minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
Pith reviewed 2026-06-29 08:20 UTC · model grok-4.3
The pith
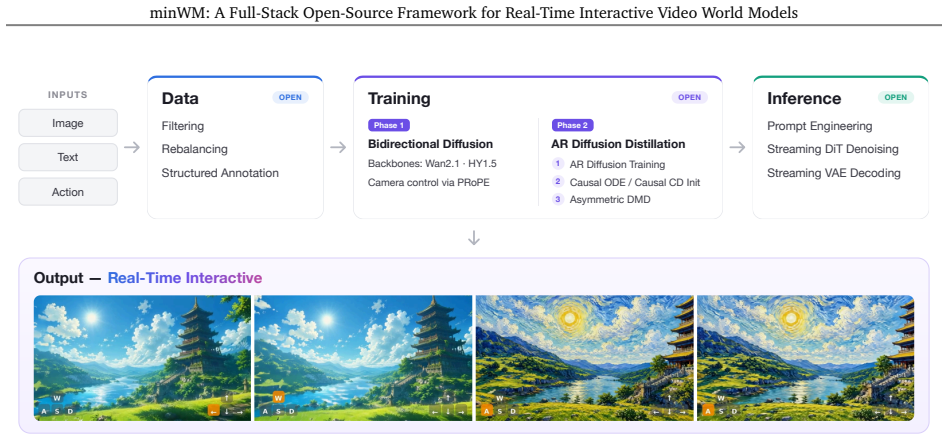
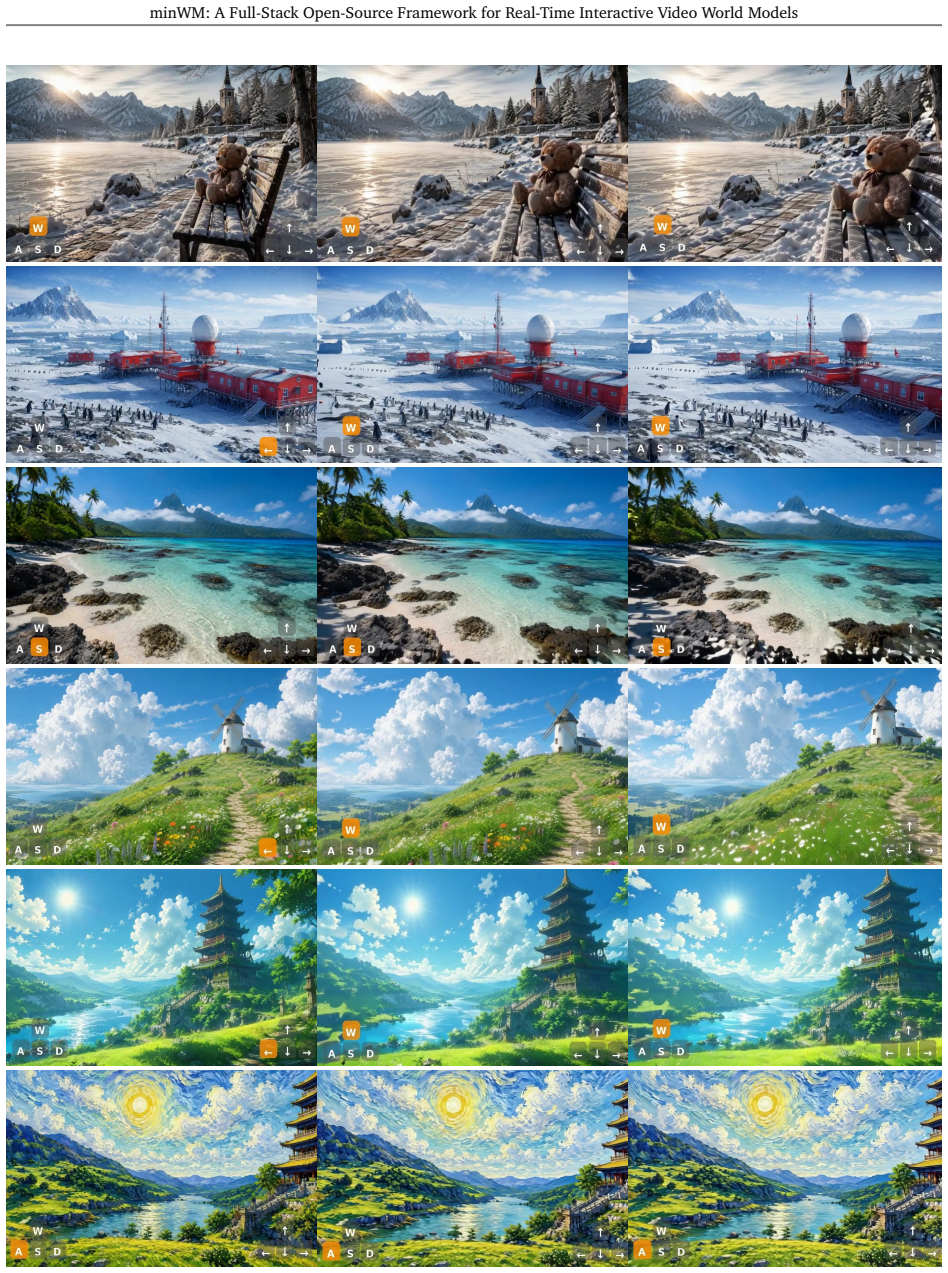
minWM framework converts bidirectional video diffusion models into camera-controllable autoregressive world models for real-time interaction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
minWM provides an end-to-end pipeline that converts existing bidirectional T2V/TI2V video foundation models into camera-controllable few-step autoregressive world models. Specifically, it first fine-tunes a bidirectional video diffusion model with camera control, and then applies the Causal Forcing / Causal Forcing++ pipeline, including AR diffusion training, causal ODE or causal consistency distillation, and asymmetric DMD, to distill it into a few-step autoregressive generator for low-latency rollout. The framework is modular and architecture-extensible across cross-attention-based and MMDiT-style models, and it also supports adapting existing video world models to new data distributions a
What carries the argument
The Causal Forcing / Causal Forcing++ pipeline, which performs autoregressive diffusion training, causal ODE or consistency distillation, and asymmetric DMD to turn bidirectional models into few-step autoregressive generators.
If this is right
- Existing bidirectional video models gain camera controllability through targeted fine-tuning.
- Autoregressive rollouts at low latency become available after the distillation steps.
- The same pipeline works on both cross-attention and MMDiT architectures.
- Existing video world models can be adapted to new data and latency targets.
- Practical minimums for batch size and training steps are established through ablations.
Where Pith is reading between the lines
- The modular design could support adding other control signals such as object motion or text instructions on top of camera trajectories.
- The released scripts and checkpoints could serve as a starting point for testing the pipeline on newer or larger video backbones as they appear.
- Community users might combine this conversion method with different distillation techniques to trade off speed and quality in new ways.
Load-bearing premise
The Causal Forcing pipeline can reliably produce low-latency high-quality autoregressive rollouts from bidirectional models without major quality loss or instability.
What would settle it
A side-by-side comparison on the same prompts showing that videos from the distilled few-step autoregressive models exhibit clear instability such as flickering, drifting camera paths, or loss of visual coherence over dozens of frames compared with the original bidirectional model.
