Archon: A Unified Multimodal Model for Holistic Digital Human Generation
Pith reviewed 2026-06-29 08:01 UTC · model grok-4.3
The pith
Archon pretrains one autoregressive model on seven modalities and 72 tasks to generate digital humans holistically.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
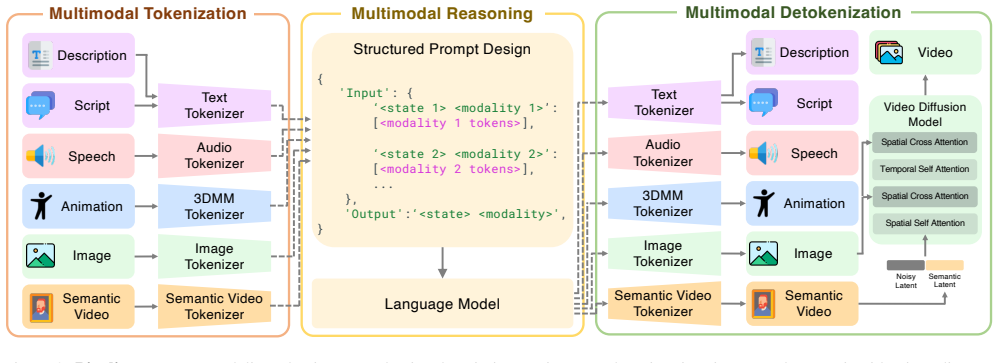
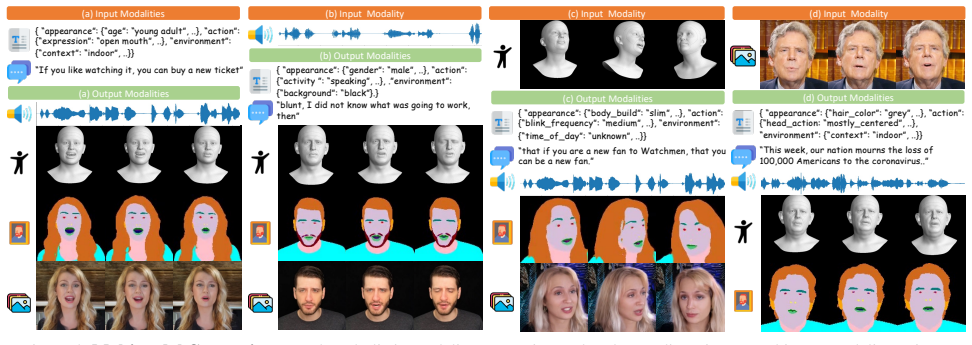
Archon unifies seven modalities with modality-specific tokenizers and a native autoregressive unified multimodal model pretrained on synchronized modalities and 72 diverse tasks to model holistic joint distributions. Memory-efficient semantic video reparameterization achieves 4x token reduction while preserving fine-grained dynamics, coupled with a semantic-driven video diffusion decoder. A Thinking in Modality strategy decomposes ambiguous cross-modal tasks into stepwise thinking in an alternative chain of modality, progressively enhancing fidelity and controllability. Experiments demonstrate superior or comparable performance across diverse digital human generation tasks.
What carries the argument
Native autoregressive unified multimodal model with modality-specific tokenizers, pretrained on synchronized data and 72 tasks, plus semantic video reparameterization and Thinking in Modality chain.
If this is right
- Holistic avatar generation becomes possible in one forward pass without switching between separate models for text, audio, motion, or video.
- High-fidelity talking videos can be processed autoregressively with only one-quarter the tokens while retaining dynamics via the diffusion decoder.
- Cross-modal tasks gain controllability by routing through an explicit chain of alternative modalities rather than direct ambiguous mapping.
- A single pretrained checkpoint suffices for the full range of 72 tasks instead of requiring per-task retraining or architectural variants.
Where Pith is reading between the lines
- If the joint-distribution claim holds, deployment pipelines for virtual humans could collapse from many specialized models to one, simplifying maintenance and inference hardware requirements.
