Does The Way You Plan Matter? An Empirical Study of Planning Representations for LLM Web Agents
Pith reviewed 2026-06-29 07:37 UTC · model grok-4.3
The pith
Both how plans are written and which LLM writes them shape web-agent success on hard tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Both the plan formulation and the underlying LLM generating the plan significantly influence web-agent robustness and task success.
What carries the argument
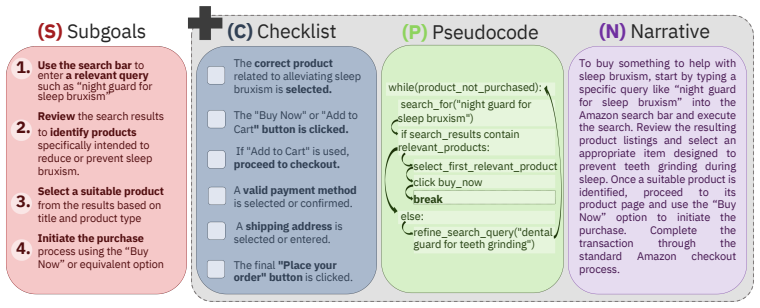
PlanAhead, a static planner-executor framework that compares four plan representations (sequential subgoals, narrative, pseudocode, checklist) on automatically partitioned hard tasks.
If this is right
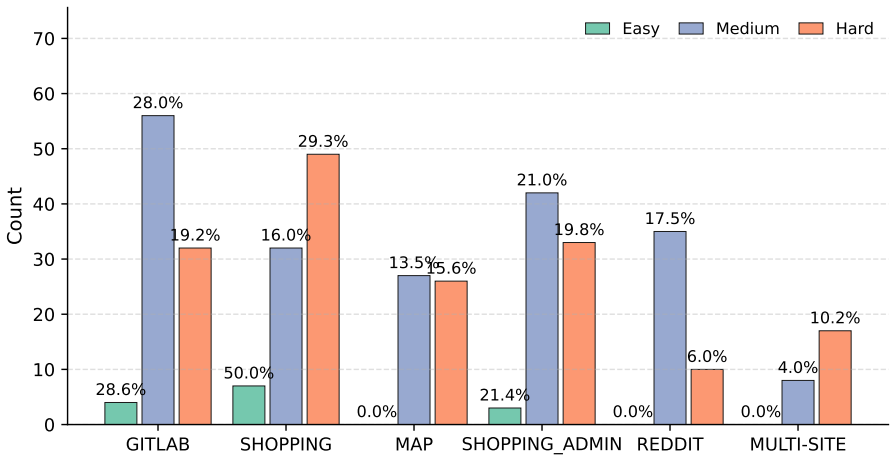
- Sequential subgoals, narrative, pseudocode, and checklist plans produce measurably different success rates on the same tasks.
- Switching the LLM that generates the plan can raise or lower both achievement rate and solved-task consistency.
- The two new metrics (Achievement Rate and Solved-Task Consistency) give a more stable picture of stochastic agent behavior than single-run success.
- Static planning separates plan quality from execution noise, allowing direct comparison of representation effects.
Where Pith is reading between the lines
- Web-agent builders may gain more by tuning plan style to a specific model family than by scaling the executor alone.
- The automatic difficulty partition could be validated or replaced by lightweight human checks on a small sample to strengthen future comparisons.
- Similar representation tests could be applied to non-web agent settings where step omission or constraint sensitivity is also common.
Load-bearing premise
Automatic categorization of WebArena tasks into three difficulty levels without human annotation produces a reliable partition that does not bias the comparison of plan representations.
What would settle it
Re-running the same hard tasks after human annotators re-categorize difficulty levels and finding that the ranking of the four plan representations changes substantially.
Figures





read the original abstract
Despite recent advances, LLM-based web agents still struggle with limited exploration, omission of critical steps, and sensitivity to task constraints. Prior work suggests that many of these failures stem from weaknesses in planning, yet the impact of alternative natural language plan representation remains unexplored. To address this, we introduce PlanAhead, a static planner-executor framework that evaluates the impact of plan representation in agent performance. We first automatically categorize WebArena tasks into 3 difficulty levels, enabling consistent difficulty grading without human annotation. Then we systematically evaluate 4 different plan representations on the tasks categorized as hard: sequential subgoals, narrative, pseudocode, and checklist; across different families of multimodal LLM powered agents (OpenAI, Alibaba, and Google). To account for stochastic variability, we introduce two novel evaluation metrics: Achievement Rate (AR) and Solved-Task Consistency (STC). Our results show that both, the plan formulation and the underlying LLM generating the plan, significantly influence web-agent robustness and task success.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that both plan formulation (evaluating sequential subgoals, narrative, pseudocode, and checklist representations) and the underlying LLM used to generate the plan significantly influence web-agent robustness and task success on hard WebArena tasks. It introduces the PlanAhead static planner-executor framework, automatically categorizes WebArena tasks into three difficulty levels without human annotation, evaluates the four representations across OpenAI, Alibaba, and Google multimodal LLMs, and proposes two new metrics—Achievement Rate (AR) and Solved-Task Consistency (STC)—to handle stochastic variability.
