How to Relieve Distribution Shifts in Semantic Segmentation for Off-Road Environments
Pith reviewed 2026-06-29 06:54 UTC · model grok-4.3
The pith
ST-Seg expands source styles and regularizes textures to reduce distribution shifts in off-road semantic segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
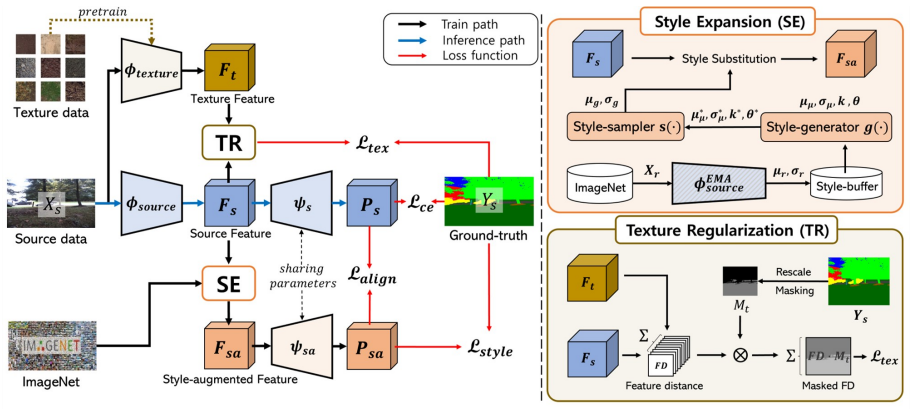
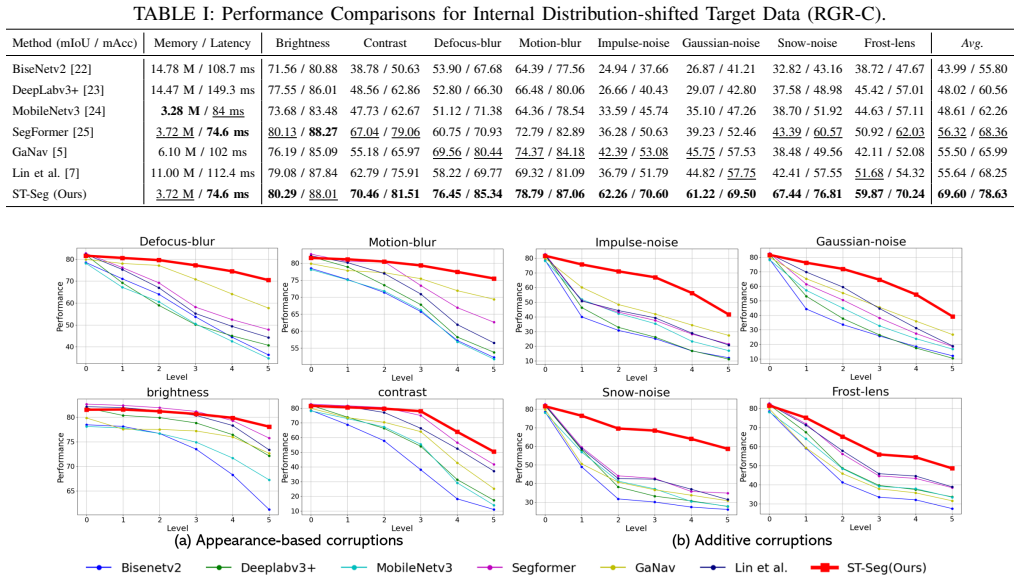
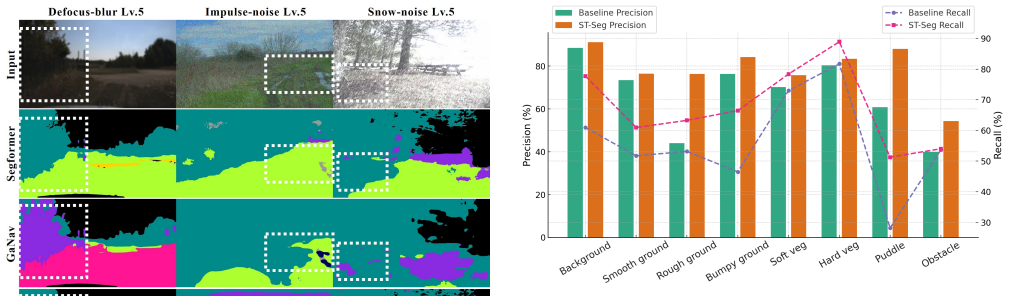
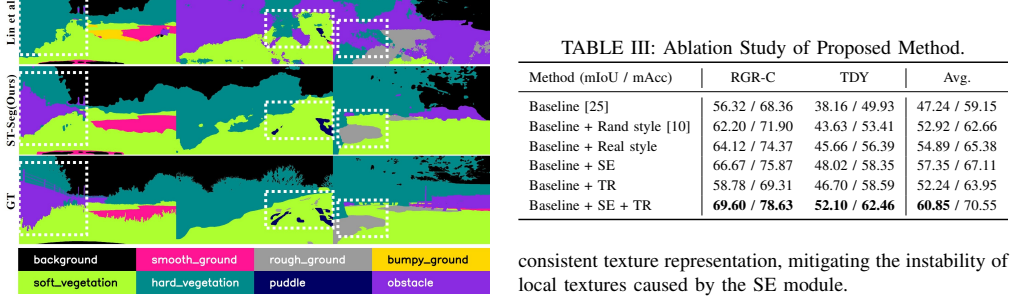
ST-Seg expands the source distribution through style expansion (SE) that generates diverse realistic styles to augment the limited style information of the source domain, combined with texture regularization (TR) that stabilizes local texture representation affected by style-augmented learning through a deep texture manifold, resulting in substantial improvements over existing methods across various distribution-shifted target domains.
What carries the argument
Style expansion (SE) and texture regularization (TR) in the ST-Seg framework: SE broadens domain coverage by generating diverse styles, while TR stabilizes texture features via a deep texture manifold.
If this is right
- Models trained with ST-Seg generalize to unseen off-road domains without needing target-domain examples.
- Navigation systems experience fewer failures from inaccurate traversable-region predictions caused by domain shifts or sensor corruption.
- The approach works across multiple kinds of distribution shifts common in rough terrain.
- Real-world deployment of semantic segmentation for autonomous off-road vehicles becomes more practical.
Where Pith is reading between the lines
- The same style-plus-texture approach might help segmentation models handle other unstructured environments such as construction sites or disaster zones.
- ST-Seg could lower reliance on methods that require collecting or adapting to target data at deployment time.
- Further tests on night-time or weather-altered off-road footage would show whether the texture manifold holds up under additional corruptions.
Load-bearing premise
Generating diverse realistic styles and then stabilizing textures through a deep manifold will reliably improve performance on unseen off-road domains without creating new errors.
What would settle it
