EviLink: Multi-Path Schema Linking with Uncertainty-Guided Evidence Acquisition for Large-Scale Text-to-SQL
Pith reviewed 2026-06-29 07:50 UTC · model grok-4.3
The pith
Schema linking for Text-to-SQL improves when multiple plausible paths guide uncertainty-based evidence selection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
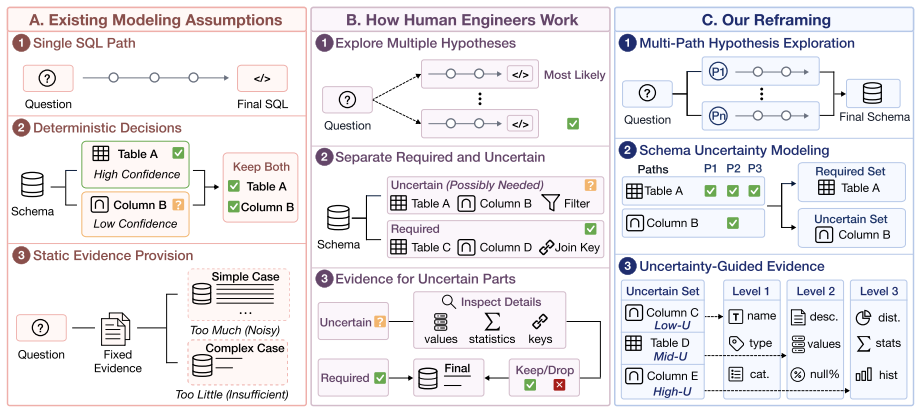
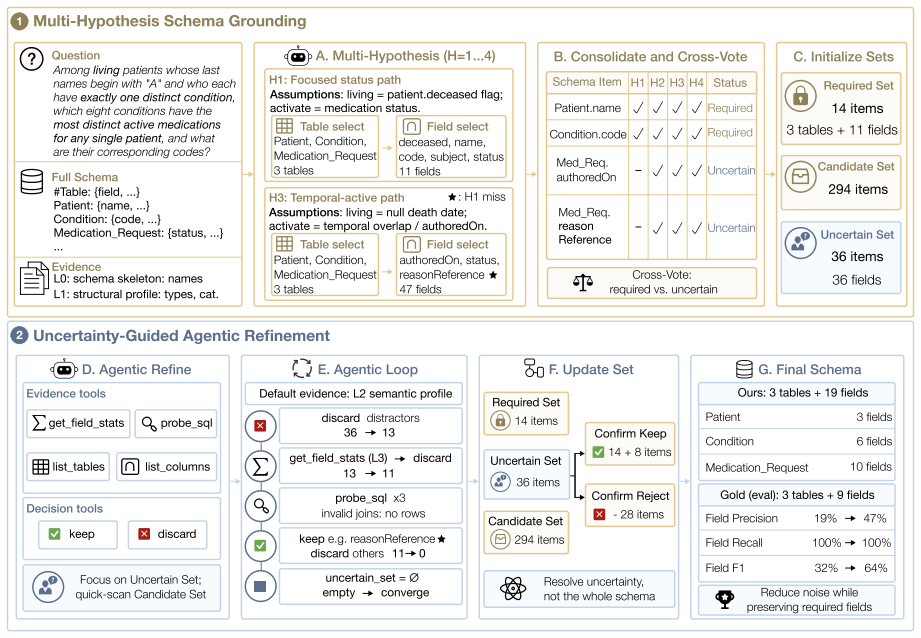
EviLink reframes schema linking as uncertainty-aware schema-need inference over multiple plausible SQL paths. It combines multi-hypothesis schema grounding with uncertainty-guided evidence acquisition to distinguish required schema items from path-dependent uncertain ones and acquires evidence only where needed, improving the balance among schema completeness, schema relevance, and token cost.
What carries the argument
Multi-hypothesis schema grounding paired with uncertainty-guided evidence acquisition, which identifies items needed across all paths while limiting evidence collection to uncertain positions.
