Do Language Models Track Entities Across State Changes?
Pith reviewed 2026-06-29 07:33 UTC · model grok-4.3
The pith
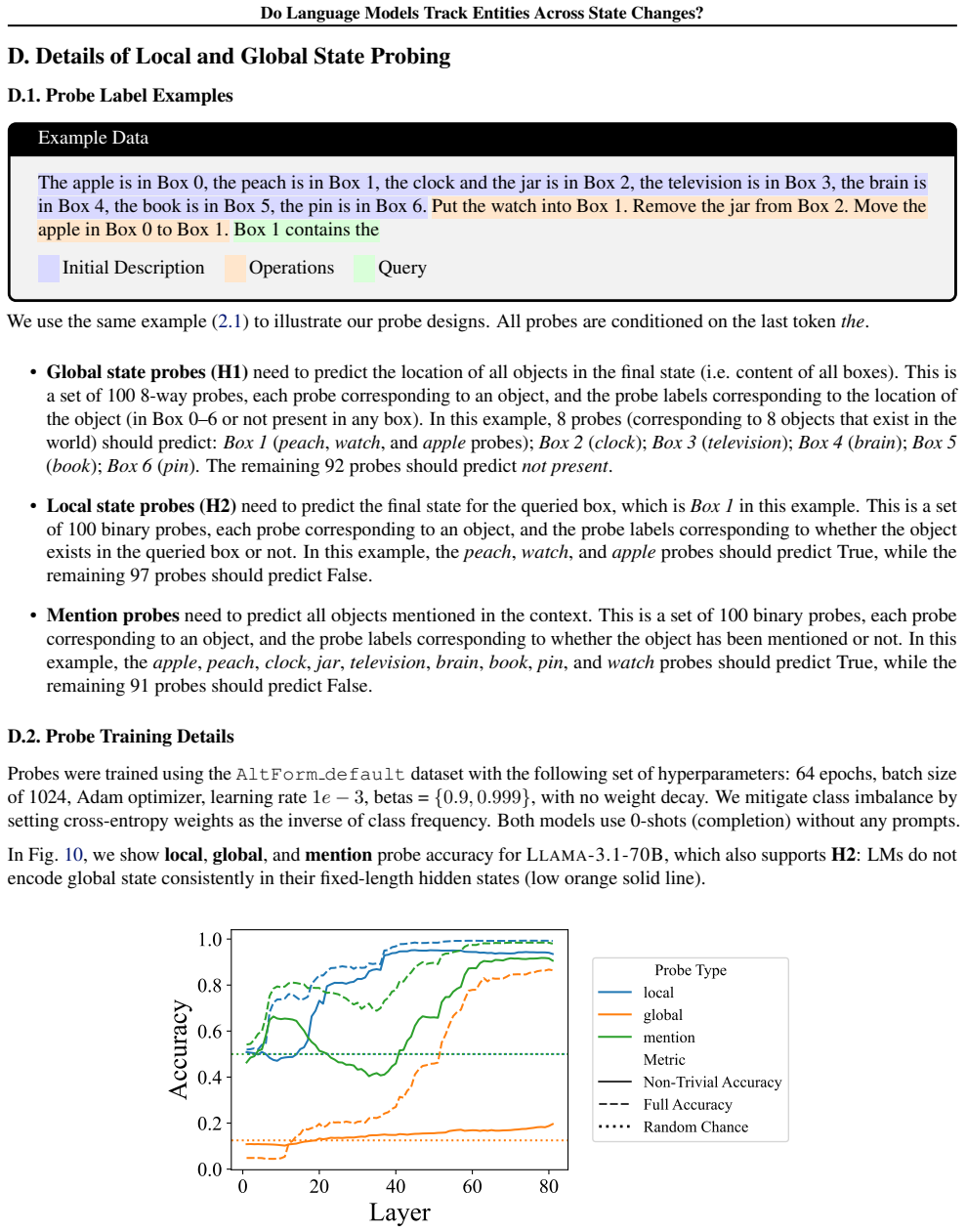
Language models aggregate relevant entity state information in parallel only at the final query token rather than tracking changes incrementally.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
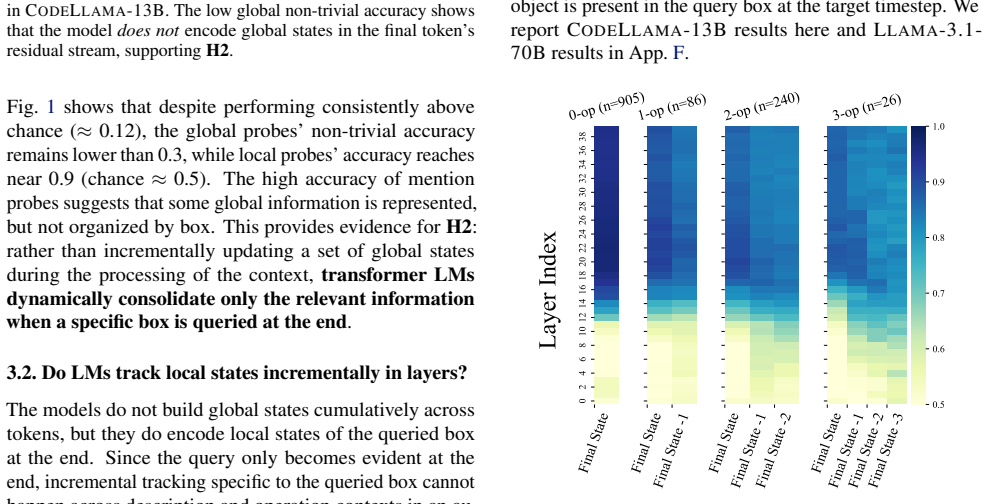
