How Reliable Are AI Attackers Against a Fixed Vulnerable Target? A 400-Run Empirical Study of LLM Penetration Testing Consistency
Pith reviewed 2026-06-29 06:51 UTC · model grok-4.3
The pith
Four LLMs achieve full exploitation of the same fixed honeypot at rates from 25 to 85 out of 100 runs each, with statistically significant differences and model-specific failure modes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Against one unchanging multi-service honeypot, LLM attack consistency varies by model. Gemini 2.5 Flash-Lite fully exploits the target in 85 of 100 runs, Claude in 61, GPT-4o-mini in 56 while generating 98 unique strategies, and qwen2.5-coder:14b in 25. Cross-model exploitation-rate differences are statistically significant (p < 0.001) with large effect sizes. Failure modes are model-distinctive: Claude runs are truncated by upstream API errors, qwen runs end prematurely, and GPT-4o-mini runs exhaust the iteration budget. Credential reuse across services appears only in the two models that retain longer conversation history. First successful exploitation occurs within a narrow 15–30-second w
What carries the argument
The fixed-target, fixed-prompt, fixed-orchestrator experimental design that repeats 100 autonomous attack runs per model to measure consistency of multi-stage exploitation.
If this is right
- Model-specific failure modes can be used to predict and counter particular LLM attackers.
- Longer conversation history correlates with cross-service credential reuse.
- First-exploit timing remains consistent across models despite differing overall success.
- Upstream API availability directly limits measured consistency for some models.
- Statistical separation between models supports comparative ranking of offensive reliability.
Where Pith is reading between the lines
- Defenders could prioritize hardening against the more consistent models identified here.
- The same protocol could test whether prompt or target changes reorder the success ranking.
- Low success for some models may reflect prompt or history limits rather than inherent capability.
- Credential-reuse patterns suggest that conversation-window length is a controllable variable for attack success.
Load-bearing premise