If this is right
- On Spider2-Snow the method reaches 90.15 percent field-level strict recall while using 123.30K average tokens.
- The same procedure improves downstream SQL generation accuracy when the generator is held fixed.
- The approach yields a measurable improvement in the three-way balance of completeness, relevance, and token cost on both BIRD-Dev and Spider2-Snow.
- Evidence acquisition occurs selectively rather than uniformly across the schema.
Where Pith is reading between the lines
- The same uncertainty signal could be reused to prune evidence in other retrieval-augmented generation settings that face large, ambiguous contexts.
- If path sampling is cheap, the method suggests a general template for any task where one input maps to several valid outputs with differing context needs.
- An extension could test whether the same multi-path uncertainty logic transfers to schema linking in other query languages or in visual question answering over large tables.
Load-bearing premise
Multiple plausible SQL paths can be generated reliably and uncertainty estimates over those paths accurately mark which schema items are required rather than path-specific.
What would settle it
A dataset of ambiguous questions where EviLink's uncertainty scores systematically omit a critical schema item that appears in every valid path, producing lower recall than single-path baselines.
Figures





read the original abstract
Schema linking is a difficult and important step in large-scale Text-to-SQL, where systems must identify a compact yet sufficient schema context from large and ambiguous databases. Existing methods often treat schema linking as deterministic selection around a single SQL path, but complex questions may admit multiple valid realizations with different schema needs. We reframe schema linking as uncertainty-aware schema-need inference over multiple plausible SQL paths, where the system distinguishes required schema items from path-dependent uncertain ones and acquires evidence only where needed. We instantiate this reframing with EviLink, which combines multi-hypothesis schema grounding with uncertainty-guided evidence acquisition. Experiments on BIRD-Dev and Spider2-Snow show that this perspective improves the balance among schema completeness, schema relevance, and token cost. On Spider2-Snow, EviLink achieves 90.15% field-level strict recall rate, uses 123.30K average tokens, and improves downstream SQL generation under a fixed generator.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reframes schema linking for large-scale Text-to-SQL as uncertainty-aware inference over multiple plausible SQL paths rather than deterministic selection around a single path. It introduces EviLink, which performs multi-hypothesis schema grounding combined with uncertainty-guided evidence acquisition to distinguish required schema items from path-dependent ones. Experiments on BIRD-Dev and Spider2-Snow are reported to show improved balance among schema completeness, relevance, and token cost; on Spider2-Snow the method achieves 90.15% field-level strict recall while using 123.30K average tokens and yields better downstream SQL generation under a fixed generator.
Significance. If the empirical claims hold under rigorous validation, the work offers a meaningful advance for Text-to-SQL on large ambiguous databases by explicitly modeling query ambiguity through multi-path uncertainty. The reported recall/token trade-off on Spider2-Snow is practically relevant, and the reframing could influence future systems that must avoid both under- and over-retrieval of schema context. No machine-checked proofs or parameter-free derivations are claimed, but the empirical focus on falsifiable downstream improvement is a strength.
minor comments (2)
- Abstract: the description of how multi-hypothesis paths are generated and how uncertainty is quantified would benefit from one additional sentence to allow readers to assess the weakest assumption identified in the review process.
- The manuscript should include a brief error analysis or ablation on cases where uncertainty estimates fail to surface critical schema items, even if only in the appendix.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and for recognizing the practical relevance of the recall/token trade-off on Spider2-Snow. The report does not enumerate any specific major comments, so we have no point-by-point rebuttals to provide at this stage.