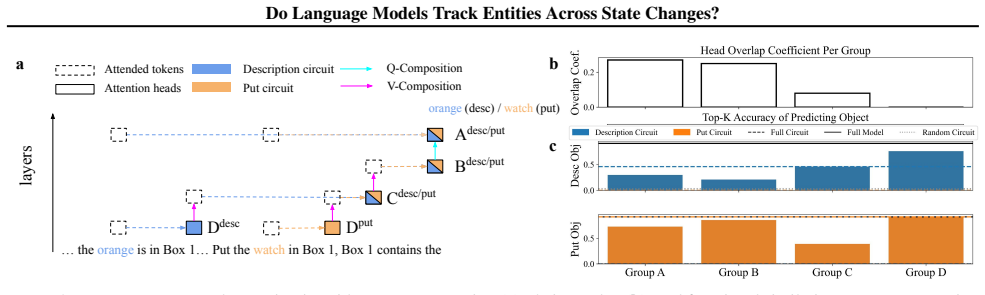
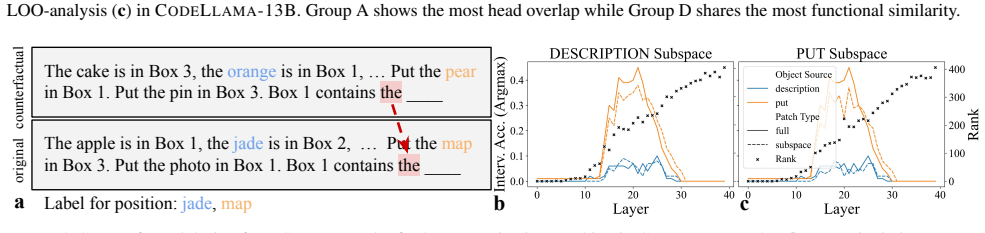
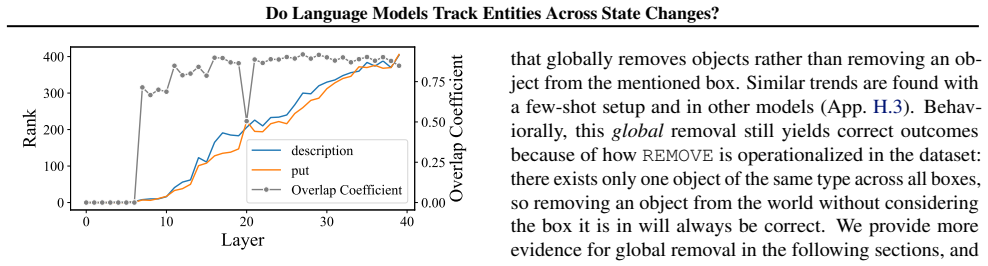
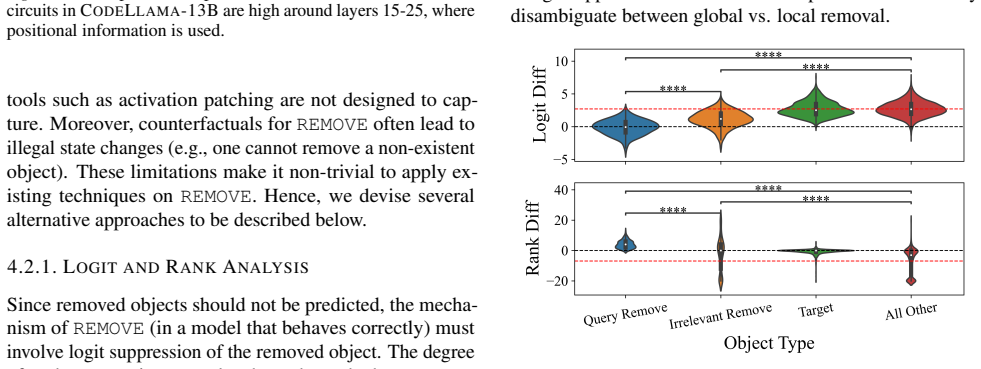
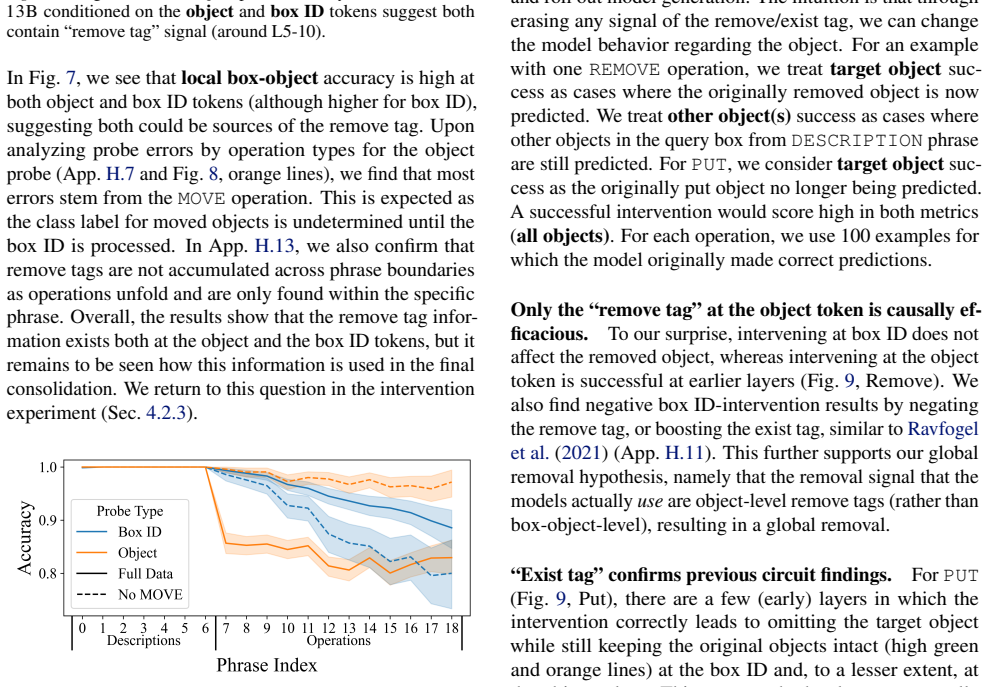
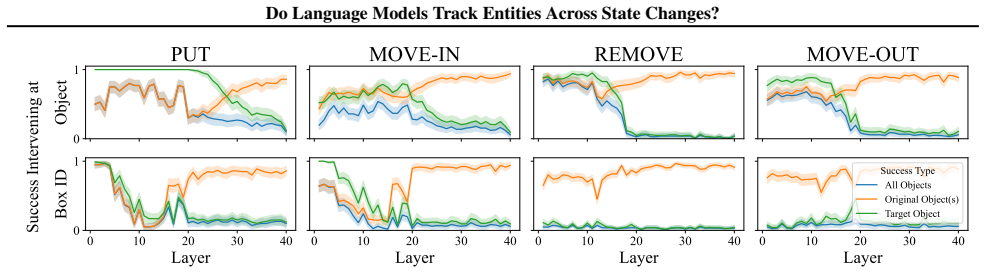
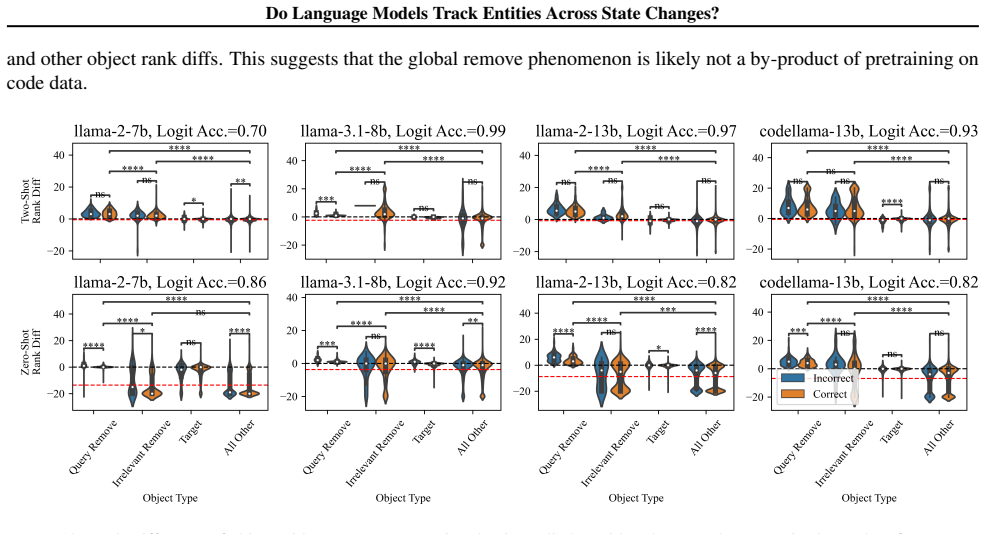
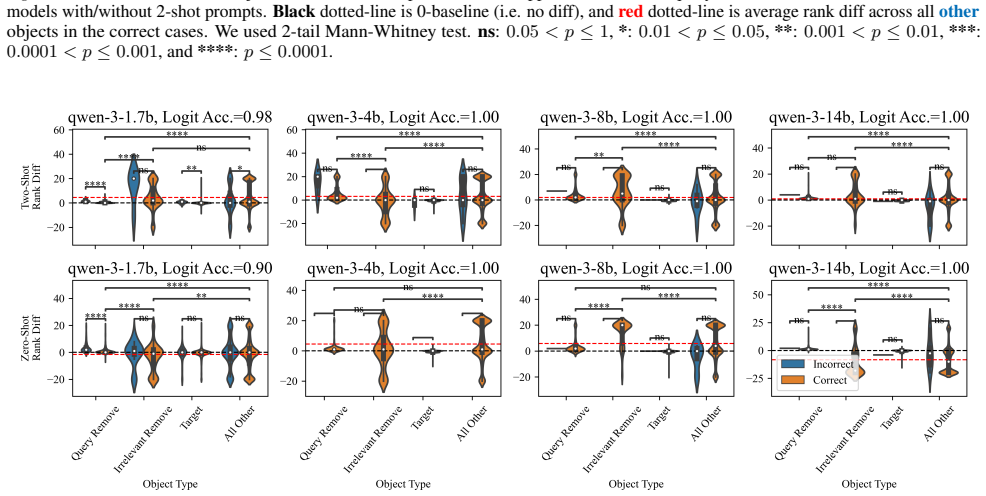
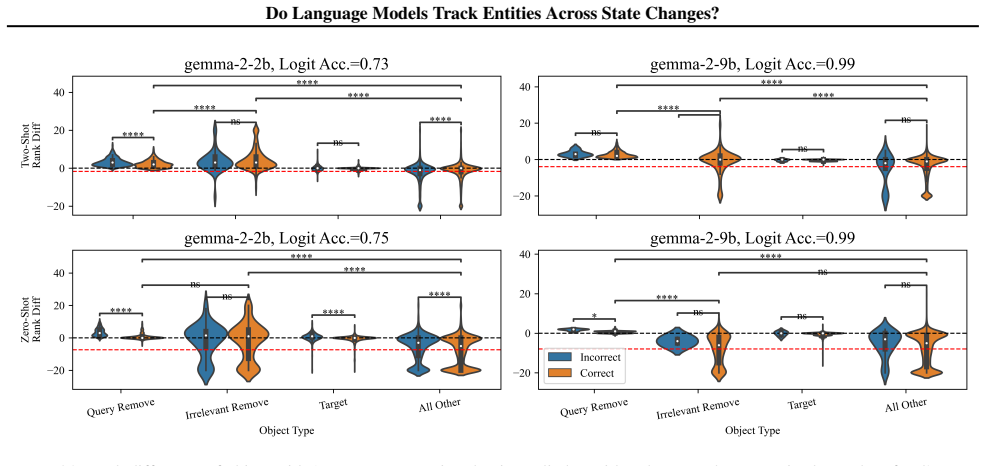
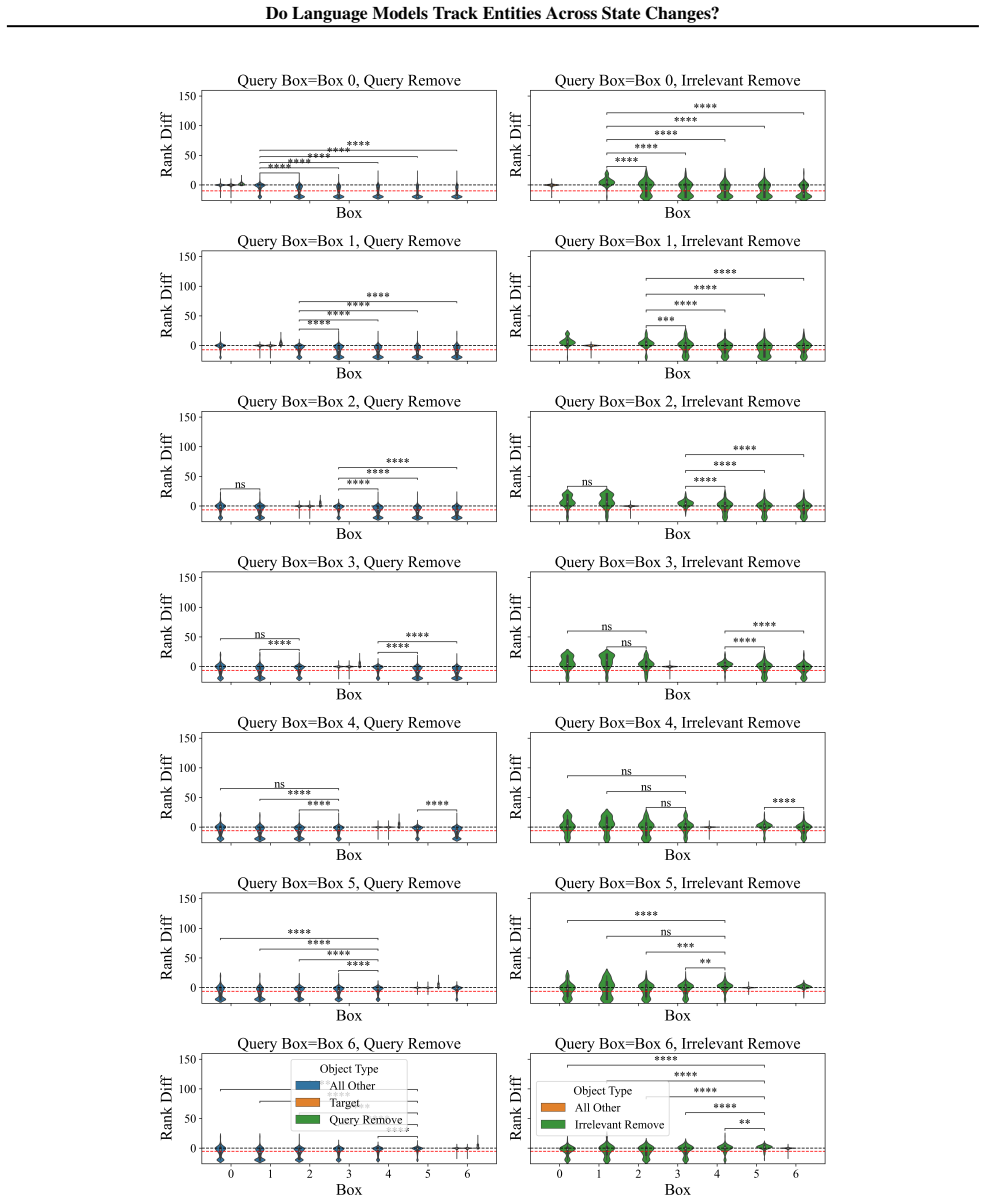
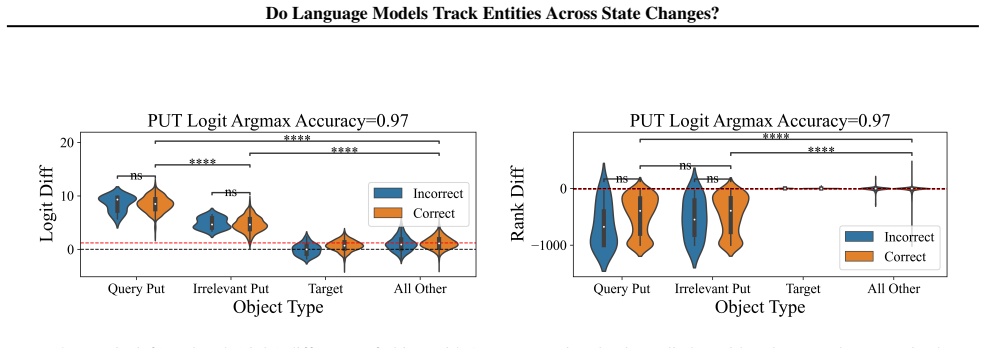
