SAFE-Pruner: Semantic Attention-Guided Future-Aware Token Pruning for Efficient Vision-Language-Action Manipulation
Pith reviewed 2026-06-29 08:38 UTC · model grok-4.3
The pith
Semantic attention consistency across steps lets SAFE-Pruner forecast deep-layer token importance and prune VLA models safely.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
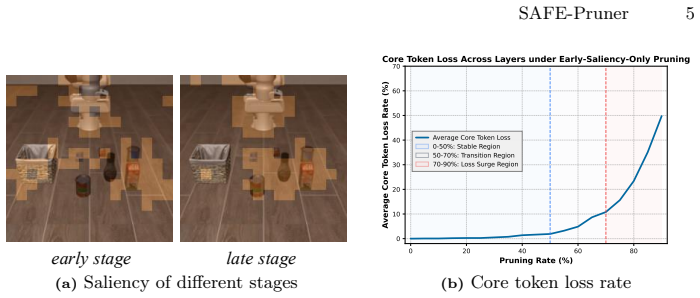
By identifying semantic attention consistency, the tendency that VLA models concentrate attention probability mass on the same semantic entity across execution steps, the method forecasts token saliency in deep layers to guide pruning, preventing premature removal of critical tokens and producing more stable acceleration than shallow-layer methods.
What carries the argument
semantic attention consistency, the observed concentration of attention on the same entity across steps, used to forecast deep-layer token saliency for pruning decisions
If this is right
- Up to 1.89x inference speedup with success-rate degradation below 1.7 percent
- Outperforms prior pruning methods by up to 1.9 percent in the same settings
- Works as a plug-and-play addition to existing VLA models
- Validated across simulation and real-world robotic manipulation tasks
- Adaptive subtask division improves forecast accuracy when attention shifts abruptly
Where Pith is reading between the lines
- The same consistency pattern could appear in other sequential multimodal models, supporting similar pruning outside robotics
- Lower compute could allow VLA policies to run on embedded hardware with tighter power budgets
- Attention stability may vary with task type, so pruning gains could differ between navigation and fine manipulation
- Forecasting from even earlier layers might compound the speedup if the consistency observation generalizes
Load-bearing premise
Attention remains concentrated on the same semantic entities from early layers through deep layers in a way that early cues reliably predict later needs.
What would settle it
A VLA task where early-layer attention forecasts cause removal of tokens required by later layers, producing success-rate drops above 5 percent on standard benchmarks.
Figures




read the original abstract
Real-time inference of vision-language-action (VLA) models is essential for robotic control. While visual token pruning has shown strong potential for accelerating inference, most existing methods mainly base pruning decisions on shallow-layer cues and risk discarding visual information required by deep layers. To address this issue, we propose SAFE-Pruner, a plug-and-play pruning framework that incorporates attention cues of future layers into pruning decisions. Specifically, we identify semantic attention consistency, the tendency that VLA models concentrate their attention probability mass on the same semantic entity across execution steps. Based on this observation, we design a forward-looking strategy to forecast the token saliency in deep layers, which prevents the premature removal of critical tokens and leads to more stable acceleration. We further introduce an adaptive subtask division strategy to detect abrupt attention shifts, thereby improving forecasting accuracy and pruning reliability. Extensive experiments in simulation and real-world settings demonstrate that our method achieves up to 1.89x speedup with a minimal degradation in success rate of less than 1.7%, while outperforming state-of-the-art methods by up to 1.9%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAFE-Pruner, a plug-and-play token pruning framework for vision-language-action (VLA) models. It observes semantic attention consistency (concentration on the same semantic entity across steps) to forecast deep-layer token saliency and avoid premature pruning of critical tokens, augmented by an adaptive subtask division strategy to detect abrupt attention shifts. Experiments in simulation and real-world robotic manipulation report up to 1.89× speedup with <1.7% success-rate degradation while outperforming state-of-the-art pruning methods by up to 1.9%.