- The modality-thinking decomposition suggests a general pattern for other ambiguous multimodal problems where direct conditioning fails but sequential rephrasing succeeds.
- Extending the same pretraining recipe to non-human subjects such as animals or objects would test whether the seven-modality unification is human-specific or broadly applicable.
- Real-time interactive use cases would require measuring whether the autoregressive nature plus reparameterization still supports low-latency responses.
Load-bearing premise
Pretraining a single autoregressive model on synchronized multimodal data and 72 tasks is sufficient to capture the joint distribution without modality-specific fine-tuning or architectural compromises that degrade any individual task.
What would settle it
A controlled comparison in which a task-specific model trained only on one digital human generation task produces measurably higher fidelity outputs than the unified Archon model on that same task.
Figures




read the original abstract
Digital humans are fundamental to immersive interaction, yet creating a unified model for holistic modalities, including text, audio, motion, and visual content, remains an open challenge. In this paper, we present Archon, a fully pretrained, human-centric unified multimodal model for holistic avatar generation. Archon unifies seven modalities with modality-specific tokenizers, and a native autoregressive unified multimodal model pretrained on synchronized modalities and 72 diverse tasks to model holistic joint distributions. To address the token explosion challenge in high-fidelity talking videos, we introduce a memory-efficient semantic video reparameterization, achieving 4x token reduction while preserving fine-grained dynamics, coupled with a semantic-driven video diffusion decoder. We further propose a "Thinking in Modality" that decomposes ambiguous cross-modal tasks into stepwise thinking in an alternative chain of modality, progressively enhancing fidelity and controllability. Extensive experiments demonstrate that Archon achieves superior or comparable performance across diverse digital human generation tasks, validating the effectiveness of our unified framework. Project page: https://zju3dv.github.io/archon/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents Archon, a fully pretrained autoregressive unified multimodal model for holistic digital human generation. It unifies seven modalities via modality-specific tokenizers, pretrains on synchronized multimodal data across 72 tasks to model joint distributions, introduces semantic video reparameterization for 4x token reduction with a diffusion decoder, and proposes 'Thinking in Modality' for stepwise cross-modal decomposition. The central claim is that this yields superior or comparable performance on diverse digital human tasks.
Significance. If the empirical claims hold with rigorous validation, the work could be significant for demonstrating that a single autoregressive model can capture holistic joint distributions across text/audio/motion/visual modalities without modality-specific fine-tuning. The token-reduction technique and cross-modal thinking strategy address practical challenges in high-fidelity generation. However, the provided manuscript contains only the abstract with no methods, results, ablations, or statistics, so significance cannot be assessed.
major comments (2)
- [Abstract] Abstract: The central performance claim ('achieves superior or comparable performance across diverse digital human generation tasks') is stated without any quantitative results, tables, figures, training details, or statistical tests. This prevents verification of whether gains are supported by data or affected by task selection, directly undermining evaluation of the unified pretraining assumption.
- [Abstract] Abstract: No description is given of the 72 tasks, data composition, synchronization method, or evaluation benchmarks. Without these, it is impossible to assess whether the autoregressive model captures the joint distribution without architectural compromises that degrade individual modalities.
Simulated Author's Rebuttal
We thank the referee for the comments. We agree that the current abstract is high-level and lacks the quantitative support and task details needed for full evaluation. We will revise the abstract to incorporate key results and brief descriptions while maintaining conciseness; an expanded manuscript with full methods, tables, and ablations will be prepared for resubmission.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim ('achieves superior or comparable performance across diverse digital human generation tasks') is stated without any quantitative results, tables, figures, training details, or statistical tests. This prevents verification of whether gains are supported by data or affected by task selection, directly undermining evaluation of the unified pretraining assumption.
Authors: We agree that the abstract would be strengthened by including quantitative evidence. In the revision we will add 1-2 specific metrics (e.g., percentage improvements on representative tasks) drawn from our experiments to substantiate the claim without exceeding abstract length limits. revision: yes
-
Referee: [Abstract] Abstract: No description is given of the 72 tasks, data composition, synchronization method, or evaluation benchmarks. Without these, it is impossible to assess whether the autoregressive model captures the joint distribution without architectural compromises that degrade individual modalities.