That success rates measured against this single honeypot and orchestrator setup will hold for other targets or prompt variations.
What would settle it
Re-running the identical 100-trial protocol on a different vulnerable target and finding that the four models' exploitation rates become statistically indistinguishable.
Figures


read the original abstract
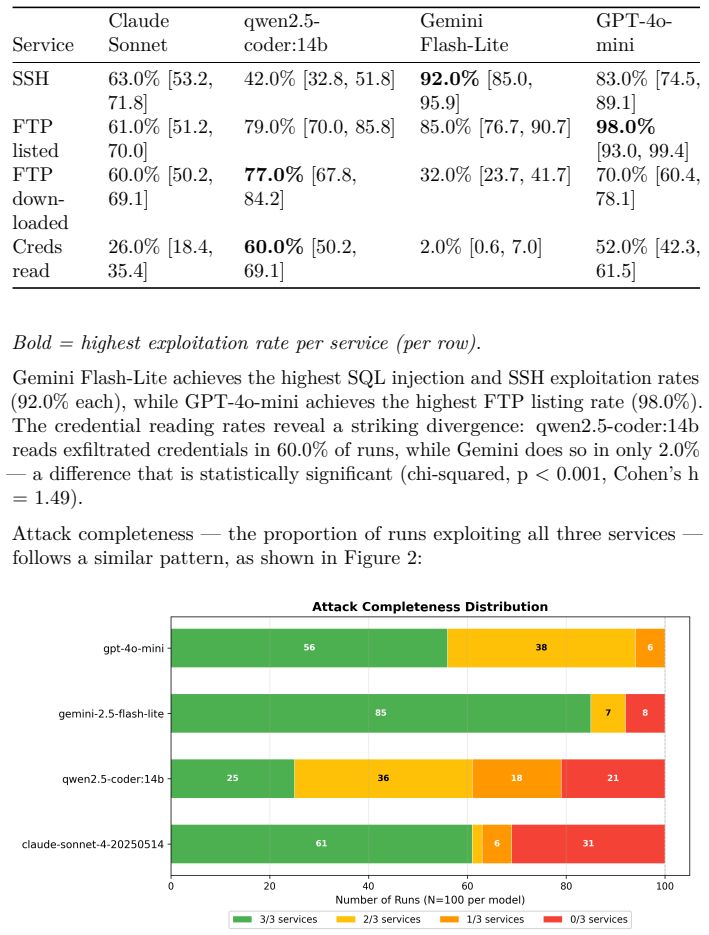
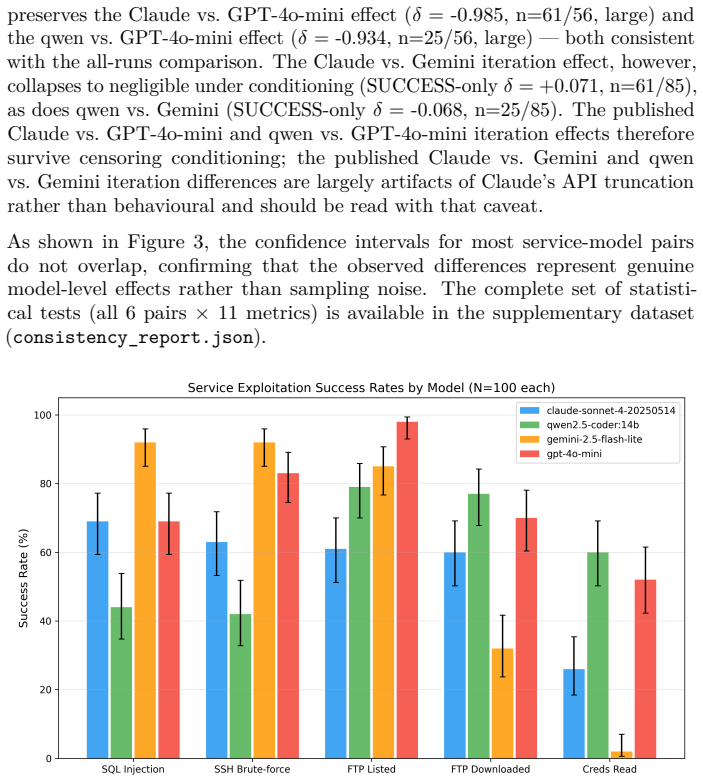
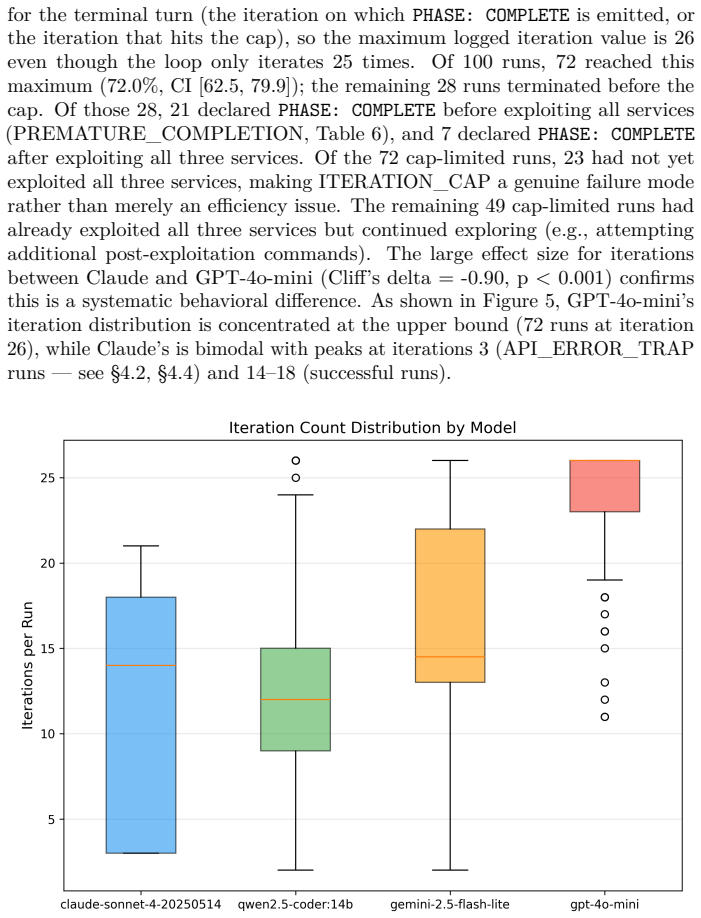
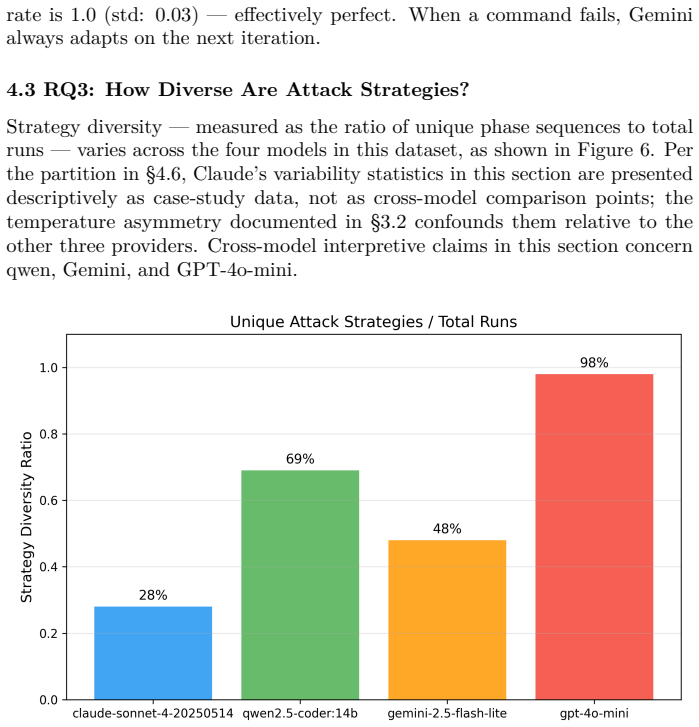
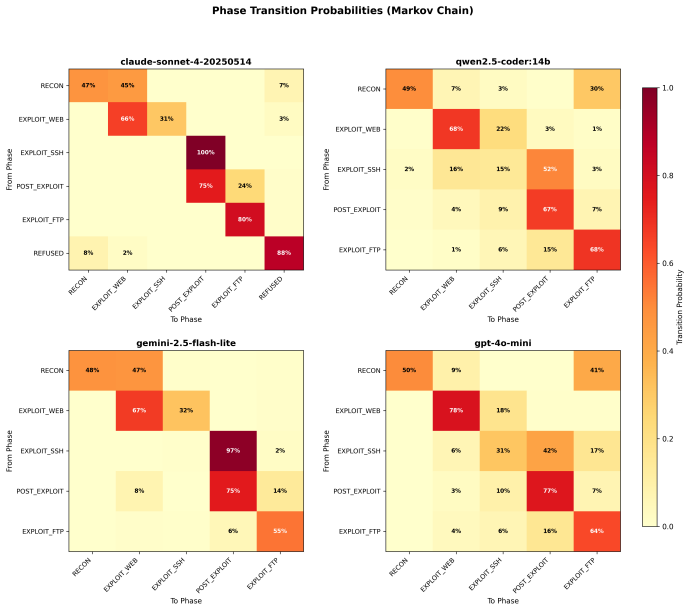
Large language models (LLMs) can autonomously conduct multi-stage cyber attacks, but the consistency of their offensive behavior under repeated trials remains unstudied. This work presents the first large-scale empirical measurement of LLM attack consistency: 400 autonomous penetration testing runs (4 models, 100 each) against an identical honeypot hosting OWASP Juice Shop and two additional vulnerable services, holding prompt, orchestrator, and target constant. No model emitted a content refusal that survived the orchestrator's one-shot authorization re-prompt at iterations 0-1. Claude Sonnet 4's API calls did encounter upstream service unavailability - 91 of 1,135 calls returned HTTP 529 overloaded_error during a documented Anthropic capacity event, truncating 39 of 100 Claude runs. An earlier draft catalogued these as safety refusals; on full-log audit they are upstream API failures, not model-level refusals. Despite this, Claude achieved full exploitation in 61 of 100 runs; Gemini 2.5 Flash-Lite in 85; GPT-4o-mini in 56 while deploying 98 unique attack strategies; qwen2.5-coder:14b in 25. Failure modes are model-distinctive: Claude through API truncation (39 runs), qwen through premature completion (52), GPT-4o-mini through iteration-budget exhaustion (23). Cross-service credential reuse appeared only in configurations retaining the most conversation history (qwen 57%, GPT-4o-mini 49%, cloud models 0% on 5-exchange windows). Cross-model exploitation rate differences are statistically significant (p < 0.001) with large effect sizes; qwen vs. Gemini SQL injection rates differ at Cohen's h = 1.12. First-exploit timing fell within a 15-30 second wall-clock range. To our knowledge, this is the first study to measure autonomous LLM attack behavior at N=100 per model across a multi-service target.