Towards Verifiable Multimodal Deep Research: A Multi-Agent Harness for Interleaved Report Generation
Pith reviewed 2026-06-29 07:49 UTC · model grok-4.3
The pith
Ptah is a multi-agent harness that uses a verifier to enforce factual grounding and cross-modal consistency when generating interleaved multimodal research reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
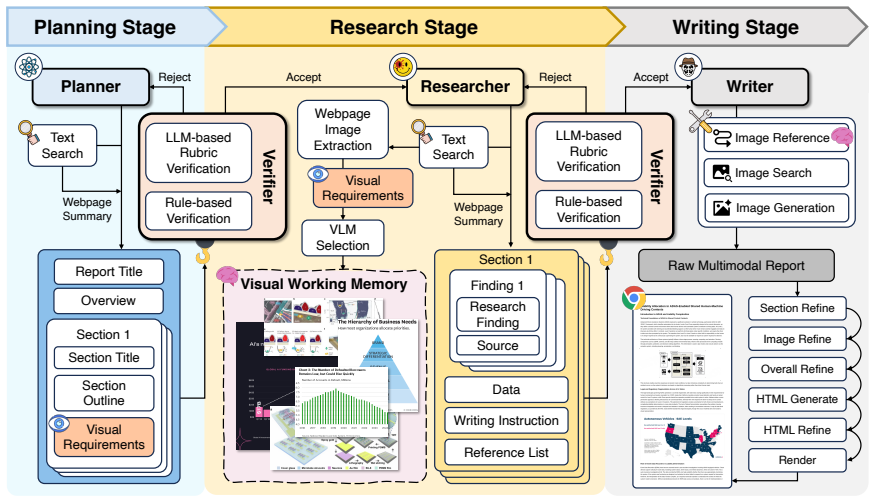
Ptah orchestrates the full lifecycle from user query to rendered web report through planning, research, and writing stages in which specialized agents construct visual-aware plans, collect claim-grounded evidence, maintain source-aligned images in a Visual Working Memory, and compose reports through declarative multimodal tool use, with a verifier agent serving as the acceptance function that enforces factual grounding, citation fidelity, and cross-modal consistency throughout the workflow.
What carries the argument
The verifier agent that acts as the harness acceptance function, checking factual grounding, citation fidelity, and cross-modal consistency at every stage.
If this is right
- Reports can interleave textual arguments with source-aligned visual evidence while preserving traceability.
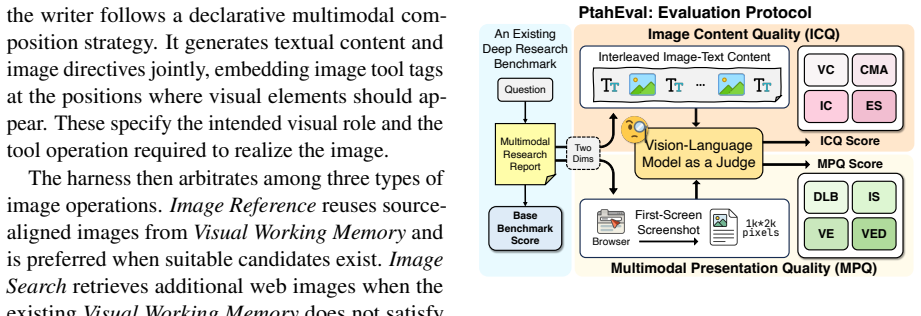
- Existing deep-research benchmarks can be extended with image-level and presentation-level assessments via PtahEval.
- The multi-agent workflow can be applied to other open-ended synthesis tasks that require both text and visuals.
- Releasing the code allows direct replication and extension on additional benchmarks.
Where Pith is reading between the lines
- If the verifier scales reliably, similar harnesses could reduce hallucinations in other long-form generation settings such as technical documentation or policy analysis.
- The Visual Working Memory mechanism suggests a general pattern for keeping evidence aligned across modalities without full retraining of base models.
- PtahEval's added metrics could become standard for any system that outputs rendered web-style reports rather than plain text.
