Decoding Strategies for Diffusion-Based ASR: A Systematic Evaluation of Confidence-Based Thresholding
Pith reviewed 2026-06-29 05:43 UTC · model grok-4.3
The pith
Static confidence thresholding lets diffusion-based ASR match autoregressive accuracy while running faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
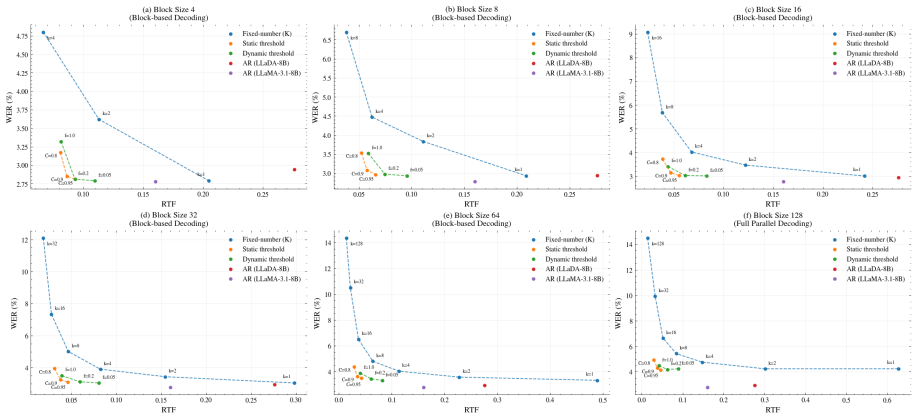
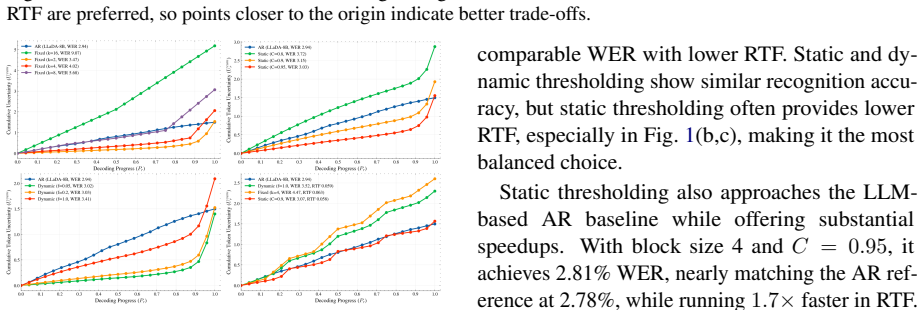
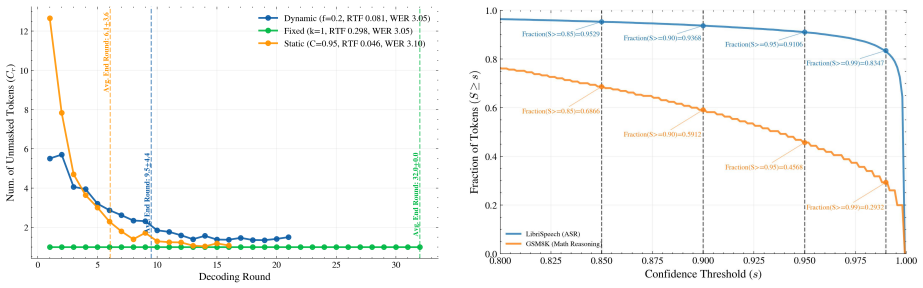
In diffusion language model ASR, a static confidence threshold that accepts tokens whose probability exceeds a fixed value in each parallel round matches the accuracy of autoregressive decoding while delivering higher efficiency; this holds because most tokens in speech recognition reach high confidence after only a few diffusion steps, so reliable tokens can be finalized immediately and only difficult tokens continue to later rounds.
What carries the argument
Static confidence thresholding, which finalizes any token whose model probability exceeds a preset value after each diffusion round and leaves the rest for further iterations.
If this is right
- Threshold-based schemes reduce the number of diffusion rounds needed for most tokens compared with fixed-number acceptance.
- Static thresholding achieves parity with autoregressive word error rate at lower latency.
- Negative log-likelihood uncertainty serves as a usable proxy for measuring per-round progress without external labels.