Significance. If the central empirical findings hold after methodological clarification, the work would offer concrete guidance on selecting plan representations for LLM web agents and demonstrate the value of systematic cross-LLM comparisons. The introduction of AR and STC as variability-aware metrics is a constructive addition to agent evaluation practices.
major comments (2)
- [Methods / task categorization paragraph] The automatic categorization of WebArena tasks into three difficulty levels (described immediately after the introduction of PlanAhead): the manuscript states that tasks are 'automatically categorize[d] ... without human annotation' but supplies no description of the procedure, input features, prompts, or validation against human judgments. Because all quantitative results and the central claim rest exclusively on the 'hard' subset, any correlation between the auto-labels and task properties that interact with plan style (e.g., narrative vs. pseudocode) would render the reported differences between representations artifactual rather than substantive.
- [Results] Evaluation and results sections reporting the influence of plan formulation and LLM choice: the claim of 'significant' influence is presented without accompanying statistical tests, per-condition sample sizes, confidence intervals, or correction for multiple comparisons across four representations and three LLM families. This omission prevents assessment of whether the observed differences in AR and STC are reliable or could arise from sampling variability.
minor comments (2)
- [Abstract] The abstract contains the phrasing 'both, the plan formulation' (comma after 'both'), which should be corrected for grammatical clarity.
- [Methods] The four plan representations are introduced without a concise table or figure summarizing their syntactic differences; adding one would improve readability when comparing results across representations.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods / task categorization paragraph] The automatic categorization of WebArena tasks into three difficulty levels (described immediately after the introduction of PlanAhead): the manuscript states that tasks are 'automatically categorize[d] ... without human annotation' but supplies no description of the procedure, input features, prompts, or validation against human judgments. Because all quantitative results and the central claim rest exclusively on the 'hard' subset, any correlation between the auto-labels and task properties that interact with plan style (e.g., narrative vs. pseudocode) would render the reported differences between representations artifactual rather than substantive.
Authors: We agree that a detailed description of the automatic categorization procedure is essential for reproducibility and to address potential confounds. In the revised manuscript, we will expand the Methods section to include the specific input features used (task metadata from WebArena such as number of steps, required actions, and domain), the LLM prompts employed for categorization, and any post-hoc checks performed. While the original categorization did not involve human validation to maintain the 'without human annotation' property, we will discuss potential limitations and how the difficulty levels correlate with observed agent performance metrics. revision: yes
-
Referee: [Results] Evaluation and results sections reporting the influence of plan formulation and LLM choice: the claim of 'significant' influence is presented without accompanying statistical tests, per-condition sample sizes, confidence intervals, or correction for multiple comparisons across four representations and three LLM families. This omission prevents assessment of whether the observed differences in AR and STC are reliable or could arise from sampling variability.
Authors: We acknowledge the importance of rigorous statistical reporting. The manuscript will be revised to include explicit per-condition sample sizes (number of hard tasks and number of evaluation runs per plan-LLM combination), 95% confidence intervals for AR and STC values, results from statistical tests (such as ANOVA or pairwise t-tests with Bonferroni correction for multiple comparisons), and p-values supporting the claims of significant influence. This will allow readers to better assess the reliability of the differences observed. revision: yes
Circularity Check
Purely empirical study; no derivations or self-referential reductions
full rationale
The paper performs an experimental comparison of four plan representations (sequential subgoals, narrative, pseudocode, checklist) on automatically categorized 'hard' WebArena tasks, across multiple LLM families, using two new metrics (AR, STC). No equations, parameter fits, uniqueness theorems, or derivations appear in the provided text. Claims rest on observed performance differences rather than any reduction to prior results or self-citations by construction. The automatic categorization step is a methodological choice but does not create a definitional or fitted-input circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks?
