Beyond Trajectory Rewards: Step-level Credit Assignment for Agentic Search via Graph Modeling
Pith reviewed 2026-06-29 07:56 UTC · model grok-4.3
The pith
Modeling search as graph navigation lets distance to the answer node assign credit to individual retrieval steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
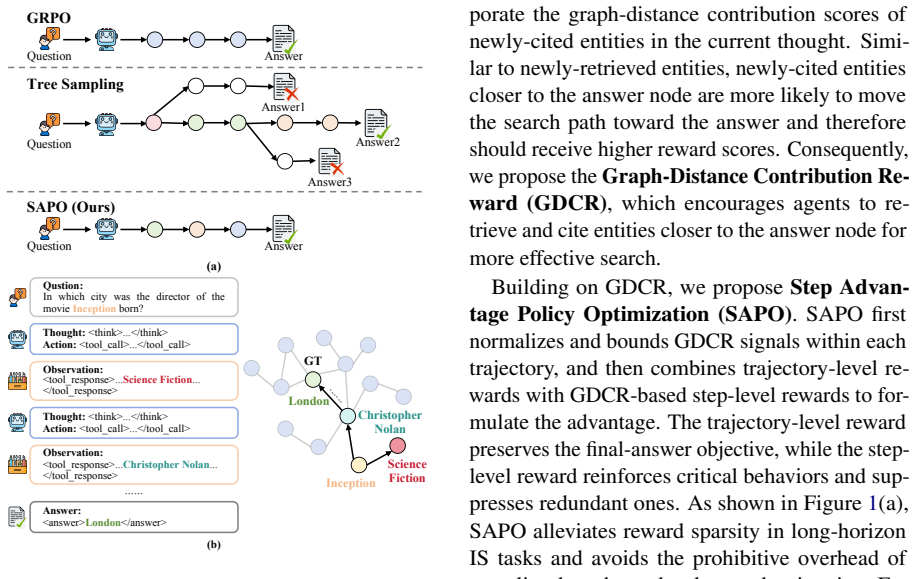
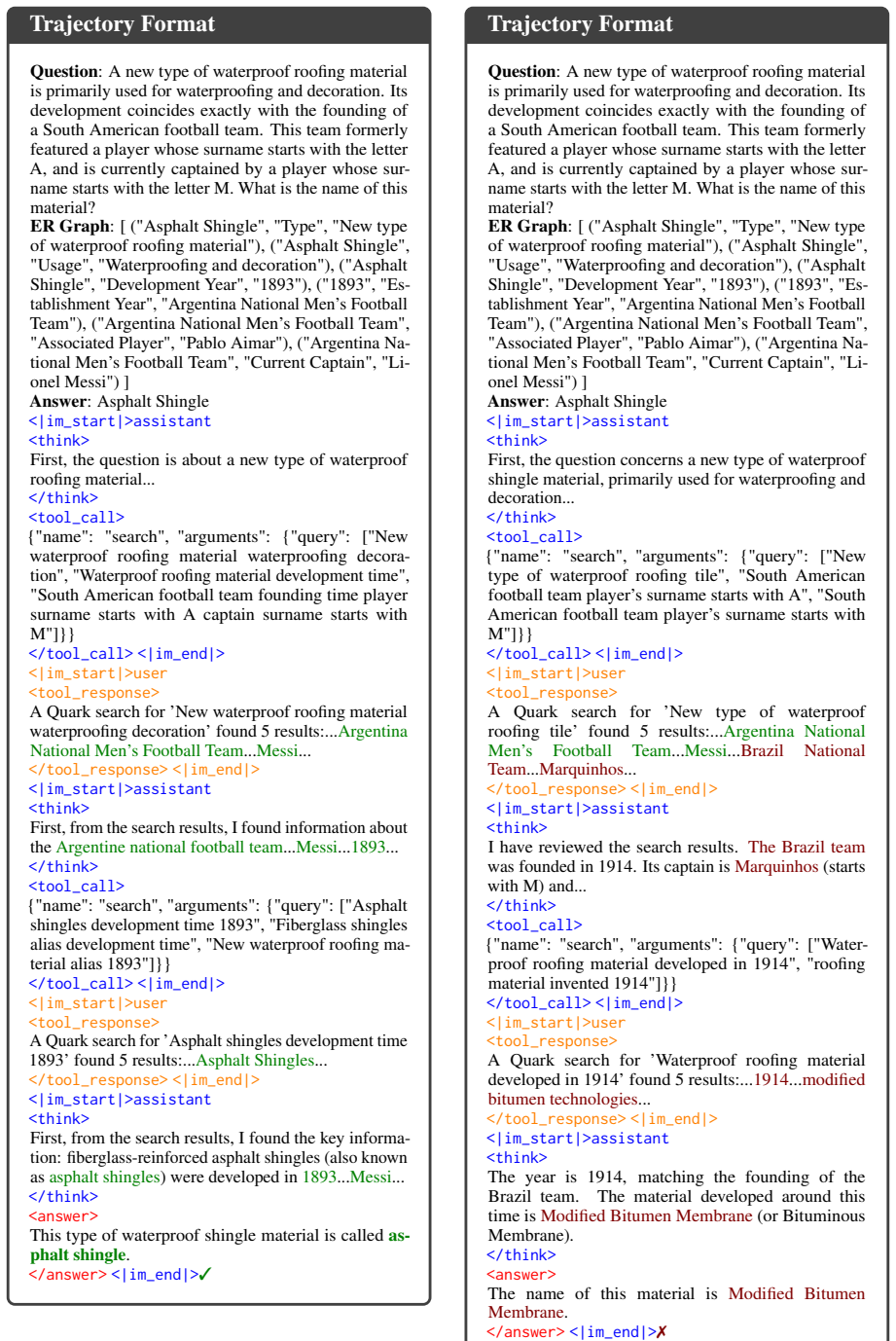
The central claim is that newly retrieved or cited entities can be scored by their shortest-path distance to the answer node inside a