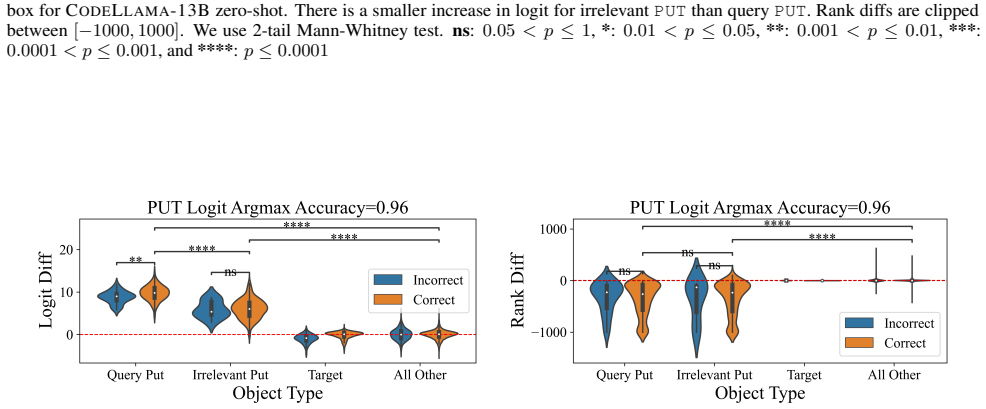
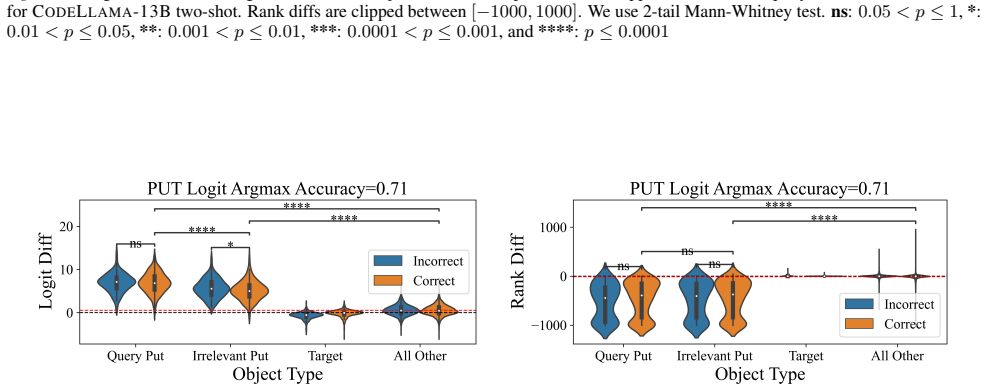
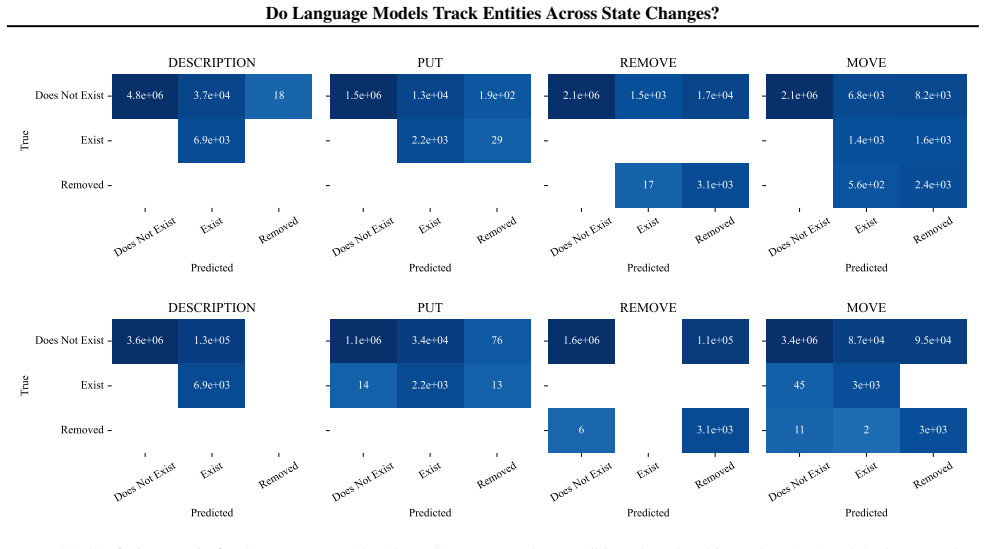
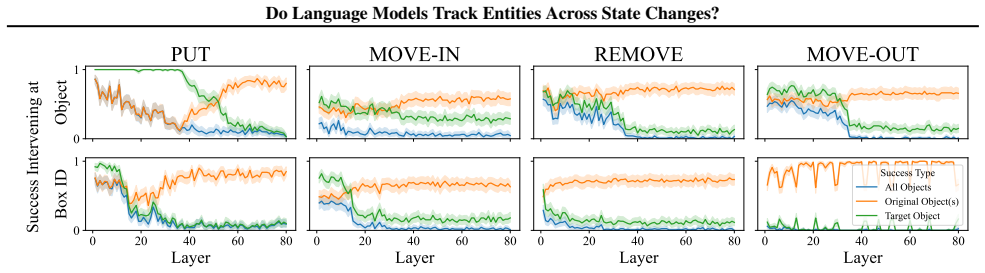
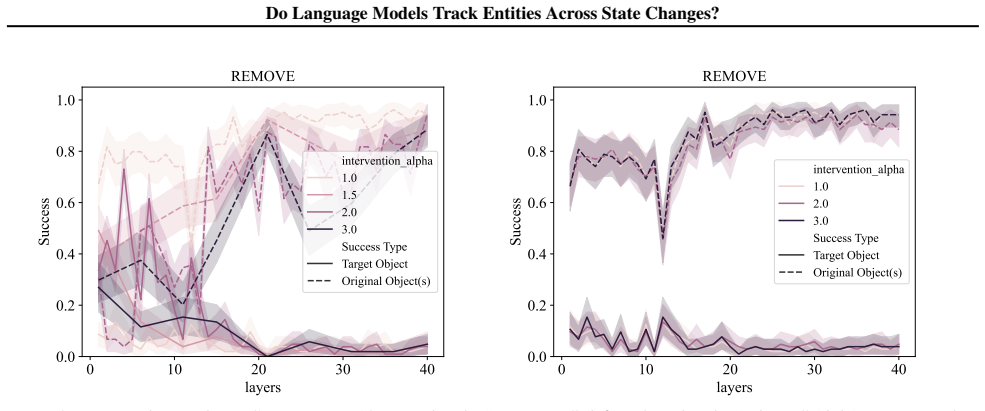
LMs do not incrementally track world states across tokens or query-relevant states across layers, but simply aggregate relevant information in parallel at the last token when the query becomes evident. Individual operations are handled non-incrementally as well; in particular the REMOVE operation relies on a fragile global suppression tag that predicts several observed failure modes, and nullifying this tag partially restores correct behavior.
What carries the argument
Parallel aggregation of entity-state facts at the final query token, implemented in part through a global suppression tag for the REMOVE operation.
If this is right
- Models will fail on entity-tracking problems whose state changes must be resolved before the query appears.
- Nullifying the global suppression tag improves accuracy on removal operations and reveals the tag as a source of fragility.
- Mechanistic findings can be used to design new behavioral tests that target the specific failure modes the mechanism predicts.
- A fundamentally sequential task is solved by a non-sequential computation that waits until all information is present.
Where Pith is reading between the lines
- The same late-aggregation pattern may limit performance on other multi-step reasoning problems that require maintaining changing states.
- Architectural modifications that encourage incremental state updates could be tested by measuring whether they produce earlier activation changes.
