Same Evidence, Different Answers: Canonical-Context On-Policy Distillation for Multi-Turn Language Models
Pith reviewed 2026-06-29 07:24 UTC · model grok-4.3
The pith
Training a model to match its full-prompt answers while generating its own multi-turn trajectories reduces drift from partial evidence and improves consistency across tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
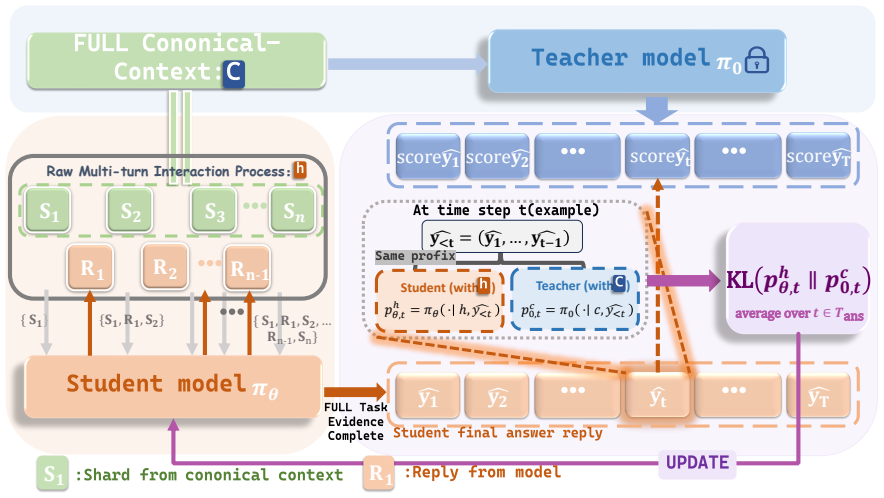
When the same complete user evidence is presented either as a clean full prompt or as a raw-sharded multi-turn conversation, models should produce identical answers; the gap arises because partial responses introduce unsupported assumptions that later distort the final answer. Canonical-Context On-Policy Distillation corrects this by using the base model in two roles: a frozen teacher conditioned on the full prompt supplies the target behavior, while the trainable student receives the identical evidence turn by turn and is trained on-policy to match the teacher's outputs on its own generated trajectories. This yields the reported 32 percent average relative improvement on raw-sharded perform
What carries the argument
Canonical-Context On-Policy Distillation (CCOPD), in which the identical base model acts as frozen teacher on the clean full prompt and as trainable student on incremental conversations, aligning the student's behavior on its own trajectories to the teacher's canonical full-context answers.
If this is right
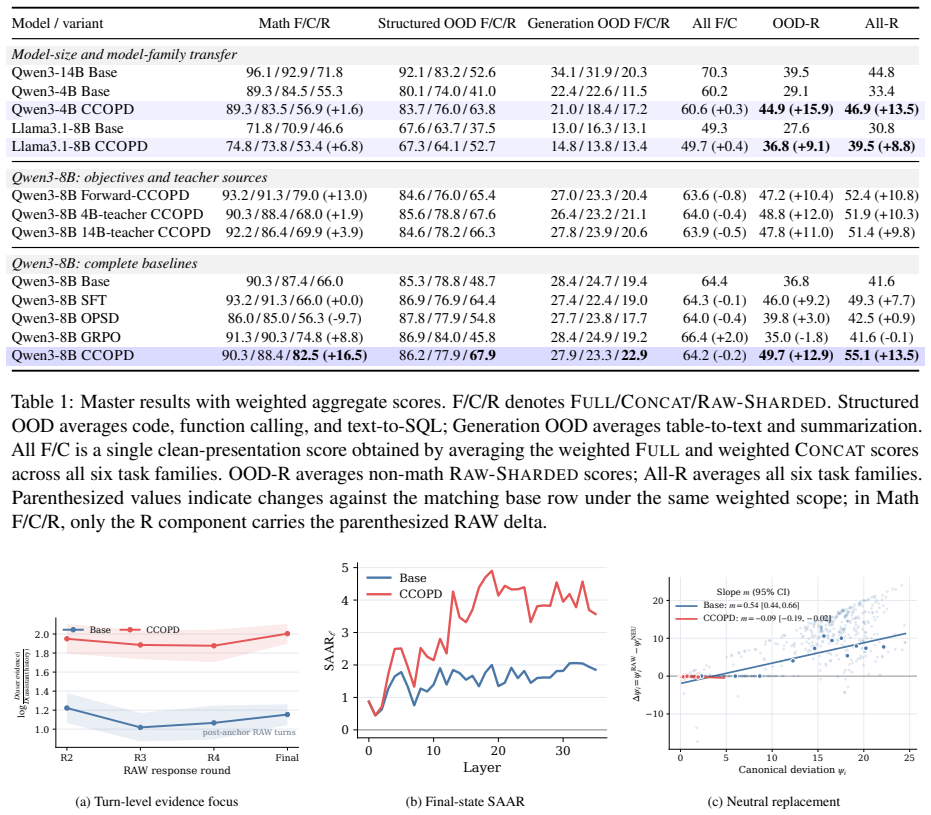
- RAW-SHARDED performance improves by 32 percent relative on average across math and five zero-shot out-of-domain families.
- Full-context performance is largely preserved after training.
- Grounding in user-provided evidence is strengthened and sensitivity to contamination from prior assistant turns is reduced.
- The improvement transfers to tasks outside the math-only training distribution.
- The same base model can serve simultaneously as teacher and student without external supervision.
Where Pith is reading between the lines
- The method could be applied to other incremental-information settings such as long-running dialogues or step-by-step reasoning chains where early assumptions must not propagate unchecked.
- If the teacher's full-context answers contain systematic errors, the distillation process would embed those errors into the student's multi-turn behavior.
- Extending the training distribution beyond math problems might further widen the set of tasks that benefit from reduced context drift.
Load-bearing premise
