LLM-Guided Future Hypotheses for Horizon-Aware Exploration in Multi-Step Robot Manipulation
Pith reviewed 2026-06-29 06:33 UTC · model grok-4.3
The pith
Short-horizon future videos generated through LLM reasoning and video diffusion provide useful structured priors for closed-loop robot policies in multi-step manipulation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
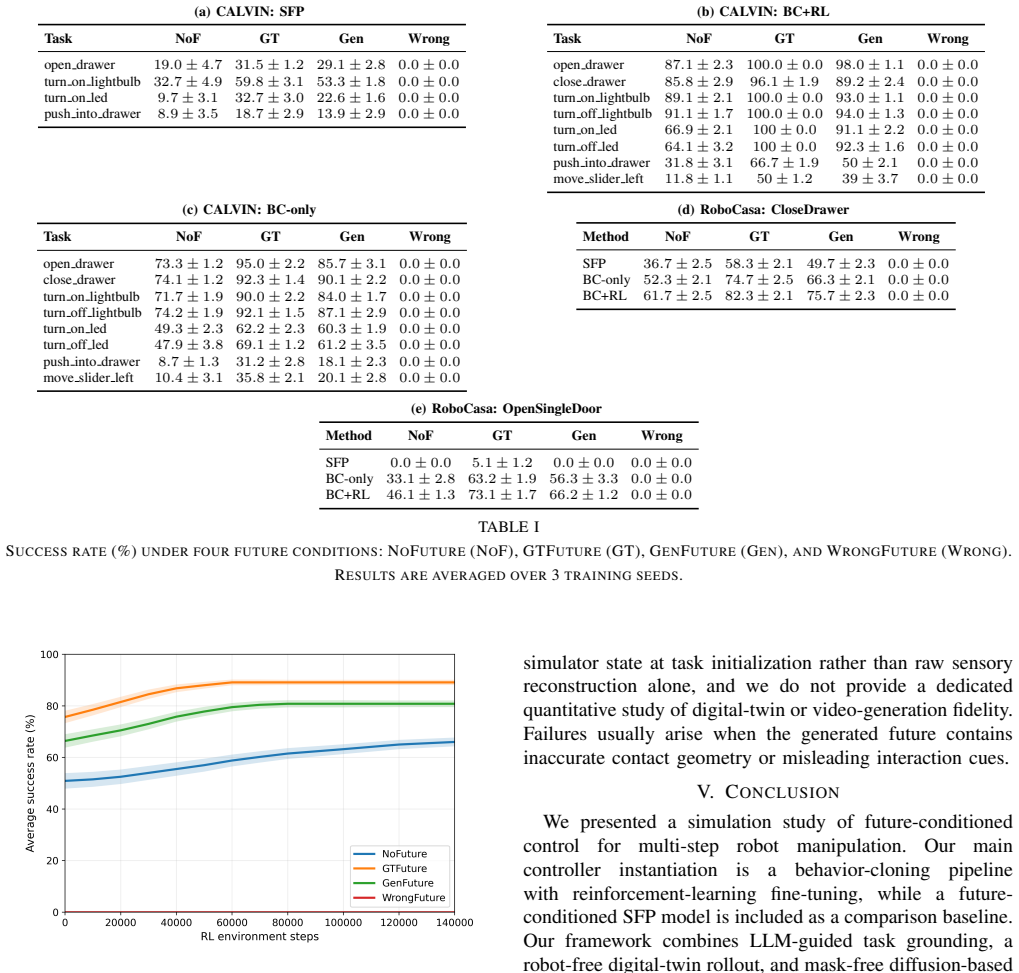
Short-horizon, task-consistent future videos serve as useful structured priors for control and reinforcement-learning fine-tuning in multi-step robot manipulation, as formalized by the Future-Experience Conditioning interface that conditions policies on a latent future-video representation; generated futures improve performance over no-future conditioning while mismatched futures degrade it, and the BC+RL instantiation reaches the highest overall results.
