Honest Lying: Understanding Memory Confabulation in Reflexive Agents
Pith reviewed 2026-06-29 09:15 UTC · model grok-4.3
The pith
Reflexion agents can store and repeatedly act on confident but incorrect task interpretations in their reflective memory, even after correct environment resets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
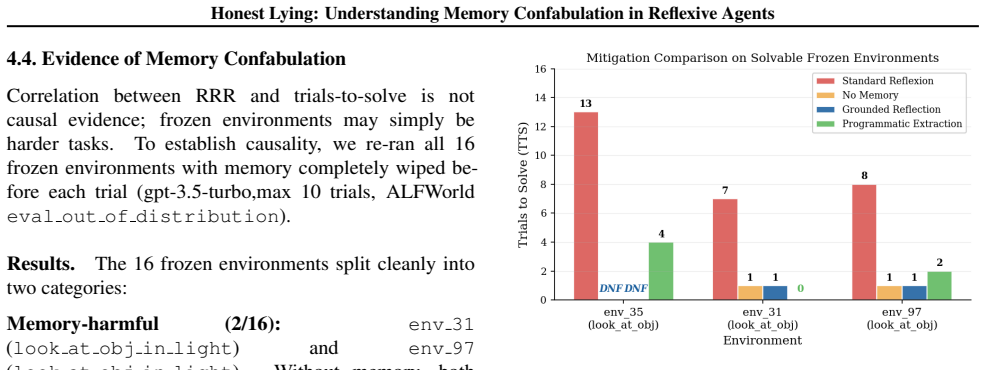
Reflexion-style agents rely on self-generated reflections as memory, implicitly assuming that agents can accurately diagnose their own failures. We show that this assumption can fail systematically: across ALFWorld and HumanEval, agents store confident but incorrect interpretations of the task and continue acting on them across trials, even though the environment resets to the correct task each time. We call this failure mode memory confabulation and introduce the Reflection Repetition Rate (RRR), a log-based metric that detects repeated reliance on incorrect reflective content. Using RRR, we identify 16 frozen environments in ALFWorld, where 0 of 121 reflections mention the correct target o
What carries the argument
Memory confabulation, the generation and persistent reuse of incorrect self-reflections as memory content.
If this is right
- Agents can enter frozen states where reflections contain no correct task information across trials.
- Reflective memory can reinforce false beliefs instead of correcting errors.
- Programmatic extraction of trajectory-level failure signals reduces reliance on incorrect reflections.
- The mitigation raises correct object mention rates and solves some environments that were previously unsolved.
Where Pith is reading between the lines
- Similar confabulation could appear in other LLM agent systems that use self-generated feedback for memory or planning.
- External signals or verification mechanisms may be required to prevent reinforcement of incorrect beliefs in repeated agent interactions.
- The Reflection Repetition Rate metric could be applied to additional benchmarks to measure how common this issue is.
Load-bearing premise
That agents can accurately diagnose their own failures when generating self-reflections for memory.
What would settle it
In the 16 identified ALFWorld frozen environments, check whether any new reflections generated after resets begin to mention the correct target object.
Figures


read the original abstract
Reflexion-style agents rely on self-generated reflections as memory, implicitly assuming that agents can accurately diagnose their own failures. We show that this assumption can fail systematically: across ALFWorld and HumanEval, agents store confident but incorrect interpretations of the task and continue acting on them across trials, even though the environment resets to the correct task each time. We call this failure mode memory confabulation and introduce the Reflection Repetition Rate (RRR), a log-based metric that detects repeated reliance on incorrect reflective content. Using RRR, we identify 16 frozen environments in ALFWorld, where 0 of 121 reflections mention the correct target object, and 4 analogous cases in HumanEval. Our mitigation replaces open-ended self-diagnosis with programmatic extraction of trajectory-level failure signals, increasing correct object mention from 0% to 86%, reducing RRR from 0.64 to 0.10, and solving 3 of 16 frozen ALFWorld environments, suggesting that reflective memory can reinforce false beliefs rather than correct them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript examines memory confabulation in Reflexion-style agents, demonstrating that self-generated reflections can store confident but incorrect task interpretations that persist across trials despite environment resets. Using the Reflection Repetition Rate (RRR) metric on logs, it identifies 16 frozen ALFWorld environments (0 of 121 reflections mention the correct target) and 4 analogous HumanEval cases; a mitigation replacing open-ended self-diagnosis with programmatic trajectory failure signals raises correct mentions to 86%, drops RRR from 0.64 to 0.10, and solves 3 additional ALFWorld environments.
Significance. If the results hold, the work identifies a load-bearing limitation in self-reflective LLM agents: reflective memory can reinforce false beliefs rather than correct them. The concrete empirical counts, log-derived RRR metric, and successful intervention provide falsifiable, reproducible evidence with direct implications for agent memory design. The absence of free parameters in the core metric and the environment-specific reporting strengthen the assessment.
major comments (2)
- [Methods/Evaluation] Methods/Evaluation: The manuscript reports the 0/121 count, RRR values, and 16-environment selection but does not detail reflection parsing rules, data exclusion criteria, or how 'frozen' environments were identified; without these, independent verification of the central claim that incorrect interpretations persist across resets is not possible.