Figures



read the original abstract
Recent video diffusion foundation models have achieved remarkable progress in high-quality video generation, yet turning them into real-time interactive video world models remains challenging. Interactive world models require controllable, causal, and low-latency rollout, which in practice demands a full pipeline spanning data construction, controllable fine-tuning, autoregressive training, few-step distillation, and streaming inference. In this work, we present minWM, a full-stack open-source framework for building real-time interactive video world models. minWM provides an end-to-end pipeline that converts existing bidirectional T2V/TI2V video foundation models into camera-controllable few-step autoregressive world models. Specifically, minWM first fine-tunes a bidirectional video diffusion model with camera control, and then applies the Causal Forcing / Causal Forcing++ pipeline, including AR diffusion training, causal ODE or causal consistency distillation, and asymmetric DMD, to distill it into a few-step autoregressive generator for low-latency rollout. The framework is modular and architecture-extensible: we instantiate it on representative open backbones, including Wan2.1-T2V-1.3B and HY1.5-TI2V-8B, covering both cross-attention-based condition injection and MMDiT-style architectures. minWM also supports adapting existing video world models, such as HY-WorldPlay, to new data distributions, training recipes, and latency targets. Beyond releasing runnable scripts, checkpoints, documentation, and inference code, we provide practical ablations on camera trajectory quality, controllability training steps, and minimal batch-size requirements. We hope minWM serves as a reproducible and extensible recipe for building and adapting real-time interactive video world models. Project Page: [https://github.com/shengshu-ai/minWM](https://github.com/shengshu-ai/minWM)
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents minWM, an open-source full-stack framework that converts existing bidirectional T2V/TI2V video diffusion models (e.g., Wan2.1-T2V-1.3B, HY1.5-TI2V-8B) into camera-controllable few-step autoregressive world models. The pipeline consists of camera-controlled fine-tuning of the bidirectional model, followed by AR diffusion training, causal ODE/consistency distillation, and asymmetric DMD to enable low-latency rollout; the work also supports adaptation of existing world models and releases code, checkpoints, and ablations on camera trajectories, controllability steps, and batch size.