What carries the argument
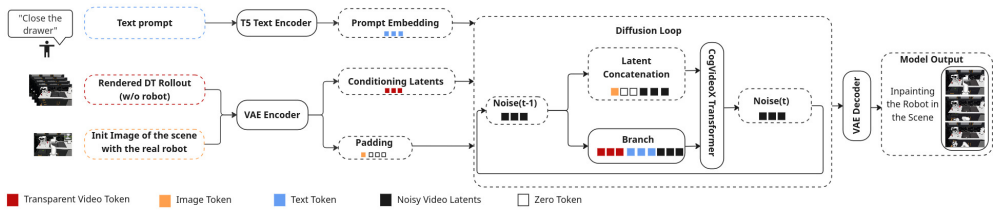
Future-Experience Conditioning (FEC), the interface that conditions closed-loop policies on a latent representation of a short future video produced by LLM reasoning, digital-twin rollout, and video diffusion.
If this is right
- Generated futures improve performance over no-future conditioning on the tested RoboCasa and CALVIN setups.
- Mismatched futures degrade performance relative to no-future baselines.
- The BC+RL instantiation with future conditioning produces the strongest overall results.
- Across eight CALVIN tasks the GTFuture condition improves fastest while GenFuture reaches higher levels earlier than NoFuture and WrongFuture remains at zero.
- Short-horizon future videos can function as useful structured priors even under imperfect predictions.
Where Pith is reading between the lines
- If the accuracy of the three-stage future generator improves, the same conditioning approach could support longer prediction horizons without retraining the policy stack.
- The separation between future generation and policy learning may allow reuse of the same generated clips across multiple tasks that share the underlying object ontology.
- The observed degradation under WrongFuture suggests that future conditioning could be combined with uncertainty estimation to fall back to no-future mode when prediction is unreliable.
- The learning-curve separation implies that future priors could reduce the number of environment interactions needed to reach a target success rate in new manipulation scenarios.
Load-bearing premise
The three-stage generation process produces robot-consistent future clips that serve as useful structured priors for closed-loop control and RL fine-tuning even when predictions are imperfect.
What would settle it
A controlled replication on the CALVIN benchmark in which the GenFuture condition yields no higher success rate or slower learning than the NoFuture condition across random seeds would falsify the claim that generated futures supply useful priors.
Figures


read the original abstract
Multi-step robot manipulation requires acting under uncertainty about how the scene will evolve, making exploration and policy adaptation challenging. We study whether short-horizon, task-consistent future videos can provide useful structured priors for control and reinforcement-learning fine-tuning. We formalize this idea through Future-Experience Conditioning (FEC), a simple interface that conditions closed-loop policies on a latent representation of a short future video. In our simulation setup, future clips are generated in three stages, an LLM reasoner operating over a task ontology initialized from the current scene state, a robot-free digital-twin rollout of the intended object motion, and a mask-free video diffusion model that synthesizes a robot-consistent future clip without requiring segmentation at inference. We instantiate this future-conditioning interface primarily with BC and BC+RL, and compare against a future-conditioned Streaming Flow Policy (SFP) baseline on RoboCasa and CALVIN under NoFuture, GTFuture, GenFuture, and WrongFuture. Generated futures improve performance over no-future conditioning, while mismatched futures degrade it, and our BC+RL instantiation achieves the strongest overall results. An average BC+RL learning-curve analysis across 8 CALVIN tasks further shows that GTFuture improves fastest, GenFuture improves earlier and to a higher level than NoFuture, and WrongFuture remains at zero throughout training. These results suggest that short-horizon future videos can serve as useful structured priors for exploration and policy adaptation under imperfect future predictions. https://enact2026.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Future-Experience Conditioning (FEC), an interface that conditions closed-loop robot policies on latent representations of short-horizon future videos. Futures are generated via a three-stage pipeline (LLM reasoner over task ontology, robot-free digital-twin rollout, mask-free video diffusion). Experiments on RoboCasa and CALVIN compare BC, BC+RL, and Streaming Flow Policy instantiations under NoFuture, GTFuture, GenFuture, and WrongFuture conditions. The central empirical claim is that GenFuture improves performance over NoFuture while WrongFuture degrades it, with BC+RL achieving the strongest results; average BC+RL learning curves across 8 CALVIN tasks show GTFuture improving fastest, GenFuture outperforming NoFuture, and WrongFuture remaining at zero.