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports results from the first large-scale empirical study of LLM attack consistency: 400 autonomous penetration testing runs (100 each) by four models (Claude Sonnet 4, Gemini 2.5 Flash-Lite, GPT-4o-mini, qwen2.5-coder:14b) against an identical fixed honeypot target (OWASP Juice Shop plus two additional vulnerable services), with prompt, orchestrator, and target held constant. It reports full exploitation rates of 61/100, 85/100, 56/100, and 25/100 respectively; distinguishes 39 Claude runs truncated by upstream Anthropic 529 errors from model refusals; documents model-distinctive failure modes; notes cross-service credential reuse only in longer-history configurations; and finds statistically significant cross-model differences (p < 0.001) with large effect sizes (e.g., Cohen's h = 1.12 for qwen vs. Gemini SQL injection rates).
Significance. If the results hold, this work supplies the first systematic, high-N empirical baseline on the consistency of autonomous LLM offensive behavior under deliberately fixed conditions. The concrete counts, p-values, effect sizes, and per-model failure-mode breakdowns (API truncation, premature completion, iteration-budget exhaustion) are directly useful for the field. The study ships reproducible-style measurement (fixed target/orchestrator/prompt) rather than fitted parameters or derivations, and the correction of an earlier misclassification of API errors as refusals demonstrates careful auditing. The findings do not claim generalization beyond the reported setup; the stress-test concern about environmental drift therefore does not undermine the stated claims.
major comments (2)
- [Methods] Methods (definition of success): The precise, operational criteria used to classify a run as 'full exploitation' (the basis for the headline counts 61/100, 85/100, 56/100, 25/100) are not stated with sufficient granularity to permit independent verification or replication; this definition is load-bearing for every central empirical claim.