Significance. If the described pipeline reliably yields stable low-latency rollouts with limited quality degradation, the contribution would be significant for lowering barriers to interactive video world models. The modular architecture support, open-source release of runnable scripts and checkpoints, and practical ablations constitute concrete strengths that aid reproducibility.
major comments (2)
- [Abstract and Evaluation section] Abstract and Evaluation section: The central claims of low-latency, high-quality autoregressive rollouts without major quality loss rest on unshown quantitative results; no FVD, temporal consistency, perceptual quality, or long-horizon rollout metrics versus the base bidirectional models are reported, leaving the success of the Causal Forcing / Causal Forcing++ pipeline unverified.
- [§3 (Causal Forcing pipeline description)] §3 (Causal Forcing pipeline description): The assumption that AR diffusion training plus causal ODE/consistency distillation and asymmetric DMD can convert non-causal bidirectional models into stable causal few-step generators is load-bearing for the main claim, yet the manuscript provides no empirical evidence on compounding artifacts, temporal drift, or stability over extended rollouts.
minor comments (1)
- [Project Page and Code Release] Ensure the GitHub repository link includes complete documentation, all referenced training/inference scripts, and the exact checkpoints used for the reported ablations.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback emphasizing the need for quantitative validation. We agree that the manuscript as submitted does not contain the requested metrics or stability analyses, and we will revise accordingly to address these gaps.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] Abstract and Evaluation section: The central claims of low-latency, high-quality autoregressive rollouts without major quality loss rest on unshown quantitative results; no FVD, temporal consistency, perceptual quality, or long-horizon rollout metrics versus the base bidirectional models are reported, leaving the success of the Causal Forcing / Causal Forcing++ pipeline unverified.
Authors: We agree that direct quantitative comparisons are necessary to substantiate the claims. The current manuscript prioritizes the description of the modular pipeline, open-source release, and ablations on camera trajectories and training hyperparameters, but omits FVD, temporal consistency, perceptual quality, and long-horizon metrics against the base models. In the revised version we will add these evaluations in the Evaluation section, including comparisons that verify the Causal Forcing pipeline. revision: yes
-
Referee: [§3 (Causal Forcing pipeline description)] §3 (Causal Forcing pipeline description): The assumption that AR diffusion training plus causal ODE/consistency distillation and asymmetric DMD can convert non-causal bidirectional models into stable causal few-step generators is load-bearing for the main claim, yet the manuscript provides no empirical evidence on compounding artifacts, temporal drift, or stability over extended rollouts.