training-time Entity-Relation graph, and that converting these distances into step-level advantages via SAPO produces a combined advantage signal that improves agent performance on information-seeking tasks over trajectory-only rewards.
What carries the argument
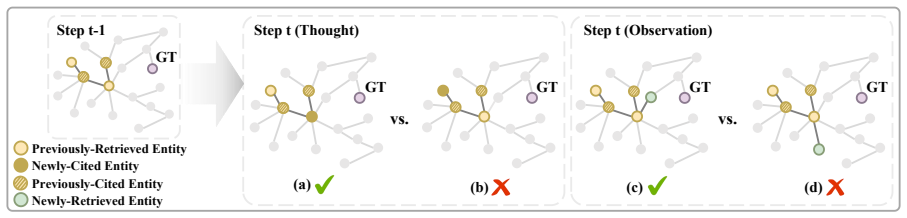
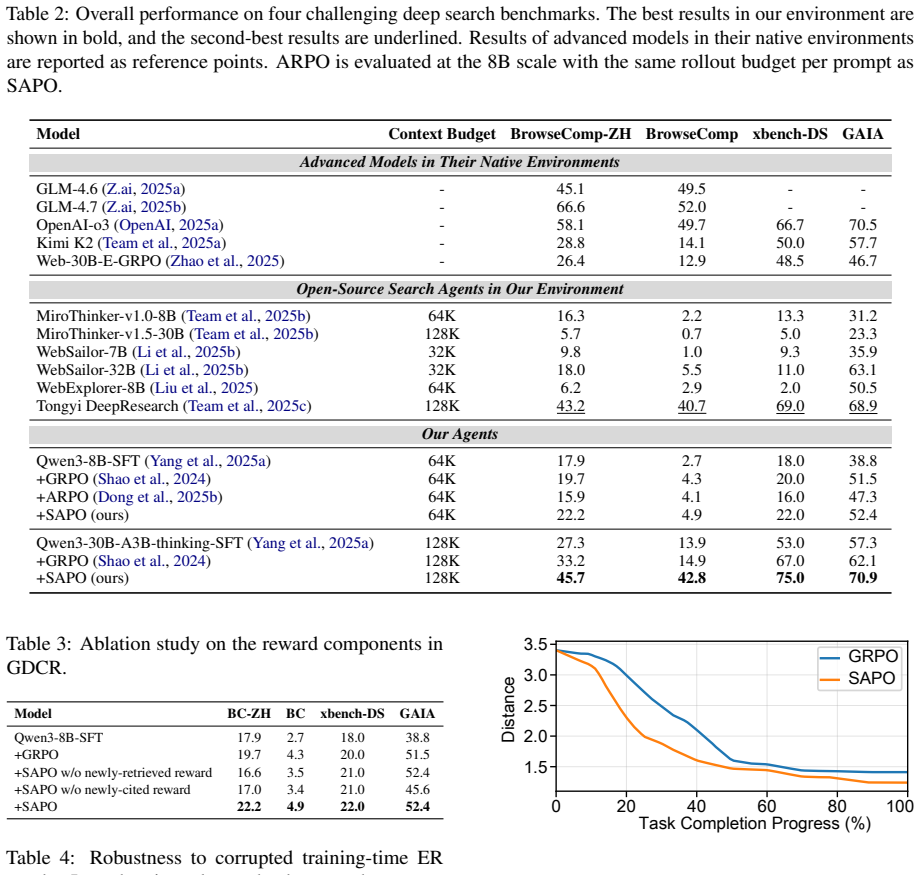
Graph-Distance Contribution Reward (GDCR), which scores each step by the reduction in graph distance of its newly retrieved or cited entities to the answer node in a pre-built Entity-Relation graph.