The frozen teacher's answers on the clean full prompt are the correct canonical target, and aligning the student to those answers on its own generated trajectories transfers the desired behavior without introducing new drift or distribution shift.
What would settle it
A controlled experiment in which the distilled student is evaluated on full-prompt inputs and produces answers that systematically diverge from the frozen teacher, or in which raw-sharded accuracy shows no gain or a loss relative to the base model.
Figures


read the original abstract
Large language models (LLMs) often solve a task when all instructions are given in a single prompt, but fail when the same information is revealed gradually across turns. When a clean FULL prompt and a RAW-SHARDED conversation contain the same complete user evidence, the model should still arrive at the same answer. We argue that a key reason for this gap is self-anchored drift: responses produced under partial information introduce unsupported assumptions, and those assumptions later distort the final answer. To reduce this effect, we propose Canonical-Context On-Policy Distillation (CCOPD). During training, the same base model is used in two roles: a frozen teacher conditioned on the clean FULL prompt and a trainable student that receives the same evidence incrementally through a multi-turn conversation; CCOPD aligns the student's behavior on its own trajectories with the teacher's canonical full-context behavior. Trained only on math problem conversations, CCOPD yields a 32\% average relative improvement in RAW-SHARDED performance over the original base model across math and five zero-shot out-of-domain task families, while largely preserving full-context performance. Further analyses suggest that CCOPD strengthens grounding in user evidence and reduces sensitivity to contamination from earlier assistant turns.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Canonical-Context On-Policy Distillation (CCOPD) to address self-anchored drift in LLMs, where models solve tasks with full prompts but fail when the same evidence is revealed incrementally across conversation turns. CCOPD uses the base model as both a frozen teacher (conditioned on the clean FULL prompt) and a trainable student (receiving the evidence sharded across turns); the student is aligned on-policy to the teacher's canonical outputs on its own generated trajectories. Trained only on math problem conversations, the method is reported to yield a 32% average relative improvement in RAW-SHARDED performance over the base model across math and five zero-shot out-of-domain task families while largely preserving full-context performance.