Authors: We acknowledge the absence of these specifics in the abstract. We will add a concise sentence summarizing task categories, data sources, and synchronization approach, while directing readers to the methods section for complete details. Full task lists and benchmark descriptions will appear in the expanded manuscript. revision: partial
Circularity Check
No significant circularity detected
full rationale
The provided abstract and described structure contain no derivation chain, equations, fitted parameters presented as predictions, or self-citations that reduce claims to inputs by construction. The central claim rests on empirical experiments across tasks, which are independent of any definitional or self-referential loop under the enumerated patterns. This is the standard case for an empirical multimodal modeling paper with no load-bearing mathematical reductions.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Alternating gradi- ent descent and mixture-of-experts for integrated multimodal perception.Advances in Neural Information Processing Sys- tems, 36:79142–79154, 2023
Hassan Akbari, Dan Kondratyuk, Yin Cui, Rachel Hornung, Huisheng Wang, and Hartwig Adam. Alternating gradi- ent descent and mixture-of-experts for integrated multimodal perception.Advances in Neural Information Processing Sys- tems, 36:79142–79154, 2023. 5
2023
-
[2]
Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
Jean-Baptiste Alayrac, Jeff Donahue, Pauline Luc, Antoine Miech, Iain Barr, Yana Hasson, Karel Lenc, Arthur Men- sch, Katherine Millican, Malcolm Reynolds, et al. Flamingo: a visual language model for few-shot learning.Advances in neural information processing systems, 35:23716–23736,
-
[3]
Rohan Anil, Andrew M Dai, Orhan Firat, Melvin John- son, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. Palm 2 technical report.arXiv preprint arXiv:2305.10403, 2023. 2, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhao- hai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Jun- yang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shix...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Location-relative attention mechanisms for robust long-form speech synthesis
Eric Battenberg, RJ Skerry-Ryan, Soroosh Mariooryad, Daisy Stanton, David Kao, Matt Shannon, and Tom Bagby. Location-relative attention mechanisms for robust long-form speech synthesis. InICASSP 2020-2020 IEEE Interna- tional Conference on Acoustics, Speech and Signal Process- ing (ICASSP), pages 6194–6198. IEEE, 2020. 7
2020
-
[6]
Audiolm: a language modeling approach to audio genera- tion.IEEE/ACM transactions on audio, speech, and lan- guage processing, 31:2523–2533, 2023
Zalán Borsos, Raphaël Marinier, Damien Vincent, Eugene Kharitonov, Olivier Pietquin, Matt Sharifi, Dominik Roblek, Olivier Teboul, David Grangier, Marco Tagliasacchi, et al. Audiolm: a language modeling approach to audio genera- tion.IEEE/ACM transactions on audio, speech, and lan- guage processing, 31:2523–2533, 2023. 3
2023
-
[7]
Bge m3-embedding: Multi- lingual, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation, 2023
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi- lingual, multi-functionality, multi-granularity text embed- dings through self-knowledge distillation, 2023. 19
2023
-
[8]
Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions
Zhiyuan Chen, Jiajiong Cao, Zhiquan Chen, Yuming Li, and Chenguang Ma. Echomimic: Lifelike audio-driven portrait animations through editable landmark conditions. InPro- ceedings of the AAAI Conference on Artificial Intelligence, pages 2403–2410, 2025. 2, 6, 7, 8
2025
-
[9]
Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240): 1–113, 2023
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of Machine Learning Research, 24(240): 1–113, 2023. 2, 5
2023
-
[10]
Out of time: auto- mated lip sync in the wild
