SAAS: Self-Aware Reinforcement Learning for Over-Search Mitigation in Agentic Search
Pith reviewed 2026-06-29 07:20 UTC · model grok-4.3
The pith
SAAS trains agentic LLMs to recognize their own knowledge limits and stop searching early.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
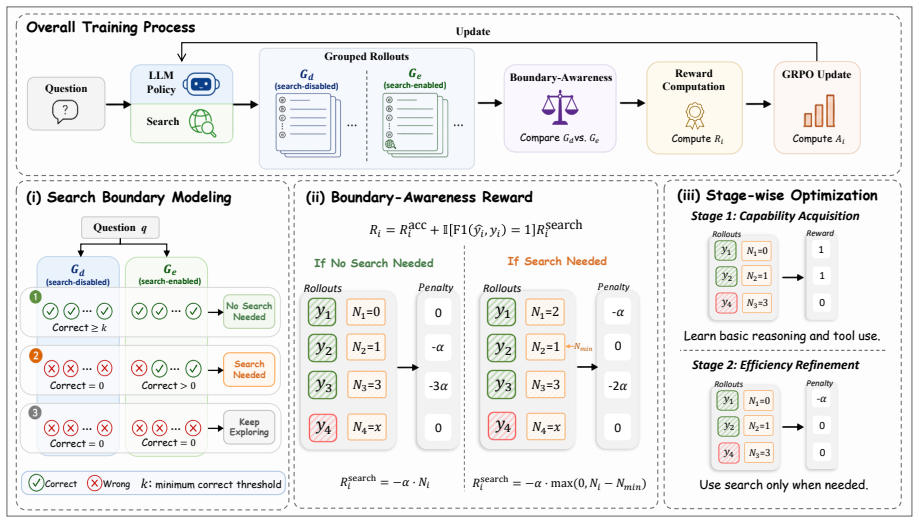
By contrasting search-disabled and search-enabled rollouts under the evolving policy, SAAS identifies a search boundary; a boundary-aware reward then penalizes trajectories that perform unnecessary or redundant searches, and a stage-wise curriculum first optimizes reasoning before applying the regularization to prevent reward hacking. This produces a policy that dynamically regulates search behavior according to its own knowledge limits.
What carries the argument
Search boundary modeling via contrasting search-disabled and search-enabled rollouts under the evolving policy, converted into boundary-aware trajectory penalties with stage-wise curriculum optimization.
If this is right
- Inference latency drops because the model issues fewer search calls per question.
- Computational cost falls from reduced external API usage and shorter trajectories.
- Answer accuracy on multi-hop questions stays the same as the unregularized baseline.
- The stage-wise curriculum prevents the reward signal from being exploited to avoid search entirely.
- The policy learns a dynamic rather than fixed threshold for when to search.
Where Pith is reading between the lines
- The same contrast-and-penalize pattern could be applied to other agent actions such as tool selection or memory lookup.
- If the boundary signal proves stable across model sizes, it offers a route to calibrate larger agents without extra labeled data.
- Real-world deployments could measure wall-clock time and token spend on production query logs to quantify the efficiency gain.
- Extending the boundary model to track confidence per reasoning step rather than per trajectory might further tighten search decisions.
Load-bearing premise
The boundary found by contrasting disabled and enabled rollouts truly marks where the model's internal knowledge ends, and the stage-wise training prevents the penalty from being gamed.
What would settle it
Run the trained policy on a set of questions where the model already answers correctly with search turned off; if the number of search calls remains high while accuracy stays flat, the boundary modeling does not reflect real knowledge limits.
