VLM-GLoc: Vision-Language Model Enhanced Monte Carlo Localization for Robust Semantic Global Localization in Cluttered Quasi-Static Environments
Pith reviewed 2026-06-29 06:46 UTC · model grok-4.3
The pith
Vision-language models improve Monte Carlo localization success to 70% in grocery stores and 74% in labs by supplying semantic observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VLM-GLoc achieves 70% and 74% global localization success respectively in a 3,500 sq. ft. grocery store and a 3,700 sq. ft. lab space by using vision-language models for semantic observations inside Monte Carlo localization, together with an inverse semantic proposal that seeds particles through text-to-map retrieval, and this substantially outperforms traditional geometry-only and domain-specific baselines.
What carries the argument
The inverse semantic proposal mechanism that seeds particles via text-to-map retrieval using VLM-derived features as the observation model.
If this is right
- Robots gain the ability to localize globally in long-tailed semantic environments without building separate vision modules for each domain.
- Particle filters receive observations that implicitly down-weight blurry or moving objects without extra detection stages.
- Permanence reasoning from the model allows selective augmentation of map data rather than uniform use of all detections.
Where Pith is reading between the lines
- The same VLM front-end could be tested in hospitals or warehouses that share repetitive geometry and variable occupancy.
- Hybrid filters that fuse the semantic proposals with geometric features might further reduce failure cases in edge conditions.
- Open-vocabulary models appear to handle product or furniture distributions that closed-set classifiers would miss.
Load-bearing premise
That vision-language models deliver richer semantic distinctions, filter transient clutter, and support permanence reasoning in ways that measurably raise particle-filter accuracy over geometry alone in repetitive indoor spaces.
What would settle it
An experiment in the same grocery store that measures global localization success for VLM-GLoc no higher than for a geometry-only particle filter baseline would falsify the performance claim.
Figures




read the original abstract
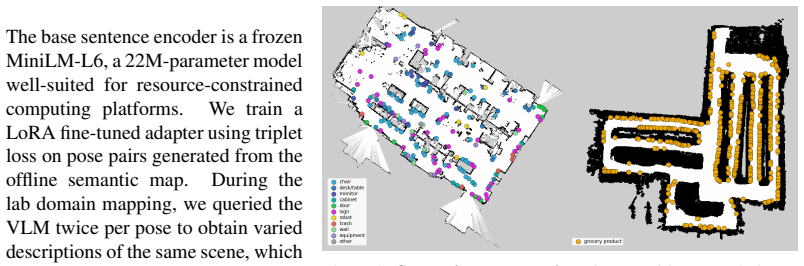
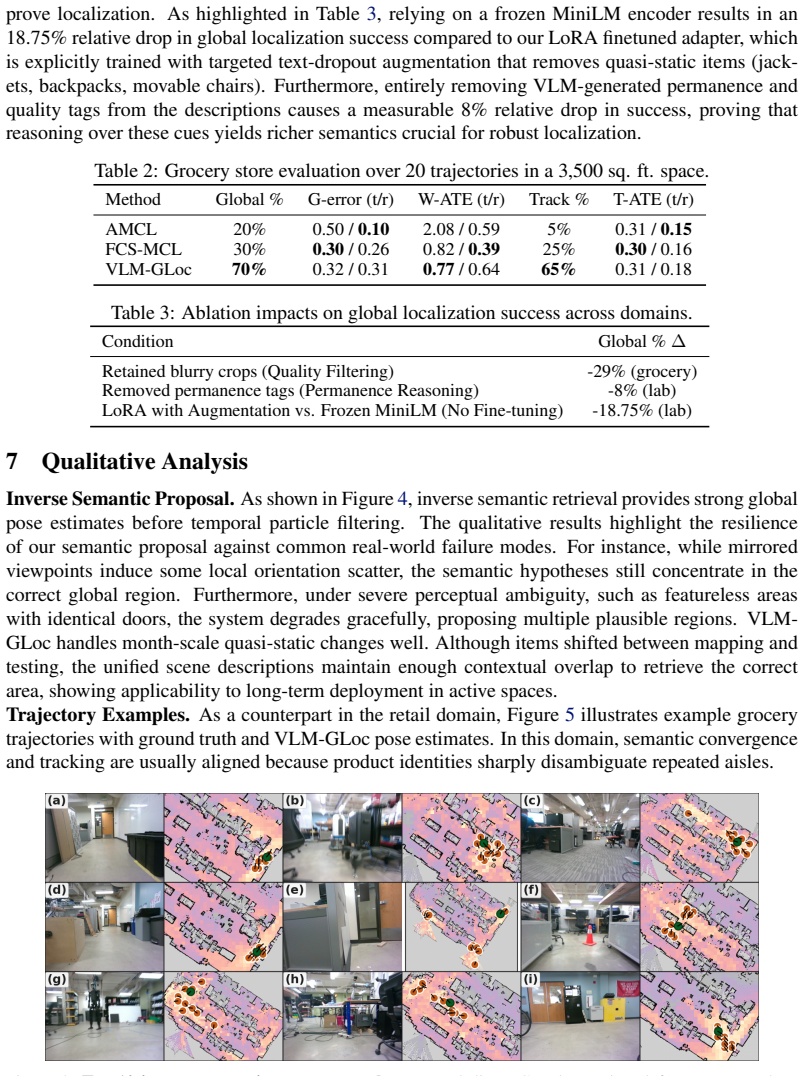
Global localization in geometrically aliased, quasi-static environments such as grocery stores, offices, schools, and hospitals poses a significant challenge for mobile robots. Grocery stores with parallel aisles and a long tailed distribution of products, as well as offices and labs with repetitive furniture such as chairs, desks, monitors, and doors, exemplify common indoor environments that present geometric and even semantic ambiguity. Traditional approaches rely either on distinct geometric features or on domain-specific vision pipelines that struggle with long-tail semantic distributions and transient visual clutter. We present VLM-GLoc, a method for hierarchical semantic Monte Carlo Localization (MCL) that leverages open-vocabulary Vision-Language Models (VLMs) as a unified semantic observation front-end. We hypothesize a three-fold benefit from VLMs: (1) extracting highly discriminative rich text features, (2) implicit quality filtering of blurry or dynamic objects, and (3) permanence reasoning for targeted data augmentation. We introduce an inverse semantic proposal mechanism that seeds particles via text-to-map