Significance. If the directional results hold under full reporting, the work provides controlled evidence that imperfect but task-consistent short-horizon video futures can act as useful structured priors for exploration and policy adaptation in multi-step manipulation. The explicit ablations (GTFuture vs. GenFuture vs. WrongFuture) and learning-curve ordering across multiple tasks strengthen the case that consistency, rather than mere presence of future conditioning, drives the gains. The approach is notable for its robot-free generation pipeline and direct integration with both BC and RL fine-tuning.
major comments (2)
- [Experimental results and learning-curve analysis] The abstract and learning-curve analysis report consistent directional improvements and differential training speeds, yet the manuscript provides no error bars, standard deviations, full per-task metrics, or statistical significance tests for the RoboCasa and CALVIN comparisons. This absence makes it impossible to assess whether the reported gains (GenFuture over NoFuture, BC+RL strongest) exceed noise.
- [Method and pipeline description] The central claim rests on the assumption that the three-stage pipeline (LLM reasoner + digital-twin rollout + video diffusion) yields robot-consistent clips usable as priors even when imperfect. No quantitative measures of prediction accuracy, robot-action consistency, or failure modes of the generated futures are reported, leaving the weakest assumption untested.
minor comments (1)
- [Future-Experience Conditioning interface] Notation for the FEC latent representation and how it is injected into the policy (e.g., concatenation, cross-attention) should be formalized with an equation or diagram.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below, agreeing where the manuscript requires strengthening and providing our strongest honest defense on the pipeline evaluation.
read point-by-point responses
-
Referee: [Experimental results and learning-curve analysis] The abstract and learning-curve analysis report consistent directional improvements and differential training speeds, yet the manuscript provides no error bars, standard deviations, full per-task metrics, or statistical significance tests for the RoboCasa and CALVIN comparisons. This absence makes it impossible to assess whether the reported gains (GenFuture over NoFuture, BC+RL strongest) exceed noise.
Authors: We agree that the absence of error bars, standard deviations, per-task breakdowns, and significance tests limits the strength of the claims. In the revised manuscript we will add these: results from multiple random seeds, standard deviations on all reported metrics, full per-task tables for both RoboCasa and CALVIN, and appropriate statistical tests comparing GenFuture vs. NoFuture and BC+RL vs. other instantiations. revision: yes
-
Referee: [Method and pipeline description] The central claim rests on the assumption that the three-stage pipeline (LLM reasoner + digital-twin rollout + video diffusion) yields robot-consistent clips usable as priors even when imperfect. No quantitative measures of prediction accuracy, robot-action consistency, or failure modes of the generated futures are reported, leaving the weakest assumption untested.