Joon Son Chung and Andrew Zisserman. Out of time: auto- mated lip sync in the wild. InAsian conference on computer vision, pages 251–263. Springer, 2016. 6, 7
2016
-
[11]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blis- tein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025. 5, 6, 15
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
Hallo3: Highly dynamic and realistic portrait image an- imation with diffusion transformer networks.arXiv e-prints, pages arXiv–2412, 2024
Jiahao Cui, Hui Li, Yun Zhan, Hanlin Shang, Kaihui Cheng, Yuqi Ma, Shan Mu, Hang Zhou, Jingdong Wang, and Siyu Zhu. Hallo3: Highly dynamic and realistic portrait image an- imation with diffusion transformer networks.arXiv e-prints, pages arXiv–2412, 2024. 2, 6, 7, 8
2024
-
[13]
Emoca: Emotion driven monocular face capture and animation
Radek Dan ˇeˇcek, Michael J Black, and Timo Bolkart. Emoca: Emotion driven monocular face capture and animation. In Proceedings of the IEEE/CVF Conference on Computer Vi- sion and Pattern Recognition, pages 20311–20322, 2022. 2, 17
2022
-
[14]
Gemini 3
Google Deepmind. Gemini 3. https://deepmind.google/models/gemini/, 2025. 19
2025
-
[15]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
PaLM-E: An Embodied Multimodal Language Model
Danny Driess, Fei Xia, Mehdi SM Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, et al. Palm- e: An embodied multimodal language model.arXiv preprint arXiv:2303.03378, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
3d morphable face models—past, present, and future.ACM Transactions on Graphics (ToG), 39(5):1–38, 2020
Bernhard Egger, William AP Smith, Ayush Tewari, Stefanie Wuhrer, Michael Zollhoefer, Thabo Beeler, Florian Bernard, Timo Bolkart, Adam Kortylewski, Sami Romdhani, et al. 3d morphable face models—past, present, and future.ACM Transactions on Graphics (ToG), 39(5):1–38, 2020. 17
2020
-
[18]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 3, 13
2021
-
[19]
Learning an animatable detailed 3d face model from in-the- wild images.ACM Transactions on Graphics (ToG), 40(4): 1–13, 2021
Yao Feng, Haiwen Feng, Michael J Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the- wild images.ACM Transactions on Graphics (ToG), 40(4): 1–13, 2021. 2
2021
-
[20]
Face2speech: Towards multi- speaker text-to-speech synthesis using an embedding vector predicted from a face image
Shunsuke Goto, Kotaro Onishi, Yuki Saito, Kentaro Tachibana, and Koichiro Mori. Face2speech: Towards multi- speaker text-to-speech synthesis using an embedding vector predicted from a face image. InInterspeech, pages 1321– 1325, 2020. 2
2020
-
[21]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Ab- hinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, 9 et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Vector quantization.IEEE Assp Magazine, 1 (2):4–29, 1984
Robert Gray. Vector quantization.IEEE Assp Magazine, 1 (2):4–29, 1984. 14
1984
-
[23]
Photorealistic video generation with diffusion models
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and José Lezama. Photorealistic video generation with diffusion models. In European Conference on Computer Vision, pages 393–411. Springer, 2024. 5
2024
-
[24]
Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilib- rium.Advances in neural information processing systems, 30, 2017. 7
2017
-
[25]
Minki Kang, Wooseok Han, and Eunho Yang. Face- stylespeech: Improved face-to-voice latent mapping for nat- ural zero-shot speech synthesis from a face image.arXiv preprint arXiv:2311.05844, 2023. 2
-
[26]
Sapiens: Foundation for human vision mod- els
Rawal Khirodkar, Timur Bagautdinov, Julieta Martinez, Su Zhaoen, Austin James, Peter Selednik, Stuart Anderson, and Shunsuke Saito. Sapiens: Foundation for human vision mod- els. InEuropean Conference on Computer Vision, pages 206–228. Springer, 2024. 3
2024
-
[27]
A method for stochastic optimization
