CONCAT: Consensus- and Confidence-Driven Ad Hoc Teaming for Efficient LLM-Based Multi-Agent Systems
Pith reviewed 2026-06-29 00:10 UTC · model grok-4.3
The pith
By clustering agents on their answers and pruning talks via a confidence-based heuristic, multi-agent LLM systems cut latency in half without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
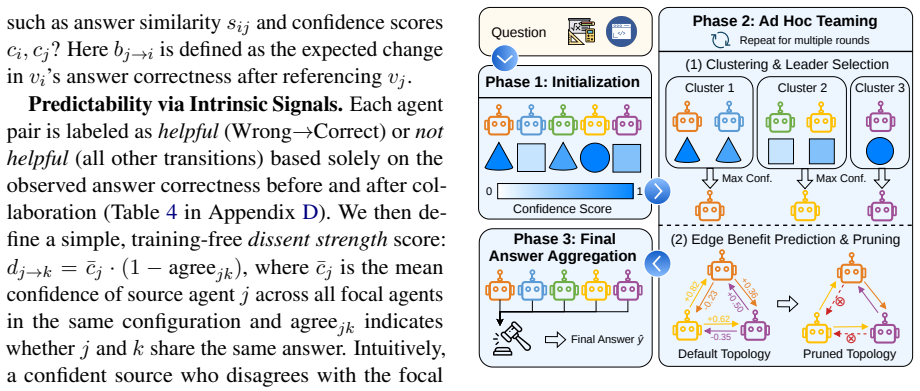
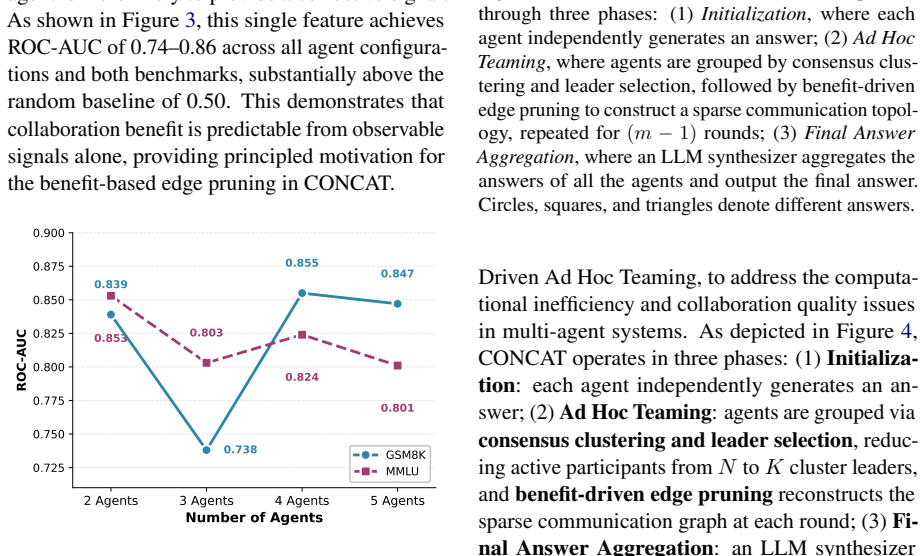
CONCAT clusters agents according to their initial answers, selects cluster leaders by reported confidence, and applies a Theory of Mind heuristic to forecast collaboration benefits between every pair of leaders from their answers and scores. Communications predicted to deliver little benefit are then evicted, producing an ad hoc network that delivers up to 2.02 times higher accuracy-per-latency than full LLM-Debate while cutting average latency by 50.1 percent on Qwen2.5-14B-Instruct, all without task-specific training and outperforming certain training-aware baselines on three benchmarks.
What carries the argument
The Theory of Mind heuristic that estimates pairwise collaboration benefits from leaders' answers and confidence values to decide which communications to keep.
If this is right
- Accuracy divided by latency reaches up to 2.02 times the value of LLM-Debate across three models and three benchmarks.
- Average latency drops by 50.1 percent on Qwen2.5-14B-Instruct while performance stays competitive.
