Calibrated Preference Learning: The Case of Label Ranking
Pith reviewed 2026-06-29 08:51 UTC · model grok-4.3
The pith
Calibration for label ranking is formalized as a hierarchy where full ranking calibration implies sub-ranking and top-k versions but not the reverse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
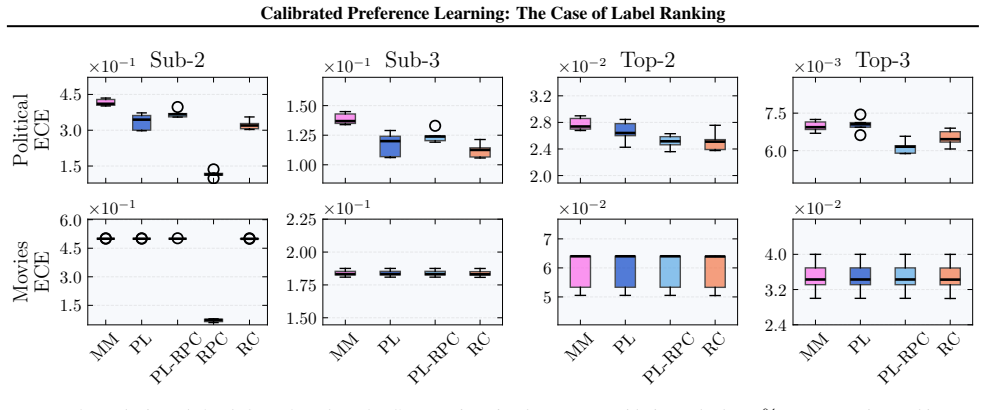
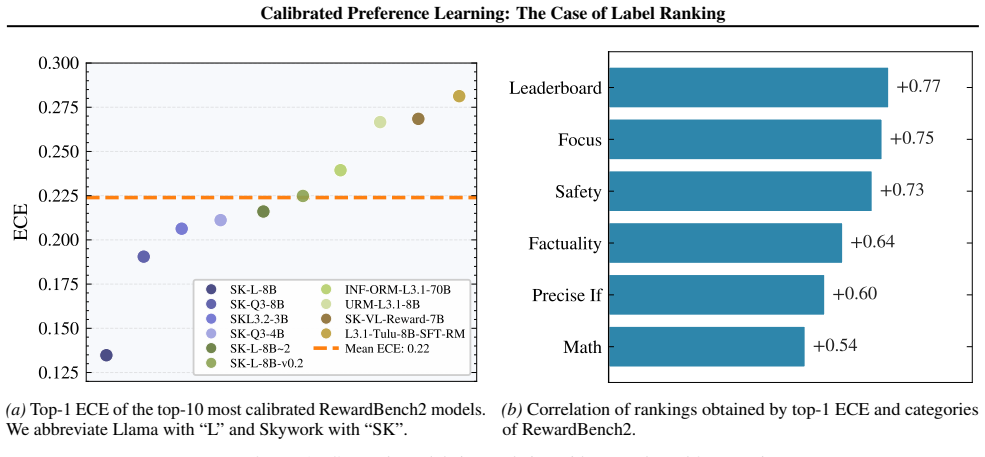
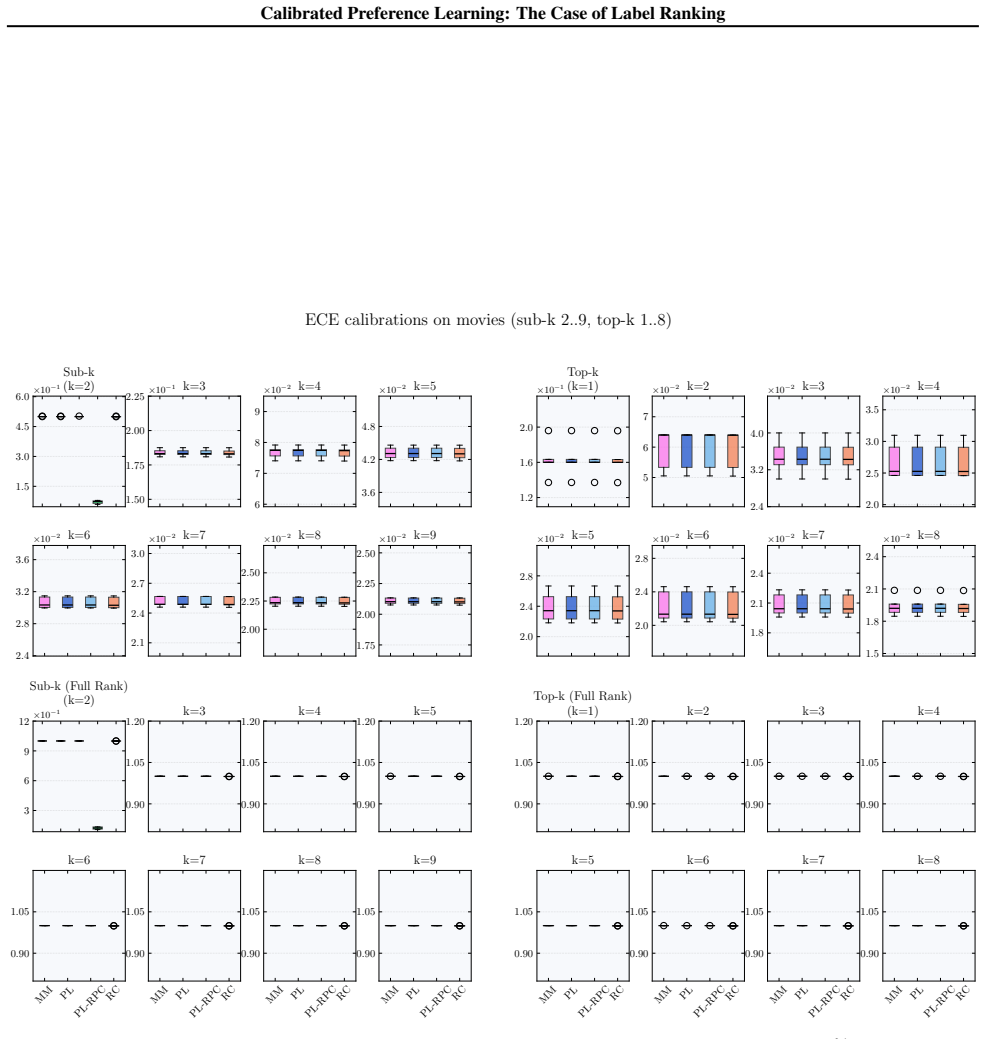
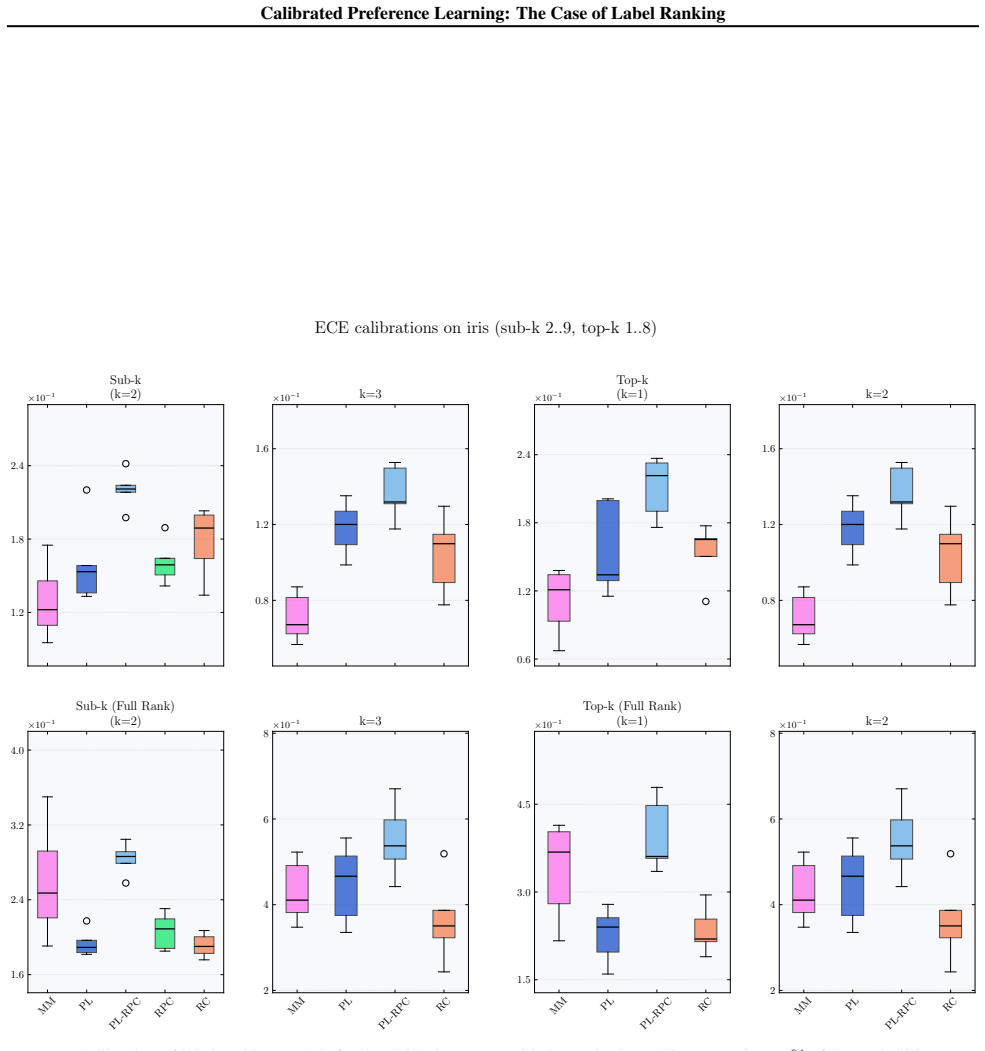
