y., Torralba, A., Tenenbaum, J.B.: Compositional visual gen- eration with composable diffusion models. In: European conference on computer vision. pp. 423–439. Springer (2022)
2022
-
[36]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Liu, X., Gong, C., Liu, Q.: Flow straight and fast: Learning to generate and transfer data with rectified flow. arXiv preprint arXiv:2209.03003 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
SDEdit: Guided Image Synthesis and Editing with Stochastic Differential Equations
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[38]
In: Proceedings of the AAAI conference on artificial intelligence
Mou, C., Wang, X., Xie, L., Wu, Y., Zhang, J., Qi, Z., Shan, Y.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In: Proceedings of the AAAI conference on artificial intelligence. vol. 38, pp. 4296–4304 (2024)
2024
-
[39]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Nguyen, V., Nguyen, A., Dao, T., Nguyen, K., Pham, C., Tran, T., Tran, A.: Supercharged one-step text-to-image diffusion models with negative prompts. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 18004–18013 (2025)
2025
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Parihar, R., Bhat, A., Basu, A., Mallick, S., Kundu, J.N., Babu, R.V.: Balanc- ing act: Distribution-guided debiasing in diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 6668–6678 (2024)
2024
-
[41]
In: The Thirteenth International Conference on Learning Representations (2024)
Park, J., Ko, J., Byun, D., Suh, J., Rhee, W.: Cross-attention head position pat- terns can align with human visual concepts in text-to-image generative models. In: The Thirteenth International Conference on Learning Representations (2024)
2024
-
[42]
Peebles,W.,Xie,S.:Scalablediffusionmodelswithtransformers.In:Proceedingsof the IEEE/CVF international conference on computer vision. pp. 4195–4205 (2023)
2023
-
[43]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[44]
arXiv preprint arXiv:2210.04610 (2022)
Rando, J., Paleka, D., Lindner, D., Heim, L., Tramèr, F.: Red-teaming the stable diffusion safety filter. arXiv preprint arXiv:2210.04610 (2022)
-
[45]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
2022
-
[46]
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth:Finetuningtext-to-imagediffusionmodelsforsubject-drivengeneration.In: Proceedings of the IEEE/CVF conference on computer vision and pattern recog- nition. pp. 22500–22510 (2023)
2023
-
[47]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Schramowski, P., Brack, M., Deiseroth, B., Kersting, K.: Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22522– 22531 (2023)
2023
-
[48]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Shin, J., Hwang, A., Kim, Y., Kim, D., Park, J.: Exploring multimodal diffu- sion transformers for enhanced prompt-based image editing. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 19492–19502 (2025) 18 J. Ko et al
2025
-
[49]
In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition
Tumanyan, N., Geyer, M., Bagon, S., Dekel, T.: Plug-and-play diffusion features for text-driven image-to-image translation. In: Proceedings of the IEEE/CVF con- ference on computer vision and pattern recognition. pp. 1921–1930 (2023)
1921
-
[50]
Advances in neural information pro- cessing systems30(2017)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information pro- cessing systems30(2017)
2017
-
[51]
Wu, C., Li, J., Zhou, J., Lin, J., Gao, K., Yan, K., ming Yin, S., Bai, S., Xu, X., Chen, Y., Chen, Y., Tang, Z., Zhang, Z., Wang, Z., Yang, A., Yu, B., Cheng, C., Liu, D., Li, D., Zhang, H., Meng, H., Wei, H., Ni, J., Chen, K., Cao, K., Peng, L., Qu, L., Wu, M., Wang, P., Yu, S., Wen, T., Feng, W., Xu, X., Wang, Y., Zhang, Y., Zhu, Y., Wu, Y., Cai, Y., L...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[52]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Wu, C., Zheng, P., Yan, R., Xiao, S., Luo, X., Wang, Y., Li, W., Jiang, X., Liu, Y., Zhou, J., et al.: Omnigen2: Exploration to advanced multimodal generation. arXiv preprint arXiv:2506.18871 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[53]
In: Proceedings of the IEEE/CVF international conference on computer vision
Xie,J.,Li,Y.,Huang,Y.,Liu,H.,Zhang,W.,Zheng,Y.,Shou,M.Z.:Boxdiff:Text- to-image synthesis with training-free box-constrained diffusion. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 7452–7461 (2023)
2023
-
[54]
In: 2024 IEEE symposium on security and privacy (SP)
Yang, Y., Hui, B., Yuan, H., Gong, N., Cao, Y.: Sneakyprompt: Jailbreaking text- to-image generative models. In: 2024 IEEE symposium on security and privacy (SP). pp. 897–912. IEEE (2024)
2024
-
[55]
a bunch of animals that are in a field
Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 3836–3847 (2023) Orthogonal Negative Guidance in Attention Feature Space 19 A Pseudocode for Orthogonal Negative Guidance Algorithm 1Orthogonal Negative Guidance Require:P +: Posit...
2023
-
[56]
Object: "roses"
Object Absence: The image must NOT contain the object mentioned below. Object: "roses"
-
[57]
A vase of flowers is partially in the dark
Description Match: The image matches the given description. Description: "A vase of flowers is partially in the dark .. " 0 Image 1 0 lmage3 0 Images Back Next 0 lmage2 0 lmage4 D No image satisfies both requirements. Clear form Fig.17: Screenshot of the survey interface used in the human preference study.Participants selected all images that satisfied bo...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.