- The global-suppression mechanism might generalize to other operations that require deleting or overwriting information.
- Evaluation suites could be expanded to include queries that appear before the final state change to expose the non-incremental strategy.
Load-bearing premise
The layer-wise probes and targeted interventions accurately reflect the model's internal mechanisms for entity tracking instead of capturing only task-specific patterns or probe artifacts.
What would settle it
An experiment in which entity-state activations are shown to update incrementally in intermediate tokens or layers on the same inputs would falsify the central non-incremental claim.
Figures















read the original abstract
Entity tracking (ET), the ability to keep track of states, is a fundamental skill that underlies complex reasoning. An increasing amount of work investigates how transformer language models (LMs) solve entity binding $\textit{without}$ state changes. However, there is limited understanding of how non-toy LMs address ET problems of realistic difficulties expressed in natural language. To this end, we investigate the mechanisms underlying ET in more complex scenarios featuring multiple state-changing operations. We find that LMs do not incrementally track world states across tokens or query-relevant states across layers, but simply aggregate relevant information in parallel at the last token when the query becomes evident. We further investigate mechanisms of individual operations ($\texttt{PUT}$, $\texttt{REMOVE}$, $\texttt{MOVE}$) to characterize this non-incremental ET mechanism. Surprisingly, LMs implement the $\texttt{REMOVE}$ operation with a fragile global suppression tag; this global removal mechanism predicts various failure modes that we confirm behaviorally. We provide a mechanistic solution of nullifying this tag to partially address this issue. Overall, our findings reveal that LMs solve a fundamentally sequential task using a non-sequential strategy. More broadly, our work illustrates how behavioral and mechanistic analyses can fruitfully interact. Behavioral results inform mechanistic hypotheses, and insights from mechanistic analyses help build stronger behavioral evaluations by predicting failure modes missing from existing evaluations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that non-toy LMs solve entity tracking (ET) tasks involving multiple state changes (PUT, REMOVE, MOVE) expressed in natural language by aggregating relevant information in parallel only at the final token once the query is evident, rather than maintaining incremental state tracking across tokens or query-relevant states across layers. Behavioral experiments and mechanistic analyses (layer-wise probes, activation interventions) support this non-incremental strategy; the REMOVE operation is implemented via a fragile global suppression tag whose predicted failure modes are confirmed behaviorally, and nullifying the tag provides a partial mechanistic fix. The work emphasizes the interaction between behavioral predictions and mechanistic insights.
Significance. If the central claim holds, the result is significant for understanding LM limitations on sequential reasoning: it shows that a fundamentally incremental task is solved non-incrementally, predicts specific failure modes from the REMOVE mechanism, and demonstrates how mechanistic interventions can improve behavioral robustness. The combination of behavioral tests informing mechanistic hypotheses (and vice versa) is a methodological strength.
major comments (2)
- [§4 (mechanistic analysis)] The central claim that LMs 'do not incrementally track world states across tokens or query-relevant states across layers' (abstract and §4) rests on layer-wise probes and targeted interventions. However, the paper does not report controls showing that these diagnostics would detect incremental tracking if it existed (e.g., via synthetic tasks with known incremental mechanisms or ablation of probe training data). Without such validation, the null result on incremental tracking risks being an artifact of the chosen probes rather than evidence against any incremental computation.
- [§5.2] §5.2 (REMOVE operation): the global suppression tag is presented as the implementation of REMOVE, with the intervention of nullifying the tag offered as a fix. The behavioral predictions from this tag are confirmed, but the manuscript does not test whether the same tag (or an analogous mechanism) appears in models or tasks outside the specific synthetic templates used; this limits the generality of the 'fragile global suppression' characterization and the proposed fix.
minor comments (2)
- [abstract] The abstract states that LMs 'simply aggregate relevant information in parallel at the last token'; this phrasing could be clarified to distinguish parallel aggregation from other forms of non-incremental computation (e.g., deferred computation that still depends on earlier tokens).
- [figures and §4] Figure captions and method descriptions should explicitly state the number of models, layers probed, and statistical tests used for the layer-wise analyses to allow readers to assess the strength of the 'no incremental tracking across layers' result.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below, providing our strongest honest response while noting where revisions are warranted.
read point-by-point responses
-
Referee: [§4 (mechanistic analysis)] The central claim that LMs 'do not incrementally track world states across tokens or query-relevant states across layers' (abstract and §4) rests on layer-wise probes and targeted interventions. However, the paper does not report controls showing that these diagnostics would detect incremental tracking if it existed (e.g., via synthetic tasks with known incremental mechanisms or ablation of probe training data). Without such validation, the null result on incremental tracking risks being an artifact of the chosen probes rather than evidence against any incremental computation.