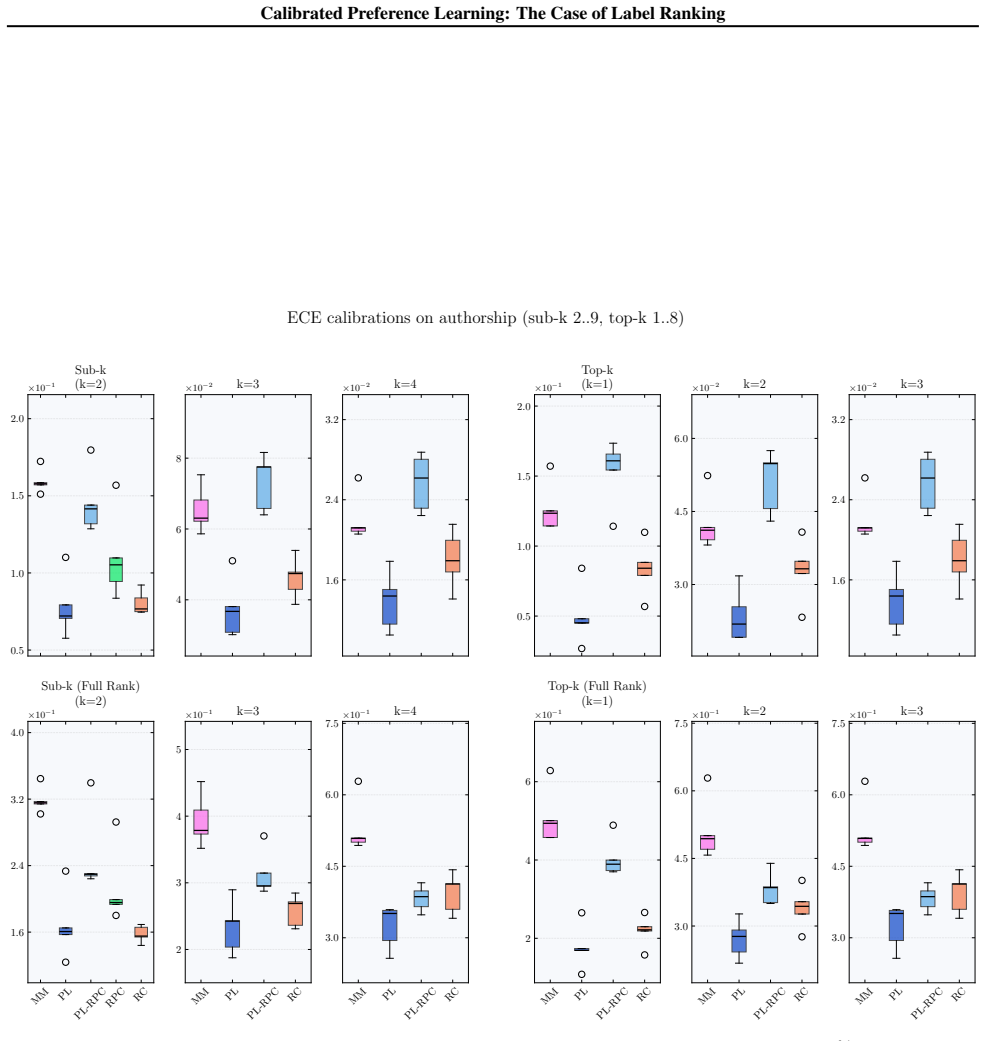
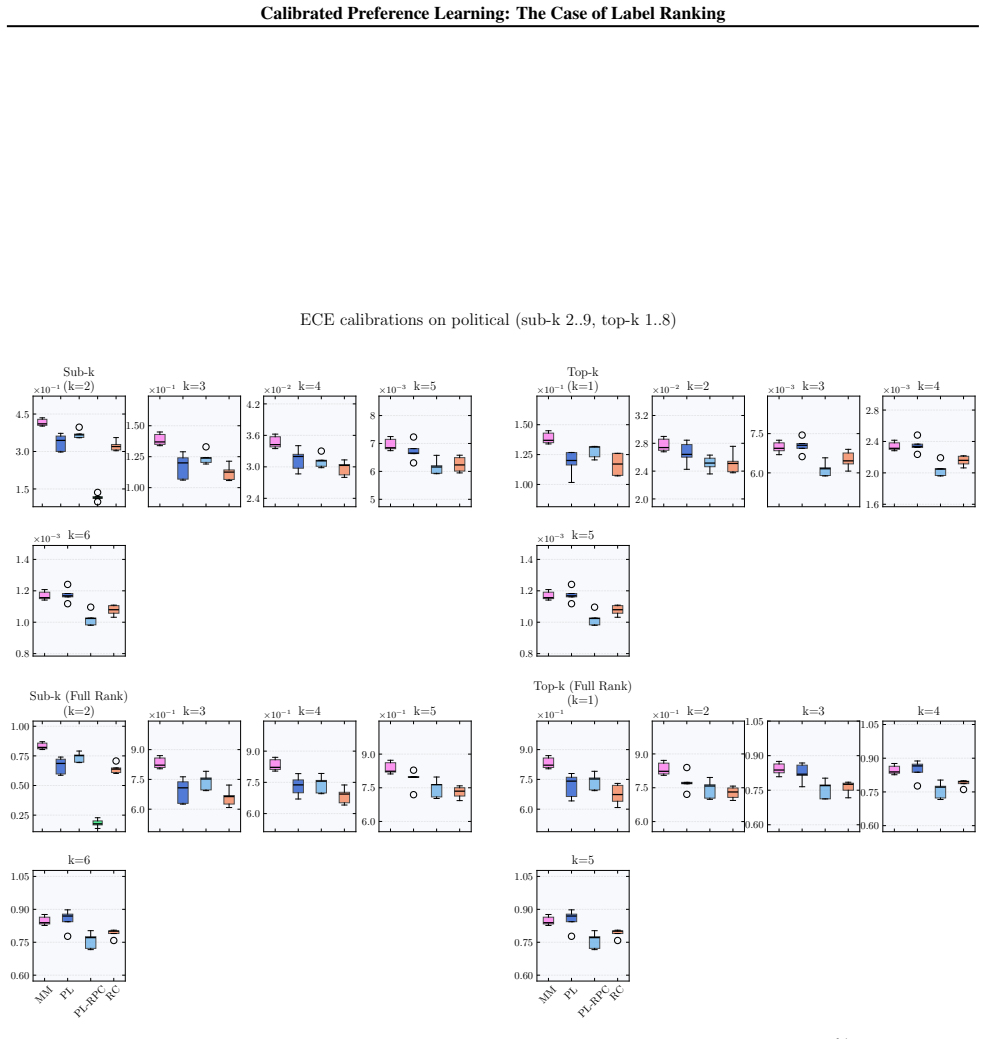
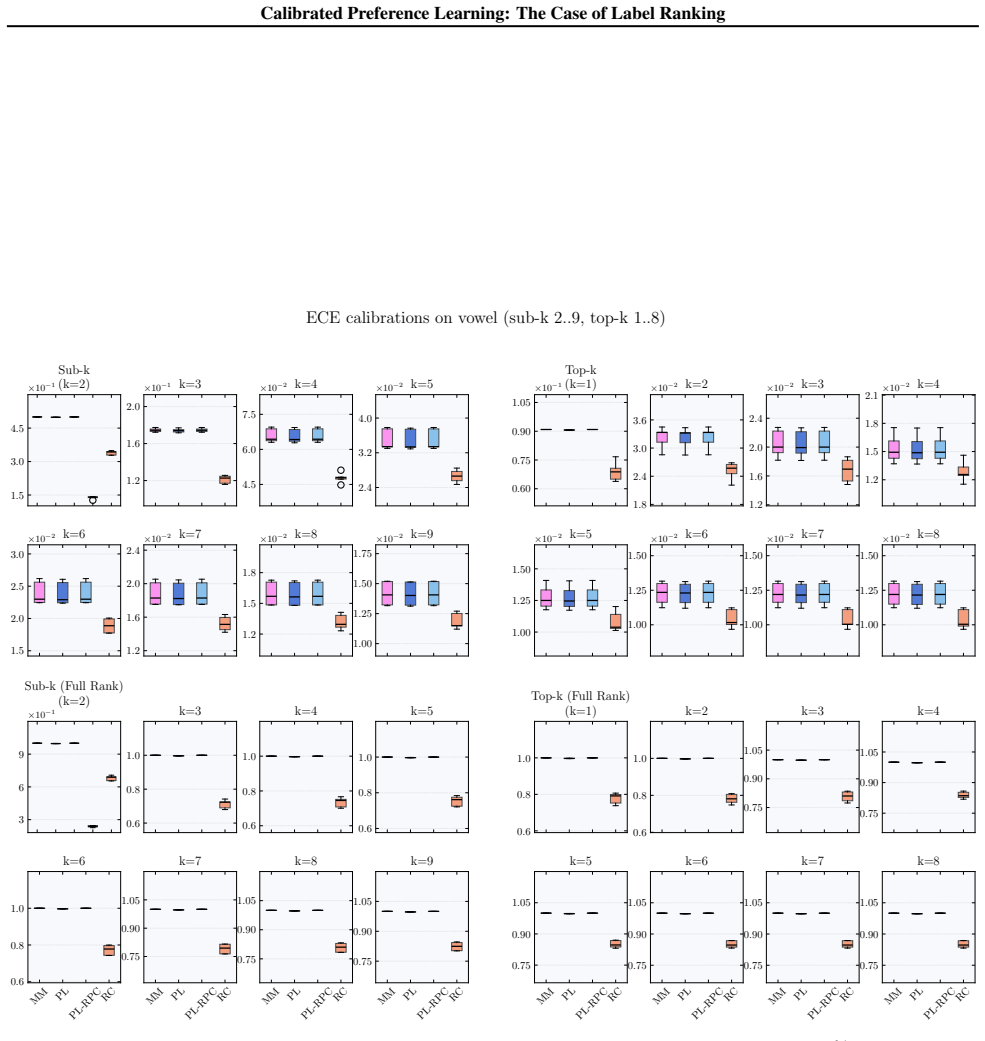
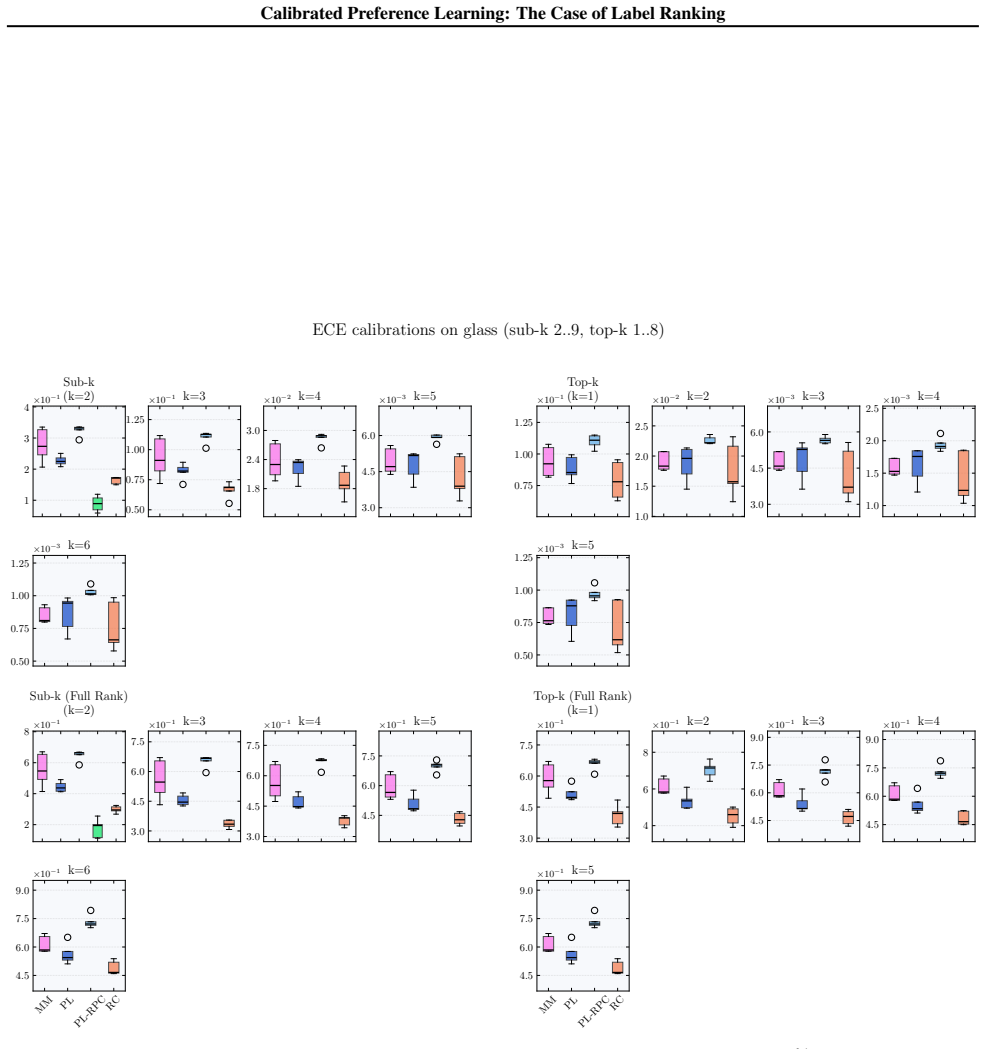
We formalize calibration for label ranking and develop a hierarchy of