Inferring Code Correctness from Specification
Pith reviewed 2026-06-29 06:31 UTC · model grok-4.3
The pith
TRAILS infers code correctness by checking if input-output pairs from spec-based tests conform to the specification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
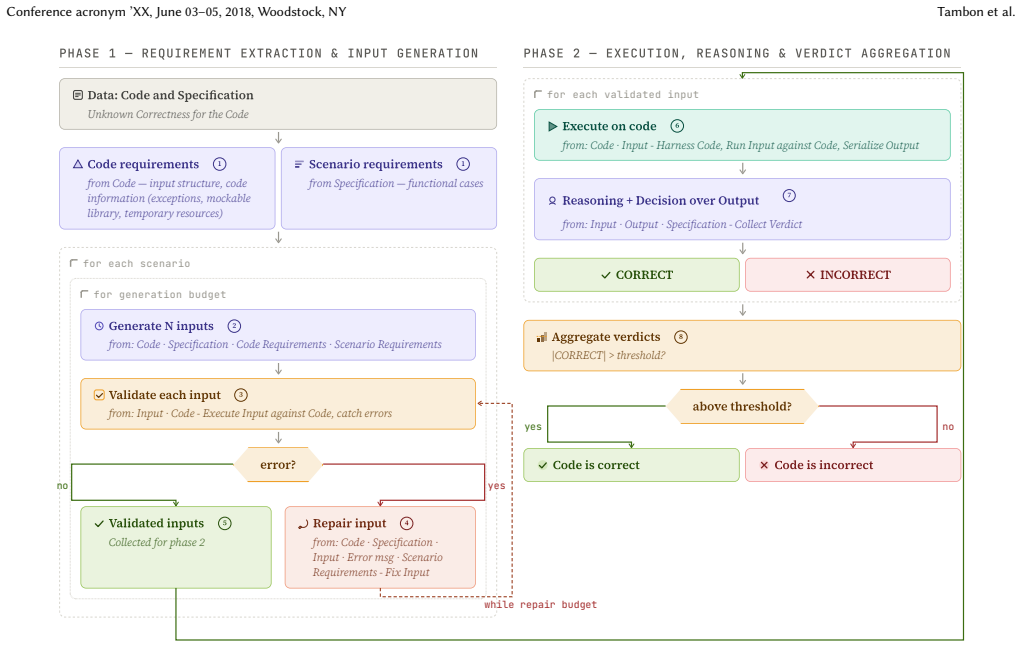
TRAILS grounds LLM reasoning with concrete input-output pairs by generating test inputs via category partitioning based on the specification, executing the candidate code, and prompting LLMs to assess conformance to the specification without reasoning over the code, then aggregating scores to determine if the program is likely correct.
What carries the argument
The TRAILS method using category partitioning to create test inputs for LLM assessment of input-output pair conformance to the specification.
If this is right
- Code correctness can be determined without inspecting or reasoning over the code itself.
- The method reduces sensitivity to LLM non-determinism through grounding in concrete executions.
- It assigns correct labels to a larger set of unique code samples than prior approaches.
- Verification avoids the cost of dynamic consensus across multiple code candidates.
Where Pith is reading between the lines
- This approach might apply to verifying code generated by other means beyond LLMs.
- Combining category partitioning with execution could enhance other specification-based verification techniques.
- Such methods could lead to more reliable automated software development pipelines.
- Testing the limits of LLM judgment accuracy on input-output pairs would be a natural next step.
Load-bearing premise
LLM judgments of whether input-output pairs conform to the specification are accurate enough and the category-partitioned inputs are diverse enough to reveal incorrect code.
What would settle it
A demonstration that faulty code passes all category-partitioned tests with LLM judgments indicating conformance, or that correct code is incorrectly flagged due to LLM misjudgment on the pairs.
