AnyMo: Scaling Any-Modality Conditional Motion Generation with Masked Modeling
Pith reviewed 2026-06-29 08:50 UTC · model grok-4.3
The pith
AnyMo enables high-fidelity human motion generation from arbitrary combinations of text, speech, music, and trajectory controls using a single masked modeling transformer.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
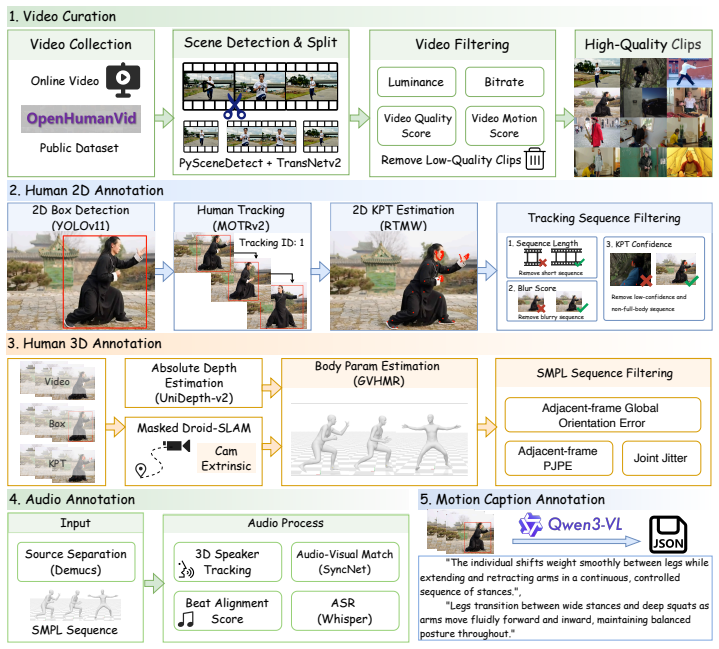
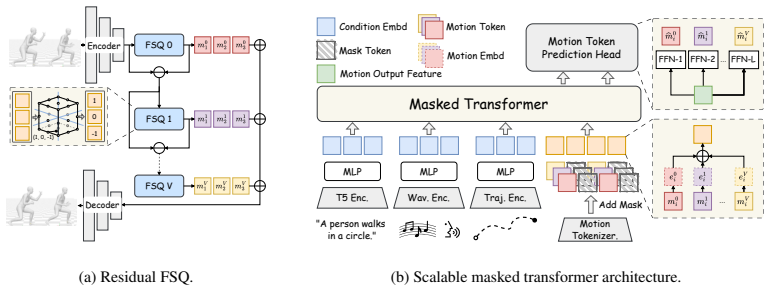
AnyMo pairs a Residual FSQ-based motion tokenizer with a scalable masked modeling transformer trained on the OmniHuMo dataset of over 5,000 hours of multimodal motion sequences, enabling high-quality synthesis controlled by any subset of the available modalities.
What carries the argument
The masked modeling transformer that reconstructs motion tokens while conditioned on arbitrary modality inputs.
If this is right
- A single model can accept mixed spatial controls such as trajectories together with stylistic controls such as text or music.
- No separate fine-tuning or architecture changes are required when the set of available control signals changes.
- Cross-modal interactions are learned directly through masked reconstruction on large aligned sequences.
Where Pith is reading between the lines
- The same masked modeling pattern could be tested on other sequential outputs such as full-body video or audio waveforms.
- Further scaling of the dataset size would be expected to improve fidelity and control precision in the same way observed for language models.
Load-bearing premise
The OmniHuMo dataset supplies precisely aligned multimodal annotations at a scale and quality sufficient for one transformer to generalize across arbitrary modality combinations without modality-specific fine-tuning.
What would settle it
A controlled test in which the model receives deliberately misaligned modality labels for a held-out combination and produces lower fidelity or less controllable outputs than single-modality baselines.