A new distribution-shifted off-road test set where ST-Seg produces equal or lower accuracy than a standard baseline, or where the generated styles introduce visible artifacts that degrade labels.
Figures


read the original abstract
Semantic segmentation is crucial for autonomous navigation in off-road environments, enabling precise classification of surroundings to identify traversable regions. However, distinctive factors inherent to off-road conditions, such as source-target domain discrepancies and sensor corruption from rough terrain, can result in distribution shifts that alter the data differently from the trained conditions. This often leads to inaccurate semantic label predictions and subsequent failures in navigation tasks. To address this, we propose ST-Seg, a novel framework that expands the source distribution through style expansion (SE) and texture regularization (TR). Unlike prior methods that implicitly apply generalization within a fixed source distribution, ST-Seg offers an intuitive approach for distribution shift. Specifically, SE broadens domain coverage by generating diverse realistic styles, augmenting the limited style information of the source domain. TR stabilizes local texture representation affected by style-augmented learning through a deep texture manifold. Experiments across various distribution-shifted target domains demonstrate the effectiveness of ST-Seg, with substantial improvements over existing methods. These results highlight the robustness of ST-Seg, enhancing the real-world applicability of semantic segmentation for off-road navigation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ST-Seg, a framework for semantic segmentation in off-road autonomous navigation that addresses distribution shifts via style expansion (SE), which generates diverse realistic styles to broaden the source domain, and texture regularization (TR), which stabilizes local texture representations through a learned deep texture manifold. Unlike prior implicit generalization methods within a fixed source distribution, ST-Seg explicitly expands domain coverage and anchors texture features. Experiments on multiple distribution-shifted target domains are reported to yield substantial gains over existing approaches, supported by implementation details, ablation studies, and cross-domain evaluations.