Significance. If the reported speedups and bounded performance loss hold under the stated conditions, the method offers a practical efficiency gain for real-time VLA inference in robotics. The forward-looking pruning and adaptive division are targeted responses to a known limitation of shallow-layer pruning; the plug-and-play design lowers the barrier to adoption.
major comments (1)
- [Abstract; §3 (method description of consistency and forecasting)] The central performance claims (1.89× speedup, <1.7% success-rate drop) rest on the reliability of semantic attention consistency for forecasting deep-layer saliency. The manuscript introduces adaptive subtask division to handle abrupt shifts but provides no explicit ablation or stress tests under distribution shift (e.g., added visual distractors) or extended task horizons; if consistency degrades, the saliency forecast becomes inaccurate and the degradation bound may not hold. This is load-bearing for the main empirical contribution.
minor comments (1)
- [Abstract] The abstract states quantitative results but does not name the specific VLA backbone, number of tokens pruned per layer, or exact baseline implementations; adding these details would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on the robustness of our core assumption. We agree that additional validation under distribution shifts and longer horizons would strengthen the empirical claims and will incorporate the requested experiments in the revision.
read point-by-point responses
-
Referee: [Abstract; §3 (method description of consistency and forecasting)] The central performance claims (1.89× speedup, <1.7% success-rate drop) rest on the reliability of semantic attention consistency for forecasting deep-layer saliency. The manuscript introduces adaptive subtask division to handle abrupt shifts but provides no explicit ablation or stress tests under distribution shift (e.g., added visual distractors) or extended task horizons; if consistency degrades, the saliency forecast becomes inaccurate and the degradation bound may not hold. This is load-bearing for the main empirical contribution.
Authors: We acknowledge that the manuscript does not include explicit ablations with added visual distractors or on substantially extended task horizons. Our current evaluation covers diverse simulation and real-world manipulation tasks that implicitly test varying conditions, and the adaptive subtask division is designed to detect attention shifts. However, to directly address the load-bearing concern, the revised version will add targeted stress-test ablations introducing visual distractors and evaluating longer-horizon sequences to confirm that the consistency-based forecasting remains reliable and the reported performance bounds hold. revision: yes
Circularity Check
No circularity: empirical method grounded in external experiments
full rationale
The paper presents an empirical pruning framework that identifies semantic attention consistency via observation and uses it to design a forward-looking strategy, with performance validated through simulation and real-world experiments. No equations, fitted parameters renamed as predictions, self-citations, or self-definitional reductions appear in the provided text. The central claims reduce to measured speedups and success rates rather than to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Semantic attention consistency holds across execution steps in VLA models
Reference graph
Works this paper leans on
-
[1]
Alvar, S.R., Singh, G., Akbari, M., Zhang, Y.: Divprune: Diversity-based visual tokenpruningforlargemultimodalmodels.In:ProceedingsoftheComputerVision and Pattern Recognition Conference. pp. 9392–9401 (2025)
2025
-
[2]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
PaliGemma: A versatile 3B VLM for transfer