Diederik Kinga, Jimmy Ba Adam, et al. A method for stochastic optimization. InInternational conference on learning representations (ICLR). California;, 2015. 6
2015
-
[28]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, José Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vigh- nesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video gen- eration.arXiv preprint arXiv:2312.14125, 2023. 2, 3, 4
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[29]
Imag- inary voice: Face-styled diffusion model for text-to-speech
Jiyoung Lee, Joon Son Chung, and Soo-Whan Chung. Imag- inary voice: Face-styled diffusion model for text-to-speech. InICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2023. 2, 7, 8
2023
-
[30]
Learning a model of facial shape and expression from 4d scans.ACM Trans
Tianye Li, Timo Bolkart, Michael J Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4d scans.ACM Trans. Graph., 36(6):194–1, 2017. 4
2017
-
[31]
Omnihuman-1: Re- thinking the scaling-up of one-stage conditioned human an- imation models
Gaojie Lin, Jianwen Jiang, Jiaqi Yang, Zerong Zheng, Chao Liang, Yuan Zhang, and Jingtuo Liu. Omnihuman-1: Re- thinking the scaling-up of one-stage conditioned human an- imation models. InProceedings of the IEEE/CVF Interna- tional Conference on Computer Vision, pages 13847–13858,
-
[32]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Hao Yang, et al. Deepseek-vl: towards real-world vision- language understanding.arXiv preprint arXiv:2403.05525,
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
World-consistent video-to-video synthesis
Arun Mallya, Ting-Chun Wang, Karan Sapra, and Ming-Yu Liu. World-consistent video-to-video synthesis. InEuropean Conference on Computer Vision, pages 359–378. Springer,
-
[34]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193, 2023. 4, 6, 17
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
Dpe: Dis- entanglement of pose and expression for general video por- trait editing
Youxin Pang, Yong Zhang, Weize Quan, Yanbo Fan, Xi- aodong Cun, Ying Shan, and Dong-ming Yan. Dpe: Dis- entanglement of pose and expression for general video por- trait editing. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 427–436,
-
[36]
Kosmos-2: Grounding Multimodal Large Language Models to the World
Zhiliang Peng, Wenhui Wang, Li Dong, Yaru Hao, Shaohan Huang, Shuming Ma, and Furu Wei. Kosmos-2: Ground- ing multimodal large language models to the world.arXiv preprint arXiv:2306.14824, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[37]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInterna- tional conference on machine learning, pages 28492–28518. PMLR, 2023. 6, 17
2023
-
[38]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of Machine Learn- ing Research, 21(140):1–67, 2020. 3
2020
-
[39]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 4
2020
-
[40]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022. 5
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[41]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. InInternational Conference on Machine Learning, pages 4596–4604. PMLR,
-
[42]
X-vectors: Robust dnn em- beddings for speaker recognition
David Snyder, Daniel Garcia-Romero, Gregory Sell, Daniel Povey, and Sanjeev Khudanpur. X-vectors: Robust dnn em- beddings for speaker recognition. In2018 IEEE interna- tional conference on acoustics, speech and signal processing (ICASSP), pages 5329–5333. IEEE, 2018. 7
2018
-
[43]
Shuai Tan, Bill Gong, Bin Ji, and Ye Pan. Fixtalk: Taming identity leakage for high-quality talking head generation in extreme cases.arXiv preprint arXiv:2507.01390, 2025. 2
-
[44]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean- Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[45]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Thomas Unterthiner, Sjoerd Van Steenkiste, Karol Kurach, Raphael Marinier, Marcin Michalski, and Sylvain Gelly. To- wards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717, 2018. 7