notions covering full rankings, sub-rankings, and top-k rankings. We prove that full-rank calibration implies the others but not conversely, and sub-ranking and top-k calibration are incomparable. Empirically, popular label ranking models are often poorly calibrated, with substantial differences between sub-ranking and top-k metrics. Applying the framework to RLHF reward models shows that calibration correlates strongly but not perfectly with benchmark accuracy.
What carries the argument
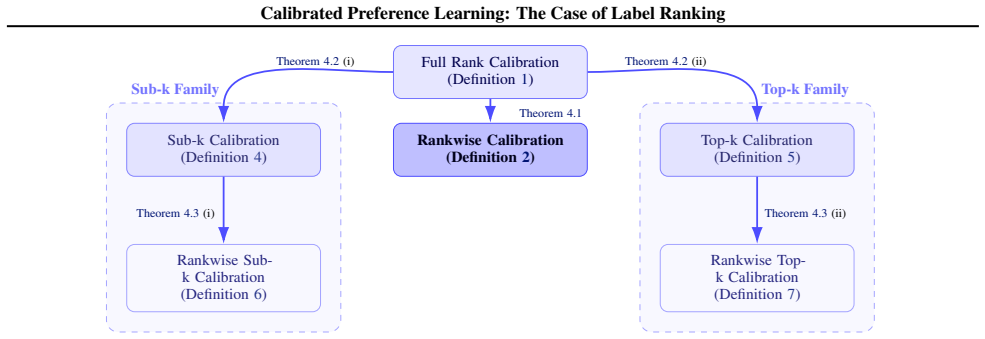
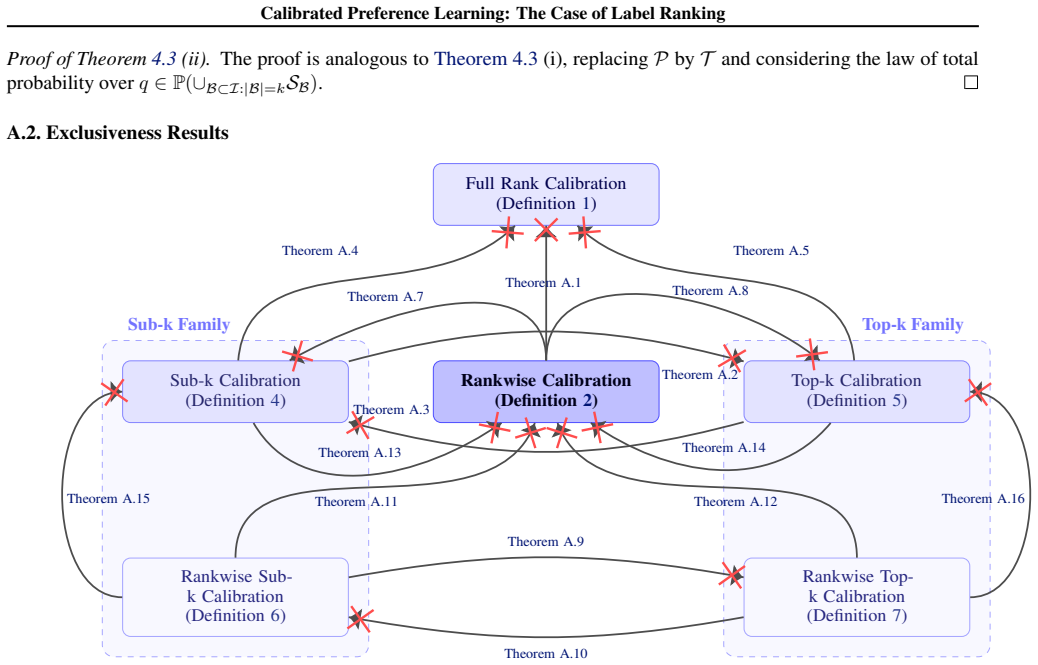
Hierarchy of calibration notions for distributions over rankings, with full-rank, sub-ranking, and top-k levels and proved implication relations.