Figures

read the original abstract
Large language models (LLMs) have become integral to modern software development, enabling automated code generation at scale. However, validating the correctness of LLM-generated code remains a critical and largely unsolved challenge. Existing approaches either rely on dynamic consensus across multiple code candidates - making them costly and difficult to scale - or on static reasoning that is susceptible to dynamic bugs and order bias. In this paper, we propose TRAILS~ (Targeted Reasoning Agreement via Inputs and Specifications), an approach that grounds LLM reasoning with concrete (input, output) pairs. TRAILS~ first generates diverse test inputs via category partitioning based on the specification, then executes them against the candidate code and prompts LLMs to assess whether the resulting input-output pairs conform to the specification - without ever reasoning over the code itself. Scores are aggregated across inputs, to determines whether the program is likely correct. We evaluate TRAILS~ on two datasets, LiveCodeBench and CoCoClaNeL, across three LLMs (Qwen3Coder-30B, Devstral-Small-24B, and Olmo3.1-Instruct), comparing against HoarePrompt and a Zero-Shot Chain-of-Thought baseline. TRAILS~ improves Matthew Correlation Coefficient by up to 39\% relative to Zero-Shot COT and consistently outperforms HoarePrompt. Beyond accuracy, TRAILS~ demonstrates greater stability across seeded runs, reducing sensitivity to LLM non-determinism, and assigns correct labels to a larger set of unique code samples than competing approaches.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes TRAILS (Targeted Reasoning Agreement via Inputs and Specifications), a method to infer the correctness of LLM-generated code. TRAILS generates diverse test inputs via category partitioning based on the specification, executes the candidate code on these inputs, and prompts LLMs to assess whether the resulting input-output pairs conform to the specification without ever reasoning over the code itself. Scores are aggregated across inputs to determine whether the program is likely correct. The approach is evaluated on LiveCodeBench and CoCoClaNeL across three LLMs (Qwen3Coder-30B, Devstral-Small-24B, Olmo3.1-Instruct), claiming up to 39% relative MCC improvement over Zero-Shot CoT, consistent outperformance of HoarePrompt, and greater stability across seeded runs.
Significance. If the results hold under rigorous validation, the work would offer a scalable, code-agnostic alternative to consensus-based or static-reasoning methods for validating generated code, directly leveraging specifications and concrete executions. The reported stability across runs addresses a practical concern with LLM non-determinism. The empirical nature of the gains is a strength, but the absence of supporting experimental details limits assessment of whether the improvements are attributable to the TRAILS design.
major comments (2)
- [Abstract] Abstract: the reported MCC gains (up to 39% relative to Zero-Shot COT) and stability benefits are presented without details on statistical significance, error bars, exact test-generation procedure, aggregation method, or potential selection effects in the datasets. These omissions are load-bearing for the central empirical claim.
- [Abstract] The method (as described in the abstract) rests on the assumption that aggregated LLM judgments of IO-spec conformance are sufficiently accurate proxies for code correctness. No validation, error analysis, human evaluation of judgment accuracy, or analysis of failure modes (e.g., misreading subtle violations) is provided; because the approach never inspects the code, systematic LLM misjudgment would directly produce incorrect labels and undermine attribution of the reported improvements to TRAILS.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and methodological assumptions. We address each major comment below and indicate planned revisions to strengthen the presentation of results and analysis.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported MCC gains (up to 39% relative to Zero-Shot COT) and stability benefits are presented without details on statistical significance, error bars, exact test-generation procedure, aggregation method, or potential selection effects in the datasets. These omissions are load-bearing for the central empirical claim.
Authors: We agree the abstract would benefit from greater self-containment. The full manuscript details category partitioning for input generation in Section 3.2, score aggregation via averaged LLM conformance judgments in Section 3.3, and reports MCC values with standard deviations across five seeded runs in Table 2 and the stability analysis in Section 5.2. Datasets use the complete public splits of LiveCodeBench and CoCoClaNeL with no additional selection. We will revise the abstract to briefly note the multi-run protocol, test-generation method, and aggregation approach, and add a parenthetical reference to statistical consistency across seeds. revision: yes
-
Referee: [Abstract] The method (as described in the abstract) rests on the assumption that aggregated LLM judgments of IO-spec conformance are sufficiently accurate proxies for code correctness. No validation, error analysis, human evaluation of judgment accuracy, or analysis of failure modes (e.g., misreading subtle violations) is provided; because the approach never inspects the code, systematic LLM misjudgment would directly produce incorrect labels and undermine attribution of the reported improvements to TRAILS.