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[46]
Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 4
2017
-
[47]
Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 14, 17 10
2017
-
[48]
Generalized end-to-end loss for speaker verification
Li Wan, Quan Wang, Alan Papir, and Ignacio Lopez Moreno. Generalized end-to-end loss for speaker verification. In2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4879–4883. IEEE, 2018. 7
2018
-
[49]
Visionllm: Large language model is also an open- ended decoder for vision-centric tasks.Advances in Neural Information Processing Systems, 36:61501–61513, 2023
Wenhai Wang, Zhe Chen, Xiaokang Chen, Jiannan Wu, Xizhou Zhu, Gang Zeng, Ping Luo, Tong Lu, Jie Zhou, Yu Qiao, et al. Visionllm: Large language model is also an open- ended decoder for vision-centric tasks.Advances in Neural Information Processing Systems, 36:61501–61513, 2023. 4
2023
-
[50]
Prompthmr: Promptable human mesh recovery
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael J Black, and Muhammed Kocabas. Prompthmr: Promptable human mesh recovery. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 1148–1159, 2025. 3
2025
-
[51]
Mocha: Towards movie-grade talking character synthesis.arXiv preprint arXiv:2503.23307, 2025
Cong Wei, Bo Sun, Haoyu Ma, Ji Hou, Felix Juefei-Xu, Zecheng He, Xiaoliang Dai, Luxin Zhang, Kunpeng Li, Tingbo Hou, et al. Mocha: Towards movie-grade talking character synthesis.arXiv preprint arXiv:2503.23307, 2025. 2
-
[52]
Aniportrait: Audio-driven synthesis of photorealistic portrait animation
Huawei Wei, Zejun Yang, and Zhisheng Wang. Aniportrait: Audio-driven synthesis of photorealistic portrait animation. arXiv preprint arXiv:2403.17694, 2024. 2, 7, 8
-
[53]
Fake it till you make it: face analysis in the wild using synthetic data alone
Erroll Wood, Tadas Baltrušaitis, Charlie Hewitt, Sebastian Dziadzio, Thomas J Cashman, and Jamie Shotton. Fake it till you make it: face analysis in the wild using synthetic data alone. InProceedings of the IEEE/CVF international conference on computer vision, pages 3681–3691, 2021. 6
2021
-
[54]
Q-Align: Teaching LMMs for Visual Scoring via Discrete Text-Defined Levels
Haoning Wu, Zicheng Zhang, Weixia Zhang, Chaofeng Chen, Liang Liao, Chunyi Li, Yixuan Gao, Annan Wang, Erli Zhang, Wenxiu Sun, et al. Q-align: Teaching lmms for visual scoring via discrete text-defined levels.arXiv preprint arXiv:2312.17090, 2023. 7
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[55]
Next-gpt: Any-to-any multimodal llm
Shengqiong Wu, Hao Fei, Leigang Qu, Wei Ji, and Tat-Seng Chua. Next-gpt: Any-to-any multimodal llm. InForty-first International Conference on Machine Learning, 2024. 2, 3, 18, 19
2024
-
[56]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show- o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025. 2, 18
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, Yuanjun Lv, Yongqi Wang, Dake Guo, He Wang, Linhan Ma, Pei Zhang, Xinyu Zhang, Hongkun Hao, Zishan Guo, Baosong Yang, Bin Zhang, Ziyang Ma, Xipin Wei, Shuai Bai, Keqin Chen, Xuejing Liu, Peng Wang, Mingkun Yang, Dayiheng Liu, Xingzhang Ren, Bo ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[58]
Vasa-1: Lifelike audio-driven talking faces generated in real time.Advances in Neural Information Pro- cessing Systems, 37:660–684, 2024
Sicheng Xu, Guojun Chen, Yu-Xiao Guo, Jiaolong Yang, Chong Li, Zhenyu Zang, Yizhong Zhang, Xin Tong, and Baining Guo. Vasa-1: Lifelike audio-driven talking faces generated in real time.Advances in Neural Information Pro- cessing Systems, 37:660–684, 2024. 2
2024
-
[59]
Emotional face-to-speech.arXiv preprint arXiv:2502.01046, 2025
Jiaxin Ye, Boyuan Cao, and Hongming Shan. Emotional face-to-speech.arXiv preprint arXiv:2502.01046, 2025. 2
-
[60]
Magvit: Masked generative video transformer