Significance. If the empirical results hold, the work offers a practical contribution to robust semantic segmentation for off-road robotics, where terrain-induced sensor corruption and domain gaps frequently degrade performance. The explicit separation of style broadening from texture stabilization provides an interpretable alternative to standard domain adaptation techniques. Credit is due for including ablation studies and cross-domain testing that directly test the central mechanisms.
minor comments (2)
- Abstract: the claim of 'substantial improvements' is stated without any numerical values, baselines, or error statistics, which reduces the abstract's utility as a standalone summary even though the full manuscript supplies these details.
- The description of the deep texture manifold in TR would benefit from an explicit statement of its training objective and dimensionality to allow readers to assess potential overfitting risks on limited off-road data.
Simulated Author's Rebuttal
We thank the referee for the positive summary of ST-Seg, the recognition of its practical value for off-road robotics, and the recommendation of minor revision. The report correctly identifies the roles of style expansion and texture regularization. No major comments appear in the provided report, so we have no specific points requiring rebuttal or clarification at this stage. We remain available to address any additional minor suggestions during revision.
Circularity Check
No significant circularity detected
full rationale
The paper proposes ST-Seg as a framework using style expansion (SE) to broaden source styles and texture regularization (TR) via a deep texture manifold to stabilize representations. No equations, fitted parameters, or derivation steps are described that reduce a claimed prediction or result to an input by construction. The central claims rest on empirical improvements across shifted domains, supported by implementation details, ablations, and cross-domain experiments rather than self-referential definitions or self-citation chains. The method is presented as an intuitive augmentation approach without invoking uniqueness theorems or renaming known results as novel derivations. This is a standard empirical ML paper whose validity hinges on external benchmarks, not internal circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Adaptive robot traversability estimation based on self- supervised online continual learning in unstructured environments,
H.-S. Yoon, J.-H. Hwang, C. Kim, E. I. Son, S.-W. Yoo, and S.- W. Seo, “Adaptive robot traversability estimation based on self- supervised online continual learning in unstructured environments,” IEEE Robotics and Automation Letters, vol. 9, no. 6, pp. 4902–4909, 2024
2024
-
[2]
R. R. Murphy, S. Tadokoro, and A. Kleiner,Disaster Robotics, pp. 1577–1604. Cham: Springer International Publishing, 2016
2016
-
[3]
Advances in agriculture robotics: A state-of-the-art review and challenges ahead,
L. F. P. Oliveira, A. P. Moreira, and M. F. Silva, “Advances in agriculture robotics: A state-of-the-art review and challenges ahead,” Robotics, vol. 10, no. 2, 2021
2021
-
[4]
A brief survey on semantic segmen- tation with deep learning,
S. Hao, Y . Zhou, and Y . Guo, “A brief survey on semantic segmen- tation with deep learning,”Neurocomputing, vol. 406, pp. 302–321, 2020
2020
-
[5]
Ga-nav: Efficient terrain segmenta- tion for robot navigation in unstructured outdoor environments,
T. Guan, D. Kothandaraman, R. Chandra, A. J. Sathyamoorthy, K. Weerakoon, and D. Manocha, “Ga-nav: Efficient terrain segmenta- tion for robot navigation in unstructured outdoor environments,”IEEE Robotics and Automation Letters, vol. 7, no. 3, pp. 8138–8145, 2022
2022
-
[6]
Offseg: A semantic segmentation framework for off-road driving,