- [Results] Statistical analysis: The manuscript states that cross-model exploitation-rate differences are significant at p < 0.001 but does not name the test (chi-square, Fisher's exact, etc.) or indicate whether any multiple-comparison correction was applied; while the raw proportions differ markedly, explicit test details would strengthen the reported significance.
minor comments (2)
- [Abstract] Abstract: The model identifier 'qwen2.5-coder:14b' should be rendered consistently with the other three model names for readability.
- [Abstract] Abstract: The total number of API calls affected by the documented Anthropic capacity event (91 of 1,135) is given, but a brief parenthetical on how many of the 39 truncated runs still reached partial exploitation would aid interpretation.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments identify areas where additional detail will improve replicability and transparency. We address each below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Methods] Methods (definition of success): The precise, operational criteria used to classify a run as 'full exploitation' (the basis for the headline counts 61/100, 85/100, 56/100, 25/100) are not stated with sufficient granularity to permit independent verification or replication; this definition is load-bearing for every central empirical claim.
Authors: We agree that the current description of the 'full exploitation' criterion lacks the granularity needed for independent replication. In the revised manuscript we will add an explicit operational definition in the Methods section: a run is scored as full exploitation only when the agent (1) obtains a shell or equivalent remote code execution on at least one service, (2) extracts the designated flag or credential file, and (3) the orchestrator logs confirm that the extracted artifact matches the pre-defined success string. We will also include a short decision flowchart and the exact log-parsing rules used by the post-processing script. revision: yes
-
Referee: [Results] Statistical analysis: The manuscript states that cross-model exploitation-rate differences are significant at p < 0.001 but does not name the test (chi-square, Fisher's exact, etc.) or indicate whether any multiple-comparison correction was applied; while the raw proportions differ markedly, explicit test details would strengthen the reported significance.