Circularity Check
No significant circularity; empirical method with no derivations or self-referential reductions
full rationale
The paper describes an empirical reframing of schema linking as uncertainty-aware inference over multiple SQL paths, instantiated as EviLink, and evaluated on BIRD-Dev and Spider2-Snow benchmarks. No equations, parameters, or derivations are present in the provided text. Claims rest on experimental metrics (e.g., 90.15% recall, token usage) rather than any chain that reduces by construction to fitted inputs or self-citations. The central premise does not invoke uniqueness theorems, ansatzes smuggled via citation, or renaming of known results. This is a self-contained empirical contribution with no load-bearing steps that match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
C3: Zero-shot text-to-SQL with ChatGPT,
C3: Zero-shot Text-to-SQL with ChatGPT. Preprint, arXiv:2307.07306. Dawei Gao, Haibin Wang, Yaliang Li, Xiuyu Sun, Yichen Qian, Bolin Ding, and Jingren Zhou. 2024. Text-to-SQL Empowered by Large Language Mod- els: A Benchmark Evaluation.Proc. VLDB Endow., 17(5):1132–1145. Zhifeng Hao, Qibin Song, Ruichu Cai, and Boyan Xu
-
[2]
Text-to-SQL as Dual-State Reasoning: Inte- grating Adaptive Context and Progressive Generation. Preprint, arXiv:2511.21402. George Katsogiannis-Meimarakis, Katsiaryna Mirylenka, Paolo Scotton, Francesco Fusco, and Abdel Labbi. 2026. In-depth Analysis of LLM-based Schema Linking. InInternational Conference on Extending Database Technology, pages 117–130. D...
-
[3]
arXiv preprint arXiv:2408.07702 , year=
Solid-SQL: Enhanced Schema-linking based In-context Learning for Robust Text-to-SQL. InPro- ceedings of the 31st International Conference on Computational Linguistics, pages 9793–9803. Karime Maamari, Fadhil Abubaker, Daniel Jaroslawicz, and Amine Mhedhbi. 2024. The Death of Schema Linking? Text-to-SQL in the Age of Well-Reasoned Language Models.Preprint,...
-
[4]
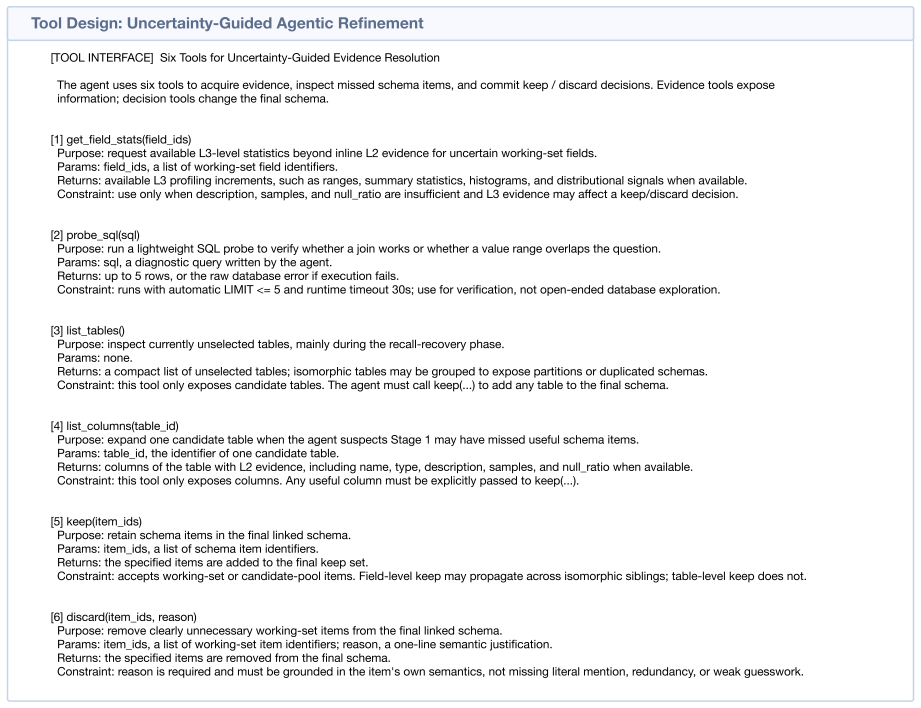
Params: field_ids, a list of working-set field identifiers
get_field_stats(field_ids) Purpose: r equest available L3-level statistics beyond inline L2 evidence for uncertain working-set fields. Params: field_ids, a list of working-set field identifiers. Retur ns: available L3 pr ofiling incr ements, such as ranges, summary statistics, histograms, and distributional signals when available. Constraint: use only whe...