retrieval. Evaluated across two real-world environments with different characteristics and two different platforms: a 3,500 sq. ft. grocery store with a cellphone and a 3,700 sq. ft. lab space with a quadruped, VLM-GLoc achieves 70% and 74% global localization success respectively, substantially outperforming traditional geometry-only and domain-specific baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents VLM-GLoc, a hierarchical semantic Monte Carlo Localization (MCL) method that uses open-vocabulary Vision-Language Models (VLMs) as a unified observation front-end for global localization in geometrically aliased, quasi-static indoor environments. It introduces an inverse semantic proposal mechanism for seeding particles via text-to-map retrieval and hypothesizes three VLM benefits: extraction of rich text features, implicit quality filtering of blurry/dynamic objects, and permanence reasoning for targeted augmentation. Real-world evaluation on a cellphone in a 3,500 sq. ft. grocery store and a quadruped in a 3,700 sq. ft. lab reports 70% and 74% global localization success rates, respectively, substantially outperforming geometry-only and domain-specific baselines.
Significance. If the reported gains can be attributed to the VLM components via controlled experiments, the work would provide evidence that general-purpose VLMs can improve robustness in long-tailed, aliased indoor scenes without requiring domain-specific training pipelines. The cross-environment, cross-platform real-world testing (grocery store with cellphone; lab with quadruped) is a positive aspect that supports practical relevance.
major comments (2)
- [Abstract / Evaluation] Abstract and evaluation description: the central claim that VLM-GLoc 'substantially outperform[s]' baselines rests on 70% and 74% success rates, yet no ablation is described that disables individual hypothesized VLM benefits (e.g., replacing VLM embeddings with conventional descriptors to test rich text features, feeding all detections to test implicit filtering, or removing targeted augmentation to test permanence reasoning). Without such controls, performance cannot be attributed to the three VLM mechanisms rather than the inverse semantic proposal or hierarchical MCL structure.
- [Abstract] Abstract: success percentages are stated without accompanying error bars, number of trials, dataset sizes, or statistical significance tests against baselines. This makes the quantitative outperformance claim difficult to assess for robustness.
minor comments (1)
- [Abstract] The abstract refers to 'two different platforms' but provides only high-level descriptors ('cellphone' and 'quadruped') without model specifics or sensor configurations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and will revise the manuscript to strengthen the attribution of results and improve experimental reporting.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and evaluation description: the central claim that VLM-GLoc 'substantially outperform[s]' baselines rests on 70% and 74% success rates, yet no ablation is described that disables individual hypothesized VLM benefits (e.g., replacing VLM embeddings with conventional descriptors to test rich text features, feeding all detections to test implicit filtering, or removing targeted augmentation to test permanence reasoning). Without such controls, performance cannot be attributed to the three VLM mechanisms rather than the inverse semantic proposal or hierarchical MCL structure.