- The method beats training-aware approaches such as AgentDropout on the reported efficiency metric.
- No task-specific training is required, preserving applicability across different LLMs and benchmarks.
Where Pith is reading between the lines
- The same clustering-plus-pruning pattern could be tested on agent teams that include non-LLM components such as symbolic planners.
- If the heuristic remains stable when agent count grows, the approach might support real-time team reorganization in long-running multi-agent workflows.
- The reported gains suggest that similar confidence signals might reduce message volume in other distributed reasoning systems that currently rely on complete graphs.
Load-bearing premise
The heuristic function based on the Theory of Mind accurately predicts the collaboration benefits between every two leaders according to their answers and confidence.
What would settle it
An experiment in which teams formed by the heuristic show lower accuracy than either the full-communication baseline or teams formed by random eviction of the same number of links.
Figures


read the original abstract
Although large language model (LLM) based multi-agent systems (MAS) show their capability to solve complex tasks and achieve higher performance over single agent systems, they lead to huge computational overheads because of heavy communication between agents. Previous research has made efforts to train a sparse multi-agent graph or fine-tune a planner to orchestrate the workflow better. However, such extra training processes introduce computational costs and limit MAS to specific domains, therefore compromising their generalizability. In this paper, we propose CONCAT, a training-free multi-agent collaboration framework based on CONsensus and Confidence-driven Ad hoc Teaming to efficiently organize agent interactions. Specifically, agents are clustered based on their initial answers, and leaders of each cluster are selected based on the agents' confidence. Then, a heuristic function based on the Theory of Mind is designed to predict the collaboration benefits between every two leaders according to their answers and confidence. Finally, an ad hoc multi-agent network is organized after evicting a percentage of communications based on the predicted benefits. Experiments across three LLMs and three benchmarks show that CONCAT achieves up to 2.02x higher efficiency (accuracy/latency ratio) than LLM-Debate and outperforms training-aware methods such as AgentDropout, while reducing average latency by 50.1% on Qwen2.5-14B-Instruct, without any task-specific training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CONCAT, a training-free multi-agent collaboration framework for LLM-based systems. Agents are clustered based on initial answers and leaders selected by confidence; a Theory of Mind heuristic then predicts pairwise collaboration benefits to evict a percentage of communications and form an ad hoc network. Experiments across three LLMs and three benchmarks report up to 2.02x higher accuracy/latency efficiency than LLM-Debate, outperformance versus training-aware baselines such as AgentDropout, and a 50.1% average latency reduction on Qwen2.5-14B-Instruct.
Significance. If the reported efficiency gains hold and the ToM heuristic is shown to be the operative mechanism, the work would be significant for enabling generalizable, low-overhead multi-agent LLM systems without task-specific training or fine-tuning costs. The training-free design and concrete latency/accuracy trade-off improvements address a practical bottleneck in current MAS deployments.
major comments (2)
- [Abstract / Experiments] Abstract and Experiments section: the central efficiency claims (2.02x ratio, 50.1% latency reduction) are presented without accompanying details on baseline implementations, number of runs, error bars, or statistical tests. These elements are load-bearing for verifying that the observed gains exceed those from generic communication reduction.
- [Method] Method description: the ToM-based heuristic for predicting collaboration benefits between leader pairs is the key innovation enabling selective eviction. Without an ablation that isolates this heuristic from simpler clustering or random eviction, it remains unclear whether the reported gains are attributable to the specific benefit-prediction mechanism rather than reduced communication volume alone.
minor comments (1)
- [Method] Notation for the heuristic function and clustering procedure could be formalized with explicit equations or pseudocode to improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [Abstract / Experiments] Abstract and Experiments section: the central efficiency claims (2.02x ratio, 50.1% latency reduction) are presented without accompanying details on baseline implementations, number of runs, error bars, or statistical tests. These elements are load-bearing for verifying that the observed gains exceed those from generic communication reduction.