Significance. If the empirical claims hold under detailed scrutiny, the result would be moderately significant for multi-turn LLM consistency: it offers a training-time intervention that improves sharded-evidence robustness without architectural changes or new data sources, and the reported zero-shot transfer from math-only training is noteworthy. The approach directly targets a practical failure mode (drift from partial information) and could inform distillation techniques more broadly, though its impact depends on whether the gains are robust to variations in base models and task distributions.
major comments (3)
- [Abstract] Abstract: the central claim of a 32% average relative improvement in RAW-SHARDED performance is presented without any information on the concrete metrics, the precise definition or computation of RAW-SHARDED, the baselines, the number of evaluation examples per task family, statistical significance testing, or data exclusion criteria. These omissions make it impossible to assess whether the reported gain supports the method's effectiveness.
- [Method / Experiments (implied by abstract description)] The core assumption that the frozen teacher's full-context answers constitute reliable canonical targets is load-bearing for the claimed benefit. If the base model produces incorrect or assumption-laden answers even when given the complete prompt (a known issue in math reasoning and zero-shot tasks), on-policy distillation will propagate those errors rather than correct drift. The manuscript provides no per-example analysis comparing teacher outputs to ground truth, nor an ablation isolating cases where the teacher itself errs.
- [Experiments / Results (implied by abstract)] The generalization claim (math-only training yields gains on five out-of-domain families) is central yet unsupported by any reported controls for task similarity, prompt formatting differences, or whether the out-of-domain tasks were truly zero-shot with respect to the training distribution.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below, providing clarifications from the manuscript and committing to revisions where details or analyses are missing.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of a 32% average relative improvement in RAW-SHARDED performance is presented without any information on the concrete metrics, the precise definition or computation of RAW-SHARDED, the baselines, the number of evaluation examples per task family, statistical significance testing, or data exclusion criteria. These omissions make it impossible to assess whether the reported gain supports the method's effectiveness.
Authors: We agree the abstract is too condensed. RAW-SHARDED denotes accuracy on multi-turn conversations where the full evidence is provided incrementally (vs. the single full prompt). The 32% figure is the mean relative gain in task-specific metrics (exact match for math, accuracy for others) vs. the base model baseline. Evaluation details, example counts, significance tests, and exclusion criteria appear in Sections 3-4. We will revise the abstract to define RAW-SHARDED and reference the experimental protocol. revision: yes
-
Referee: The core assumption that the frozen teacher's full-context answers constitute reliable canonical targets is load-bearing for the claimed benefit. If the base model produces incorrect or assumption-laden answers even when given the complete prompt (a known issue in math reasoning and zero-shot tasks), on-policy distillation will propagate those errors rather than correct drift. The manuscript provides no per-example analysis comparing teacher outputs to ground truth, nor an ablation isolating cases where the teacher itself errs.
Authors: This concern is valid. The approach assumes the full-context teacher yields higher-quality targets than the sharded student. We report that full-context performance is largely preserved after distillation, which indirectly suggests limited degradation. However, the manuscript lacks explicit per-example teacher-vs-ground-truth comparisons or ablations on teacher-error cases. We will add these analyses in the revision, reporting teacher accuracy rates and the impact of distilling from erroneous teacher outputs. revision: yes
-
Referee: The generalization claim (math-only training yields gains on five out-of-domain families) is central yet unsupported by any reported controls for task similarity, prompt formatting differences, or whether the out-of-domain tasks were truly zero-shot with respect to the training distribution.