Beyer, L., Steiner, A., Pinto, A.S., Kolesnikov, A., Wang, X., Salz, D., Neumann, M., Alabdulmohsin, I., Tschannen, M., Bugliarello, E., et al.: Paligemma: A ver- satile 3b vlm for transfer. arXiv preprint arXiv:2407.07726 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
GR00T N1: An Open Foundation Model for Generalist Humanoid Robots
Bjorck, J., Castañeda, F., Cherniadev, N., Da, X., Ding, R., Fan, L., Fang, Y., Fox, D., Hu, F., Huang, S., et al.: Gr00t n1: An open foundation model for generalist humanoid robots. arXiv preprint arXiv:2503.14734 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., Ding, T., Driess, D., Dubey, A., Finn, C., Florence, P., Fu, C., Arenas, M.G., Gopalakrishnan, K., Han, K., Hausman, K., Herzog, A., Hsu, J., Ichter, B., Irpan, A., Joshi, N., Julian, R., Kalashnikov, D., Kuang, Y., Leal, I., Lee, L., Lee, T.W.E., Levine, S., Lu, Y., Michalewski...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[7]
RT-1: Robotics Transformer for Real-World Control at Scale
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Dabis, J., Finn, C., Gopalakr- ishnan, K., et al.: Rt-1: Robotics transformer for real-world control at scale. arXiv preprint arXiv:2212.06817 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
In: European Conference on Computer Vision
Chen, L., Zhao, H., Liu, T., Bai, S., Lin, J., Zhou, C., Chang, B.: An image is worth 1/2 tokens after layer 2: Plug-and-play inference acceleration for large vision-language models. In: European Conference on Computer Vision. pp. 19–35. Springer (2024)
2024
-
[9]
PaLI-X: On Scaling up a Multilingual Vision and Language Model
Chen, X., Djolonga, J., Padlewski, P., Mustafa, B., Changpinyo, S., Wu, J., Ruiz, C.R., Goodman, S., Wang, X., Tay, Y., Shakeri, S., Dehghani, M., Salz, D., Lucic, M., Tschannen, M., Nagrani, A., Hu, H., Joshi, M., Pang, B., Montgomery, C., Pietrzyk, P., Ritter, M., Piergiovanni, A., Minderer, M., Pavetic, F., Waters, A., Li, 16 S. Ma et al. G., Alabdulmo...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
RLRC: Reinforcement Learning-based Recovery for Compressed Vision-Language-Action Models
Chen, Y., Li, X.: Rlrc: Reinforcement learning-based recovery for compressed vision-language-action models. arXiv preprint arXiv:2506.17639 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
The International Journal of Robotics Research44(10-11), 1684–1704 (2025)
Chi,C.,Xu,Z.,Feng,S.,Cousineau,E.,Du,Y.,Burchfiel,B.,Tedrake,R.,Song,S.: Diffusion policy: Visuomotor policy learning via action diffusion. The International Journal of Robotics Research44(10-11), 1684–1704 (2025)
2025
-
[12]
arXiv preprint arXiv:2402.08178 (2024)
Choi, J.W., Yoon, Y., Ong, H., Kim, J., Jang, M.: Lota-bench: Bench- marking language-oriented task planners for embodied agents. arXiv preprint arXiv:2402.08178 (2024)
-
[13]
Advances in neural information pro- cessing systems35, 16344–16359 (2022)
Dao, T., Fu, D., Ermon, S., Rudra, A., Ré, C.: Flashattention: Fast and memory- efficient exact attention with io-awareness. Advances in neural information pro- cessing systems35, 16344–16359 (2022)
2022
-
[14]
RoboNet: Large-Scale Multi-Robot Learning
Dasari, S., Ebert, F., Tian, S., Nair, S., Bucher, B., Schmeckpeper, K., Singh, S., Levine, S., Finn, C.: Robonet: Large-scale multi-robot learning. arXiv preprint arXiv:1910.11215 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 1910
-
[15]
arXiv preprint arXiv:2510.09607 (2025)
Dong, S., Fu, C., Gao, H., Zhang, Y.F., Yan, C., Wu, C., Liu, X., Shen, Y., Huo, J., Jiang, D., Cao, H., Gao, Y., Sun, X., He, R., Shan, C.: Vita-vla: Efficiently teaching vision-language models to act via action expert distillation. arXiv preprint arXiv:2510.09607 (2025)
-
[16]
PaLM-E: An Embodied Multimodal Language Model