K. Viswanath, K. Singh, P. Jiang, P. Sujit, and S. Saripalli, “Offseg: A semantic segmentation framework for off-road driving,” in2021 IEEE 17th international conference on automation science and engineering (CASE), pp. 354–359, IEEE, 2021
2021
-
[7]
Real-time segmentation of unstructured environments by combining domain generalization and attention mechanisms,
N. Lin, W. Zhao, S. Liang, and M. Zhong, “Real-time segmentation of unstructured environments by combining domain generalization and attention mechanisms,”Sensors, vol. 23, no. 13, p. 6008, 2023
2023
-
[8]
Unsupervised domain adaptation by back- propagation,
Y . Ganin and V . Lempitsky, “Unsupervised domain adaptation by back- propagation,” inProceedings of the 32nd International Conference on International Conference on Machine Learning - V olume 37, ICML’15, p. 1180–1189, JMLR.org, 2015
2015
-
[9]
Arbitrary style transfer in real-time with adaptive instance normalization,
X. Huang and S. Belongie, “Arbitrary style transfer in real-time with adaptive instance normalization,” inProceedings of the IEEE international conference on computer vision, pp. 1501–1510, 2017
2017
-
[10]
Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data,
X. Yue, Y . Zhang, S. Zhao, A. Sangiovanni-Vincentelli, K. Keutzer, and B. Gong, “Domain randomization and pyramid consistency: Simulation-to-real generalization without accessing target domain data,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 2100–2110, 2019
2019
-
[11]
Texture Networks: Feed-forward Synthesis of Textures and Stylized Images
D. Ulyanov, V . Lebedev, A. Vedaldi, and V . Lempitsky, “Texture networks: Feed-forward synthesis of textures and stylized images,” arXiv preprint arXiv:1603.03417, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[12]
Style follows content: On the microgenesis of art perception,
M. D. Augustin, H. Leder, F. Hutzler, and C.-C. Carbon, “Style follows content: On the microgenesis of art perception,”Acta psychologica, vol. 128, no. 1, pp. 127–138, 2008
2008
-
[13]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” in2009 IEEE conference on computer vision and pattern recognition, pp. 248–255, Ieee, 2009
2009
-
[14]
Stratified sampling,
R. Singh, N. S. Mangat, R. Singh, and N. S. Mangat, “Stratified sampling,”Elements of survey sampling, pp. 102–144, 1996
1996
-
[15]
Deep texture manifold for ground terrain recognition,
J. Xue, H. Zhang, and K. Dana, “Deep texture manifold for ground terrain recognition,” inProceedings of the IEEE Conference on Com- puter Vision and Pattern Recognition, pp. 558–567, 2018
2018
-
[16]
A rugd dataset for autonomous navigation and visual perception in unstructured outdoor environments,
M. Wigness, S. Eum, J. G. Rogers, D. Han, and H. Kwon, “A rugd dataset for autonomous navigation and visual perception in unstructured outdoor environments,” inInternational Conference on Intelligent Robots and Systems (IROS), 2019
2019
-
[17]
Rellis-3d dataset: Data, benchmarks and analysis,
P. Jiang, P. Osteen, M. Wigness, and S. Saripalli, “Rellis-3d dataset: Data, benchmarks and analysis,” 2020
2020
-
[18]
A Fine-Grained Dataset and its Efficient Semantic Segmentation for Unstructured Driv- ing Scenarios,
K. A. Metzger, P. Mortimer, and H.-J. Wuensche, “A Fine-Grained Dataset and its Efficient Semantic Segmentation for Unstructured Driv- ing Scenarios,” inInternational Conference on Pattern Recognition (ICPR2020), (Milano, Italy (Virtual Conference)), Jan. 2021
2021
-
[19]
Deep multispectral semantic scene understanding of forested environments using multi- modal fusion,
A. Valada, G. Oliveira, T. Brox, and W. Burgard, “Deep multispectral semantic scene understanding of forested environments using multi- modal fusion,” inInternational Symposium on Experimental Robotics (ISER), 2016
2016
-
[20]
Real-time semantic mapping for autonomous off-road navigation,
D. Maturana, P.-W. Chou, M. Uenoyama, and S. Scherer, “Real-time semantic mapping for autonomous off-road navigation,” inField and Service Robotics, pp. 335–350, Springer, 2018
