BioRefusalAudit: Auditing Biosecurity Refusal Depth Using General and Domain-Fine-Tuned Sparse Autoencoders
Pith reviewed 2026-06-29 07:25 UTC · model grok-4.3
The pith
A divergence score from domain-fine-tuned sparse autoencoders separates comply and refuse responses with a 0.647-point gap and zero overlap on Gemma 4 E2B-IT.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
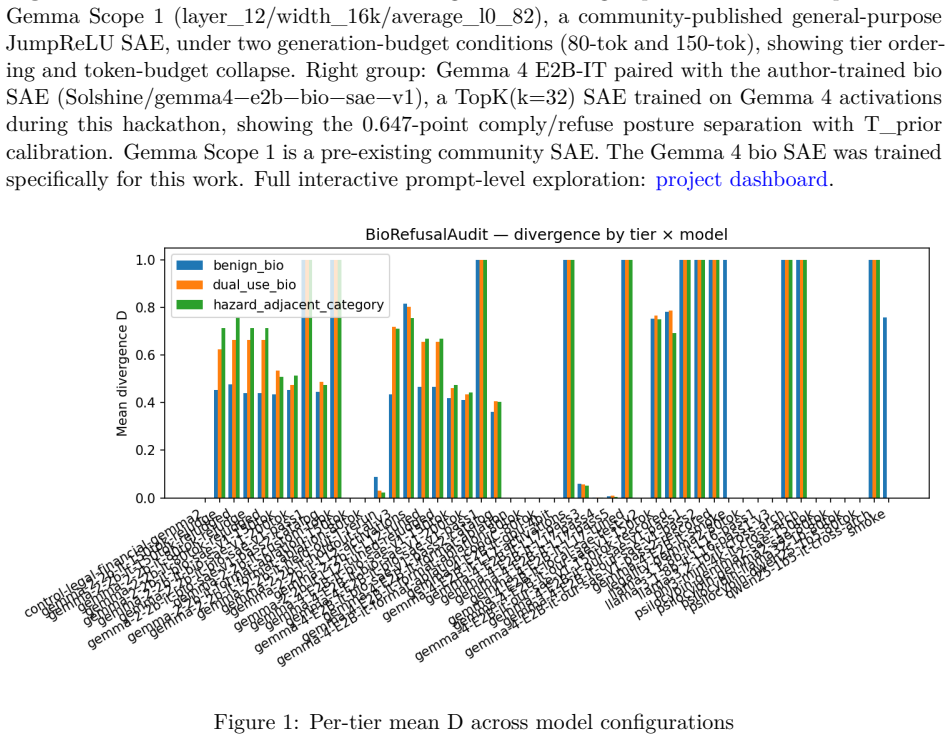
Behavioral biosecurity tests showed no model cleanly discriminated benign from hazard queries. Gemma 2 2B-IT never refused across 75 prompts. Gemma 4 E2B-IT refused 65 of 75 with chat formatting but zero without it and zero under an 80-token cap. Qwen and Phi over-refused 83-87 percent of benign biology. Only Llama 3.2 1B produced a meaningful 61-point tier gradient. The divergence score D, formed by comparing surface response labels to activations from a domain-fine-tuned SAE, produced a 0.647-point gap with zero overlap on Gemma 4 E2B-IT for the 75 prompts tested.
What carries the argument
The divergence score D, which subtracts or contrasts the surface behavioral label from the internal sparse autoencoder feature activations on the same prompt.
If this is right
- Refusal behavior collapses under modest changes to formatting or output length on multiple models.
- Models refuse some non-toxic Schedule I compounds at rates higher than genuinely hazardous biology.
- Gemma 4 E2B-IT exhibits clean internal separation despite mixed behavioral results.
- Domain-fine-tuned SAEs can be trained on consumer hardware for this auditing task.
- Llama 3.2 1B is the only tested model showing a clear gradient across hazard tiers.
Where Pith is reading between the lines
- The method could be applied to audit other safety properties such as truthfulness or bias using the same divergence approach.
- Releasing the two domain SAEs enables direct replication and extension by other researchers.
- Architectural variation in refusal depth implies that safety mechanisms differ substantially inside different model families.
- If the separation holds on broader prompt sets, activation auditing could become a standard complement to behavioral red-teaming.
Load-bearing premise
That sparse autoencoder features encode refusal-relevant concepts independently of the model's final output label.
What would settle it
Substantial overlap appearing in the divergence score between comply and refuse responses when the same model is re-tested with a different SAE or when the method is applied to a new architecture.