Driess, D., Xia, F., Sajjadi, M.S.M., Lynch, C., Chowdhery, A., Ichter, B., Wahid, A., Tompson, J., Vuong, Q., Yu, T., Huang, W., Chebotar, Y., Sermanet, P., Duckworth, D., Levine, S., Vanhoucke, V., Hausman, K., Toussaint, M., Greff, K., Zeng, A., Mordatch, I., Florence, P.: Palm-e: An embodied multimodal language model. arXiv preprint arXiv:2303.03378 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Bridge Data: Boosting Generalization of Robotic Skills with Cross-Domain Datasets
Ebert, F., Yang, Y., Schmeckpeper, K., Bucher, B., Georgakis, G., Daniilidis, K., Finn, C., Levine, S.: Bridge data: Boosting generalization of robotic skills with cross-domain datasets. arXiv preprint arXiv:2109.13396 (2021)
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[18]
arXiv preprint arXiv:2507.17141 (2025)
Gao, G., Wang, J., Zuo, J., Jiang, J., Zhang, J., Zeng, X., Zhu, Y., Ma, L., Chen, K., Sheng, M., et al.: Towards human-level intelligence via human-like whole-body manipulation. arXiv preprint arXiv:2507.17141 (2025)
-
[19]
$\pi_{0.5}$: a Vision-Language-Action Model with Open-World Generalization
Intelligence, P., Black, K., Brown, N., Darpinian, J., Dhabalia, K., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Galliker, M.Y., Ghosh, D., Groom, L., Hausman, K., Ichter, B., Jakubczak, S., Jones, T., Ke, L., LeBlanc, D., Levine, S., Li-Bell, A., Mothukuri, M., Nair, S., Pertsch, K., Ren, A.Z., Shi, L.X., Smith, L., Springenberg, J.T., Stachow...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
arXiv preprint arXiv:2104.08212 (2021)
Kalashnikov, D., Varley, J., Chebotar, Y., Swanson, B., Jonschkowski, R., Finn, C., Levine, S., Hausman, K.: Mt-opt: Continuous multi-task robotic reinforcement learning at scale. arXiv preprint arXiv:2104.08212 (2021)
-
[21]
In: Forty-first International Conference on Machine Learning (2024)
Karamcheti, S., Nair, S., Balakrishna, A., Liang, P., Kollar, T., Sadigh, D.: Pris- matic vlms: Investigating the design space of visually-conditioned language models. In: Forty-first International Conference on Machine Learning (2024)
2024
-
[22]
Fine-Tuning Vision-Language-Action Models: Optimizing Speed and Success
Kim, M.J., Finn, C., Liang, P.: Fine-tuning vision-language-action models: Opti- mizing speed and success. arXiv preprint arXiv:2502.19645 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
OpenVLA: An Open-Source Vision-Language-Action Model
Kim, M.J., Pertsch, K., Karamcheti, S., Xiao, T., Balakrishna, A., Nair, S., Rafailov, R., Foster, E., Lam, G., Sanketi, P., et al.: Openvla: An open-source vision-language-action model. arXiv preprint arXiv:2406.09246 (2024) SAFE-Pruner 17
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[24]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Kwon, W., Li, Z., Zhuang, S., Sheng, Y., Zheng, L., Yu, C.H., Gonzalez, J.E., Zhang, H., Stoica, I.: Efficient memory management for large language model serv- ing with pagedattention. arXiv preprint arXiv:2309.06180 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[25]
Li, Q., Liang, Y., Wang, Z., Luo, L., Chen, X., Liao, M., Wei, F., Deng, Y., Xu, S., Zhang,Y.,etal.:Cogact:Afoundationalvision-language-actionmodelforsynergiz- ing cognition and action in robotic manipulation. arXiv preprint arXiv:2411.19650 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Evaluating Real-World Robot Manipulation Policies in Simulation
Li, X., Hsu, K., Gu, J., Pertsch, K., Mees, O., Walke, H.R., Fu, C., Lunawat, I., Sieh, I., Kirmani, S., Levine, S., Wu, J., Finn, C., Su, H., Vuong, Q., Xiao, T.: Evaluating real-world robot manipulation policies in simulation. arXiv preprint arXiv:2405.05941 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Advances in Neural Information Processing Systems36, 44776–44791 (2023)