Authors: We agree that the current evaluation does not include targeted ablations that isolate each of the three hypothesized VLM benefits. The reported comparisons are against geometry-only and domain-specific baselines, which demonstrate overall gains but do not disable the VLM components individually. In the revised manuscript we will add controlled ablations that (1) replace VLM embeddings with conventional descriptors, (2) disable implicit quality filtering by feeding all detections, and (3) remove targeted augmentation, thereby quantifying the contribution of each VLM mechanism relative to the inverse semantic proposal and hierarchical MCL structure. revision: yes
-
Referee: [Abstract] Abstract: success percentages are stated without accompanying error bars, number of trials, dataset sizes, or statistical significance tests against baselines. This makes the quantitative outperformance claim difficult to assess for robustness.
Authors: We acknowledge that the abstract reports only the aggregate success rates. The full evaluation section already records the number of trials and environment sizes, but we will expand the abstract and results to include error bars, explicit trial counts, dataset sizes, and statistical significance tests against the baselines in the revised version. revision: yes
Circularity Check
No circularity: empirical evaluation on external environments is independent of method definition
full rationale
The paper describes a VLM-enhanced hierarchical MCL pipeline with an inverse semantic proposal and reports aggregate success rates (70%/74%) on two distinct real-world test environments using different robot platforms. No equations, parameter fits, or derivation steps are presented that would make the performance metrics reduce to quantities defined by the method itself. The three hypothesized VLM benefits are stated as motivations rather than proven via self-referential construction, and evaluation relies on external benchmarks rather than internal consistency checks. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Target environments are quasi-static with long-tailed semantic distributions and geometric aliasing
invented entities (1)
-
inverse semantic proposal mechanism
no independent evidence
Reference graph
Works this paper leans on
-
[1]
N. Zimmerman, T. Guadagnino, X. Chen, J. Behley, and C. Stachniss. Long-Term Localization Using Semantic Cues in Floor Plan Maps.IEEE Robotics and Automation Letters, 8(1):176– 183, Jan. 2023. doi:10.1109/LRA.2022.3223556. Conference Name: IEEE Robotics and Automation Letters
-
[2]
Agrawal, J
S. Agrawal, J. Brawer, A. Naik, A. Roncone, and B. Hayes. Shelfaware: Real-time visual- inertial semantic localization in quasi-static environments with low-cost sensors.IEEE Robotics and Automation Letters, 2026
2026
-
[3]
D. Fox. KLD-Sampling: Adaptive Particle Filters. InAdvances in Neural Information Pro- cessing Systems, volume 14. MIT Press, 2001
2001
-
[4]
Accessed 2025-09-21
AMCL nav2 documentation.https://docs.nav2.org/configuration/packages/ configuring-amcl.html. Accessed 2025-09-21
2025
-
[5]
Biswas and M
J. Biswas and M. Veloso. Depth camera based indoor mobile robot localization and navigation. In2012 IEEE International Conference on Robotics and Automation, pages 1697–1702, May
-
[6]
doi:10.1109/ICRA.2012.6224766. ISSN: 1050-4729
-
[7]
Y . Watanabe, K. R. Amaro, B. Ilhan, T. Kinoshita, T. Bock, and G. Cheng. Robust Local- ization with Architectural Floor Plans and Depth Camera. In2020 IEEE/SICE International Symposium on System Integration (SII), pages 133–138, Jan. 2020. doi:10.1109/SII46433. 2020.9025984. ISSN: 2474-2325
-
[8]
H. Yin, X. Xu, S. Lu, X. Chen, R. Xiong, S. Shen, C. Stachniss, and Y . Wang. A Survey on Global LiDAR Localization: Challenges, Advances and Open Problems.International Journal of Computer Vision, 132(8):3139–3171, Aug. 2024. doi:10.1007/s11263-024-02019-5
-
[9]
H. Kuang, X. Chen, T. Guadagnino, N. Zimmerman, J. Behley, and C. Stachniss. IR-MCL: Implicit Representation-Based Online Global Localization.IEEE Robotics and Automation Letters, 8(3), Mar. 2023. doi:10.1109/LRA.2023.3239318. Conference Name: IEEE Robotics and Automation Letters
-
[10]
F. Xie and S. Schwertfeger. Robust Lifelong Indoor LiDAR Localization Using the Area Graph.IEEE Robotics and Automation Letters, Jan. 2024. doi:10.1109/LRA.2023.3334158. Conference Name: IEEE Robotics and Automation Letters