If this is right
- Steps that retrieve entities close to the answer receive positive credit even when the full trajectory ultimately fails.
- Policy updates can use dense step-level signals rather than waiting for sparse outcome rewards.
- No tree sampling is required to estimate the value of individual actions.
- The same advantage combination can be applied to any agent that retrieves and cites entities during search.
Where Pith is reading between the lines
- Pre-computing distances from a static training graph trades online exploration cost for an offline graph-construction cost.
- The approach may under-credit steps that discover entities outside the training graph.
- Similar distance-based rewards could be tested in other relational domains such as theorem proving or program synthesis where partial states form graphs.
Load-bearing premise
That progress toward an answer can be reliably measured by how much closer newly retrieved entities are to the answer node in a fixed entity-relation graph constructed from training data.
What would settle it
If replacing the graph-distance scores with random step values produces the same final performance on the four benchmarks, the claim that distance-based scoring supplies useful credit would be falsified.
Figures



read the original abstract
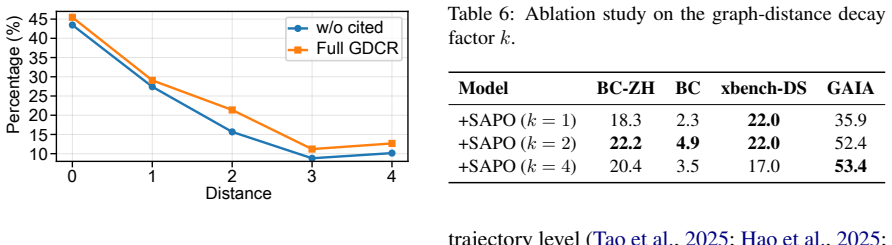
In Agentic Search, trajectory-level outcome rewards fail to quantify the behavioral contributions of individual steps, while existing step-level reward methods typically rely on costly tree sampling. We view world knowledge as a latent world graph and each IS task as search within a latent task graph, where effective steps should make graph progress toward the answer node. Based on this prior, we propose Graph-Distance Contribution Reward (GDCR), a step-level process reward that scores newly-retrieved and newly-cited entities by their distance to the answer node in a training-time Entity-Relation (ER) graph. We further propose Step Advantage Policy Optimization (SAPO), which converts GDCR into step-level advantages and combines them with trajectory-level outcome advantages. Experiments on four challenging benchmarks validate the effectiveness of our method.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that trajectory-level outcome rewards are insufficient for credit assignment in agentic search tasks. It models world knowledge as a latent graph and each information-seeking task as search within a latent task graph, where effective steps make measurable progress toward an answer node. Based on this, it proposes Graph-Distance Contribution Reward (GDCR), a step-level process reward scoring newly-retrieved and newly-cited entities by their distance to the answer node in a training-time Entity-Relation (ER) graph. It further proposes Step Advantage Policy Optimization (SAPO) to convert GDCR into step-level advantages combined with trajectory-level outcome advantages. Experiments on four challenging benchmarks are said to validate the approach.
Significance. If the results hold, the work provides an efficient alternative to tree-sampling methods for step-level rewards by directly operationalizing graph progress as a prior, potentially improving sample efficiency in training agents for information-seeking tasks without introducing self-referential parameters.
major comments (2)
- Abstract: the construction procedure for the training-time ER graph, the distance metric, and how newly-retrieved entities are identified are not described, preventing verification that GDCR is non-circular or that it measures genuine progress rather than a fitted quantity.
- Abstract: no derivation details, equations, experimental numbers, baselines, or ablation results are provided, so it is impossible to assess whether the math or data support the central claim that GDCR plus SAPO yields better credit assignment than trajectory-only rewards.
minor comments (1)
- Abstract: the acronym 'IS' is introduced without expansion (presumably 'information seeking').