Liu, B., Zhu, Y., Gao, C., Feng, Y., Liu, Q., Zhu, Y., Stone, P.: Libero: Benchmark- ing knowledge transfer for lifelong robot learning. Advances in Neural Information Processing Systems36, 44776–44791 (2023)
2023
-
[28]
Bridging the Semantic-Action Gap in Visual Token Pruning for Efficient VLA Inference
Liu, Z., Chen, Y., Cai, H., Lin, T., Yang, S., Liu, Z., Zhao, B.: Vla-pruner: Temporal-aware dual-level visual token pruning for efficient vision-language-action inference. arXiv preprint arXiv:2511.16449 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
arXiv preprint arXiv:2602.02538 (2026)
Lv, Z., Fan, Z., Tian, Q., Zhang, W., Zhuang, Y.: Enhancing post-training quan- tization via future activation awareness. arXiv preprint arXiv:2602.02538 (2026)
-
[30]
IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
Mees, O., Hermann, L., Rosete-Beas, E., Burgard, W.: Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks. IEEE Robotics and Automation Letters7(3), 7327–7334 (2022)
2022
-
[31]
In: International Conference on Learning Representations (ICLR) (2018)
Micikevicius, P., Narang, S., Alben, J., Diamos, G., Elsen, E., Garcia, D., Ginsburg, B., Houston, M., Kuchaiev, O., Venkatesh, G., Wu, H.: Mixed precision training. In: International Conference on Learning Representations (ICLR) (2018)
2018
-
[32]
In: 2024 IEEE International Conference on Robotics and Automation (ICRA)
O’Neill, A., Rehman, A., Maddukuri, A., Gupta, A., Padalkar, A., Lee, A., Pooley, A., Gupta, A., Mandlekar, A., Jain, A., et al.: Open x-embodiment: Robotic learn- ing datasets and rt-x models: Open x-embodiment collaboration 0. In: 2024 IEEE International Conference on Robotics and Automation (ICRA). pp. 6892–6903. IEEE (2024)
2024
-
[33]
arXiv preprint arXiv:2509.22093 (2025)
Pei, X., Chen, Y., Xu, S., Wang, Y., Shi, Y., Xu, C.: Action-aware dynamic pruning for efficient vision-language-action manipulation. arXiv preprint arXiv:2509.22093 (2025)
-
[34]
In: Meila, M., Zhang, T
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning trans- ferable visual models from natural language supervision. In: Meila, M., Zhang, T. (eds.) Proceedings of the 38th International Conference on Machine Learning. Proceedings of Machine Learning Res...
2021
-
[35]
Reed, S., Zolna, K., Parisotto, E., Colmenarejo, S.G., Novikov, A., Barth-Maron, G., Gimenez, M., Sulsky, Y., Kay, J., Springenberg, J.T., Eccles, T., Bruce, J., Razavi, A., Edwards, A., Heess, N., Chen, Y., Hadsell, R., Vinyals, O., Bordbar, M., de Freitas, N.: A generalist agent. arXiv preprint arXiv:2205.06175 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [36]
-
[37]
Advances in Neural Information Processing Systems37, 114553–114573 (2024)
Wang, C., Wang, Z., Xu, X., Tang, Y., Zhou, J., Lu, J.: Q-vlm: Post-training quantization for large vision-language models. Advances in Neural Information Processing Systems37, 114553–114573 (2024)
2024
-
[38]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wang, H., Nie, Y., Ye, Y., Wang, Y., Li, S., Yu, H., Lu, J., Huang, C.: Dynamic- vlm: Simple dynamic visual token compression for videollm. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20812–20823 (2025) 18 S. Ma et al
2025
-
[39]
SpecPrune-VLA: Accelerating Vision-Language-Action Models via Action-Aware Self-Speculative Pruning
Wang, H., Xu, J., Pan, J., Zhou, Y., Dai, G.: Specprune-vla: Accelerating vision- language-action models via action-aware self-speculative pruning. arXiv preprint arXiv:2509.05614 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T
Wang, Y., Zhang, H., Tian, J., Tang, Y.: Ponder & press: Advancing visual GUI agent towards general computer control. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Findings of the Association for Computational Linguistics: ACL 2025. pp. 1461–1473. Association for Computational Linguistics, Vienna, Austria (Jul 2025).https://doi.org/10.18653...
