Source-Grounded Semantic Reinforcement Learning for Low-Resource Target-Language Generation
Pith reviewed 2026-06-29 07:31 UTC · model grok-4.3
The pith
Source-grounded RL with a cross-lingual reranker improves semantic grounding and factual coverage in low-resource target-language generation after a recovery stage restores fluency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
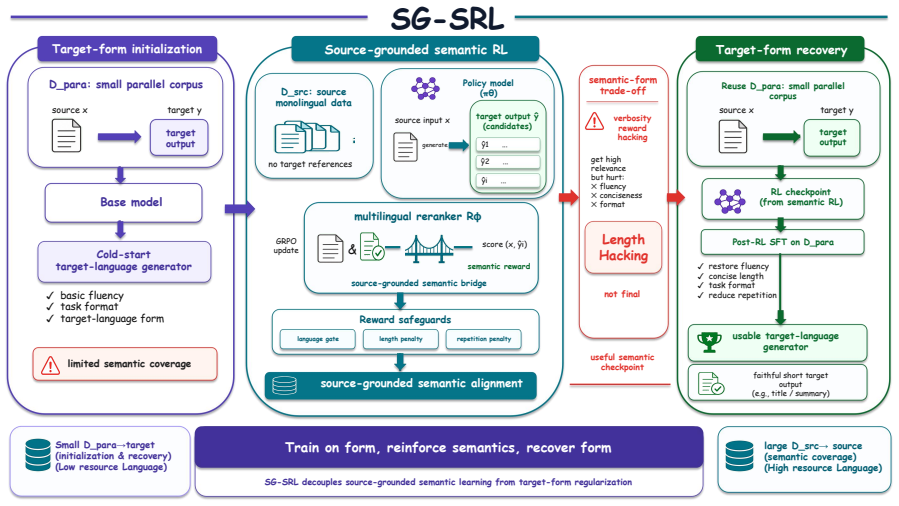
SG-SRL performs reference-free RL on source-language monolingual data using a cross-lingual reranker that scores semantic relevance between the source input and the target-language generation. This produces improved semantic grounding and factual coverage over cold-start SFT on Chinese-to-Thai, despite inducing verbosity-based reward hacking; a recovery stage that uses a small parallel corpus then restores fluency, conciseness, and task format while preserving the semantic gains. Analyses further show generalization to long-form transfer and that an encoder-based semantic reward can substitute for an LLM-based reranker.
What carries the argument
The cross-lingual reranker that supplies a reference-free semantic reward signal for RL on source monolingual data, followed by a recovery stage on limited parallel data.
If this is right
- Semantic grounding and factual coverage improve over standard SFT on Chinese-to-Thai generation.
- The method extends to long-form transfer tasks while retaining its semantic advantages.
- Encoder-based rewards can replace LLM-based rerankers in realistic low-resource settings.
- The recovery stage corrects verbosity and format issues induced by the RL stage without erasing semantic improvements.
Where Pith is reading between the lines
- The same source-to-target semantic reward pattern could be tested on other generation tasks such as summarization where source monolingual data greatly exceeds parallel data.
- If the reranker signal remains reliable across more distant language pairs, the need for large parallel corpora in multilingual training pipelines would decrease.
- Applying the recovery stage with even smaller parallel sets or synthetic data would test how little target-side data is truly required to stabilize the method.
Load-bearing premise
The cross-lingual reranker gives an accurate semantic relevance signal between source input and target generation without any references, and the recovery stage keeps those semantic gains without adding new biases.
What would settle it
A human evaluation on the Chinese-to-Thai test set that finds no improvement in factual coverage or semantic accuracy for SG-SRL outputs relative to cold-start SFT would show the central claim does not hold.
Figures

read the original abstract
Low-resource target-language generation is often limited by scarce parallel data, while high-resource source-language monolingual data is abundant but difficult to use with standard supervised fine-tuning. We propose Source-Grounded Semantic Reinforcement Learning (SG-SRL), a resource-utilization framework that converts source-language monolingual data into cross-lingual semantic supervision for target-language generation. SG-SRL performs reference-free reinforcement learning (RL) on source-language data using a cross-lingual semantic reward model, instantiated by a cross-lingual reranker that scores the semantic relevance between the source input and the target-language generation. While this induces severe verbosity-based reward hacking, a lightweight recovery stage using a small parallel corpus restores fluency, conciseness, and task format while preserving the semantic gains. Experiments on Chinese-to-Thai generation show that SG-SRL improves semantic grounding and factual coverage over cold-start SFT. Additional analyses on long-form transfer and Tibetan embedding-based rewards clarify the generalization behavior of SG-SRL and show that an encoder-based semantic reward can substitute for an LLM-based reranker in a realistic low-resource language setting.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Source-Grounded Semantic Reinforcement Learning (SG-SRL) to address low-resource target-language generation by converting abundant source-language monolingual data into cross-lingual semantic supervision. It performs reference-free RL using a cross-lingual reranker as semantic reward on source inputs, followed by a lightweight recovery stage on small parallel data to mitigate verbosity-based reward hacking and restore fluency/conciseness while preserving semantic gains. Experiments on Chinese-to-Thai generation report improved semantic grounding and factual coverage over cold-start SFT, with additional analyses on long-form transfer and Tibetan embedding-based rewards.