Figures

read the original abstract
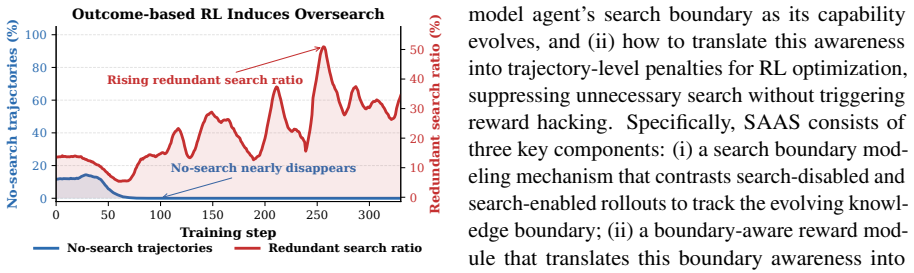
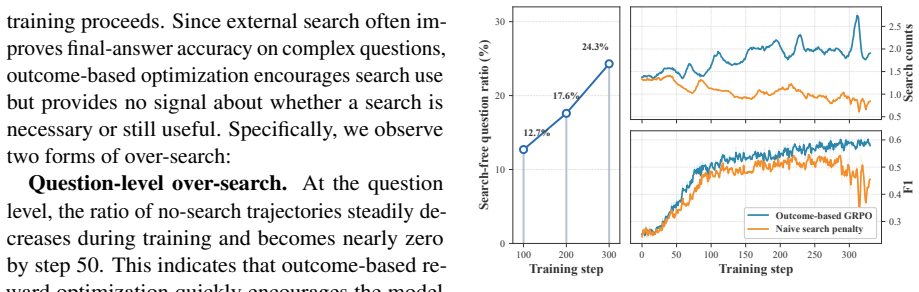
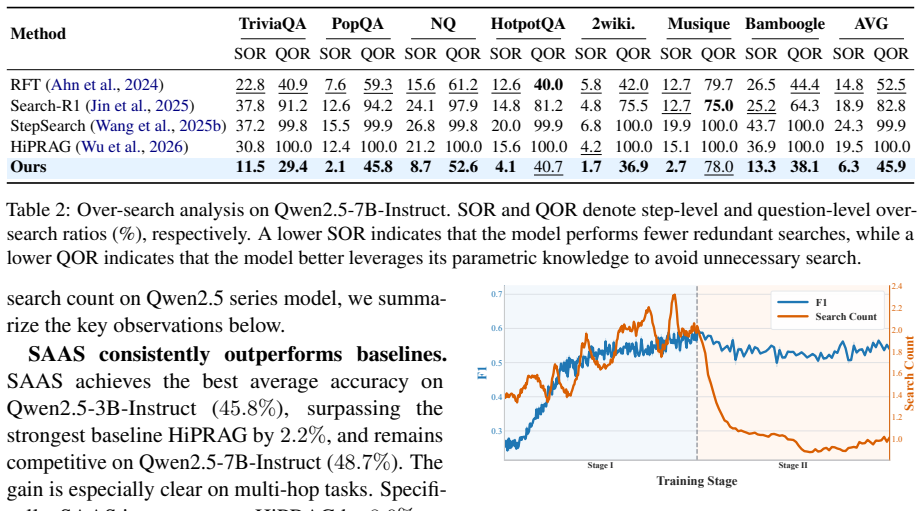
Agentic search enables LLMs to solve complex multi-hop questions through iterative reasoning and external search. Despite the effectiveness, these systems often suffer from a critical limitation in practice: agents fail to recognize their own knowledge boundaries, blindly triggering searches when internal knowledge suffices and failing to terminate search even when adequate evidence has been collected. The lack of self-awareness leads to severe \textbf{over-search}, incurring substantial inference latency and prohibitive computational cost. To this end, we propose SAAS, a novel RL framework designed to cultivate dynamic self-awareness that precisely regulates search behavior without compromising accuracy. SAAS introduces three key components: (i) a search boundary modeling mechanism, which identifies the search boundary under the evolving policy by contrasting search-disabled and search-enabled rollouts; (ii) a boundary-aware reward module, which translates this boundary awareness into trajectory-level penalties, suppressing unnecessary and redundant searches; and (iii) a stage-wise optimization strategy, which leverages a sequential curriculum to prioritize reasoning over search regularization, thereby avoiding reward hacking. Extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy. Our code and implementation details are released at https://github.com/XMUDeepLIT/SAAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAAS, an RL framework for agentic search in LLMs to address over-search caused by lack of self-awareness of knowledge boundaries. It introduces (i) search boundary modeling via contrast of search-disabled vs. search-enabled rollouts under the evolving policy, (ii) a boundary-aware reward module that applies trajectory-level penalties for unnecessary searches, and (iii) a stage-wise curriculum optimization to prioritize reasoning and avoid reward hacking. The central claim is that SAAS substantially reduces over-search while maintaining accuracy, with code released.
Significance. If the boundary contrast mechanism isolates genuine knowledge limits rather than training artifacts, the approach could meaningfully improve inference efficiency and cost in multi-hop agentic systems without accuracy trade-offs. Releasing code supports reproducibility, though the absence of detailed metrics in the provided text limits assessment of practical impact.
major comments (2)
- [Search boundary modeling mechanism] Search boundary modeling (described in abstract and §3): the claim that contrasting search-disabled and search-enabled rollouts under the evolving policy accurately identifies true knowledge boundaries lacks supporting stability analysis. Because the policy evolves during training, rollout distributions can diverge due to policy drift or optimization dynamics; no checks (e.g., boundary consistency across curriculum stages or against a frozen policy) are reported to rule out capture of artifacts rather than knowledge limits.