Simulated Author's Rebuttal
We thank the referee for the review and the opportunity to clarify the manuscript. The two major comments both concern the brevity of the abstract. We address each point below and will revise the abstract in the next version to incorporate the requested details while preserving its length constraints.
read point-by-point responses
-
Referee: Abstract: the construction procedure for the training-time ER graph, the distance metric, and how newly-retrieved entities are identified are not described, preventing verification that GDCR is non-circular or that it measures genuine progress rather than a fitted quantity.
Authors: We agree that the abstract does not contain these procedural details. The full manuscript describes the training-time ER graph construction in Section 3.2 (built exclusively from training-set entity-relation extractions with no test leakage), the distance metric as shortest-path distance in Equation (2), and newly-retrieved entities as those appearing in the current observation but absent from prior trajectory states. These choices ensure GDCR is non-circular and reflects genuine graph progress. We will add a concise clause to the abstract summarizing the graph construction and distance definition. revision: yes
-
Referee: Abstract: no derivation details, equations, experimental numbers, baselines, or ablation results are provided, so it is impossible to assess whether the math or data support the central claim that GDCR plus SAPO yields better credit assignment than trajectory-only rewards.
Authors: The abstract is intentionally high-level. Derivations of GDCR (Section 3.3, Equations 3-4) and SAPO (Section 3.4, Equation 5) appear in the body, along with the combination of step-level and trajectory advantages. Section 4 reports results on four benchmarks with explicit baselines (e.g., PPO, ReAct variants), ablation studies, and quantitative improvements. We will revise the abstract to include one key result and the main baseline comparison to better support the central claim. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper explicitly grounds its proposal in a stated prior assumption that effective steps produce measurable graph progress toward an answer node in a latent task graph. GDCR is defined as a direct scoring of entity distances in an externally constructed training-time ER graph, and SAPO is a subsequent conversion of those scores into advantages that are then combined with independent trajectory-level outcome advantages. No equations or steps in the provided description reduce a claimed prediction or result to a fitted parameter, self-definition, or self-citation chain by construction; the method is an operationalization of the prior rather than a derivation that loops back to its own inputs. The central claim therefore remains independent of the construction details.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World knowledge can be represented as a latent world graph and each information-seeking task as search within a latent task graph where effective steps reduce distance to the answer node.
invented entities (1)
-
Entity-Relation (ER) graph
no independent evidence
Reference graph
Works this paper leans on
- [1]
- [2]
- [3]
-
[4]
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, and 1 others. 2025 b . Agentic reinforced policy optimization. arXiv preprint arXiv:2507.19849
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tianqing Fang, Zhisong Zhang, Xiaoyang Wang, Rui Wang, Can Qin, Yuxuan Wan, Jun-Yu Ma, Ce Zhang, Jiaqi Chen, Xiyun Li, and 1 others. 2025. Cognitive kernel-pro: A framework for deep research agents and agent foundation models training. arXiv preprint arXiv:2508.00414
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [6]
- [7]
- [8]
- [9]
-
[10]
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. 2025. Search-r1: Training llms to reason and leverage search engines with reinforcement learning. arXiv preprint arXiv:2503.09516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Kuan Li, Zhongwang Zhang, Huifeng Yin, Rui Ye, Yida Zhao, Liwen Zhang, Litu Ou, Dingchu Zhang, Xixi Wu, Jialong Wu, and 1 others. 2025 a . Websailor-v2: Bridging the chasm to proprietary agents via synthetic data and scalable reinforcement learning. arXiv preprint arXiv:2509.13305
-
[12]
Kuan Li, Zhongwang Zhang, Huifeng Yin, Liwen Zhang, Litu Ou, Jialong Wu, Wenbiao Yin, Baixuan Li, Zhengwei Tao, Xinyu Wang, and 1 others. 2025 b . Websailor: Navigating super-human reasoning for web agent. arXiv preprint arXiv:2507.02592
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. 2025 c . Search-o1: Agentic search-enhanced large reasoning models. arXiv preprint arXiv:2501.05366
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [14]
- [15]
-
[16]
Gr \'e goire Mialon, Cl \'e mentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. 2023. Gaia: a benchmark for general ai assistants. In The Twelfth International Conference on Learning Representations