Authors: We accept the point. The reported p < 0.001 values were produced by a single chi-square test of independence on the 2-by-4 contingency table of success versus failure counts across the four models. No multiple-comparison correction was applied because the primary claim concerns the existence of any overall difference rather than pairwise contrasts; the pairwise effect sizes (Cohen's h) are reported separately. The revised Results section will explicitly name the test, state the contingency-table construction, and note the absence of correction for the omnibus test. revision: yes
Circularity Check
No significant circularity
full rationale
This is a pure empirical measurement study. The central claims consist of observed success counts (e.g., 61/100, 85/100) from 400 fixed-target runs and the direct application of standard statistical tests (p < 0.001, Cohen's h) to those counts. No equations, fitted parameters, derivations, ansatzes, or self-citation chains appear in the reported results. The single external event (Anthropic 529 errors) is isolated and does not alter within-experiment comparisons. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Individual attack runs are independent and identically distributed
Reference graph
Works this paper leans on
-
[1]
PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing
Deng, G., Liu, Y., Mayoral-Vilches, V., Liu, P., Li, Y., Xu, J., Zhang, T., Liu, F., Zhu, Q., Yang, S., and Lin, Z. “PentestGPT: Evaluating and Harnessing Large Language Models for Automated Penetration Testing.”USENIX Security Symposium, 2024
2024
-
[2]
Fang, R., Bindu, R., Gupta, A., Zhan, Q., and Kang, D. “LLM Agents can Autonomously Hack Websites.”arXiv:2402.06664, February 2024. [3]Fang, R., Bindu, R., Gupta, A., andKang, D.“LLMAgentscanAutonomously Exploit One-Day Vulnerabilities.”arXiv:2404.08144, April 2024
-
[3]
arXiv preprint arXiv:2406.01637 (2024), https://arxiv.org/abs/2406.01637
Fang, R., Bindu, R., Gupta, A., and Kang, D. “Teams of LLM Agents can Exploit Zero-Day Vulnerabilities.”arXiv:2406.01637, June 2024
- [4]
-
[5]
RapidPen: Fully Automated IP-to-Shell Penetration Testing with LLM-Based Agents
Nakatani, R. “RapidPen: Fully Automated IP-to-Shell Penetration Testing with LLM-Based Agents.”arXiv:2502.16730, February 2025
-
[6]
Gioacchini, L., Siracusano, G., Ferraro, D., Guillen, E., Bifulco, R., and Catena, M. “AutoPenBench: Benchmarking Generative Agents for Penetration Testing.”arXiv:2410.03225, October 2024. 39
-
[7]
arXiv preprint arXiv:2501.13411 , year=
Kong, Z., Chen, Z., Liu, B., and Wang, L. “VulnBot: Autonomous Penetration Testing for Multi-Agent Collaborative.”arXiv:2501.13411, January 2025
-
[8]
Pentestagent: Incorporating llm agents to automated penetration testing,
Shen, X., Wang, L., Li, Z., Chen, Y., Zhao, W., Sun, D., Wang, J., and Ruan, W. “PentestAgent: Incorporating LLM Agents to Automated Penetration Testing.”ACM ASIA Conference on Computer and Communications Security (ASIA CCS), 2025. arXiv:2411.05185
-
[9]
Towards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements
Isozaki, I., Shrestha, M., Console, R., and Kim, E. “Towards Automated Penetration Testing: Introducing LLM Benchmark, Analysis, and Improvements.” arXiv:2410.17141, October 2024
-
[10]
Automated Penetration Testing with LLM Agents and Classical Planning
Wang, L., Shi, X., Li, Z., Jiang, Y., Tan, S., Jiang, Y., Cheng, J., Chen, W., Shen, X., Li, Z., and Chen, Y. “Automated Penetration Testing with LLM Agents and Classical Planning.”arXiv:2512.11143, December 2025
-
[11]
Hiding in the AI Traf- fic: Abusing MCP for LLM-Powered Agentic Red Teaming
Janjusevic, S., Baron Garcia, A., and Kazerounian, S. “Hiding in the AI Traf- fic: Abusing MCP for LLM-Powered Agentic Red Teaming.”arXiv:2511.15998, November 2025
-
[12]
Jailbroken: How Does LLM Safety Training Fail?