- Dynamic thresholding offers an alternative that can adapt per token but shows no clear accuracy gain over the simpler static version.
Where Pith is reading between the lines
- The same early-confidence pattern might appear in other short-sequence tasks such as machine translation of spoken language, allowing similar static thresholds.
- Real-time ASR deployments could adopt static thresholding to cut latency while keeping the same error rate as current autoregressive systems.
- If the early-confidence property is domain-specific to speech, the finding would not transfer directly to long-form text generation with diffusion models.
Load-bearing premise
In ASR, most tokens reach high model confidence after only a few diffusion rounds, so a fixed threshold can safely accept them without harming final accuracy.
What would settle it
A controlled test on the same DLM ASR setup in which a large fraction of tokens remain below the static threshold even after many rounds, causing the threshold strategy to lose accuracy relative to autoregressive decoding.
Figures
read the original abstract
While LLM-based Automatic Speech Recognition (ASR) achieves high accuracy, its speed is limited by sequential autoregressive decoding. Diffusion Language Models (DLMs) offer a parallel alternative, yet their decoding strategies remain under-explored in ASR contexts. This paper analyzes three decoding schemes for DLM-based ASR: fixed-number, static confidence threshold, and dynamic confidence threshold. We propose measuring round-wise accuracy using Negative Log-Likelihood-based uncertainty as a proxy for decoding progress. Our results show that both threshold-based strategies significantly outperform fixed-number schemes in accuracy and speed. We attribute this to a property unique to ASR: most tokens reach high confidence early, allowing reliable ones to be harvested aggressively while leaving only difficult tokens for later rounds. Notably, the static-threshold strategy matches the accuracy of autoregressive decoding while offering superior efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates three decoding strategies for diffusion language models applied to automatic speech recognition (ASR): fixed-number decoding, static confidence thresholding, and dynamic confidence thresholding. Using negative log-likelihood as a proxy for uncertainty, it reports that both threshold-based methods outperform fixed-number decoding in accuracy and speed. The static-threshold strategy is claimed to match the accuracy of autoregressive decoding while providing superior efficiency. The authors attribute the advantage to an ASR-specific property that most tokens reach high confidence early, enabling aggressive harvesting of reliable tokens.
Significance. If the empirical comparisons hold under proper controls, the work provides actionable guidance on efficient parallel decoding for DLM-based ASR and demonstrates that static thresholding can close the accuracy gap with autoregressive baselines. The use of round-wise accuracy measurement is a positive methodological contribution for tracking decoding progress.
major comments (1)
- [Results/Discussion] Results/Discussion (attribution paragraph following the main performance claims): The mechanistic explanation that threshold strategies succeed because "most tokens reach high confidence early" is presented without supporting data such as per-token confidence trajectories, histograms of the round at which tokens first exceed the threshold, or any cross-domain comparison. This premise is invoked to explain both the performance gains over fixed-number schemes and the ASR-specific success of the method; its absence leaves the interpretation of the reported accuracy/efficiency numbers without the stated basis.
minor comments (2)
- [Abstract] Abstract and experimental sections: No details are provided on the datasets used, model sizes, number of runs, or statistical significance tests for the accuracy and efficiency comparisons; these must be added for reproducibility.
- [Methods] Notation: The definition and exact computation of the Negative Log-Likelihood-based uncertainty proxy should be stated explicitly (including any temperature or scaling parameters) rather than referenced only as a proxy.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for the constructive comment on strengthening the mechanistic interpretation. We address the point below.
read point-by-point responses
-
Referee: [Results/Discussion] Results/Discussion (attribution paragraph following the main performance claims): The mechanistic explanation that threshold strategies succeed because "most tokens reach high confidence early" is presented without supporting data such as per-token confidence trajectories, histograms of the round at which tokens first exceed the threshold, or any cross-domain comparison. This premise is invoked to explain both the performance gains over fixed-number schemes and the ASR-specific success of the method; its absence leaves the interpretation of the reported accuracy/efficiency numbers without the stated basis.