Authors: We concur that empirical evidence on rollout stability is required. Section 3 currently describes the pipeline components without accompanying experiments on compounding artifacts, temporal drift, or long-horizon behavior. We will incorporate such analyses and any observed limitations into the revised manuscript. revision: yes
Circularity Check
No circularity: engineering pipeline with no derivations or self-referential predictions
full rationale
The paper presents an open-source framework and modular pipeline for adapting bidirectional video diffusion models into autoregressive world models via fine-tuning, AR training, distillation steps (Causal Forcing / Causal Forcing++), and inference. No mathematical derivations, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described structure. The work is self-contained as a reproducible recipe with code release and practical ablations on controllability and batch size; the central claim does not reduce to its own inputs by construction. This matches the default expectation for non-circular engineering papers.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Li Jing, David Schnurr , Joe T aylor , Troy Luhman, Eric Luhman, Clarence Ng, Ricky Wang, and Aditya Ramesh. Video generation models as world simulators. 2024
2024
-
[2]
Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models
Fan Bao, Chendong Xiang, Gang Yue, Guande He, Hongzhou Zhu, Kaiwen Zheng, Min Zhao, Shilong Liu, Y aole Wang, and Jun Zhu. Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models. arXiv preprint arXiv:2405.04233 , 2024
-
[3]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Y ang, Jiayan T eng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Y ang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: T ext-to-video diffusion models with an expert transformer . arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Y ang Y e, Shenghai Yuan, Liuhan Chen, et al. Open-sora plan: Open-source large video generation model. arXiv preprint arXiv:2412.00131 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Y ang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Y ang Y ou. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404 , 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Wan: Open and Advanced Large-Scale Video Generative Models
T eam Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Y ang, et al. Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jian- wei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models. arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, T engfei Wang, and Chunchao Guo. Worldplay: T owards long-term geometric consistency for real-time interactive world modeling. arXiv preprint arXiv:2512.14614 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Philip J. Ball, Jakob Bauer , Frank Belletti, Bethanie Brownfield, Ariel Ephrat, Shlomi Fruchter , Agrim Gupta, Kris- tian Holsheimer , Aleksander Holynski, Jiri Hron, Christos Kaplanis, Marjorie Limont, Matt McGill, Y anko Oliveira, Jack Parker-Holder , Frank Perbet, Guy Scully , Jeremy Shar , Stephen Spencer , Omer T ov , Ruben Villegas, Emma Wang, Jessi...
2025
-
[10]
Hunyuan-gamecraft-2: Instruction-following interactive game world model
Junshu T ang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Y ang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, and Qinglin Lu. Hunyuan-gamecraft-2: Instruction-following interactive game world model. arXiv preprint arXiv:2511.23429, 2025
-
[11]
Yume-1.5: A text-controlled interactive world generation model
Xiaofeng Mao, Zhen Li, Chuanhao Li, Xiaojie Xu, Kaining Ying, T ong He, Jiangmiao Pang, Yu Qiao, and Kaipeng Zhang. Yume-1.5: A text-controlled interactive world generation model. arXiv preprint arXiv:2512.22096 , 2025
-
[12]
Vidarc: Embodied video diffusion model for closed-loop control
Y ao Feng, Chendong Xiang, Xinyi Mao, Hengkai T an, Zuyue Zhang, Shuhe Huang, Kaiwen Zheng, Haitian Liu, Hang Su, and Jun Zhu. Vidarc: Embodied video diffusion model for closed-loop control. arXiv preprint arXiv:2512.17661, 2025
-
[13]
Live Avatar: Streaming Real-time Audio-Driven Avatar Generation with Infinite Length
Yubo Huang, Hailong Guo, Fangtai Wu, Shifeng Zhang, Shijie Huang, Qijun Gan, Lin Liu, Sirui Zhao, Enhong Chen, Jiaming Liu, et al. Live avatar: Streaming real-time audio-driven avatar generation with infinite length. arXiv preprint arXiv:2512.04677, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Streamavatar: Streaming diffusion models for real-time interactive human avatars
Zhiyao Sun, Ziqiao Peng, Yifeng Ma, Yi Chen, Zhengguang Zhou, Zixiang Zhou, Guozhen Zhang, Y ouliang Zhang, Yuan Zhou, Qinglin Lu, et al. Streamavatar: Streaming diffusion models for real-time interactive human avatars. arXiv preprint arXiv:2512.22065 , 2025. 11 minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
-
[15]
Relic: Interactive video world model with long-horizon memory
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Y ang Zhou, Sai Bi, Y annick Hold-Geoffroy , Mike Roberts, Matthew Fisher , Eli Shechtman, et al. Relic: Interactive video world model with long-horizon memory . arXiv preprint arXiv:2512.04040, 2025
-
[16]
Y an: Foundational interactive video generation