Figures


read the original abstract
Conditional human motion generation remains a fundamental challenge in computer vision and robotics. Despite significant progress, current methods are often constrained by fixed modality configurations and task-specific architectures, leaving cross-modal interactions and the scaling laws of multimodal-conditioned synthesis largely underexplored. A key bottleneck is the scarcity of large-scale modality-aligned motion data, limiting generalization across diverse control signals. In this work, we introduce OmniHuMo, a large-scale, high-quality dataset comprising over 5,000 hours of motion and 3.2 million sequences with precisely aligned multimodal annotations (e.g., text, speech, music, and trajectory). Leveraging OmniHuMo, we propose AnyMo, a unified multimodal framework combining a Residual FSQ-based motion tokenizer with a scalable masked modeling transformer, enabling high-quality motion synthesis under arbitrary modality combinations. Extensive experiments show that AnyMo achieves high-fidelity synthesis while offering flexible control over both spatial and stylistic attributes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniHuMo, a dataset of over 5,000 hours of motion across 3.2 million sequences with precisely aligned multimodal annotations (text, speech, music, trajectory), and AnyMo, a unified framework that combines a Residual FSQ motion tokenizer with a masked modeling transformer to support high-fidelity conditional motion synthesis under arbitrary modality combinations while providing flexible spatial and stylistic control.
Significance. If the dataset alignment precision and cross-modal generalization claims hold, the work would be significant for addressing data scarcity in multimodal motion generation and for demonstrating scalable masked modeling across modality combinations, with potential impact on flexible control in computer vision and robotics applications.
major comments (2)
- [Abstract] Abstract: The central claim that OmniHuMo supplies 'precisely aligned multimodal annotations' at sufficient scale and quality for a single transformer to generalize across arbitrary modality combinations without modality-specific fine-tuning is load-bearing, yet the manuscript supplies no description of the alignment procedure, no quantitative alignment metrics, and no ablation results showing performance when individual modalities are dropped or combined.
- [Abstract] Abstract: The assertion of 'high-fidelity synthesis' and 'flexible control over both spatial and stylistic attributes' under arbitrary modality combinations lacks supporting cross-modal ablation tables or comparisons to modality-specific baselines, which are required to substantiate that the Residual FSQ tokenizer plus masked transformer reliably learns the claimed interactions.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need to better substantiate the alignment claims and cross-modal performance assertions. We will revise the manuscript to include the requested details and experiments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that OmniHuMo supplies 'precisely aligned multimodal annotations' at sufficient scale and quality for a single transformer to generalize across arbitrary modality combinations without modality-specific fine-tuning is load-bearing, yet the manuscript supplies no description of the alignment procedure, no quantitative alignment metrics, and no ablation results showing performance when individual modalities are dropped or combined.
Authors: We agree that the alignment procedure and supporting metrics are essential to substantiate the central claims. While the manuscript describes the overall data curation process in Section 4, it does not provide a dedicated account of the alignment methodology or quantitative synchronization metrics. We will add a new subsection detailing the alignment procedure (including tools and protocols used for text-speech-music-trajectory synchronization) along with quantitative metrics such as temporal offset statistics and inter-annotator agreement scores. We will also include ablations that systematically drop or combine modalities to demonstrate generalization without modality-specific fine-tuning. revision: yes
-
Referee: [Abstract] Abstract: The assertion of 'high-fidelity synthesis' and 'flexible control over both spatial and stylistic attributes' under arbitrary modality combinations lacks supporting cross-modal ablation tables or comparisons to modality-specific baselines, which are required to substantiate that the Residual FSQ tokenizer plus masked transformer reliably learns the claimed interactions.