Significance. If the preservation of semantic gains through the recovery stage is demonstrated, the framework provides a practical method for leveraging high-resource monolingual source data in low-resource settings, reducing dependence on large parallel corpora and offering a template for reference-free semantic RL that could generalize via alternative reward models such as embeddings.
major comments (2)
- [Experiments] Experiments section: the central claim that SG-SRL improves semantic grounding over cold-start SFT requires that the recovery stage preserves the RL-induced gains without erosion or new biases, yet no quantitative before/after comparison of semantic metrics (factual coverage, semantic relevance) immediately post-RL versus post-recovery is reported; this omission is load-bearing because the recovery uses parallel data that could independently shift the output distribution.
- [Abstract] Abstract and method description: the cross-lingual reranker is posited to supply an accurate reference-free semantic relevance signal between source input and target generation, but no validation, accuracy metrics, or error analysis of the reranker on the Chinese-to-Thai pair (or held-out data) is provided; without this, the RL stage risks optimizing toward an unverified reward, undermining attribution of any observed gains to SG-SRL.
minor comments (2)
- The size of the 'small parallel corpus' used in the recovery stage and the number of recovery fine-tuning steps should be stated explicitly to support reproducibility.
- Tables or figures showing semantic metric trajectories across RL and recovery stages would clarify whether gains are preserved; current presentation leaves this implicit.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will incorporate additional quantitative analyses and validation in the revision to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim that SG-SRL improves semantic grounding over cold-start SFT requires that the recovery stage preserves the RL-induced gains without erosion or new biases, yet no quantitative before/after comparison of semantic metrics (factual coverage, semantic relevance) immediately post-RL versus post-recovery is reported; this omission is load-bearing because the recovery uses parallel data that could independently shift the output distribution.
Authors: We agree this comparison is necessary to fully substantiate preservation of gains. In the revised manuscript we will add a direct before/after evaluation reporting factual coverage and semantic relevance scores on the same test set immediately after the RL stage and after the recovery stage. This will quantify any erosion or distributional shift and allow readers to assess the recovery stage's effect independently of the RL gains. revision: yes
-
Referee: [Abstract] Abstract and method description: the cross-lingual reranker is posited to supply an accurate reference-free semantic relevance signal between source input and target generation, but no validation, accuracy metrics, or error analysis of the reranker on the Chinese-to-Thai pair (or held-out data) is provided; without this, the RL stage risks optimizing toward an unverified reward, undermining attribution of any observed gains to SG-SRL.
Authors: We acknowledge the absence of explicit reranker validation for the Chinese-to-Thai pair. In revision we will include an appendix with accuracy metrics (e.g., precision@K on held-out pairs) and a brief error analysis of the reranker on Chinese-Thai data. This will provide evidence that the reward signal is reliable and support attribution of observed improvements to SG-SRL rather than reward noise. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes SG-SRL as an RL framework that applies a cross-lingual reranker reward to source monolingual data, followed by a recovery stage on small parallel data. No equations, fitted parameters, or self-referential definitions appear that would reduce any claimed prediction or result to the inputs by construction. The central empirical claims rest on external components (reranker, parallel corpus) and comparisons to cold-start SFT rather than internal loops or self-citation chains. The derivation is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
https://huggingface.co/blog/ smollm3
SmolLM3: smol, multilingual, long-context reasoner. https://huggingface.co/blog/ smollm3. Luiz Bonifacio, Vitor Jeronymo, Hugo Queiroz Abonizio, Israel Campiotti, Marzieh Fadaee, Roberto Lotufo, and Rodrigo Nogueira. 2021. mMARCO: A multilingual version of the MS MARCO passage ranking dataset.arXiv preprint arXiv:2108.13897. Alexis Conneau, Kartikay Khand...
-
[2]
Understanding r1-zero-like training: A critical perspective. InConference on Language Modeling (COLM). Rodrigo Nogueira and Kyunghyun Cho. 2019. Pas- sage re-ranking with BERT.arXiv preprint arXiv:1901.04085. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, Jo...
work page internal anchor Pith review Pith/arXiv arXiv 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.