Deheng Y e, Fangyun Zhou, Jiacheng Lv , Jianqi Ma, Jun Zhang, Junyan Lv , Junyou Li, Minwen Deng, Mingyu Y ang, Qiang Fu, et al. Y an: Foundational interactive video generation. arXiv preprint arXiv:2508.08601 , 2025
-
[17]
Pan: A world model for general, interactable, and long-horizon world simulation
Jiannan Xiang, Yi Gu, Zihan Liu, Zeyu Feng, Qiyue Gao, Yiyan Hu, Benhao Huang, Guangyi Liu, Yichi Y ang, Kun Zhou, et al. Pan: A world model for general, interactable, and long-horizon world simulation. arXiv preprint arXiv:2511.09057, 2025
-
[18]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Y angyang Ren, et al. Matrix-game 2.0: An open-source real-time and streaming interactive world model. arXiv preprint arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Motion- stream: Real-time video generation with interactive motion controls
Joonghyuk Shin, Zhengqi Li, Richard Zhang, Jun-Y an Zhu, Jaesik Park, Eli Shechtman, and Xun Huang. Motion- stream: Real-time video generation with interactive motion controls. arXiv preprint arXiv:2511.01266 , 2025
-
[20]
From slow bidirectional to fast autoregressive video diffusion models
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Freeman, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion models. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025
2025
-
[21]
Diffusion adversarial post-training for one-step video generation
Shanchuan Lin, Xin Xia, Yuxi Ren, Ceyuan Y ang, Xuefeng Xiao, and Lu Jiang. Diffusion adversarial post-training for one-step video generation. arXiv preprint arXiv:2501.08316 , 2025
-
[22]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion. arXiv preprint arXiv:2506.08009 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Hongzhou Zhu, Min Zhao, Guande He, Hang Su, Chongxuan Li, and Jun Zhu. Causal forcing: Autoregressive diffu- sion distillation done right for high-quality real-time interactive video generation. arXiv preprint arXiv:2602.02214, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Min Zhao, Hongzhou Zhu, Kaiwen Zheng, Zihan Zhou, Bokai Y an, Xinyuan Li, Xiao Y ang, Chongxuan Li, and Jun Zhu. Causal forcing++: Scalable few-step autoregressive diffusion distillation for real-time interactive video generation. arXiv preprint arXiv:2605.15141 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
T owards one-step causal video generation via adversarial self-distillation
Y ongqi Y ang, Huayang Huang, Xu Peng, Xiaobin Hu, Donghao Luo, Jiangning Zhang, Chengjie Wang, and Yu Wu. T owards one-step causal video generation via adversarial self-distillation. arXiv preprint arXiv:2511.01419 , 2025
-
[26]
Cameras as relative positional encoding
Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Cameras as relative positional encoding. In D. Belgrave, C. Zhang, H. Lin, R. Pascanu, P. Koniusz, M. Ghassemi, and N. Chen, editors, Advances in Neural Information Processing Systems , volume 38, pages 15984–16009. Curran Associates, Inc., 2025
2025
-
[27]
MAGI-1: Autoregressive Video Generation at Scale
Hansi T eng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu T ang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale. arXiv preprint arXiv:2505.13211 , 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Prolificdreamer: High- fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High- fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information process- ing systems, 36:8406–8441, 2023
2023
-
[29]
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models. Advances in Neural Information Processing Systems, 36:76525–76546, 2023
2023
-
[30]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and T aesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 6613–6623, 2024
2024
-
[31]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser , Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller , Harry Saini, Y am Levi, Dominik Lorenz, Axel Sauer , Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. In Forty-first international conference on machine learning , 2024
2024
-
[32]
Score-Based Generative Modeling through Stochastic Differential Equations
Y ang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar , Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. arXiv preprint arXiv:2011.13456 , 2020. 12 minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[33]
Consistency models
Y ang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever . Consistency models. 2023
2023
-
[34]
Spatialvid: A large-scale video dataset with spatial annotations
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Y outian Lin, Jian Gao, Lin-Zhuo Chen, Y ajie Bao, Yi Zhang, Chang Zeng, Y anxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations. arXiv preprint arXiv:2509.09676, 2025
-
[35]
Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision
Lu Ling, Yichen Sheng, Zhi T u, Wentian Zhao, Cheng Xin, Kun Wan, Lantao Yu, Qianyu Guo, Zixun Yu, Y awen Lu, et al. Dl3dv-10k: A large-scale scene dataset for deep learning-based 3d vision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 22160–22169, 2024
2024
-
[36]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhenheng Y ang, Zhijie Chen, Xiang Li, Jian Y ang, and Ying T ai. Openvid-1m: A large-scale high-quality dataset for text-to-video generation. arXiv preprint arXiv:2407.02371 , 2024. 13
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.