Authors: This is a substantive concern regarding the core assumption. The manuscript demonstrates empirical gains over baselines that also rely on LLM reasoning, but does not include direct human validation or systematic error analysis of the judge outputs. We will add a dedicated subsection in the revised version that samples judgments for manual review, reports inter-annotator agreement with ground-truth code correctness on a held-out subset, and discusses observed failure modes such as overlooked edge-case violations. This addition will clarify the conditions under which the proxy holds. revision: yes
Circularity Check
No circularity: purely empirical evaluation on external baselines
full rationale
The paper describes an empirical technique (TRAILS) that generates category-partitioned inputs, executes code, and aggregates LLM judgments of spec conformance. No equations, parameters, or first-principles derivations are present. Reported gains (MCC improvements, stability) are direct experimental comparisons against named public datasets and external baselines (HoarePrompt, Zero-Shot COT). No self-citation is invoked to justify uniqueness or to close a derivation loop; the method's validity rests on observable run-time behavior rather than any reduction to its own inputs or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[n. d.]. Devstral-Small2. https://devstralsmall2.com/. Accessed: 2026-03-06
2026
-
[2]
[n. d.]. ReplicationPackage. Under construction
-
[3]
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, et al. 2025. Gepa: Reflective prompt evolution can outperform reinforcement learning.arXiv preprint arXiv:2507.19457(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [4]
- [5]
-
[6]
Bei Chen, Fengji Zhang, Anh Nguyen, Daoguang Zan, Zeqi Lin, Jian-Guang Lou, and Weizhu Chen. 2022. Codet: Code generation with generated tests.arXiv preprint arXiv:2207.10397(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
- [7]
-
[8]
Yinghao Chen, Zehao Hu, Chen Zhi, Junxiao Han, Shuiguang Deng, and Jianwei Yin. 2024. Chatunitest: A framework for llm-based test generation. InCompan- ion Proceedings of the 32nd ACM International Conference on the Foundations of Software Engineering. 572–576
2024
- [9]
-
[10]
Zhiyu Fan, Haifeng Ruan, Sergey Mechtaev, and Abhik Roychoudhury. 2024. Oracle-Guided Program Selection from Large Language Models. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis (Vienna, Austria)(ISSTA 2024). Association for Computing Machinery, New York, NY, USA, 628–640. doi:10.1145/3650212.3680308
- [11]
-
[12]
Molly Q Feldman and Carolyn Jane Anderson. 2024. Non-expert programmers in the generative AI future. InProceedings of the 3rd annual meeting of the symposium on human-computer interaction for work. 1–19
2024
- [13]
-
[14]
2010.Robust nonparametric statistical methods
Thomas P Hettmansperger and Joseph W McKean. 2010.Robust nonparametric statistical methods. CRC press
2010
-
[15]
Soneya Binta Hossain and Matthew B Dwyer. 2025. Togll: Correct and strong test oracle generation with llms. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). IEEE, 1475–1487
2025
-
[16]
Soneya Binta Hossain and Matthew B. Dwyer. 2025. TOGLL: Correct and Strong Test Oracle Generation with LLMS. In2025 IEEE/ACM 47th International Confer- ence on Software Engineering (ICSE). 1475–1487. doi:10.1109/ICSE55347.2025.000 98
- [17]
-
[18]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, et al. 2024. Qwen2. 5-Coder Technical Report.arXiv preprint arXiv:2409.12186(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [19]
- [20]
-
[21]
Caroline Lemieux, Jeevana Priya Inala, Shuvendu K Lahiri, and Siddhartha Sen
-
[22]
In2023 IEEE/ACM 45th International Conference on Soft- ware Engineering (ICSE)