Load-bearing premise
A verifier agent can reliably enforce factual grounding, citation fidelity, and cross-modal consistency throughout the workflow even when there is no deterministic ground truth for open-ended synthesis.
What would settle it
A set of generated reports in which the verifier passes outputs that contain verifiable factual errors, mismatched citations, or images that contradict the accompanying text.
Figures


read the original abstract
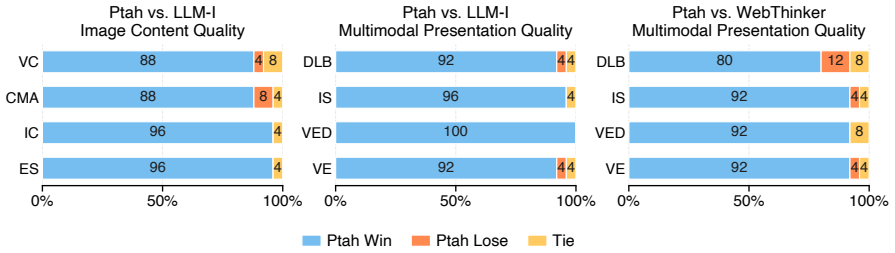
Large Language Models (LLMs) have advanced autonomous agents from deep search, which retrieves concise factual answers, to deep research, which synthesizes scattered evidence into long-form reports. However, verifiable multimodal deep research remains challenging due to open-ended synthesis without deterministic ground truth and the need to interleave textual arguments with visual evidence. We propose Ptah, a multi-agent harness for interleaved report generation. Ptah orchestrates the lifecycle from user query to rendered web report through planning, research, and writing stages, where specialized agents construct visual-aware plans, collect claim-grounded evidence, maintain source-aligned images in a Visual Working Memory, and compose reports through declarative multimodal tool use. A verifier agent serves as the harness's acceptance function, enforcing factual grounding, citation fidelity, and cross-modal consistency throughout the workflow. We further introduce PtahEval, an evaluation protocol that augments existing benchmarks with image-level and presentation-level assessments. Experiments on deep research benchmarks show that Ptah produces more reliable, visually informative, and usable human-facing multimodal reports than strong baselines. Our code is released at https://github.com/SnowNation101/Ptah
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Ptah, a multi-agent harness for generating verifiable interleaved multimodal reports in deep research tasks. It orchestrates planning, research, and writing stages via specialized agents that construct visual-aware plans, collect claim-grounded evidence, maintain source-aligned images in a Visual Working Memory, and compose reports through declarative multimodal tools. A verifier agent acts as the acceptance function to enforce factual grounding, citation fidelity, and cross-modal consistency. The work also proposes PtahEval, an evaluation protocol augmenting benchmarks with image-level and presentation-level assessments, and claims that Ptah yields more reliable, visually informative, and usable reports than strong baselines on deep research benchmarks. Code is released at the provided GitHub link.
Significance. If the claims hold under rigorous validation, the framework could advance autonomous agents for trustworthy multimodal synthesis by providing a structured harness and evaluation protocol for open-ended research reports. The public code release and introduction of PtahEval are concrete strengths that support reproducibility and future benchmarking in verifiable AI research.
major comments (2)
- [Abstract and §3] Abstract and §3 (system description): The headline claim that Ptah produces more reliable multimodal reports depends on the verifier agent reliably enforcing factual grounding, citation fidelity, and cross-modal consistency. Yet the manuscript provides no implementation details, training procedure, ablation studies, error-injection tests, or reliability metrics (e.g., agreement with human judgments) for this verifier, despite explicitly noting the absence of deterministic ground truth for open-ended synthesis. This leaves open whether observed gains on PtahEval stem from the verifier or from planning/writing agents and Visual Working Memory.
- [§4] §4 (Experiments) and PtahEval description: No quantitative metrics, baseline comparisons, error analysis, or inter-annotator agreement scores are reported for the verifier's decisions or the augmented image/presentation assessments. Without these, it is impossible to determine whether the reported improvements are supported by the data or methods, weakening the cross-benchmark claim.
minor comments (2)
- [§3] The term 'Visual Working Memory' is introduced without reference to related concepts in cognitive modeling or prior AI literature on memory-augmented agents.