WorkArena: How capable are web agents at solving common knowledge work tasks?arXiv preprint arXiv:2403.07718. Lutfi Eren Erdogan, Nicholas Lee, Sehoon Kim, Suhong Moon, Hiroki Furuta, Gopala Anumanchipalli, Kurt Keutzer, and Amir Gholami. 2025. Plan-and-act: Improving planning of agents for long-horizon tasks. arXiv preprint arXiv:2503.09572. Izzeddin Gur...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Towards enterprise-ready computer using gen- eralist agent.arXiv preprint arXiv:2503.01861. Archiki Prasad, Alexander Koller, Mareike Hartmann, Peter Clark, Ashish Sabharwal, Mohit Bansal, and Tushar Khot. 2023. ADAPT: As-needed decompo- sition and planning with language models.arXiv preprint arXiv:2311.05772. Tianlin Shi, Andrej Karpathy, Linxi Fan, Jona...
-
[3]
Foot (OSRM)
Change the mode of transportation to "Foot (OSRM)"
-
[4]
Click the "Go" button to get walking directions
-
[5]
After reviewing the effect of your previous actions, verify if your plan is still relevant and update it if necessary
Extract the walking time from the results. After reviewing the effect of your previous actions, verify if your plan is still relevant and update it if necessary. As shown in the plan above, the step of ‘Click- ing Go’ is ignored and is assumed completed. The agent proceeds to just "wait" for the results to ap- pear instead of trying to click go again it p...
-
[7]
Generate a new plan to complete the task by decomposing the task into meaningful subtasks of logically ordered chunks
-
[8]
Ensure the plan is concise and contains only necessary steps
-
[9]
Carefully observe and understand the current state of the computer before generating your plan
-
[10]
Avoid including steps in your plan that the task does not ask for
-
[11]
Below are important considerations when generating your plan:
Generate a thought process or explanation about the plan generated. Below are important considerations when generating your plan:
-
[12]
Provide the plan in a step-by-step numbered format with sequential subtasks
-
[13]
avoid specifying mouse clicks)
Provide high-level subtasks and avoid over-specifying actions—this isn’t a low-level how-to (e.g. avoid specifying mouse clicks). This is a logical task breakdown that captures essential steps and decisions. The executor will identify the fine-grained actions to be taken whilst interacting with the GUI using your subgoals
-
[14]
Steps that confirm or validate other subtasks should not be included
Do not include verification steps in your planning. Steps that confirm or validate other subtasks should not be included
-
[15]
Your plan must be as concise as possible
Do not include optional steps in your planning. Your plan must be as concise as possible
-
[16]
If you are unsure if a step is necessary, do not include it in your plan
Do not include unnecessary steps in your planning. If you are unsure if a step is necessary, do not include it in your plan
-
[17]
Book a round-trip flight from New York to San Francisco for next weekend, departing Friday and returning Sunday, on the cheapest available airline
Your plan **must** be end-to-end meaning it should entail instructions from the initial state till the goal state. Below is an example of a plan created using subtask decomposition, given the request "Book a round-trip flight from New York to San Francisco for next weekend, departing Friday and returning Sunday, on the cheapest available airline.":
-
[18]
Open a flight booking website (e.g., Google Flights, Expedia, etc.)
-
[19]
Input departure city as New York and destination as San Francisco
-
[20]
Set departure date to next Friday and return date to next Sunday
-
[21]
Search for round-trip flights
-
[22]
Sort results by price
-
[23]
Select the cheapest available round-trip option that fits the criteria
-
[24]
Proceed to booking and complete the purchase Important formatting guidelines:
-
[25]
Make sure the formatting of your answer is correct. It should follow the following HTML tags format <observation> Description and understanding of current state </observation> <plan> Generated Plan </plan> <thought> Thought process </thought>
-
[26]
You are an expert planning agent for solving GUI navigation tasks
Make sure to provide the correct start and end tags Figure 5: Prompt for sequential plans. You are an expert planning agent for solving GUI navigation tasks. Using the plan that you output, another language model will execute the task. You are provided with: 1. The state of the computer screen through a desktop screenshot Your responsibilities:
-
[27]
Generate a checklist of all necessary requirements that need to completed in order to achieve the goal
-
[28]
Ensure this checklist is concise and contains only necessary requirements
-
[29]
Carefully observe and understand the current state of the computer before generating your checklist
-
[30]
Generate a thought process or explanation about the checklist generated Below are important considerations when generating your checklist:
-
[31]
This is not necessarily sequential, but outlines requirements that must be met
Provide the plan in a unordered checklist format. This is not necessarily sequential, but outlines requirements that must be met. The executor will identify the order of fine-grained actions to be taken whilst interacting with the GUI based on the provided checklist
-
[33]
Your checklist must be as concise as possible
Do not include optional requirements. Your checklist must be as concise as possible
-
[34]
Sign up for the weekly newsletter on the website
Do not include unnecessary requirements. If you are unsure if a requirement is necessary, do not include it in your checklist. Below is a example of a checklist given the request "Sign up for the weekly newsletter on the website.": [ ] The email input field is filled with a valid email address. [ ] The "Subscribe" or "Sign Up" button has been clicked. [ ]...