If this is right
- Full-rank calibration is sufficient to guarantee both sub-ranking and top-k calibration.
- Sub-ranking calibration does not guarantee top-k calibration and vice versa.
- Common label ranking algorithms exhibit poor calibration under these definitions.
- In RLHF reward models, calibration provides information about quality that is distinct from top-1 accuracy.
- Miscalibration can differ in degree across the hierarchy levels for the same model.
Where Pith is reading between the lines
- Downstream tasks that rely on pairwise comparisons may still suffer from errors even when top-k calibration holds.
- Calibration correction techniques developed for classification could be adapted to ranking distributions.
- Evaluation benchmarks for preference learning might usefully add calibration checks at multiple hierarchy levels.
- Models trained only to maximize accuracy could be improved by adding explicit calibration objectives at the sub-ranking level.
Load-bearing premise
The defined calibration notions for full, sub, and top-k rankings correctly capture the structure that matters for reliable decisions based on predicted orderings.
What would settle it
A dataset or model where a predictor meets full-rank calibration yet produces miscalibrated pairwise probabilities or top-k selections on held-out data.
Figures





read the original abstract
Calibration, the alignment of predicted probabilities with true outcome frequencies, is essential for reliable decision-making. While extensively studied for classification and regression, calibration has not been formally addressed for probabilistic label ranking, where the goal is to predict a distribution over orderings of a label set. Naively treating rankings as classes ignores their structure and fails to capture important modalities such as pairwise and top-k predictions. We formalize calibration for label ranking and develop a hierarchy of notions covering full rankings, sub-rankings, and top-k rankings. We prove that full-rank calibration implies the others but not conversely, and sub-ranking and top-k calibration are incomparable. Empirically, we find popular label ranking models are often poorly calibrated, with substantial differences between sub-ranking and top-k metrics. Applying our framework to RLHF reward models, we find that calibration correlates strongly but not perfectly with benchmark accuracy, suggesting it captures a meaningful quality dimension beyond top-1 accuracy. These findings motivate future work on understanding the downstream effects of miscalibration and developing methods to correct it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to formalize calibration for probabilistic label ranking by developing a hierarchy of notions covering full rankings, sub-rankings, and top-k rankings. It proves that full-rank calibration implies the others but not conversely, and that sub-ranking and top-k calibration are incomparable. Empirically, popular label ranking models are often poorly calibrated with substantial differences between sub-ranking and top-k metrics; applying the framework to RLHF reward models shows calibration correlates strongly but not perfectly with benchmark accuracy.
Significance. If the formalization and proofs hold, the work supplies a structured hierarchy for assessing calibration in label ranking, addressing a gap beyond standard classification. The explicit proofs of the implication and incomparability results, together with the empirical demonstration of miscalibration in existing models and the partial correlation with accuracy in RLHF, constitute a meaningful contribution that could motivate downstream calibration methods for ranking tasks.
minor comments (1)
- The abstract asserts the existence of proofs and empirical results without supplying derivations, data details, or verification steps; expanding the abstract or adding a short methods overview would improve accessibility while preserving the high-level claim.
Simulated Author's Rebuttal
We thank the referee for the positive summary of our contribution and for recommending minor revision. No specific major comments appear in the report.