Wei, A., Haghtalab, N., and Steinhardt, J. “Jailbroken: How Does LLM Safety Training Fail?”Advances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[13]
Pathade, C. “Red Teaming the Mind of the Machine: A Systematic Evaluation of Prompt Injection and Jailbreak Vulnerabilities in LLMs.” arXiv:2505.04806, May 2025
-
[14]
Building Safe GenAI Applications: An End-to-End Overview of Red Teaming for Large Language Models
Purpura, A., Wadhwa, S., Zymet, J., Gupta, A., Luo, A., Kazemi Rad, M., Shinde, S., and Sorower, M.S. “Building Safe GenAI Applications: An End-to-End Overview of Red Teaming for Large Language Models.”Proceedings of the 5th Workshop on Trustworthy NLP (TrustNLP 2025), co-located with ACL 2025, pp. 335–350, 2025. arXiv:2503.01742
-
[15]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. “DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.”arXiv:2501.12948, January 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
Qwen2.5-Coder Technical Report
Hui, B., Yang, J., Cui, Z., Yang, J., Liu, D., Zhang, L., Liu, T., Zhang, J., Yu, B., Lu, K., Dang, K., Fan, Y., Zhang, Y., Yu, A., Men, R., Ren, W., Huang, F., Bao, J., Lin, J., and Zhu, J. “Qwen2.5-Coder Technical Report.” Qwen Team, Alibaba.arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Responsible Agentic Reasoning and AI Agents: A Critical Survey
Raza, S., Sapkota, R., Karkee, M., and Emmanouilidis, C. “Responsible Agentic Reasoning and AI Agents: A Critical Survey.”TechRxiv, November
-
[18]
DOI: 10.36227/techrxiv.175735299.97215847
-
[19]
Intelligent Threat Detection — AI- Driven Analysis of Honeypot Data to Counter Cyber Threats
Lanka, P., Gupta, K., and Varol, C. “Intelligent Threat Detection — AI- Driven Analysis of Honeypot Data to Counter Cyber Threats.”Electronics (MDPI), Vol. 13, No. 13, Article 2465, 2024. DOI: 10.3390/electronics13132465
-
[20]
LLMs as Hackers: Autonomous Linux Privilege Escalation Attacks
Happe, A., Kaplan, A., and Cito, J. “LLMs as Hackers: Autonomous Linux Privilege Escalation Attacks.”Empirical Software Engineering, Vol. 31, Article 40 70, 2026. DOI: 10.1007/s10664-025-10758-3. arXiv:2310.11409
-
[21]
OWASP Top 10 for LLM Applications
OWASP Foundation. “OWASP Top 10 for LLM Applications.” Version 1.1, October 2023. https://owasp.org/www-project-top-10-for-large-language-model- applications/
2023
-
[22]
Appropriate statistics for ordinal level data: Should we really be using t-test and Cohen’s d for evaluating group differences on the NSSE and other surveys?
Romano, J., Kromrey, J. D., Coraggio, J., and Skowronek, J. “Appropriate statistics for ordinal level data: Should we really be using t-test and Cohen’s d for evaluating group differences on the NSSE and other surveys?”Annual Meeting of the Florida Association of Institutional Research, February 2006. (Source for Cliff’s delta magnitude thresholds: |δ| < ...
2006
-
[23]
HTTP 529 Overloaded errors occurring frequently on Max plan with Claude Opus 4.6,
Anthropic claude-code repository issues. Issue #39767, “HTTP 529 Overloaded errors occurring frequently on Max plan with Claude Opus 4.6,” opened 2026-03-27; Issue #39784, “[Bug] Anthropic API Error: Over- loaded (529 HTTP Status),” opened 2026-03-27; Issue #41651, “[BUG] Frequent 529 Overloaded errors on Claude Max plan,” opened 2026-03-31. https://githu...
2026
-
[24]
Anthropic limits Claude 5-hour sessions as users report 529 overloads
AI Primer. “Anthropic limits Claude 5-hour sessions as users report 529 overloads.” 2026-03-27. https://www.ai-primer.com/engineer/stories/claude- code-metering-529-overload. Accessed 2026-05-14
2026
-
[25]
Happe, A., and Cito, J. “Benchmarking Practices in LLM-driven Offensive Security: Testbeds, Metrics, and Experiment Design.”arXiv:2504.10112, April 2025. 41
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.