- [Experiments] Experiments section: the abstract states that 'extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy,' yet supplies no quantitative metrics, baselines, datasets, ablation results, or tables quantifying the reduction or accuracy preservation. This prevents evaluation of whether the central claim holds.
minor comments (1)
- [Abstract] The abstract refers to 'stage-wise optimization strategy' and 'sequential curriculum' without defining the stages or curriculum schedule in the provided text.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below, indicating planned revisions to improve the manuscript's clarity and rigor.
read point-by-point responses
-
Referee: [Search boundary modeling mechanism] Search boundary modeling (described in abstract and §3): the claim that contrasting search-disabled and search-enabled rollouts under the evolving policy accurately identifies true knowledge boundaries lacks supporting stability analysis. Because the policy evolves during training, rollout distributions can diverge due to policy drift or optimization dynamics; no checks (e.g., boundary consistency across curriculum stages or against a frozen policy) are reported to rule out capture of artifacts rather than knowledge limits.
Authors: We agree that explicit stability analysis would strengthen the presentation. The stage-wise curriculum is designed to limit policy drift by first optimizing reasoning before introducing boundary penalties, but we will add new experiments in the revised manuscript demonstrating boundary consistency across curriculum stages and comparisons against a frozen policy to confirm that the contrast mechanism captures genuine knowledge limits. revision: yes
-
Referee: [Experiments] Experiments section: the abstract states that 'extensive experiments demonstrate that SAAS substantially reduces over-search, while maintaining accuracy,' yet supplies no quantitative metrics, baselines, datasets, ablation results, or tables quantifying the reduction or accuracy preservation. This prevents evaluation of whether the central claim holds.
Authors: The full manuscript includes an Experiments section with quantitative results, but we acknowledge that these details were not sufficiently highlighted or summarized for easy assessment. In the revision we will add explicit tables and metrics (including over-search reduction percentages, accuracy on datasets such as HotpotQA, baseline comparisons, and ablations) and ensure a concise summary of key numbers appears in the abstract or introduction. revision: yes
Circularity Check
No circularity: procedural RL components defined independently of target outcomes.
full rationale
The paper introduces SAAS as an RL framework with three explicitly described components: rollout-contrast boundary modeling, trajectory-level penalty rewards, and stage-wise curriculum. No equations, derivations, or self-citations appear that reduce any claimed result (e.g., over-search reduction) to a fitted parameter or self-referential definition. Boundary identification is a defined procedure under the evolving policy rather than a prediction forced by construction. The central claims rest on experimental outcomes rather than algebraic equivalence to inputs. This is the normal non-circular case for a methods paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Qwen3 technical report.arXiv preprint arXiv:2505.09388. Chang Yang, Chuang Zhou, Yilin Xiao, Su Dong, Luyao Zhuang, Yujing Zhang, Zhu Wang, Zijin Hong, Zheng Yuan, Zhishang Xiang, and 1 others. 2026. Graph-based agent memory: Taxonomy, techniques, and applications.arXiv preprint arXiv:2602.05665. Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Ben- gio, Will...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Sugar: Leveraging contextual confidence for smarter retrieval.Preprint, arXiv:2501.04899. A Frequently Asked Questions (FAQs) A.1 Code and Data Availability To facilitate future research and allow independent verification of our results, all code and data as- sociated with SAAS are released via an anony- mous repository: https://anonymous.4open. science/r...
-
[3]
Correct" if they are equivalent, or
fine-tunes the model on trajectories se- lected through rejection sampling. For each train- 18 LLM-as-a-Judge Evaluation You are an evaluation assistant. Please determine if the model output is equivalent to the labeled answer. Question: {question} Labeled Answer: {labeled answer} Model Output: {pred answer} Did the model give an answer equivalent to the ...
2025
-
[4]
Other works focus on adaptive exploration
trains intrinsically search-efficient models, Search Wisely (Wu et al., 2025a) mitigates unnec- essary searches by reducing model uncertainty, and IKEA (Huang et al., 2025) introduces a knowledge- boundary aware reward to prioritize parametric knowledge and resort to search only when internal knowledge is insufficient. Other works focus on adaptive explor...
2025
-
[5]
evaluates and refines individual steps using process rewards. HiPRAG (Wu et al., 2026) and parallel works on process rewards (Ye et al., 2025; Yue et al., 2025) introduce hierarchical supervi- sion to constrain reasoning paths and curb over- searching. Despite these advances, these methods often lack a unified mechanism to trigger and halt search based on...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.