Authors: We acknowledge that the current experiments section would benefit from explicit cross-modal ablation tables and direct comparisons against modality-specific baselines to more rigorously support the high-fidelity and flexible control claims. We will add these tables, including quantitative results for all modality combinations versus single-modality baselines, along with qualitative examples demonstrating spatial and stylistic control. This will be incorporated into the revised experiments and supplementary material. revision: yes
Circularity Check
No significant circularity detected
full rationale
The provided abstract and description introduce OmniHuMo as a new dataset and AnyMo as a masked-modeling transformer framework without any equations, parameter-fitting steps presented as predictions, or derivation chains. No self-citations, uniqueness theorems, or ansatzes are invoked in the text to support core claims. The central contribution is an empirical construction (new data + architecture) rather than a mathematical reduction that collapses to its own inputs by definition. This matches the default expectation of a non-circular empirical paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Smpler-x: Scaling up expressive human pose and shape estimation.Advances in Neural Information Processing Systems, 36:11454–11468, 2023
Zhongang Cai, Wanqi Yin, Ailing Zeng, Chen Wei, Qingping Sun, Wang Yanjun, Hui En Pang, Haiyi Mei, Mingyuan Zhang, Lei Zhang, et al. Smpler-x: Scaling up expressive human pose and shape estimation.Advances in Neural Information Processing Systems, 36:11454–11468, 2023
2023
-
[3]
Bin Cao, Sipeng Zheng, Hao Luo, Boyuan Li, Jing Liu, and Zongqing Lu. Opent2m: No-frill motion generation with open-source, large-scale, high-quality data.arXiv preprint arXiv:2603.18623, 2026
-
[4]
Generating human motion in 3d scenes from text descriptions
Zhi Cen, Huaijin Pi, Sida Peng, Zehong Shen, Minghui Yang, Shuai Zhu, Hujun Bao, and Xiaowei Zhou. Generating human motion in 3d scenes from text descriptions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1855–1866, 2024
2024
-
[5]
Maskgit: Masked generative image transformer
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman. Maskgit: Masked generative image transformer. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11315–11325, 2022
2022
-
[6]
The language of motion: Unifying verbal and non- verbal language of 3d human motion
Changan Chen, Juze Zhang, Shrinidhi K Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, and Ehsan Adeli. The language of motion: Unifying verbal and non- verbal language of 3d human motion. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 6200–6211, 2025
2025
-
[7]
3d-speaker-toolkit: An open-source toolkit for multimodal speaker verification and diarization
Yafeng Chen, Siqi Zheng, Hui Wang, Luyao Cheng, Tinglong Zhu, Rongjie Huang, Chong Deng, Qian Chen, Shiliang Zhang, Wen Wang, et al. 3d-speaker-toolkit: An open-source toolkit for multimodal speaker verification and diarization. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
2025
-
[8]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[9]
Out of time: automated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: automated lip sync in the wild. InAsian conference on computer vision, pages 251–263. Springer, 2016
2016
-
[10]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding.arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[11]
Go to zero: Towards zero-shot motion generation with million-scale data
Ke Fan, Shunlin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, and Jingbo Wang. Go to zero: Towards zero-shot motion generation with million-scale data. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13336–13348, 2025
2025
-
[12]
Snapmogen: Human motion generation from expressive texts
Chuan Guo, Inwoo Hwang, Jian Wang, and Bing Zhou. Snapmogen: Human motion generation from expressive texts. InAdvances in Neural Information Processing Systems (NeurIPS), 2025
2025
-
[13]
Momask: Generative masked modeling of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked modeling of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024
1900
-
[14]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152–5161, 2022
2022
-
[15]
Catalin Ionescu, Dragos Papava, Vlad Olaru, and Cristian Sminchisescu. Human3. 6m: Large scale datasets and predictive methods for 3d human sensing in natural environments.TPAMI, 36(7):1325–1339, 2013. 10
2013
-
[16]
WavTokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling,
Shengpeng Ji, Ziyue Jiang, Wen Wang, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Xize Cheng, Zehan Wang, Ruiqi Li, et al. Wavtokenizer: an efficient acoustic discrete codec tokenizer for audio language modeling.arXiv preprint arXiv:2408.16532, 2024
-
[17]
Tao Jiang, Xinchen Xie, and Yining Li. Rtmw: Real-time multi-person 2d and 3d whole-body pose estimation.arXiv preprint arXiv:2407.08634, 2024
-
[18]