Codamosa: Escaping coverage plateaus in test generation with pre-trained large language models. In2023 IEEE/ACM 45th International Conference on Soft- ware Engineering (ICSE). IEEE, 919–931
-
[23]
Yujia Li, David Choi, Junyoung Chung, Nate Kushman, Julian Schrittwieser, Rémi Leblond, Tom Eccles, James Keeling, Felix Gimeno, Agustin Dal Lago, et al. 2022. Competition-level code generation with alphacode.Science378, 6624 (2022), 1092–1097
2022
-
[24]
Jiawei Liu, Chunqiu Steven Xia, Yuyao Wang, and Lingming Zhang. 2023. Is your code generated by chatgpt really correct? rigorous evaluation of large language models for code generation.Advances in neural information processing systems 36 (2023), 21558–21572
2023
-
[26]
Noble Saji Mathews and Meiyappan Nagappan. 2024. Test-Driven Development and LLM-based Code Generation. InProceedings of the 39th IEEE/ACM Interna- tional Conference on Automated Software Engineering(Sacramento, CA, USA) (ASE ’24). Association for Computing Machinery, New York, NY, USA, 1583–1594. doi:10.1145/3691620.3695527
-
[27]
Jain Naman, Han King, Gu Alex, Li Wen-Ding, Yan Fanjia, Zhang Tianjun, Wang Sida, Solar-Lezama Armando, Sen Koushik, and Stoica Ion. 2024. LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code. arXiv preprint(2024)
2024
-
[28]
Team Olmo, Allyson Ettinger, Amanda Bertsch, Bailey Kuehl, David Graham, David Heineman, Dirk Groeneveld, Faeze Brahman, Finbarr Timbers, Hamish Ivison, Jacob Morrison, Jake Poznanski, Kyle Lo, Luca Soldaini, Matt Jordan, Mayee Chen, Michael Noukhovitch, Nathan Lambert, Pete Walsh, Pradeep Dasigi, Robert Berry, Saumya Malik, Saurabh Shah, Scott Geng, Shan...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Nearchos Potamitis, Lars Klein, and Akhil Arora. 2025. ReasonBENCH: Bench- marking the (In) Stability of LLM Reasoning.arXiv preprint arXiv:2512.07795 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[30]
Nikitha Rao, Kush Jain, Uri Alon, Claire Le Goues, and Vincent J Hellendoorn
-
[31]
In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE)
CAT-LM training language models on aligned code and tests. In2023 38th IEEE/ACM International Conference on Automated Software Engineering (ASE). IEEE, 409–420
-
[32]
Max Schäfer, Sarah Nadi, Aryaz Eghbali, and Frank Tip. 2023. An empirical evaluation of using large language models for automated unit test generation. IEEE Transactions on Software Engineering50, 1 (2023), 85–105
2023
-
[33]
Lin Shi, Chiyu Ma, Wenhua Liang, Xingjian Diao, Weicheng Ma, and Soroush Vosoughi. 2025. Judging the judges: A systematic study of position bias in llm- as-a-judge. InProceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics. 292–314
2025
- [34]
-
[35]
Philipp Straubinger and Gordon Fraser. 2023. A survey on what developers think about testing. In2023 IEEE 34th International Symposium on Software Reliability Engineering (ISSRE). IEEE, 80–90
2023
-
[36]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [37]
-
[38]
Zhilong Wang, Lan Zhang, Chen Cao, Nanqing Luo, Xinzhi Luo, and Peng Liu
- [39]
-
[40]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models.Advances in neural information processing systems35 (2022), 24824–24837
2022
-
[41]
Lin Yang, Chen Yang, Shutao Gao, Weijing Wang, Bo Wang, Qihao Zhu, Xiao Chu, Jianyi Zhou, Guangtai Liang, Qianxiang Wang, et al. 2024. On the evaluation of large language models in unit test generation. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering. 1607–1619
2024
-
[42]
G Udny Yule. 1912. On the methods of measuring association between two attributes.Journal of the Royal Statistical Society75, 6 (1912), 579–652
1912
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.