Authors: We agree that additional experimental details are needed to substantiate the efficiency claims. In the revised manuscript, we will expand the Experiments section to specify baseline implementations (reproduced following the original papers), report results averaged over 5 independent runs with standard error bars, and include statistical tests (paired t-tests) comparing CONCAT against baselines. These additions will help confirm that gains are not attributable solely to generic communication reduction. We will also note these details briefly in the abstract if space allows. revision: yes
-
Referee: [Method] Method description: the ToM-based heuristic for predicting collaboration benefits between leader pairs is the key innovation enabling selective eviction. Without an ablation that isolates this heuristic from simpler clustering or random eviction, it remains unclear whether the reported gains are attributable to the specific benefit-prediction mechanism rather than reduced communication volume alone.
Authors: We acknowledge that an ablation isolating the Theory of Mind heuristic would strengthen the paper. We will add this analysis in the revised version, including comparisons of CONCAT against (i) a variant using random eviction at the same communication reduction rate and (ii) a variant using only initial clustering without the ToM benefit prediction. This will clarify the contribution of the heuristic beyond volume reduction alone. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper describes CONCAT as a training-free heuristic that clusters agents by initial answers, selects leaders by confidence, applies a Theory of Mind-based benefit prediction to evict communications, and organizes an ad hoc network. No equations, fitted parameters, or self-citations appear in the provided text that would reduce any claimed prediction or result to the method's own inputs by construction. The efficiency gains are presented as outcomes of experimental evaluation against baselines rather than definitional or self-referential equivalences. The derivation chain remains independent of the patterns that trigger circularity flags.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Baker, Julian Jara-Ettinger, Rebecca Saxe, and Joshua B
Chris L. Baker, Julian Jara-Ettinger, Rebecca Saxe, and Joshua B. Tenenbaum. 2017. https://doi.org/10.1038/s41562-017-0064 Rational quantitative attribution of beliefs, desires and percepts in human mentalizing . Nature Human Behaviour, 1:0064
-
[2]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, and 39 others. 2021. https://doi.org/10.48550/arXiv.2107.03374 Evaluating L...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374 2021
-
[3]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Logan Cross, Violet Xiang, Agam Bhatia, Daniel Yamins, and Nick Haber. 2025. Hypothetical minds: Scaffolding theory of mind for multi-agent tasks with large language models. In International Conference on Learning Representations, volume 2025, pages 6507--6546
2025
-
[5]
Yufan Dang, Chen Qian, Xueheng Luo, Jingru Fan, Zihao Xie, Ruijie Shi, Weize Chen, Cheng Yang, Xiaoyin Che, Ye Tian, Xuantang Xiong, Lei Han, Zhiyuan Liu, and Maosong Sun. 2025. https://doi.org/10.48550/arXiv.2505.19591 Multi- Agent Collaboration via Evolving Orchestration . Preprint, arXiv:2505.19591
-
[6]
DeepSeek-AI , Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, and 181 others. 2025. https://doi.org/10.48550/arXiv.2501.12948 DeepSeek-R1 : Incentivizing Reasoning Capability in LLMs via Reinfo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[7]
Tenenbaum, and Igor Mordatch
Yilun Du, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. 2024. Improving Factuality and Reasoning in Language Models through Multiagent Debate . In Forty-First International Conference on Machine Learning
2024
-
[8]
Adam Fourney, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Erkang, Zhu, Friederike Niedtner, Grace Proebsting, Griffin Bassman, Jack Gerrits, Jacob Alber, Peter Chang, Ricky Loynd, Robert West, Victor Dibia, Ahmed Awadallah, Ece Kamar, Rafah Hosn, and Saleema Amershi. 2024. https://doi.org/10.48550/arXiv.2411.04468 Magentic- One : A General...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2411.04468 2024
-
[9]
Carlin, Hal S
Andrew Gelman, John B. Carlin, Hal S. Stern, David B. Dunson, Aki Vehtari, and Donald B. Rubin. 2013. Bayesian Data Analysis, 3rd edition. CRC Press
2013
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle , Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mitra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others. 2024. https://doi.org/10.48550/arXiv.2407.21783 T...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[11]
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