Lijun Yu, Yong Cheng, Kihyuk Sohn, José Lezama, Han Zhang, Huiwen Chang, Alexander G Hauptmann, Ming- Hsuan Yang, Yuan Hao, Irfan Essa, et al. Magvit: Masked generative video transformer. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10459–10469, 2023. 3
2023
-
[61]
Language model beats diffusion-tokenizer is key to visual generation
Lijun Yu, José Lezama, Nitesh Bharadwaj Gundavarapu, Luca Versari, Kihyuk Sohn, David Minnen, Yong Cheng, Agrim Gupta, Xiuye Gu, Alexander G Hauptmann, et al. Language model beats diffusion-tokenizer is key to visual generation. InICLR, 2024. 2, 3, 4, 12
2024
-
[62]
Soundstream: An end- to-end neural audio codec.IEEE/ACM Transactions on Au- dio, Speech, and Language Processing, 30:495–507, 2021
Neil Zeghidour, Alejandro Luebs, Ahmed Omran, Jan Skoglund, and Marco Tagliasacchi. Soundstream: An end- to-end neural audio codec.IEEE/ACM Transactions on Au- dio, Speech, and Language Processing, 30:495–507, 2021. 3, 4, 17
2021
-
[63]
Anygpt: Unified multimodal llm with dis- crete sequence modeling
Jun Zhan, Junqi Dai, Jiasheng Ye, Yunhua Zhou, Dong Zhang, Zhigeng Liu, Xin Zhang, Ruibin Yuan, Ge Zhang, Linyang Li, et al. Anygpt: Unified multimodal llm with dis- crete sequence modeling. InProceedings of the 62nd An- nual Meeting of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 9637–9662, 2024. 2, 3
2024
-
[64]
Speechgpt: Empow- ering large language models with intrinsic cross-modal con- versational abilities
Dong Zhang, Shimin Li, Xin Zhang, Jun Zhan, Pengyu Wang, Yaqian Zhou, and Xipeng Qiu. Speechgpt: Empow- ering large language models with intrinsic cross-modal con- versational abilities. InThe 2023 Conference on Empirical Methods in Natural Language Processing, 2023. 3
2023
-
[65]
Sadtalker: Learning realistic 3d motion coefficients for stylized audio- driven single image talking face animation
Wenxuan Zhang, Xiaodong Cun, Xuan Wang, Yong Zhang, Xi Shen, Yu Guo, Ying Shan, and Fei Wang. Sadtalker: Learning realistic 3d motion coefficients for stylized audio- driven single image talking face animation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8652–8661, 2023. 2
2023
-
[66]
Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset
Zhimeng Zhang, Lincheng Li, Yu Ding, and Changjie Fan. Flow-guided one-shot talking face generation with a high-resolution audio-visual dataset. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3661–3670, 2021. 6, 7, 8, 17, 19
2021
-
[67]
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
Chunting Zhou, Lili Yu, Arun Babu, Kushal Tirumala, Michihiro Yasunaga, Leonid Shamis, Jacob Kahn, Xuezhe Ma, Luke Zettlemoyer, and Omer Levy. Transfusion: Pre- dict the next token and diffuse images with one multi-modal model.arXiv preprint arXiv:2408.11039, 2024. 2
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[68]
Pose-controllable talking face generation by implicitly modularized audio-visual rep- resentation
Hang Zhou, Yasheng Sun, Wayne Wu, Chen Change Loy, Xiaogang Wang, and Ziwei Liu. Pose-controllable talking face generation by implicitly modularized audio-visual rep- resentation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4176–4186,
-
[69]
Celebv- hq: A large-scale video facial attributes dataset
Hao Zhu, Wayne Wu, Wentao Zhu, Liming Jiang, Siwei Tang, Li Zhang, Ziwei Liu, and Chen Change Loy. Celebv- hq: A large-scale video facial attributes dataset. InEuropean conference on computer vision, pages 650–667. Springer,
-
[70]
Thinking in Modality
6, 7, 8, 17 11 Supplementary Material This supplementary material provides additional imple- mentation details, experimental results and a brief discus- sion on ethics. In Sec. A, we claim that our work adheres to ethical guidelines. In Sec. C, we elaborate on the architec- tural designs and training protocols for our semantic and an- imation tokenizers, ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.