YOLOv11: An Overview of the Key Architectural Enhancements
Rahima Khanam and Muhammad Hussain. Yolov11: An overview of the key architectural enhancements.arXiv preprint arXiv:2410.17725, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
Openhumanvid: A large-scale high-quality dataset for enhancing human-centric video generation
Hui Li, Mingwang Xu, Yun Zhan, Shan Mu, Jiaye Li, Kaihui Cheng, Yuxuan Chen, Tan Chen, Mao Ye, Jingdong Wang, et al. Openhumanvid: A large-scale high-quality dataset for enhancing human-centric video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7752–7762, 2025
2025
-
[20]
Genmo: A generalist model for human motion
Jiefeng Li, Jinkun Cao, Haotian Zhang, Davis Rempe, Jan Kautz, Umar Iqbal, and Ye Yuan. Genmo: A generalist model for human motion. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 11766–11776, 2025
2025
-
[21]
Ai choreographer: Music conditioned 3d dance generation with aist++
Ruilong Li, Shan Yang, David A Ross, and Angjoo Kanazawa. Ai choreographer: Music conditioned 3d dance generation with aist++. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 13401–13412, 2021
2021
-
[22]
Morph: A motion-free physics optimization framework for human motion generation
Zhuo Li, Mingshuang Luo, Ruibing Hou, Xin Zhao, Hao Liu, Hong Chang, Zimo Liu, and Chen Li. Morph: A motion-free physics optimization framework for human motion generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14580– 14589, 2025
2025
-
[23]
Zeyu Ling, Bo Han, Shiyang Li, Jikang Cheng, Hongdeng Shen, and Changqing Zou. Ver- satilemotion: A unified framework for motion synthesis and comprehension.arXiv preprint arXiv:2411.17335, 2024
-
[24]
Disco: Disentangled implicit content and rhythm learning for diverse co-speech gestures synthesis
Haiyang Liu, Naoya Iwamoto, Zihao Zhu, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. Disco: Disentangled implicit content and rhythm learning for diverse co-speech gestures synthesis. InProceedings of the 30th ACM international conference on multimedia, pages 3764–3773, 2022
2022
-
[25]
Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Xuefei Zhe, Naoya Iwamoto, Bo Zheng, and Michael J Black. Emage: Towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1144–1154, 2024
2024
-
[26]
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J. Black. SMPL: A skinned multi-person linear model.ACM Transactions on Graphics, 34(6):248:1– 248:16, 2015
2015
-
[27]
Scamo: Exploring the scaling law in autoregressive motion generation model
Shunlin Lu, Jingbo Wang, Zeyu Lu, Ling-Hao Chen, Wenxun Dai, Junting Dong, Zhiyang Dou, Bo Dai, and Ruimao Zhang. Scamo: Exploring the scaling law in autoregressive motion generation model. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27872–27882, 2025
2025
-
[28]
AMASS: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Gerard Pons-Moll, and Michael J Black. AMASS: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 5442–5451, 2019
2019
-
[29]
Finite Scalar Quantization: VQ-VAE Made Simple
Fabian Mentzer, David Minnen, Eirikur Agustsson, and Michael Tschannen. Finite scalar quantization: Vq-vae made simple.arXiv preprint arXiv:2309.15505, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Temos: Generating diverse human motions from textual descriptions
Mathis Petrovich, Michael J Black, and Gül Varol. Temos: Generating diverse human motions from textual descriptions. InEuropean Conference on Computer Vision, pages 480–497. Springer, 2022. 11
2022
-
[31]
Maskcontrol: Spatio- temporal control for masked motion synthesis
Ekkasit Pinyoanuntapong, Muhammad Saleem, Korrawe Karunratanakul, Pu Wang, Hongfei Xue, Chen Chen, Chuan Guo, Junli Cao, Jian Ren, and Sergey Tulyakov. Maskcontrol: Spatio- temporal control for masked motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9955–9965, 2025
2025
-
[32]
Bamm: Bidirectional autoregressive motion model.arXiv preprint arXiv:2403.19435, 2024
Ekkasit Pinyoanuntapong, Muhammad Usama Saleem, Pu Wang, Minwoo Lee, Srijan Das, and Chen Chen. Bamm: Bidirectional autoregressive motion model.arXiv preprint arXiv:2403.19435, 2024
-
[33]
Mmm: Generative masked motion model
Ekkasit Pinyoanuntapong, Pu Wang, Minwoo Lee, and Chen Chen. Mmm: Generative masked motion model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1546–1555, 2024
2024
-
[34]
The KIT motion-language dataset
Matthias Plappert, Christian Mandery, and Tamim Asfour. The KIT motion-language dataset. Big Data, 4(4):236–252, dec 2016
2016
-
[35]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[36]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational conference on machine learning, pages 28492–28518. PMLR, 2023
2023
-
[37]
Sam 2: Segment anything in images and videos, 2024
Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, and Christoph Feichtenhofer. Sam 2: Segment anything in images and videos, 2024