2023
-
[17]
Moonshot AI . 2025. https://moonshotai.github.io/Kimi-Researcher/ Kimi-researcher end-to-end rl training for emerging agentic capabilities
2025
-
[18]
OpenAI . 2025 a . https://openai.com/zh-Hans-CN/index/introducing-o3-and-o4-mini/ Introducing openai o3 and o4-mini
2025
-
[19]
OpenAI . 2025 b . https://openai.com/zh-Hans-CN/index/introducing-deep-research/ Openai deep research
2025
-
[20]
Quark . 2024. Quark ai business search api. https://vt.quark.cn/blm/qk-ai-business-page-915/index?x_render_type=stream_ssr. Accessed: 2024
2024
-
[21]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, and 1 others. 2024. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36:8634--8652
2023
-
[23]
Huatong Song, Jinhao Jiang, Yingqian Min, Jie Chen, Zhipeng Chen, Wayne Xin Zhao, Lei Fang, and Ji-Rong Wen. 2025. R1-searcher: Incentivizing the search capability in llms via reinforcement learning. arXiv preprint arXiv:2503.05592
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [24]
-
[25]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, and 1 others. 2025 a . Kimi k2: Open agentic intelligence. arXiv preprint arXiv:2507.20534
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[26]
MiroMind Team, Song Bai, Lidong Bing, Carson Chen, Guanzheng Chen, Yuntao Chen, Zhe Chen, Ziyi Chen, Jifeng Dai, Xuan Dong, and 1 others. 2025 b . Mirothinker: Pushing the performance boundaries of open-source research agents via model, context, and interactive scaling. arXiv preprint arXiv:2511.11793
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[27]
Tongyi DeepResearch Team, Baixuan Li, Bo Zhang, Dingchu Zhang, Fei Huang, Guangyu Li, Guoxin Chen, Huifeng Yin, Jialong Wu, Jingren Zhou, and 1 others. 2025 c . Tongyi deepresearch technical report. arXiv preprint arXiv:2510.24701
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Rui Wang, Ce Zhang, Jun-Yu Ma, Jianshu Zhang, Hongru Wang, Yi Chen, Boyang Xue, Tianqing Fang, Zhisong Zhang, Hongming Zhang, and 1 others. 2025. Explore to evolve: Scaling evolved aggregation logic via proactive online exploration for deep research agents. arXiv preprint arXiv:2510.14438
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. 2025 a . Browsecomp: A simple yet challenging benchmark for browsing agents. arXiv preprint arXiv:2504.12516
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[31]
Quan Wei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, Wei Deng, Anderson Schneider, Yuriy Nevmyvaka, Yang Katie Zhao, Alfredo Garcia, and Mingyi Hong. 2025 b . https://arxiv.org/abs/2505.11821 Reinforcing multi-turn reasoning in llm agents via turn-level reward design . Preprint, arXiv:2505.11821
- [32]
-
[33]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025 a . Qwen3 technical report. arXiv preprint arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [34]
-
[35]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. In The eleventh international conference on learning representations
2022
- [36]
-
[37]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, and 1 others. 2025. Dapo: An open-source llm reinforcement learning system at scale. arXiv preprint arXiv:2503.14476
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Z.ai. 2025 a . https://z.ai/blog/glm-4.6 Glm-4.6: Advanced agentic, reasoning and coding capabilities
2025
-
[39]
Z.ai. 2025 b . https://z.ai/blog/glm-4.7 Glm-4.7: Advancing the coding capability
2025
- [40]
- [41]
-
[42]
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, and 1 others. 2025 a . Group sequence policy optimization. arXiv preprint arXiv:2507.18071
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Xuhui Zheng, Kang An, Ziliang Wang, Yuhang Wang, and Yichao Wu. 2025 b . Stepsearch: Igniting llms search ability via step-wise proximal policy optimization. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 21816--21841
2025
-
[44]
Yuxiang Zheng, Dayuan Fu, Xiangkun Hu, Xiaojie Cai, Lyumanshan Ye, Pengrui Lu, and Pengfei Liu. 2025 c . Deepresearcher: Scaling deep research via reinforcement learning in real-world environments. arXiv preprint arXiv:2504.03160
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[45]
Peilin Zhou, Bruce Leon, Xiang Ying, Can Zhang, Yifan Shao, Qichen Ye, Dading Chong, Zhiling Jin, Chenxuan Xie, Meng Cao, and 1 others. 2025. Browsecomp-zh: Benchmarking web browsing ability of large language models in chinese. arXiv preprint arXiv:2504.19314
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[46]
online" 'onlinestring :=
ENTRY address archivePrefix author booktitle chapter edition editor eid eprint eprinttype howpublished institution journal key month note number organization pages publisher school series title type volume year doi pubmed url lastchecked label extra.label sort.label short.list INTEGERS output.state before.all mid.sentence after.sentence after.block STRING...
-
[47]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in capitalize " " * FUNCT...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.