-
[41]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
Xu, S., Wang, Y., Xia, C., Zhu, D., Huang, T., Xu, C.: Vla-cache: Efficient vision- language-action manipulation via adaptive token caching. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems (2025)
2025
-
[42]
arXiv preprint arXiv:2602.03782 (2026)
Xu, Y., Yang, Y., Fan, Z., Liu, Y., Li, Y., Li, B., Zhang, Z.: Qvla: Not all channels are equal in vision-language-action model’s quantization. arXiv preprint arXiv:2602.03782 (2026)
-
[43]
arXiv preprint arXiv:2506.10100 (2025)
Yang, Y., Wang, Y., Wen, Z., Zhongwei, L., Zou, C., Zhang, Z., Wen, C., Zhang, L.: Efficientvla: Training-free acceleration and compression for vision-language-action models. arXiv preprint arXiv:2506.10100 (2025)
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yang, Z., Wang, J., Tang, Y., Chen, K., Zhao, H., Torr, P.H.: Lavt: Language- aware vision transformer for referring image segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18155– 18165 (2022)
2022
-
[45]
Advances in Neural Information Processing Systems37, 56619–56643 (2024)
Yue, Y., Wang, Y., Kang, B., Han, Y., Wang, S., Song, S., Feng, J., Huang, G.: Deer-vla:Dynamicinferenceofmultimodallargelanguagemodelsforefficientrobot execution. Advances in Neural Information Processing Systems37, 56619–56643 (2024)
2024
-
[46]
arXiv preprint arXiv:2601.04061 (2026)
Zhang, C., Wang, J., Gao, Z., Su, Y., Dai, T., Zhou, C., Lu, J., Tang, Y.: Clap: Contrastive latent action pretraining for learning vision-language-action models from human videos. arXiv preprint arXiv:2601.04061 (2026)
-
[47]
arXiv preprint arXiv:2506.10967 (2025)
Zhang, Q., Liu, M., Li, L., Lu, M., Zhang, Y., Pan, J., She, Q., Zhang, S.: Be- yond attention or similarity: Maximizing conditional diversity for token pruning in mllms. arXiv preprint arXiv:2506.10967 (2025)
-
[48]
arXiv preprint arXiv:2503.20384 (2025)
Zhang, R., Dong, M., Zhang, Y., Heng, L., Chi, X., Dai, G., Du, L., Du, Y., Zhang, S.: Mole-vla: Dynamic layer-skipping vision language action model via mixture-of- layers for efficient robot manipulation. arXiv preprint arXiv:2503.20384 (2025)
-
[49]
SparseVLM: Visual Token Sparsification for Efficient Vision-Language Model Inference
Zhang, Y., Fan, C.K., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D., Okuno, T., Nakata, Y., Keutzer, K., et al.: Sparsevlm: Visual token sparsifica- tion for efficient vision-language model inference. arXiv preprint arXiv:2410.04417 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[50]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Zhao, T.Z., Kumar, V., Levine, S., Finn, C.: Learning fine-grained bimanual ma- nipulation with low-cost hardware. arXiv preprint arXiv:2304.13705 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[51]
Zhu, D., Wang, Y., Liu, Y., Tang, Y., Yu, B., Lu, J., Zhou, J.: Segment anything with motion, geometry, and semantic adaptation for complex nonlinear visual ob- ject tracking. arXiv preprint arXiv:2605.22538 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[52]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhu, T., Zhang, S., Shao, J., Tang, Y.: Kv-edit: Training-free image editing for precise background preservation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 16607–16617 (2025)
2025
-
[53]
arXiv preprint arXiv:2512.18741 (2025) SAFE-Pruner 19
Zhu, T., Zhang, S., Sun, Z., Tian, J., Tang, Y.: Memorize-and-generate: Towards long-term consistency in real-time video generation. arXiv preprint arXiv:2512.18741 (2025) SAFE-Pruner 19
-
[54]
VARestorer: One-Step VAR Distillation for Real-World Image Super-Resolution
Zhu, Y., Ma, S., Wang, H., Li, A., Jing, Y., Tang, Y., Chen, L., Lu, J., Zhou, J.: Varestorer: One-step var distillation for real-world image super-resolution. arXiv preprint arXiv:2604.21450 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[55]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhu, Y., Wang, H., Ma, S., Zhao, W., Tang, Y., Chen, L., Zhou, J.: Fade: Frequency-aware diffusion model factorization for video editing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 28426–28435 (2025) SAFE-Pruner 1 A Detailed Implementation To validate the effectiveness and generalization of our method, we ev...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.