Authors: We agree additional controls would strengthen the claim. Training used only math conversations; the five out-of-domain families involve distinct reasoning types with no training overlap and uniform sharding/prompt formatting. We will expand the revision with task-selection criteria, any available similarity metrics between math and out-of-domain distributions, and explicit confirmation of zero-shot status. revision: yes
Circularity Check
No circularity: empirical training procedure with no derivation chain or self-referential reductions
full rationale
The paper describes CCOPD as a practical distillation procedure: a frozen teacher (base model on full prompt) provides targets, and the student is trained on-policy to match those targets on sharded trajectories. No equations, fitted parameters, uniqueness theorems, or ansatzes are introduced that reduce to the inputs by construction. Performance numbers (e.g., 32% relative gain) are reported from experiments rather than derived; the central claim does not rely on self-citation load-bearing or renaming of known results. The method is self-contained as an empirical intervention whose validity is tested externally via held-out tasks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code.Preprint, arXiv:2107.03374. Qinyuan Cheng, Tianxiang Sun, Xiangyang Liu, Wen- wei Zhang, Zhangyue Yin, Shimin Li, Linyang Li, Zhengfu He, Kai Chen, and Xipeng Qiu. 2024. Can AI assistants know what they don’t know? InPro- ceedings of the 41st International Conference on Ma- chine Learning, volume 235 ofProc...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.arXiv preprint arXiv:2110.14168. Jeremy Cole, Michael Zhang, Daniel Gillick, Julian Eisenschlos, Bhuwan Dhingra, and Jacob Eisenstein
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
From Explicit CoT to Implicit CoT: Learning to Internalize CoT Step by Step
Selectively answering ambiguous questions. InProceedings of the 2023 Conference on Empiri- cal Methods in Natural Language Processing, pages 530–543, Singapore. Association for Computational Linguistics. Yuntian Deng, Yejin Choi, and Stuart Shieber. 2024. From explicit cot to implicit cot: Learning to internalize cot step by step.arXiv preprint arXiv:2405...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Clarifymt-bench: Benchmarking and improv- ing multi-turn clarification for conversational large language models.Preprint, arXiv:2512.21120. Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Wellec...
-
[5]
Learning beyond Teacher: Generalized On-Policy Distillation with Reward Extrapolation
Large language models are better reasoners with self-verification. InFindings of the Associa- tion for Computational Linguistics: EMNLP 2023, pages 2550–2575, Singapore. Association for Com- putational Linguistics. Shirley Wu, Michel Galley, Baolin Peng, Hao Cheng, Gavin Li, Yao Dou, Weixin Cai, James Zou, Jure Leskovec, and Jianfeng Gao. 2025. CollabLLM:...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
OPSDL: On-Policy Self-Distillation for Long-Context Language Models
Modeling future conversation turns to teach LLMs to ask clarifying questions. InInternational Conference on Learning Representations. Tong Zhang, Peixin Qin, Yang Deng, Chen Huang, Wen- qiang Lei, Junhong Liu, Dingnan Jin, Hongru Liang, and Tat-Seng Chua. 2024b. CLAMBER: A bench- mark of identifying and clarifying ambiguous infor- mation needs in large la...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
(12) Proof
=E y∼P h θ τ(y)X t=1 dt(y) ,(11) where dt(y) =D KL(πθ(· |h, y <t)∥π0(· |c, y <t)). (12) Proof. For any terminal answer string y= (y1, . . . , yτ(y) )∈ A , the two autoregressive dis- tributions factor as P h θ (y) = τ(y)Y t=1 πθ(yt |h, y <t),(13) P c 0(y) = τ(y)Y t=1 π0(yt |c, y <t).(14) Substituting these factorizations into sequence- 11 Model Va...
-
[8]
verified
= X y∈A P h θ (y) log P h θ (y) P c 0(y) =E y∼P h θ τ(y)X t=1 log πθ(yt |h, y <t) π0(yt |c, y <t) . (15) Conditioning on a realized prefix y<t under P h θ , the next token yt is distributed as πθ(· |h, y <t). Therefore, E log πθ(yt |h, y <t) π0(yt |c, y <t) y<t =D KL(πθ(· |h, y <t)∥π0(· |c, y <t)). (16) Applying Equation (16) inside Equation (15) ...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.