2024
-
[38]
InProceedings of the AAAI conference on artificial intelligence, Vol
Davis Rempe, Mathis Petrovich, Ye Yuan, Haotian Zhang, Xue Bin Peng, Yifeng Jiang, Tingwu Wang, Umar Iqbal, David Minor, Michael de Ruyter, et al. Kimodo: Scaling controllable human motion generation.arXiv preprint arXiv:2603.15546, 2026
-
[39]
Rf-detr: Neural architecture search for real-time detection transformers, 2025
Isaac Robinson, Peter Robicheaux, Matvei Popov, Deva Ramanan, and Neehar Peri. Rf-detr: Neural architecture search for real-time detection transformers, 2025
2025
-
[40]
Hybrid transformers for music source separation
Simon Rouard, Francisco Massa, and Alexandre Défossez. Hybrid transformers for music source separation. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023
2023
-
[41]
World-grounded human motion recovery via gravity-view coordinates
Zehong Shen, Huaijin Pi, Yan Xia, Zhi Cen, Sida Peng, Zechen Hu, Hujun Bao, Ruizhen Hu, and Xiaowei Zhou. World-grounded human motion recovery via gravity-view coordinates. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
2024
-
[42]
Bailando: 3d dance generation by actor-critic gpt with choreographic memory
Li Siyao, Weijiang Yu, Tianpei Gu, Chunze Lin, Quan Wang, Chen Qian, Chen Change Loy, and Ziwei Liu. Bailando: 3d dance generation by actor-critic gpt with choreographic memory. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 11050–11059, 2022
2022
-
[43]
Transnet v2: An effective deep network architecture for fast shot transition detection
Tomás Soucek and Jakub Lokoc. Transnet v2: An effective deep network architecture for fast shot transition detection. InProceedings of the 32nd ACM International Conference on Multimedia, pages 11218–11221, 2024
2024
-
[44]
DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras.Advances in neural information processing systems, 2021
Zachary Teed and Jia Deng. DROID-SLAM: Deep Visual SLAM for Monocular, Stereo, and RGB-D Cameras.Advances in neural information processing systems, 2021
2021
-
[45]
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H. Bermano. Human motion diffusion model, 2022
2022
-
[46]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023. 12
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[47]
Edge: Editable dance generation from music
Jonathan Tseng, Rodrigo Castellon, and Karen Liu. Edge: Editable dance generation from music. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 448–458, 2023
2023
-
[48]
PySceneDetect.https://github.com/Breakthrough/PySceneDetect, 2024
Unknown. PySceneDetect.https://github.com/Breakthrough/PySceneDetect, 2024
2024
-
[49]
Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information processing systems, 30, 2017
2017
-
[50]
Attention is all you need.Advances in Neural Information Processing Systems, 2017
A Vaswani. Attention is all you need.Advances in Neural Information Processing Systems, 2017
2017
-
[51]
Tlcontrol: Trajectory and language control for human motion synthesis
Weilin Wan, Zhiyang Dou, Taku Komura, Wenping Wang, Dinesh Jayaraman, and Lingjie Liu. Tlcontrol: Trajectory and language control for human motion synthesis. InEuropean Conference on Computer Vision, pages 37–54. Springer, 2024
2024
-
[52]
Scaling large motion models with million-level human motions.arXiv preprint arXiv:2410.03311, 2024
Ye Wang, Sipeng Zheng, Bin Cao, Qianshan Wei, Weishuai Zeng, Qin Jin, and Zongqing Lu. Scaling large motion models with million-level human motions.arXiv preprint arXiv:2410.03311, 2024
-
[53]
arXiv preprint arXiv:2512.23464 (2025)
Yuxin Wen, Qing Shuai, Di Kang, Jing Li, Cheng Wen, Yue Qian, Ningxin Jiao, Changhai Chen, Weijie Chen, Yiran Wang, et al. Hy-motion 1.0: Scaling flow matching models for text-to-motion generation.arXiv preprint arXiv:2512.23464, 2025
-
[54]
Exploring video quality assessment on user generated contents from aesthetic and technical perspectives
Haoning Wu, Erli Zhang, Liang Liao, Chaofeng Chen, Jingwen Hou Hou, Annan Wang, Wenxiu Sun Sun, Qiong Yan, and Weisi Lin. Exploring video quality assessment on user generated contents from aesthetic and technical perspectives. InICCV, 2023
2023
-
[55]
Motionstreamer: Streaming motion generation via diffusion- based autoregressive model in causal latent space
Lixing Xiao, Shunlin Lu, Huaijin Pi, Ke Fan, Liang Pan, Yueer Zhou, Ziyong Feng, Xiaowei Zhou, Sida Peng, and Jingbo Wang. Motionstreamer: Streaming motion generation via diffusion- based autoregressive model in causal latent space. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10086–10096, October 2025
2025
-
[56]
arXiv preprint arXiv:2310.08580 (2023)
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation.arXiv preprint arXiv:2310.08580, 2023
-
[57]
Unifying flow, stereo and depth estimation.TPAMI, 2023