Taicheng Guo, Xiuying Chen, Yaqi Wang, Ruidi Chang, Shichao Pei, Nitesh V. Chawla, Olaf Wiest, and Xiangliang Zhang. 2024. https://arxiv.org/abs/2402.01680 Large language model based multi-agents: A survey of progress and challenges . arXiv preprint arXiv:2402.01680
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring Massive Multitask Language Understanding . In International Conference on Learning Representations
2020
-
[13]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Zili Wang, Steven Ka Shing Yau, Zijuan Lin, Liyang Zhou, Chenyu Ran, Lingfeng Xiao, Chenglin Wu, and J \"u rgen Schmidhuber. 2023. MetaGPT : Meta Programming for A Multi-Agent Collaborative Framework . In The Twelfth International Conference on Learning Representations
2023
-
[14]
Ronald A. Howard. 1966. https://doi.org/10.1109/TSSC.1966.300074 Information value theory . IEEE Transactions on Systems Science and Cybernetics, 2(1):22--26
-
[15]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, and 1 others. 2024. Openai o1 system card. arXiv preprint arXiv:2412.16720
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Adam Kostka and Jaros aw A Chudziak. 2025. Evaluating theory of mind and internal beliefs in llm-based multi-agent systems. In International Conference on Computational Collective Intelligence, pages 18--32. Springer
2025
-
[17]
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. 2023. Efficient memory management for large language model serving with pagedattention. In Proceedings of the 29th symposium on operating systems principles, pages 611--626
2023
-
[18]
Huao Li, Yu Chong, Simon Stepputtis, Joseph Campbell, Dana Hughes, Michael Lewis, and Katia Sycara. 2023. https://arxiv.org/abs/2310.10701 Theory of mind for multi-agent collaboration via large language models . In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP)
-
[19]
Xiaoxi Li, Jiajie Jin, Guanting Dong, Hongjin Qian, Yongkang Wu, Ji-Rong Wen, Yutao Zhu, and Zhicheng Dou. 2025. https://doi.org/10.48550/arXiv.2504.21776 WebThinker : Empowering Large Reasoning Models with Deep Research Capability . Preprint, arXiv:2504.21776
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.21776 2025
-
[20]
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. https://doi.org/10.48550/arXiv.2311.12983 GAIA : A benchmark for General AI Assistants . Preprint, arXiv:2311.12983
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2311.12983 2023
-
[21]
Chunjiang Mu, Ya Zeng, Qiaosheng Zhang, Kun Shao, Chen Chu, Hao Guo, Danyang Jia, Zhen Wang, and Shuyue Hu. 2026. Adaptive theory of mind for llm-based multi-agent coordination. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 29608--29616
2026
-
[22]
David Premack and Guy Woodruff. 1978. https://doi.org/10.1017/S0140525X00076512 Does the chimpanzee have a theory of mind? Behavioral and Brain Sciences, 1(4):515--526
-
[23]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, Juyuan Xu, Dahai Li, Zhiyuan Liu, and Maosong Sun. 2024. https://arxiv.org/abs/2307.07924 ChatDev : Communicative agents for software development . In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Haojun Shi, Suyu Ye, Xinyu Fang, Chuanyang Jin, Leyla Isik, Yen-Ling Kuo, and Tianmin Shu. 2025. Muma-tom: Multi-modal multi-agent theory of mind. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 1510--1519
2025
-
[25]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. https://arxiv.org/abs/2303.11366 Reflexion: Language agents with verbal reinforcement learning . In Advances in Neural Information Processing Systems (NeurIPS)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[26]
Chenglei Si, Zhe Gan, Zhengyuan Yang, Shuohang Wang, Jianfeng Wang, Jordan Lee Boyd-Graber , and Lijuan Wang. 2022. Prompting GPT-3 To Be Reliable . In The Eleventh International Conference on Learning Representations
2022
-
[27]
Amos Tversky and Daniel Kahneman. 1974. https://doi.org/10.1126/science.185.4157.1124 Judgment under uncertainty: Heuristics and biases . Science, 185(4157):1124--1131
-
[28]
Vllm-Project. 2025. https://github.com/vllm-project/vllm-ascend Vllm-ascend
2025
-
[29]
Le, Ed H
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc V. Le, Ed H. Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2022. Self- Consistency Improves Chain of Thought Reasoning in Language Models . In The Eleventh International Conference on Learning Representations
2022
-
[30]
Wong, and Rui Wang
Yiming Wang, Pei Zhang, Baosong Yang, Derek F. Wong, and Rui Wang. 2024. Latent Space Chain-of-Embedding Enables Output-free LLM Self-Evaluation . In The Thirteenth International Conference on Learning Representations
2024
-
[31]
Zhexuan Wang, Yutong Wang, Xuebo Liu, Liang Ding, Miao Zhang, Jie Liu, and Min Zhang. 2025 a . https://doi.org/10.18653/v1/2025.acl-long.1170 AgentDropout : Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Vo...