Authors: We agree that the attribution would be more robust with explicit supporting evidence. In the revised manuscript we will add (i) histograms of the decoding round at which each token first exceeds the chosen confidence threshold (aggregated over the test set), (ii) representative per-token negative-log-likelihood trajectories across rounds, and (iii) a short cross-domain comparison using a non-ASR diffusion language-modeling task where such early-confidence behavior is absent. These additions will directly substantiate the claimed ASR-specific property and clarify why static thresholding closes the accuracy gap with autoregressive decoding. revision: yes
Circularity Check
Empirical evaluation paper with no circular derivation
full rationale
The paper reports experimental comparisons of fixed-number, static-threshold, and dynamic-threshold decoding for diffusion-based ASR models. All performance claims (accuracy, efficiency, round-wise progress via NLL uncertainty) are grounded in direct measurements on held-out data rather than any mathematical derivation, fitted parameter, or self-referential quantity. The explanatory sentence attributing success to an ASR-specific early-confidence property is presented as post-hoc interpretation and does not reduce any reported result to itself by construction. No self-citations, ansatzes, or uniqueness theorems are invoked as load-bearing steps. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen technical report. arXiv preprint arXiv:2309.16609. Heli Ben-Hamu, Itai Gat, Daniel Severo, Niklas Nolte, and Brian Karrer. Accelerated sampling from masked diffusion models via entropy bounded un- masking. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems. Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T Freeman
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
InICASSP 2024-2024 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), pages 13521–13525
Salm: Speech-augmented language model with in- context learning for speech recognition and transla- tion. InICASSP 2024-2024 IEEE International Con- ference on Acoustics, Speech and Signal Processing (ICASSP), pages 13521–13525. IEEE. Yunfei Chu, Jin Xu, Xiaohuan Zhou, Qian Yang, Shil- iang Zhang, Zhijie Yan, Chang Zhou, and Jingren Zhou
2024
-
[3]
Qwen-Audio: Advancing Universal Audio Understanding via Unified Large-Scale Audio-Language Models
Qwen-audio: Advancing universal audio understanding via unified large-scale audio- language models.arXiv preprint arXiv:2311.07919. Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168. Hengyu Fu, Baihe Huang, Virginia Adams, Charles Wang, Venkat Srinivasan, and Jiantao Jiao
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
From bits to rounds: Parallel decoding with explo- ration for diffusion language models.arXiv preprint arXiv:2511.21103. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, and 1 others
-
[6]
The llama 3 herd of models.arXiv preprint arXiv:2407.21783. Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdel- rahman Mohamed
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Large Language Diffusion Models
Large language dif- fusion models.arXiv preprint arXiv:2502.09992. Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
1: Better and faster open whisper-style speech models based on e-branchformer.Interspeech 2024, pages 352–356
Owsm v3. 1: Better and faster open whisper-style speech models based on e-branchformer.Interspeech 2024, pages 352–356. Vineel Pratap, Andros Tjandra, Bowen Shi, Paden Tomasello, Arun Babu, Sayani Kundu, Ali Elkahky, Zhaoheng Ni, Apoorv Vyas, Maryam Fazel-Zarandi, and 1 others
2024
-
[9]
wav2vec: Unsupervised pre- training for speech recognition. InProc. Interspeech 2019, pages 3465–3469. Mengqi Wang, Zhan Liu, Zengrui Jin, Guangzhi Sun, Chao Zhang, and Philip C Woodland
2019
-
[10]
Audio- conditioned diffusion llms for asr and deliberation processing.arXiv preprint arXiv:2509.16622. Chengyue Wu, Hao Zhang, Shuchen Xue, Zhijian Liu, Shizhe Diao, Ligeng Zhu, Ping Luo, Song Han, and Enze Xie
-
[11]
Fast-dLLM: Training-free Acceleration of Diffusion LLM by Enabling KV Cache and Parallel Decoding
Fast-dllm: Training-free accelera- tion of diffusion llm by enabling kv cache and parallel decoding.arXiv preprint arXiv:2505.22618. Jian Wu, Yashesh Gaur, Zhuo Chen, Long Zhou, Yi- meng Zhu, Tianrui Wang, Jinyu Li, Shujie Liu, Bo Ren, Linquan Liu, and 1 others
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Dream 7B: Diffusion Large Language Models
Dream 7b: Diffusion large language models. arXiv preprint arXiv:2508.15487. Runpeng Yu, Xinyin Ma, and Xinchao Wang
work page internal anchor Pith review Pith/arXiv arXiv
- [13]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.