-
[11]
R. G. Goswami, P. V . Amith, J. Hari, A. Dhaygude, P. Krishnamurthy, J. Rizzo, A. Tzes, and F. Khorrami. Efficient Real-Time Localization in Prior Indoor Maps Using Semantic SLAM. In2023 9th International Conference on Automation, Robotics and Applications (ICARA), pages 299–303, Feb. 2023. doi:10.1109/ICARA56516.2023.10125919. ISSN: 2767-7745
-
[12]
Zimmerman, L
N. Zimmerman, L. Wiesmann, T. Guadagnino, T. L ¨abe, J. Behley, and C. Stachniss. Robust onboard localization in changing environments exploiting text spotting. In2022 IEEE/RSJ international conference on intelligent robots and systems (IROS), pages 917–924. IEEE, 2022
2022
-
[13]
Adkins, T
A. Adkins, T. Chen, and J. Biswas. Probabilistic object maps for long-term robot localization. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 931–938. IEEE, 2022
2022
-
[14]
Q. Gu, A. Kuwajerwala, S. Morin, K. M. Jatavallabhula, B. Sen, A. Agarwal, C. Rivera, W. Paul, K. Ellis, R. Chellappa, et al. Conceptgraphs: Open-vocabulary 3d scene graphs for perception and planning. In2024 IEEE International Conference on Robotics and Automation (ICRA), pages 5021–5028. IEEE, 2024. 9
2024
-
[15]
Anderson, Q
P. Anderson, Q. Wu, D. Teney, J. Bruce, M. Johnson, N. S ¨underhauf, I. Reid, S. Gould, and A. van den Hengel. Vision-and-language navigation: Interpreting visually-grounded naviga- tion instructions in real environments. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3674–3683, 2018
2018
-
[16]
Krantz, E
J. Krantz, E. Wijmans, A. Majumdar, D. Batra, and S. Lee. Beyond the nav-graph: Vision- and-language navigation in continuous environments. InEuropean Conference on Computer Vision, pages 104–120. Springer, 2020
2020
-
[17]
J. Chen, B. Lin, R. Xu, Z. Chai, X. Liang, and K.-Y . Wong. Mapgpt: Map-guided prompting with adaptive path planning for vision-and-language navigation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 9796–9810, 2024
2024
- [18]
- [19]
-
[20]
W. Xuan, Q. Zeng, H. Qi, J. Wang, and N. Yokoya. Seeing is believing, but how much? a comprehensive analysis of verbalized calibration in vision-language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1408– 1450, 2025
2025
-
[21]
Xiong, Z
M. Xiong, Z. Hu, X. Lu, Y . Li, J. Fu, J. He, and B. Hooi. Can llms express their uncertainty? an empirical evaluation of confidence elicitation in llms. InInternational Conference on Learning Representations, volume 2024, pages 23650–23678, 2024
2024
-
[22]
Groot and M
T. Groot and M. Valdenegro-Toro. Overconfidence is key: Verbalized uncertainty evaluation in large language and vision-language models. InProceedings of the 4th Workshop on Trust- worthy Natural Language Processing (TrustNLP 2024), pages 145–171, 2024
2024
-
[23]
Wang, I.-H
C.-Y . Wang, I.-H. Yeh, and H.-Y . Mark Liao. Yolov9: Learning what you want to learn using programmable gradient information. InEuropean conference on computer vision, pages 1–21. Springer, 2024
2024
-
[24]
Goldman, R
E. Goldman, R. Herzig, A. Eisenschtat, J. Goldberger, and T. Hassner. Precise detection in densely packed scenes. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5227–5236, 2019
2019
-
[25]
Macenski and I
S. Macenski and I. Jambrecic. Slam toolbox: Slam for the dynamic world.Journal of Open Source Software, 6(61):2783, 2021
2021
-
[26]
P. J. Besl and N. D. McKay. Method for registration of 3-d shapes. InSensor fusion IV: control paradigms and data structures, volume 1611, pages 586–606. Spie, 1992. 10 Appendices A Implementation and Reproducibility Details Table 4 records the main parameters for the headline runs. Table 4: Key implementation parameters. Component Value Compute Dell G15 ...
1992
-
[27]
A bounding box [ymin, xmin, ymax, xmax] in normalized 0-1000 coordinates
-
[28]
Include any readable text
A SHORT label (5-15 words max): color + material + object type. Include any readable text
-
[29]
Permanence: [S]=structural, [QS]=quasi-static furniture/equipment, [D]=dynamic people
-
[30]
box": [y1, x1, y2, x2],
Confidence (0.0-1.0): how certain you are this is a real, distinct object (not blur/shadow/artifact) Return as JSON array: [{"box": [y1, x1, y2, x2], "label": "brief identity", "perm": "S/QS/D", "conf": 0.9}] Rules: - Do NOT include position in image (left, right, foreground) - Do NOT include spatial relationships to other objects - Do NOT detect plain fl...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.