Haofei Xu, Jing Zhang, Jianfei Cai, Hamid Rezatofighi, Fisher Yu, Dacheng Tao, and Andreas Geiger. Unifying flow, stereo and depth estimation.TPAMI, 2023
2023
-
[58]
Generating holistic 3d human motion from speech
Hongwei Yi, Hualin Liang, Yifei Liu, Qiong Cao, Yandong Wen, Timo Bolkart, Dacheng Tao, and Michael J Black. Generating holistic 3d human motion from speech. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 469–480, 2023
2023
-
[59]
LLaDA-V: Large Language Diffusion Models with Visual Instruction Tuning
Zebin You, Shen Nie, Xiaolu Zhang, Jun Hu, Jun Zhou, Zhiwu Lu, Ji-Rong Wen, and Chongxuan Li. Llada-v: Large language diffusion models with visual instruction tuning.arXiv preprint arXiv:2505.16933, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Jianrong Zhang, Yangsong Zhang, Xiaodong Cun, Shaoli Huang, Yong Zhang, Hongwei Zhao, Hongtao Lu, and Xi Shen. T2m-gpt: Generating human motion from textual descriptions with discrete representations.arXiv preprint arXiv:2301.06052, 2023
-
[61]
Jinlu Zhang, Zixi Kang, and Yizhou Wang. Opendance: Multimodal controllable 3d dance generation using large-scale internet data.arXiv preprint arXiv:2506.07565, 2025
-
[62]
Motrv2: Bootstrapping end-to-end multi- object tracking by pretrained object detectors
Yuang Zhang, Tiancai Wang, and Xiangyu Zhang. Motrv2: Bootstrapping end-to-end multi- object tracking by pretrained object detectors. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22056–22065, 2023
2023
-
[63]
Yuhong Zhang, Jing Lin, Ailing Zeng, Guanlin Wu, Shunlin Lu, Yurong Fu, Yuanhao Cai, Ruimao Zhang, Haoqian Wang, and Lei Zhang. Motion-x++: A large-scale multimodal 3d whole-body human motion dataset.arXiv preprint arXiv:2501.05098, 2025
-
[64]
arXiv preprint arXiv:2503.06955 (2025)
Zeyu Zhang, Yiran Wang, Wei Mao, Danning Li, Rui Zhao, Biao Wu, Zirui Song, Bohan Zhuang, Ian Reid, and Richard Hartley. Motion anything: Any to motion generation.arXiv preprint arXiv:2503.06955, 2025. 13
-
[65]
LLaDA 1.5: Variance-Reduced Preference Optimization for Large Language Diffusion Models
Fengqi Zhu, Rongzhen Wang, Shen Nie, Xiaolu Zhang, Chunwei Wu, Jun Hu, Jun Zhou, Jianfei Chen, Yankai Lin, Ji-Rong Wen, et al. Llada 1.5: Variance-reduced preference optimization for large language diffusion models.arXiv preprint arXiv:2505.19223, 2025. 14 Appendix This Appendix is orginazed into the following sections: Section A present additional relate...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
Generate 1-3 motion caption, containing no more than 30 words
-
[67]
The person walks forward, then bends the upper body forward and reaches down with the right hand to pick up an object
Use temporal connectors (then, while, following) to link sub-motions into one continuous narrative. For example, "The person walks forward, then bends the upper body forward and reaches down with the right hand to pick up an object"
-
[68]
Sitting cross-legged
Use precise verbs (e.g., "Sitting cross-legged", "Wave left hand" .etc) rather than generic ones (e.g., "moves")
-
[69]
If the person is performing a noticeable action, such as rowing, playing golf, stand on one's head, etc., please add a description of the corresponding action, for example: The person is performing a golf swing, with a backswing followed by a powerful forward swing
-
[70]
If the person is interacting with an object, please describe the interaction in detail, for example: The person is sitting on a chair, then stands up and walks forward to pick up a box, holding it with both hands
-
[71]
If the person is dancing, output a general description of the dance style, for example: This person is dancing ballet, lifting both hands over their head, turning their body, and the tips of their feet are lifted up
-
[72]
motion_caption
If no movement is detected, return an empty list: {"motion_caption": [] }. When writing motion captions, you can focus on one or more of the following aspects for each description:
-
[73]
The person raises their right arm above their head, then quickly lowers it while stepping forward with the left foot
Body movements: Involved joints or limbs, posture changes, movement speed, and motion trajectories. For example, "The person raises their right arm above their head, then quickly lowers it while stepping forward with the left foot"
-
[74]
The person is walking forward with a slight lean to the left, taking long strides and swinging their arms
Global movement: Body orientation, movement direction, gait characteristics, and high-level action types (e.g., walking, running, jumping). For example, "The person is walking forward with a slight lean to the left, taking long strides and swinging their arms". Return ONLY valid JSON with this exact structure: {"motion_caption": [string1, string2, ...]} F...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.