Circularity Check
No significant circularity
full rationale
The paper's core contribution consists of new formal definitions for calibration notions (full-rank, sub-ranking, top-k) in label ranking, followed by standard mathematical proofs establishing implication and incomparability relations via marginalization and counterexamples. These steps are self-contained constructions that do not reduce any claimed result to a fitted parameter, self-citation chain, or input by definition; the definitions are introduced explicitly to enable the stated hierarchy rather than presupposing it. Empirical sections evaluate existing models against the new metrics but do not feed back into the theoretical claims. No load-bearing self-citation or ansatz smuggling is present in the derivation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1016/j.fss.2024.108908. Alfaro, J. C., Aledo, J. A., and G ´amez, J. A. Learning decision trees for the partial label ranking problem.In- ternational Journal of Intelligent Systems, 36:890–918,
-
[2]
doi: 10.1002/int.22325. Alfaro, J. C., Aledo, J. A., and G´amez, J. A. Pairwise learn- ing for the partial label ranking problem.Pattern Recogni- tion, 140:109590, 2023a. doi: 10.1016/J.PATCOG.2023. 109590. Alfaro, J. C., Aledo, J. A., and G ´amez, J. A. Pairwise learning for the partial label ranking problem.Pattern Recognition, 140:109590, 2023b. doi: 1...
-
[3]
H¨ullermeier, E., F¨urnkranz, J., Cheng, W., and Brinker, K
doi: 10.1007/S10994-021-05946-3. H¨ullermeier, E., F¨urnkranz, J., Cheng, W., and Brinker, K. Label ranking by learning pairwise preferences.Artificial Intelligence, 172(16-17):1897–1916, 2008. doi: 10.1016/ J.ARTINT.2008.08.002. Hunter, D. R. Mm algorithms for generalized bradley-terry models.The annals of statistics, 32(1):384–406, 2004. J¨urgens, M., M...
-
[4]
Malik, S., Pyatkin, V ., Land, S., Morrison, J., Smith, N
doi: 10.1145/2783258.2788582. Malik, S., Pyatkin, V ., Land, S., Morrison, J., Smith, N. A., Hajishirzi, H., and Lambert, N. Rewardbench 2: Advanc- ing reward model evaluation.CoRR, abs/2506.01937,
-
[5]
RewardBench 2: Advancing Reward Model Evaluation
doi: 10.48550/ARXIV .2506.01937. Mallows, C. L. Non-null ranking models. i.Biometrika, 44 (1/2):114–130, 1957. McLean, I., Urken, A. B., and Hewitt, F.Classics of social choice. University of Michigan Press, 1995. Menon, A. K., Jiang, X., Vembu, S., Elkan, C., and Ohno- Machado, L. Predicting accurate probabilities with a ranking loss. InProceedings of th...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 1957
-
[6]
Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., and Manning, C
doi: 10.1007/978-3-031-78977-9\ 26. Tian, K., Mitchell, E., Zhou, A., Sharma, A., Rafailov, R., Yao, H., Finn, C., and Manning, C. D. Just ask for calibra- tion: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback. InProceedings of the Conference on Empirical Methods in Natural Language Processing (EML...
-
[7]
choosing someq∈P(S B)arbitrary but fixed, take someα∈[0,1]arbitrary but fixed,
-
[8]
choosinghto be full-rank calibrated, use anhthat is rankwise calibrated,
-
[9]
conditioning onh ||P(X) =q, condition onh ||P(X)[ρ] =α,
-
[10]
conditioning onh ||T (X) =q, condition onh ||T (X)[ρ] =α,
-
[11]
How conservative would you rate CDU/CSU?
replace each appearance ofq[ρ]byα. Theorem A.10.Assume that the number of itemsm≥3. Then it holds: ∀k < m:∃h∈ X →P(S I) :hrankwise top-k calibrated∧hnotrankwise sub-k calibrated . Proof of Theorem A.10.This proof is analogous to Theorem A.9, replacingPforT. Corollary A.11.Assume that the number of itemsm≥3. Then it holds: ∀k∈ {2, . . . , m−1} ∃h∈ X →P(S I...
2008
-
[12]
authorship
with learning rate10 −3 and no weight decay. On each dataset, we train for 50 epochs using a batch size of 64. RankClassifierRankClassifier is a multi-class classification model that outputs a probability distribution over all possible rankings SI. Naively training such a model is infeasible for large m, since the number of rankings grows factorially as m...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.