2018
-
[21]
The goose dataset for perception in unstructured environments,
P. Mortimer, R. Hagmanns, M. Granero, T. Luettel, J. Petereit, and H.-J. Wuensche, “The goose dataset for perception in unstructured environments,” 2024
2024
-
[22]
Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation,
C. Yu, C. Gao, J. Wang, G. Yu, C. Shen, and N. Sang, “Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation,”International Journal of Computer Vision, vol. 129, pp. 3051–3068, 2021
2021
-
[23]
Encoder-decoder with atrous separable convolution for semantic image segmentation,
L.-C. Chen, Y . Zhu, G. Papandreou, F. Schroff, and H. Adam, “Encoder-decoder with atrous separable convolution for semantic image segmentation,” inProceedings of the European conference on computer vision (ECCV), pp. 801–818, 2018
2018
-
[24]
Searching for mo- bilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevan,et al., “Searching for mo- bilenetv3,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 1314–1324, 2019
2019
-
[25]
Segformer: Simple and efficient design for semantic segmentation with transformers,
E. Xie, W. Wang, Z. Yu, A. Anandkumar, J. M. Alvarez, and P. Luo, “Segformer: Simple and efficient design for semantic segmentation with transformers,”Advances in neural information processing sys- tems, vol. 34, pp. 12077–12090, 2021
2021
-
[26]
Uncertainty-aware perception models for off- road autonomous unmanned ground vehicles,
Z. Yang, Y . Tan, S. Sen, J. Reimann, J. Karigiannis, M. Yousefhussien, and N. Virani, “Uncertainty-aware perception models for off- road autonomous unmanned ground vehicles,”arXiv preprint arXiv:2209.11115, 2022
-
[27]
Revisiting batch normalization for practical domain adaptation,
Y . Li, N. Wang, J. Shi, J. Liu, and X. Hou, “Revisiting batch normalization for practical domain adaptation,” 2017
2017
-
[28]
Three ways to improve semantic segmentation with self-supervised depth estimation,
L. Hoyer, D. Dai, Y . Chen, A. K ¨oring, S. Saha, and L. V . Gool, “Three ways to improve semantic segmentation with self-supervised depth estimation,”CoRR, vol. abs/2012.10782, 2020
-
[29]
Deep gaussian mixture models,
C. Viroli and G. J. McLachlan, “Deep gaussian mixture models,” Statistics and Computing, vol. 29, pp. 43–51, 2019
2019
-
[30]
Casella and R
G. Casella and R. L. Berger,Statistical Inference. Pacific Grove, CA: Duxbury Press, 2nd ed., 2002
2002
-
[31]
An essay towards solving a problem in the doctrine of chances,
T. Bayes, “An essay towards solving a problem in the doctrine of chances,”Biometrika, vol. 45, no. 3-4, pp. 296–315, 1958
1958
-
[32]
Distilling the knowledge in a neural network,
G. Hinton, O. Vinyals, and J. Dean, “Distilling the knowledge in a neural network,” inNIPS Deep Learning and Representation Learning Workshop, 2015
2015
-
[33]
Multi-feature co-learning for image inpainting,
J. Lin, Y .-G. Wang, W. Tang, and A. Li, “Multi-feature co-learning for image inpainting,” in2022 26th International Conference on Pattern Recognition (ICPR), pp. 296–302, IEEE, 2022
2022
-
[34]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Commun. ACM, vol. 60, p. 84–90, may 2017
2017
-
[35]
Benchmarking Neural Network Robustness to Common Corruptions and Surface Variations
D. Hendrycks and T. G. Dietterich, “Benchmarking neural network robustness to common corruptions and surface variations,”arXiv preprint arXiv:1807.01697, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[36]
Frodobots-2k (revision 1abf1b8),
FrodoBots Lab, “Frodobots-2k (revision 1abf1b8),” 2024
2024
-
[37]
MMSegmentation: Openmmlab semantic seg- mentation toolbox and benchmark
M. Contributors, “MMSegmentation: Openmmlab semantic seg- mentation toolbox and benchmark.”https://github.com/ open-mmlab/mmsegmentation, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.