-
[5]
Params: sql, a diagnostic query written by the agent
pr obe_sql(sql) Purpose: run a lightweight SQL pr obe to verify whether a join works or whether a value range overlaps the question. Params: sql, a diagnostic query written by the agent. Retur ns: up to 5 r ows, or the raw database err or if execution fails. Constraint: runs with automatic LIMIT <= 5 and runtime timeout 30s; use for verification, not open...
-
[6]
Params: none
list_tables() Purpose: inspect curr ently unselected tables, mainly during the r ecall-r ecovery phase. Params: none. Retur ns: a compact list of unselected tables; isomorphic tables may be gr ouped to expose partitions or duplicated schemas. Constraint: this tool only exposes candidate tables. The agent must call keep(...) to add any table to the final schema
-
[7]
Params: table_id, the identifier of one candidate table
list_columns(table_id) Purpose: expand one candidate table when the agent suspects Stage 1 may have missed useful schema items. Params: table_id, the identifier of one candidate table. Retur ns: columns of the table with L2 evidence, including name, type, description, samples, and null_ratio when available. Constraint: this tool only exposes columns. Any ...
-
[8]
Params: item_ids, a list of schema item identifiers
keep(item_ids) Purpose: r etain schema items in the final linked schema. Params: item_ids, a list of schema item identifiers. Retur ns: the specified items ar e added to the final keep set. Constraint: accepts working-set or candidate-pool items. Field-level keep may pr opagate acr oss isomorphic siblings; table-level keep does not
-
[9]
this table is pr obably not needed,
discar d(item_ids, r eason) Purpose: r emove clearly unnecessary working-set items fr om the final linked schema. Params: item_ids, a list of working-set item identifiers; r eason, a one-line semantic justification. Retur ns: the specified items ar e r emoved fr om the final schema. Constraint: r eason is r equir ed and must be gr ounded in the item's own...
-
[10]
Any table whose name or field names align with an entity , concept, attribute, filter value, or synonym in the question
-
[11]
Bridge / junction / mapping / r elationship tables that could connect two entities mentioned in the question — even when a dir ect for eign key also exists
-
[12]
When several tables shar e the same structur e and r epr esent partitions of one logical dataset by date, shar d suffix, r egion, version, or duplicated schema, and the question's scope may touch mor e than one partition, select ALL such partitions
-
[13]
summary , primary vs
When the same entity is r ecor ded in multiple tables at differ ent granularities or fr om differ ent sour ces, such as detail vs. summary , primary vs. history / audit, or two independent pr oviders of the same measur e, select ALL such candidates
-
[14]
Case and schema boundaries do not exempt a table
Cr oss-database and cr oss-schema tables whose names or semantics match a concept in the question. Case and schema boundaries do not exempt a table
-
[15]
r ecent,
When the question carries any temporal scope, such as a date range, a year , “r ecent,” or “latest,” select every time-series or time-keyed table whose coverage could overlap that scope
-
[16]
Such tables often expose multiple identifier -shaped columns and may carry timestamp or status fields
T ables whose name or visible field names signal a structural connector r ole: co-occurr ence, mapping, link, transition, or event tables between two or mor e concepts alr eady named by the question. Such tables often expose multiple identifier -shaped columns and may carry timestamp or status fields. Default to keeping connector tables when both endpoint...
-
[17]
every excluded table has a concr ete r eason why no corr ect SQL could use it
-
[18]
any table without such a r eason has been moved back to the selected set
-
[19]
selected_tables
every selected table name matches an input table exactly , case-sensitive. [OUTPUT FORMA T] Retur n ONL Y a single-line minified JSON object with: {"selected_tables":["<DB>.<SCHEMA>.<T ABLE>", ...]} Use the EXACT full path string fr om the input. Do NOT pr epend literal wor ds such as db, schema, or database. [OUTPUT RULES]
-
[20]
Use exact full table names fr om the input, case-sensitive
-
[21]
this field is pr obably not needed,
selected_tables must be non-empty and contain no duplicates. Figure 6: System prompt excerpt: table selection. System Pr ompt: Field Selection Y ou ar e a schema linker . Select every field that COULD be needed to answer the question, within the alr eady-filter ed tables. [INPUT] Y ou will r eceive a natural-language question, an optional structur ed hypo...