Authors: We acknowledge that direct quantitative metrics on future prediction accuracy or action consistency are not reported. However, the WrongFuture ablation provides indirect but controlled evidence for the assumption: when futures are deliberately inconsistent with the task, performance collapses to zero across training, while GenFuture (imperfect yet task-aligned) yields gains over NoFuture. This ordering (GTFuture > GenFuture > NoFuture > WrongFuture) on the learning curves supports that consistency, rather than mere presence of a future signal, drives the effect. We will expand the discussion of this ablation as evidence for the pipeline's utility and note the lack of direct prediction metrics as a limitation. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on direct empirical comparisons of future-conditioned policies (BC, BC+RL, SFP) against explicit baselines (NoFuture, GTFuture, GenFuture, WrongFuture) across RoboCasa and CALVIN benchmarks, with learning-curve analysis showing differential performance. The FEC interface is introduced as a conditioning mechanism and tested via ablations rather than derived mathematically. The three-stage generation pipeline is presented as an implementation detail, not a self-referential derivation. No equations, fitted parameters renamed as predictions, self-citation load-bearing arguments, or uniqueness theorems appear in the provided text. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Short-horizon future videos generated without the robot can provide useful structured priors for closed-loop policies in multi-step manipulation under uncertainty
invented entities (1)
-
Future-Experience Conditioning (FEC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Jiang, X. Fang, N. Roy, T. Lozano-Perez, L. P. Kaelbling, and S. An- cha, “Streaming flow policy: Simplifying diffusion/flow-matching policies by treating action trajectories as flow trajectories,”arXiv preprint arXiv:2505.21851, 2025
-
[2]
A survey on deep reinforcement learning algorithms for robotic manipulation,
D. Hanet al., “A survey on deep reinforcement learning algorithms for robotic manipulation,”Sensors, 2023
2023
-
[3]
A review on reinforcement learning for contact-rich robotic manipulation tasks,
´I. Elguea-Aguinacoet al., “A review on reinforcement learning for contact-rich robotic manipulation tasks,”Robotics and Computer- Integrated Manufacturing, 2023
2023
-
[4]
Deep visual foresight for planning robot motion,
C. Finn and S. Levine, “Deep visual foresight for planning robot motion,” inProc. IEEE International Conference on Robotics and Automation (ICRA), 2017
2017
-
[5]
Learning Latent Dynamics for Planning from Pixels
D. Hafner, T. Lillicrap, I. Fischer, R. Villegas, D. Ha, H. Lee, and J. Davidson, “Learning latent dynamics for planning from pixels,” arXiv preprint arXiv:1811.04551, 2019
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[6]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
Dream to Control: Learning Behaviors by Latent Imagination
D. Hafner, T. Lillicrap, J. Ba, and M. Norouzi, “Dream to con- trol: Learning behaviors by latent imagination,”arXiv preprint arXiv:1912.01603, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1912
-
[8]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajalet al., “Rt-1: Robotics transformer for real-world control at scale,” inRobotics: Science and Systems (RSS), 2023
2023
-
[9]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsu, J. Ibarz, B. Ichter, A. Irpan, N. Joshi, R. Julian, D. Kalashnikov, Y . Kuang, K. Lee, S. Levine, Y . Lu, C. Parada, P. Pastor, J. Quiambao, K. Rao, J. Ret- tinghouse, D. Reyes, P. Sermanet, A. Toshev, V . Vanhoucke, F. Xia, T. Xiao, P. Xu,...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Octo: An open-source generalist robot policy,
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Blacket al., “Octo: An open-source generalist robot policy,” inRobotics: Science and Systems (RSS), 2024
2024
-
[11]
A survey on reinforcement learning applications in slam,
M. D. Tezerjani, M. Khoshnazar, M. Tangestanizadeh, A. Kiani, and Q. Yang, “A survey on reinforcement learning applications in slam,” arXiv preprint arXiv:2408.14518, 2024
-
[12]
Decision transformer: Re- inforcement learning via sequence modeling,
L. Chen, K. Lu, A. Rajeswaran, K. Lee, A. Grover, M. Laskin, P. Abbeel, A. Srinivas, and I. Mordatch, “Decision transformer: Re- inforcement learning via sequence modeling,” inAdvances in Neural Information Processing Systems (NeurIPS), 2021