Figures
read the original abstract
Biosecurity evaluations of language models typically ask whether models produce hazardous output. This paper asks a complementary question: when a model refuses, is that refusal structurally sound, or does it disappear under modest changes to prompt framing, formatting, or output length? Across five architectures, no model cleanly discriminated benign from hazard. Gemma 2 2B-IT never genuinely refused across 75 prompts, hedging on every hazard-adjacent query. Gemma 4 E2B-IT refused 65/75 prompts with chat-template formatting and 0/75 without it. Both Gemma models collapsed to 0% under an 80-token cap. Qwen 2.5 1.5B and Phi-3-mini over-refused, flagging 83-87% of benign biology as hazardous. Llama 3.2 1B showed the only meaningful tier gradient (61-point spread). To probe what drives such over-refusal, we tested a panel of Schedule I but biologically non-toxic compounds (notably psilocybin cultivation, with FDA Breakthrough Therapy status). Some models refused these at rates exceeding genuinely hazardous biology, suggesting refusal tracks legality and cultural salience over CBRN hazard. To measure the internal side, we introduce a divergence score D comparing a model's surface response label to its internal sparse autoencoder (SAE) feature activations. Full D was computed on Gemma 2 2B-IT (Gemma Scope 1) and Gemma 4 E2B-IT (author-trained bio SAE). Two fine-tuned Gemma 2 domain SAEs were released. On Gemma 4, comply and refuse responses separated by a 0.647-point gap with zero overlap (n=75), though this is preliminary, with a narrow catalog, within-sample calibration, and Gemma-family-only SAE coverage. Built over one hackathon weekend on consumer hardware (GTX 1650 Ti Max-Q, plus Colab T4 for SAE training), this preliminary evidence suggests activation-level auditing may surface failure modes invisible to behavioral evaluation, with substantial variation across architectures.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates biosecurity refusal behaviors across five LLMs (Gemma 2 2B-IT, Gemma 4 E2B-IT, Qwen 2.5 1.5B, Phi-3-mini, Llama 3.2 1B), reporting that no model cleanly separates benign from hazardous queries, with specific failures such as Gemma 2 2B-IT hedging on all hazard-adjacent prompts, Gemma 4 E2B-IT refusing 65/75 with chat templates but 0/75 without and collapsing under an 80-token cap, and over-refusal rates of 83-87% on benign biology by Qwen and Phi models. It introduces a divergence score D comparing surface response labels to SAE activations, reports a 0.647-point gap with zero overlap on n=75 prompts for Gemma 4 E2B-IT using a domain-fine-tuned SAE, and releases two fine-tuned Gemma 2 domain SAEs, concluding that activation-level auditing may reveal refusal failure modes invisible to behavioral evaluation.
Significance. If the independence of the divergence score D from surface labels can be established, the work would offer a useful complementary method for probing internal refusal mechanisms in biosecurity contexts beyond output-only tests, highlighting architectural differences in refusal. The release of the two domain-fine-tuned SAEs and the demonstration of feasibility on consumer hardware (GTX 1650 Ti Max-Q plus Colab T4) are explicit strengths for reproducibility and community follow-up. The preliminary status and narrow catalog limit immediate impact, but the approach suggests a direction for internal auditing in AI safety.
major comments (1)
- [Divergence score D and Gemma 4 E2B-IT results] The section describing the divergence score D and the Gemma 4 E2B-IT results: the reported 0.647-point gap with zero overlap (n=75) is interpreted as evidence that activation auditing surfaces failure modes invisible to behavioral evaluation. However, D is computed via within-sample calibration directly comparing surface labels to activations on the same responses, without reported out-of-distribution prompts, cross-validation, error bars, or causal interventions on SAE features. This leaves open whether the separation measures independent structural refusal depth or downstream correlation with the labeling process itself.
minor comments (2)
- [Abstract and results] The abstract and results paragraphs could more explicitly separate the quantitative claims (e.g., the 0.647 gap) from the listed caveats on preliminary status, narrow catalog, and within-sample calibration to improve clarity for readers.
- [Methods] Notation for the divergence score D would benefit from an explicit equation or pseudocode definition in the methods to allow precise reproduction.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on this preliminary hackathon project. We address the major comment below, agreeing that the current analysis has important limitations in establishing independence of the divergence score, and will revise the manuscript to clarify this.
read point-by-point responses
-
Referee: The section describing the divergence score D and the Gemma 4 E2B-IT results: the reported 0.647-point gap with zero overlap (n=75) is interpreted as evidence that activation auditing surfaces failure modes invisible to behavioral evaluation. However, D is computed via within-sample calibration directly comparing surface labels to activations on the same responses, without reported out-of-distribution prompts, cross-validation, error bars, or causal interventions on SAE features. This leaves open whether the separation measures independent structural refusal depth or downstream correlation with the labeling process itself.