-
[22]
Any field whose name, type, category , or table context aligns with an entity , attribute, filter value, synonym, or display tar get in the question
-
[23]
If you select an id / code / key on one table, select its counterpart on every other table it could join to
Every JOIN key must be selected on BOTH sides of the join. If you select an id / code / key on one table, select its counterpart on every other table it could join to
-
[24]
This also applies to same-schema partition / shar d tables
When the same concept, such as entity id, timestamp, location, status, or name, can be encoded by columns in several r etained tables, select it in EVER Y such table. This also applies to same-schema partition / shar d tables. Do NOT deduplicate acr oss tables
-
[25]
Select time, date, and or dering columns whenever the question mentions any temporal or ranking notion and the column could plausibly carry that semantics
-
[26]
NULL-ness, name vs
When a filter or measur e admits multiple encodings, such as flag vs. NULL-ness, name vs. code, or dedicated column vs. descriptive patter n match, select ALL candidate columns
-
[27]
When the question implies a hierar chy , such as country / state / county / zip, year / month / day , or category / subcategory , select identifiers at EVER Y level that could be touched
-
[28]
Within a r etained table, default-keep r etrieval-unit fields: primary identifiers, for eign-key-shaped columns, categorical / status / type / flag columns, human-r eadable name / title / label columns, and timestamp / date / time columns
-
[29]
A field not mentioned in the hypothesis may still be r equir ed
Hypothesis text is a HINT , not a whitelist. A field not mentioned in the hypothesis may still be r equir ed
-
[30]
If question tokens and column-name segments shar e a non-trivial substring, default-keep the column unless a concr ete exclusion r eason exists
Surface-form alignment between the question and a column is a positive signal. If question tokens and column-name segments shar e a non-trivial substring, default-keep the column unless a concr ete exclusion r eason exists. [EXCLUDE ONL Y IF CER T AIN] A field may be omitted ONL Y if it is an engineering / ETL artifact with no business semantics AND the q...
-
[31]
every excluded field has a concr ete r eason why no corr ect SQL could use it
-
[32]
every selected JOIN key has counterparts selected on all tables it could join to
-
[33]
question tokens have been r e-scanned against r etained-table column names
-
[34]
selected_fields
every selected field name matches an input field exactly , case-sensitive. [OUTPUT FORMA T] Retur n ONL Y a single-line minified JSON object with: {"selected_fields":["<DB>.<SCHEMA>.<T ABLE>.<FIELD>", ...]} Use the EXACT full path string fr om the input. Do NOT pr epend literal wor ds such as db, schema, or database. [OUTPUT RULES]
-
[35]
Use exact full field names fr om the input, case-sensitive
-
[36]
Figure 7: System prompt excerpt: field selection
selected_fields must contain no duplicates. Figure 7: System prompt excerpt: field selection. System Pr ompt: Uncertainty-Guided Agentic Refinement Y ou ar e a schema verifier . T wo har d rules gover n every action you take: [RULE 1] Recall First A corr ect SQL may exist along multiple plausible r easoning paths. Any schema item that could be needed by a...
-
[37]
Read the L2 view and decide whether it is enough for keep or discar d
-
[38]
If mor e evidence is needed, use L3 statistics or SQL pr obes
-
[39]
the question does not literally mention this column
Or leave the item undecided. Undecided items default to KEEP at conver gence. [DISCARD REQUIRES A JUSTIFICA TION] Every discar d call must include a one-line r eason explaining why no plausible SQL path could need this field. V alid r easons cite the field's own semantics: ETL bookkeeping, inter nal system metadata, or L3 evidence showing irr elevant / co...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.