2021
-
[13]
Planning with diffusion for flexible behavior synthesis,
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine, “Planning with diffusion for flexible behavior synthesis,” inInternational Conference on Machine Learning (ICML), 2022
2022
-
[14]
Grounding video models to actions through goal- conditioned exploration,
Y . Luo and Y . Du, “Grounding video models to actions through goal- conditioned exploration,” inInternational Conference on Learning Representations (ICLR), 2025
2025
-
[15]
Closed-loop visuomotor control with generative expectation for robotic manipulation,
Q. Bu, J. Zeng, L. Chen, Y . Yang, G. Zhou, J. Yan, P. Luo, H. Cui, Y . Ma, and H. Li, “Closed-loop visuomotor control with generative expectation for robotic manipulation,” inAdvances in Neural Infor- mation Processing Systems (NeurIPS), 2024
2024
-
[16]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[17]
Video diffusion models,
J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, “Video diffusion models,” inAdvances in Neural Information Processing Systems (NeurIPS), 2022
2022
-
[18]
Repaint: Inpainting using denoising diffusion proba- bilistic models,
A. Lugmayr, M. Danelljan, A. Romero, F. Yu, R. Timofte, and L. Van Gool, “Repaint: Inpainting using denoising diffusion proba- bilistic models,” inProc. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022
2022
-
[19]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Z. Yang, J. Teng, W. Zheng, M. Ding, S. Huang, J. Xu, Y . Yang, W. Hong, X. Zhang, G. Feng, D. Yin, X. Gu, Y . Zhang, W. Wang, Y . Cheng, T. Liu, B. Xu, Y . Dong, and J. Tang, “Cogvideox: Text- to-video diffusion models with an expert transformer,”arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Videopainter: Any-length video inpainting and editing with plug-and- play context control,
Y . Bian, Z. Zhang, X. Ju, M. Cao, L. Xie, Y . Shan, and Q. Xu, “Videopainter: Any-length video inpainting and editing with plug-and- play context control,”arXiv preprint arXiv:2503.05639, 2025
-
[21]
Dream2Real: Zero- shot 3D object rearrangement with vision-language models,
I. Kapelyukh, Y . Ren, I. Alzugaray, and E. Johns, “Dream2Real: Zero- shot 3D object rearrangement with vision-language models,” inIEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 4796–4803
2024
-
[22]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
M. Ahn, A. Brohan, N. Brown, Y . Chebotar, C. Cortes, B. David, C. Finn, C. Fu, K. Gopalakrishnan, K. Hausman, A. Herzog, D. Ho, J. Hsu, B. Ichter, J. Ibarz, A. Irpan, E. Jang, R. J. Ruano, D. Kalash- nikov, S. Levineet al., “Do as i can, not as i say: Grounding language in robotic affordances,”arXiv preprint arXiv:2204.01691, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[23]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,” inRobotics: Science and Systems (RSS), 2023
2023
-
[24]
Cliport: What and where pathways for robotic manipulation,
M. Shridhar, L. Manuelli, and D. Fox, “Cliport: What and where pathways for robotic manipulation,”arXiv preprint arXiv:2109.12098, 2021
-
[25]
Peract: Multi-task 6d robotic manipulation learning from perceiver-actor,
——, “Peract: Multi-task 6d robotic manipulation learning from perceiver-actor,”arXiv preprint arXiv:2209.05451, 2022
-
[26]
Vima: General robot manipulation with multimodal prompts,
Y . Jiang, A. Gupta, A. Zeng, P. Florence, M. Ahn, Y . Lu, J. Ibarz, B. Ichter, A. Wahid, K. Kumar, J. Xu, S. Levine, and J. Tompson, “Vima: General robot manipulation with multimodal prompts,”arXiv preprint arXiv:2210.03094, 2022
-
[27]
Behavior Transformers: Cloning k modes with one stone.arXiv preprint arXiv:2206.11251, 2022
N. M. M. Shafiullah, C. Paxton, and L. Pinto, “Behavior transformers: Cloningkmodes with one stone,”arXiv preprint arXiv:2206.11251, 2022
-
[28]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and J. A. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” in Proc. International Conference on Artificial Intelligence and Statistics (AISTATS), 2011
2011
-
[29]
Scheduled sampling for sequence prediction with recurrent neural networks,
S. Bengio, O. Vinyals, N. Jaitly, and N. Shazeer, “Scheduled sampling for sequence prediction with recurrent neural networks,” inAdvances in Neural Information Processing Systems (NeurIPS), 2015
2015
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.