-
[32]
Zihao Wang, Shaofei Cai, Anji Liu, Yonggang Jin, Jinbing Hou, Bowei Zhang, Haowei Lin, Zhaofeng He, Zilong Zheng, Yaodong Yang, Xiaojian Ma, and Yitao Liang. 2025 b . https://doi.org/10.1109/TPAMI.2024.3511593 JARVIS-1 : Open-World Multi-Task Agents With Memory-Augmented Multimodal Language Models . IEEE Transactions on Pattern Analysis and Machine Intell...
-
[33]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[34]
Zhiyuan Weng, Guikun Chen, and Wenguan Wang. 2024. Do as We Do , Not as You Think : The Conformity of Large Language Models . In The Thirteenth International Conference on Learning Representations
2024
-
[35]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, and 40 others. 2024. Qwen2 technical report. arXiv preprint arXiv:2407.10671
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
Hancheng Ye, Zhengqi Gao, Mingyuan Ma, Qinsi Wang, Yuzhe Fu, Ming-Yu Chung, Yueqian Lin, Zhijian Liu, Jianyi Zhang, Danyang Zhuo, and Yiran Chen. 2025 a . KVCOMM : Online Cross-context KV-cache Communication for Efficient LLM-based Multi-agent Systems . In The Thirty-ninth Annual Conference on Neural Information Processing Systems
2025
-
[37]
Rui Ye, Shuo Tang, Rui Ge, Yaxin Du, Zhenfei Yin, Siheng Chen, and Jing Shao. 2025 b . MAS-GPT : Training LLMs to Build LLM-based Multi-Agent Systems . In Forty-Second International Conference on Machine Learning
2025
-
[38]
Enhao Zhang, Erkang Zhu, Gagan Bansal, Adam Fourney, Hussein Mozannar, and Jack Gerrits. 2025 a . https://doi.org/10.48550/arXiv.2507.08944 Optimizing Sequential Multi-Step Tasks with Parallel LLM Agents . Preprint, arXiv:2507.08944
-
[39]
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Xu Yu, and Tianlong Chen. 2024. Cut the Crap : An Economical Communication Pipeline for LLM-based Multi-Agent Systems . In The Thirteenth International Conference on Learning Representations
2024
-
[40]
Wentao Zhang, Liang Zeng, Yuzhen Xiao, Yongcong Li, Ce Cui, Yilei Zhao, Rui Hu, Yang Liu, Yahui Zhou, and Bo An. 2025 b . https://doi.org/10.48550/arXiv.2506.12508 AgentOrchestra : A Hierarchical Multi-Agent Framework for General-Purpose Task Solving . Preprint, arXiv:2506.12508
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.12508 2025
- [41]
-
[42]
Xiaochen Zhu, Caiqi Zhang, Tom Stafford, Nigel Collier, and Andreas Vlachos. 2025. https://doi.org/10.18653/v1/2025.acl-long.195 Conformity in Large Language Models . In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics ( Volume 1: Long Papers ) , pages 3854--3872, Vienna, Austria. Association for Computational Linguistics
-
[43]
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and J \"u rgen Schmidhuber. 2024. GPTSwarm : Language Agents as Optimizable Graphs . In Forty-First International Conference on Machine Learning
2024
-
[44]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[45]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.