- [§4] PtahEval is described as augmenting existing benchmarks, but the specific benchmarks used and the exact augmentation procedure (e.g., how image-level annotations are generated) are not detailed enough for replication.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We agree that the manuscript requires additional detail on the verifier agent and quantitative support for the evaluations. We will revise accordingly to strengthen the presentation of these components.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (system description): The headline claim that Ptah produces more reliable multimodal reports depends on the verifier agent reliably enforcing factual grounding, citation fidelity, and cross-modal consistency. Yet the manuscript provides no implementation details, training procedure, ablation studies, error-injection tests, or reliability metrics (e.g., agreement with human judgments) for this verifier, despite explicitly noting the absence of deterministic ground truth for open-ended synthesis. This leaves open whether observed gains on PtahEval stem from the verifier or from planning/writing agents and Visual Working Memory.
Authors: We acknowledge that the current description of the verifier is high-level and insufficient to support the headline claims. The verifier is implemented as a prompt-based LLM agent (no fine-tuning) that applies a fixed set of checks; however, we agree this must be made explicit. In the revision we will (1) move the full system prompts and decision criteria into the main text of §3, (2) add an ablation that disables the verifier while keeping all other components fixed, (3) report error-injection results on a held-out set of reports, and (4) provide agreement statistics between the verifier and human raters on a sampled subset. These additions will clarify the verifier’s contribution relative to the planning, research, and Visual Working Memory modules. revision: yes
-
Referee: [§4] §4 (Experiments) and PtahEval description: No quantitative metrics, baseline comparisons, error analysis, or inter-annotator agreement scores are reported for the verifier's decisions or the augmented image/presentation assessments. Without these, it is impossible to determine whether the reported improvements are supported by the data or methods, weakening the cross-benchmark claim.
Authors: We agree that the experimental section is missing the requested quantitative backing. In the revised manuscript we will add: (i) precision/recall figures for the verifier on injected factual and citation errors, (ii) direct baseline comparisons of the image-level and presentation-level scores produced by PtahEval, (iii) a concise error analysis of cases where the verifier accepted or rejected reports, and (iv) inter-annotator agreement (Cohen’s κ) for both the human image/presentation ratings and the verifier-human agreement. These statistics were collected during our internal evaluation but were omitted; they will be reported with the next version. revision: yes
Circularity Check
No circularity: independent system proposal with released code and benchmark evaluation
full rationale
The paper proposes an engineering architecture (multi-agent harness with planning/research/writing/verifier stages plus PtahEval protocol) and reports comparative experiments on existing benchmarks augmented with image/presentation metrics. No equations, fitted parameters, or derivations appear in the provided text. The central claims rest on observable outputs versus baselines rather than any self-referential definition, renamed empirical pattern, or load-bearing self-citation chain. Released code further renders the contribution externally inspectable and falsifiable, satisfying the default expectation of a self-contained non-circular proposal.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be effectively orchestrated as specialized agents for planning, evidence collection, report composition, and verification.
- ad hoc to paper A dedicated verifier agent can enforce factual grounding and cross-modal consistency without access to deterministic ground truth.
invented entities (2)
-
Visual Working Memory
no independent evidence
-
PtahEval
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Emerging properties in unified multimodal pretraining.CoRR, abs/2505.14683. Guanting Dong, Licheng Bao, Zhongyuan Wang, Kangzhi Zhao, Xiaoxi Li, Jiajie Jin, Jinghan Yang, Hangyu Mao, Fuzheng Zhang, Kun Gai, Guorui Zhou, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. 2025a. Agentic entropy-balanced policy optimiza- tion.CoRR, abs/2510.14545. Guanting Dong, Yife...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Show-o2: Improved Native Unified Multimodal Models
OpenReview.net. Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. 2025b. Show-o2: Improved native unified multi- modal models.CoRR, abs/2506.15564. An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Day- iheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, J...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.