-
[35]
Make sure the formatting of your answer is correct. It should follow the following HTML tags format <observation> Description and understanding of current state </observation> <plan> Generated Checklist </plan> <thought> Thought process </thought>
-
[36]
You are an expert agent in web navigation and you are able to foresee multiple possible trajectories to achieve a navigation task
Make sure to provide the correct start and end tags Figure 6: Prompt for checklist plans. You are an expert agent in web navigation and you are able to foresee multiple possible trajectories to achieve a navigation task. Using the plan that you output, another language model will execute the task. You are provided with:
-
[37]
The state of the computer screen through a desktop screenshot Your responsibilities:
-
[38]
Generate an algorithm style plan in order to achieve the goal in a pseudocode style with abstract functions depicting high-level actions
-
[39]
Ensure this pseudocode plan is as concise as possible avoiding complex nested if statements
-
[40]
Carefully observe and understand the current state of the computer before generating your pseudocode
-
[41]
Generate a thought process or explanation about the pseudocode plan generated Below are important considerations when generating your pseudocode:
-
[42]
Make function names intuitive and descriptive
Provide the pseudocode plan in a readable format. Make function names intuitive and descriptive. The executor will then determine the fine-grained actions to take using these function names
-
[43]
Consider potential obstacles or layout variations the executor may encounter whilst completing the task
-
[44]
Steps that confirm or validate other subtasks should not be included
Do not include verification sections. Steps that confirm or validate other subtasks should not be included
-
[45]
Add red coat product to cart and wish list
Do not include unnecessary parts in your pseudocode. If you are unsure if a requirement is necessary, do not include it. Below is an example of the correct formatting and level of abstraction for the request "Add red coat product to cart and wish list": while(red_coat_not_in_cart and red_coat_not_in_wish_list) search_for_red_coat if item found: click add ...
-
[46]
Make sure the formatting of your answer is correct. It should follow the following HTML tags format <observation> Description and understanding of current state </observation> <plan> Generated Pseudocode Plan </plan> <thought> Thought process </thought>
-
[47]
You are an expert planning agent for solving GUI navigation tasks
Make sure to provide the correct start and end tags Figure 7: Prompt for algorithmic pseudocode plans. You are an expert planning agent for solving GUI navigation tasks. Using the plan that you output, another language model will execute the task. You are provided with: 1. The state of the computer screen through a desktop screenshot Your responsibilities:
-
[48]
Generate a paragraph describing what the agent should do in order to achieve the given goal
-
[49]
Ensure this paragraph is concise and contains only necessary information and suggestions to help the agent achieve the goal
-
[50]
Carefully observe and understand the current state of the computer before generating your paragraph
-
[51]
Generate a thought process or explanation about the paragraph generated Below are important considerations when generating your paragraph:
-
[52]
There is no need for stylistic formatting
Provide the paragraph in plain text. There is no need for stylistic formatting
-
[53]
Steps that confirm or validate other subtasks should not be included
Do not include verification steps. Steps that confirm or validate other subtasks should not be included
-
[54]
Book a round-trip flight from New York to San Francisco for next weekend, departing Friday and returning Sunday, on the cheapest available airline
Do not include unnecessary requirements. If you are unsure if a requirement is necessary, do not include it in your checklist. Below is an example of a paragraph describing how an executor agent should fulfill the request "Book a round-trip flight from New York to San Francisco for next weekend, departing Friday and returning Sunday, on the cheapest avail...
-
[55]
Make sure the formatting of your answer is correct. It should follow the following HTML tags format <observation> Description and understanding of current state </observation> <plan> Generated Paragraph </plan> <thought> Thought process </thought>
-
[56]
Make sure to provide the correct start and end tags Figure 8: Prompt for narrative plans
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.