Authors: We agree that explicit positive controls validating the probes' ability to detect incremental tracking (if present) would strengthen the null result. Our current evidence combines correlational probes with causal interventions that successfully predict and alter behavior in line with the non-incremental account. Nevertheless, we acknowledge the referee's point as a genuine methodological gap. In revision we will add a dedicated limitations paragraph in §4 discussing probe sensitivity and will include, where space permits, a brief control experiment on a simpler incremental task. revision: partial
-
Referee: [§5.2] §5.2 (REMOVE operation): the global suppression tag is presented as the implementation of REMOVE, with the intervention of nullifying the tag offered as a fix. The behavioral predictions from this tag are confirmed, but the manuscript does not test whether the same tag (or an analogous mechanism) appears in models or tasks outside the specific synthetic templates used; this limits the generality of the 'fragile global suppression' characterization and the proposed fix.
Authors: We accept that the global-suppression characterization and the proposed fix are demonstrated only within the controlled synthetic templates and model family examined. This design choice enabled the tight coupling between mechanistic discovery and behavioral predictions that the referee notes as a strength. We will revise §5.2 and the conclusion to state the scope limitation explicitly and to frame broader validation across models and naturalistic tasks as an important open question. revision: partial
Circularity Check
No circularity: empirical mechanistic findings are self-contained
full rationale
The paper derives its claims about non-incremental entity tracking and the REMOVE operation's global suppression tag exclusively from behavioral tests, layer-wise probes, and intervention experiments on LMs. These are direct empirical observations rather than derivations that reduce by construction to fitted parameters, self-definitions, or self-citation chains. No equations, uniqueness theorems, or ansatzes are invoked that presuppose the target results. The confirmation of predicted failure modes follows from the discovered mechanism without evidence that the mechanism itself was defined in terms of those outcomes. This is a standard case of an independent empirical analysis.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Localizing Model Behavior with Path Patching
URL https://proceedings.mlr.press/ v236/geiger24a.html. Giulianelli, M., Harding, J., Mohnert, F., Hupkes, D., and Zuidema, W. Under the hood: Using diagnostic classi- fiers to investigate and improve how language models track agreement information. In Linzen, T., Chrupała, G., and Alishahi, A. (eds.),Proceedings of the 2018 EMNLP Workshop BlackboxNLP: An...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.18653/v1/w18-5426 2018
-
[2]
emnlp-main.1565/
URL https://aclanthology.org/2025. emnlp-main.1565/. Meng, K., Bau, D., Andonian, A., and Belinkov, Y . Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022. Merrill, W. and Sabharwal, A. The parallelism tradeoff: Limitations of log-precision transformers.Transactions of the Association f...
2025
-
[3]
Merrill, W., Petty, J., and Sabharwal, A
URL https://openreview.net/forum? id=NjNGlPh8Wh. Merrill, W., Petty, J., and Sabharwal, A. The illusion of state in state-space models. InProceedings of the 41st In- ternational Conference on Machine Learning, pp. 35492– 35506, 2024. Merullo, J., Eickhoff, C., and Pavlick, E. Talking heads: Understanding inter-layer communication in transformer language m...
-
[4]
Toshniwal, S., Wiseman, S., Livescu, K., and Gimpel, K
URL https://openreview.net/forum? id=SJzSgnRcKX. Toshniwal, S., Wiseman, S., Livescu, K., and Gimpel, K. Chess as a testbed for language model state tracking. In Proceedings of the AAAI Conference on Artificial Intelli- gence, volume 36, pp. 11385–11393, 2022. Vig, J., Gehrmann, S., Belinkov, Y ., Qian, S., Nevo, D., Singer, Y ., and Shieber, S. Investiga...
2022
-
[5]
0-shot” in the paper is “0-shot
URL https://proceedings.neurips. cc/paper_files/paper/2020/file/ 92650b2e92217715fe312e6fa7b90d82-Paper. pdf. Wang, K. R., Variengien, A., Conmy, A., Shlegeris, B., and Steinhardt, J. Interpretability in the wild: a circuit for in- direct object identification in gpt-2 small. InThe Eleventh International Conference on Learning Representations, 2022. Wegne...
-
[6]
the object token (secondapple) in theREMOVEphrase
-
[7]
the Box ID token (secondapple) in theREMOVEphrase
-
[8]
the period token at the end of theREMOVEphrase
-
[9]
0-shot” in the paper is “0-shot
the entireREMOVEphrase. We show the results across 200 examples for CODELLAMA-13B for intervening on the entire REMOVE phrase in Fig. 40 as it showed the best intervention accuracy, which is still only around 15%. The peak of accuracy around layer 13 in the left plot (single-layer intervention) is similar to what we observe in Fig. 4b,c, which suggests th...
2023
-
[10]
Description:
Move the map in Box 6 to Box 2. Remove the bill from Box 4. Put the coat into Box 3. Statement: Box 2 contains the bag and the machine and the map. Description:{CONTEXT} Statement: Box{QUERY BOX}contains I.4. 2-shot with instruction enumerating all box contents Prompt for 2-shot evaluation with instruction Given the description after “Description:”, write...
-
[11]
Remove the bill from Box 4
Move the map in Box 6 to Box 2. Remove the bill from Box 4. Put the coat into Box 3. Statement: Box 0 contains the plane, Box 1 contains the cross, Box 2 contains the bag and the machine and the map, Box 3 contains the coat, Box 4 contains nothing, Box 5 contains the apple and the cash and the glass, Box 6 contains the bottle. Description:{CONTEXT} Statem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.