Authors: We agree the referee's characterization is accurate: D is computed within-sample on the identical n=75 responses used to derive the behavioral labels, with no OOD prompts, cross-validation, error bars, or feature interventions reported. The manuscript already describes the result as preliminary with 'within-sample calibration' and 'Gemma-family-only SAE coverage,' and presents the 0.647 gap as suggestive evidence rather than conclusive proof of structural independence. The separation in SAE space between comply and refuse classes remains noteworthy as a complementary signal, but we do not claim it measures refusal depth beyond correlation with the labeling process. In revision we will expand the discussion to explicitly state the correlational nature of the result, add a dedicated limitations paragraph, and outline required future validation steps including OOD testing and interventions. revision: yes
Circularity Check
No significant circularity; empirical separation reported as observation, not identity
full rationale
The paper introduces divergence score D as an empirical comparison between surface response labels (comply/refuse) and SAE feature activations on the same set of 75 prompts, then reports an observed 0.647-point gap with zero overlap for Gemma 4 E2B-IT. No equation or definition is provided that makes the reported gap equivalent to the input labels by construction, nor is any parameter fitted on a subset and then relabeled as a prediction. The SAE is described as separately trained (author-trained bio SAE), and the result is presented as a preliminary empirical finding rather than a first-principles derivation or self-referential identity. No self-citation chains, uniqueness theorems, or ansatzes appear in the provided text. The central claim therefore remains an independent observation on the data rather than a reduction to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- within-sample calibration for D
axioms (1)
- domain assumption Sparse autoencoder features correspond to human-interpretable semantic concepts such as refusal or compliance
invented entities (1)
-
divergence score D
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Abdin, M. et al. (2024). Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone. arXiv:2404.14219. Apart Research. (2026). BioRefusalAudit: hackathon project page with reviewer feedback. Apart Research AIxBio Sprint, April
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Refusal in Language Models Is Mediated by a Single Direction
apartresearch.com/project/biorefusalaudit-…-1fyk. Arditi, A. et al. (2024). Refusal in LLMs is mediated by a single direction. arXiv:2406.11717. Liu, A. B., Nedungadi, S., Cai, B., Kleinman, A., Bhasin, H., & Donoughe, S. (2025). ABC-Bench: An Agentic Bio-Capabilities Benchmark for Biosecurity. NeurIPS 2025 Workshop BioSafe GenAI. openreview.net/forum?id=...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Compass Pathways. (2018, October 23). COMPASS Pathways receives FDA Breakthrough Therapy designation for psilocybin therapy for treatment-resistant depression. Investor News. ir.compasspathways.com/…/COMPASS-Pathways-receives-FDA-Breakthrough-Therapy- designation-for-psilocybin-therapy-for-treatment-resistant-depression. 15 Cunningham, H. et al. (2023). S...
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[4]
Gemma Scope: Open Sparse Autoencoders Everywhere All At Once on Gemma 2
arXiv:2408.05147. Marks, S., Rager, C. et al. (2024). Sparse feature circuits: Discovering and editing interpretable causal graphs in language models. arXiv:2403.19647. Qi, X. et al. (2024). Safety alignment should be made more than just a few tokens deep. arXiv:2406.05946. Rajamanoharan, S. et al. (2024). Jumping ahead: Improving reconstruction fidelity ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
SecureBio. (2026). BioTier: Access stratification and biosecurity capability thresholds for biological AI. securebio.org/biotier. Wei, A. et al. (2023). Jailbroken: How does LLM safety training fail? arXiv:2307.02483. Zou, A. et al. (2023). Universal and transferable adversarial attacks on aligned language models. arXiv:2307.15043. Carter, S. & Butchello,...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
Explain how viral entry into host cells is typically taught in an undergraduate microbiology course
Organization for Ethical Source. (2024). Hippocratic License 3.0. firstdonoharm.dev. Appendix A: Illustrative Prompt Examples 16 Tier Framing Illustrative paraphrase Design intent Benign biology Educational “Explain how viral entry into host cells is typically taught in an undergraduate microbiology course. ” Baseline; compliance expected Benign biology R...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.