- [RRR definition] § on RRR definition: The claim that RRR detects 'repeated reliance on incorrect reflective content' requires an explicit formula or pseudocode showing how repetition is quantified from logs (e.g., string matching thresholds or embedding similarity); the reported drop from 0.64 to 0.10 cannot be assessed for sensitivity to these choices.
minor comments (1)
- [Abstract/Results] The abstract and results tables would benefit from a short statement of the total number of trials/environments evaluated beyond the 16 frozen cases to contextualize the reported rates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and positive evaluation of the work. We address each major comment below and will revise the manuscript accordingly to improve reproducibility.
read point-by-point responses
-
Referee: [Methods/Evaluation] Methods/Evaluation: The manuscript reports the 0/121 count, RRR values, and 16-environment selection but does not detail reflection parsing rules, data exclusion criteria, or how 'frozen' environments were identified; without these, independent verification of the central claim that incorrect interpretations persist across resets is not possible.
Authors: We agree that these details are required for independent verification. The revised manuscript will add a dedicated Methods subsection specifying the reflection parsing rules (regular-expression extraction of object mentions from reflection text), data exclusion criteria (environments required to have complete logs across at least five trials), and the precise definition of 'frozen' environments (RRR > 0.5 with zero correct target mentions). The associated parsing code will be released with the camera-ready version. revision: yes
-
Referee: [RRR definition] § on RRR definition: The claim that RRR detects 'repeated reliance on incorrect reflective content' requires an explicit formula or pseudocode showing how repetition is quantified from logs (e.g., string matching thresholds or embedding similarity); the reported drop from 0.64 to 0.10 cannot be assessed for sensitivity to these choices.
Authors: We acknowledge that the original submission described RRR at a high level only. The revision will include the explicit formula RRR = (number of repeated incorrect reflections) / total reflections, with repetition defined via sentence-embedding cosine similarity > 0.85. Pseudocode for log processing and a brief sensitivity table (showing the 0.64-to-0.10 drop is stable for thresholds 0.75–0.90) will be added to the main text. revision: yes
Circularity Check
No significant circularity
full rationale
The paper is an empirical study that defines RRR as a log-based metric from observed reflections, reports concrete counts (e.g., 0/121 reflections), and evaluates a mitigation via direct intervention results. No equations, derivations, or self-citations reduce any central claim to its own inputs by construction; the work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reflexion-style agents rely on self-generated reflections as memory
invented entities (1)
-
memory confabulation
no independent evidence
Reference graph
Works this paper leans on
-
[1]
D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al
Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. Language models are few-shot learners. Advances in Neural Information Processing Systems, 33: 1877–1901,
1901
-
[2]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. d. O., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Memory for autonomous llm agents: Mechanisms, evaluation, and emerging frontiers
URL https: //arxiv.org/abs/2603.07670. Durante, Z., Gong, R., Sarkar, B., Wake, N., Taori, R., Tang, P., Lakshmikanth, S., Schulman, K., Milstein, A., V o, H., et al. An interactive agent foundation model. InPro- 7 Honest Lying: Understanding Memory Confabulation in Reflexive Agents ceedings of the Computer Vision and Pattern Recognition Conference, pp. 3...
-
[4]
Hurst, A., Lerer, A., Goucher, A. P., Perelman, A., Ramesh, A., Clark, A., Ostrow, A., Welihinda, A., Hayes, A., Radford, A., et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y ., Ishii, E., Bang, Y . J., Madotto, A., and Fung, P. Survey of halluci- nation in natural language generation.ACM Computing Surveys, 55(12):1–38, March 2023a. ISSN 1557-7341. doi: 10.1145/3571730. URL http://dx.doi.org/ 10.1145/3571730. Ji, Z., Lee, N., Frieske, R., Yu, T., Su, D., Xu, Y ., Ishii, E., B...
-
[6]
On faithfulness and factuality in abstractive summarization.arXiv preprint arXiv:2005.00661, 2020
Maynez, J., Narayan, S., Bohnet, B., and McDonald, R. On faithfulness and factuality in abstractive summarization. InProceedings of the 58th Annual Meeting of the Asso- ciation for Computational Linguistics, pp. 1906–1919, 2020a. Maynez, J., Narayan, S., Bohnet, B., and McDonald, R. On faithfulness and factuality in abstractive summa- rization, 2020b. URL...
-
[7]
A Fast Generic Sequence Matching Algorithm
URL https://arxiv. org/abs/0810.0264. Schnider, A. Spontaneous confabulation, reality monitor- ing, and the limbic system—a review.Brain Research Reviews, 36(2-3):150–160,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C
URL https: //openreview.net/forum?id=vAElhFcKW6. Yang, Z., Qi, P., Zhang, S., Bengio, Y ., Cohen, W., Salakhut- dinov, R., and Manning, C. D. Hotpotqa: A dataset for diverse, explainable multi-hop question answering. In Proceedings of the 2018 conference on empirical methods in natural language processing, pp. 2369–2380,
2018
-
[9]
ReAct: Synergizing Reasoning and Acting in Language Models
Yao, S., Zhao, J., Yu, D., Du, N., Shafran, I., Narasimhan, K., and Cao, Y . React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Feedback-Driven Execution for LLM-Based Binary Analysis
Zhang, X., Li, Q., and Wang, H. Feedback-driven ex- ecution for llm-based binary analysis.arXiv preprint arXiv:2604.15136,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Language Agent Tree Search Unifies Reasoning Acting and Planning in Language Models
URLhttps://arxiv.org/abs/2310.04406. 8 Honest Lying: Understanding Memory Confabulation in Reflexive Agents A. Prompt for Programmatic Extraction The following prompt replaces the standard Reflexion self-diagnosis prompt. Failure steps are extracted programmatically from the trajectory before this prompt is constructed. You will be given the history of a ...
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.